
从零实现RLHF
强化学习的过程也叫做偏好对齐的过程,发展到现在其已不再神秘了,一些最新的大模型流程基本都有RLHF的过程,之前看过一篇论文其是先DPO然后再PPO,DPO的文章之前我们已经讲过了,所以现在我们以PPO为例,进行RLHF全过程代码的构建。
本篇文章着重讲解具体的代码实现过程,其中的原理一篇文章是讲不完的,需要读者自己去阅读及思考。
首先,关键点就在于三个步骤
- SFT model
- reward model
- Reinforcement Learning
SFT就是你微调过后,想要RLHF的模型,也就是想要提升的模型。
剩余两个在下面进行介绍
Reward
Reward model
Reward model实际上是一个分类器,对输入的 指令+回答 进行 打分。一般Reward model我们就采用常规的已经pretrain的分类模型即可,也可以自己训练魔改一个。例如可以使用gpt2、facebook/opt-350m等,加载方式如下即可,如果 AutoModelForSequenceClassification不能识别的话需要自己在模型的config.json文件中进行映射了:
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
如果想使用大模型的话,例如QWEN、LLAMA等模型,可以直接通过huggingface使用
ForSequenceClassification
方法加载,可以去transformers库中查看,一般的大模型都会有一个
ForSequenceClassification
类,我们以最新的QWEN2为例,进入transformers库中的modeling_qwen2.py, 如下图所示,可以看到其是有一个
Qwen2ForSequenceClassification
方法的,其他模型也以此类推,使用这个方法作为reward model的加载。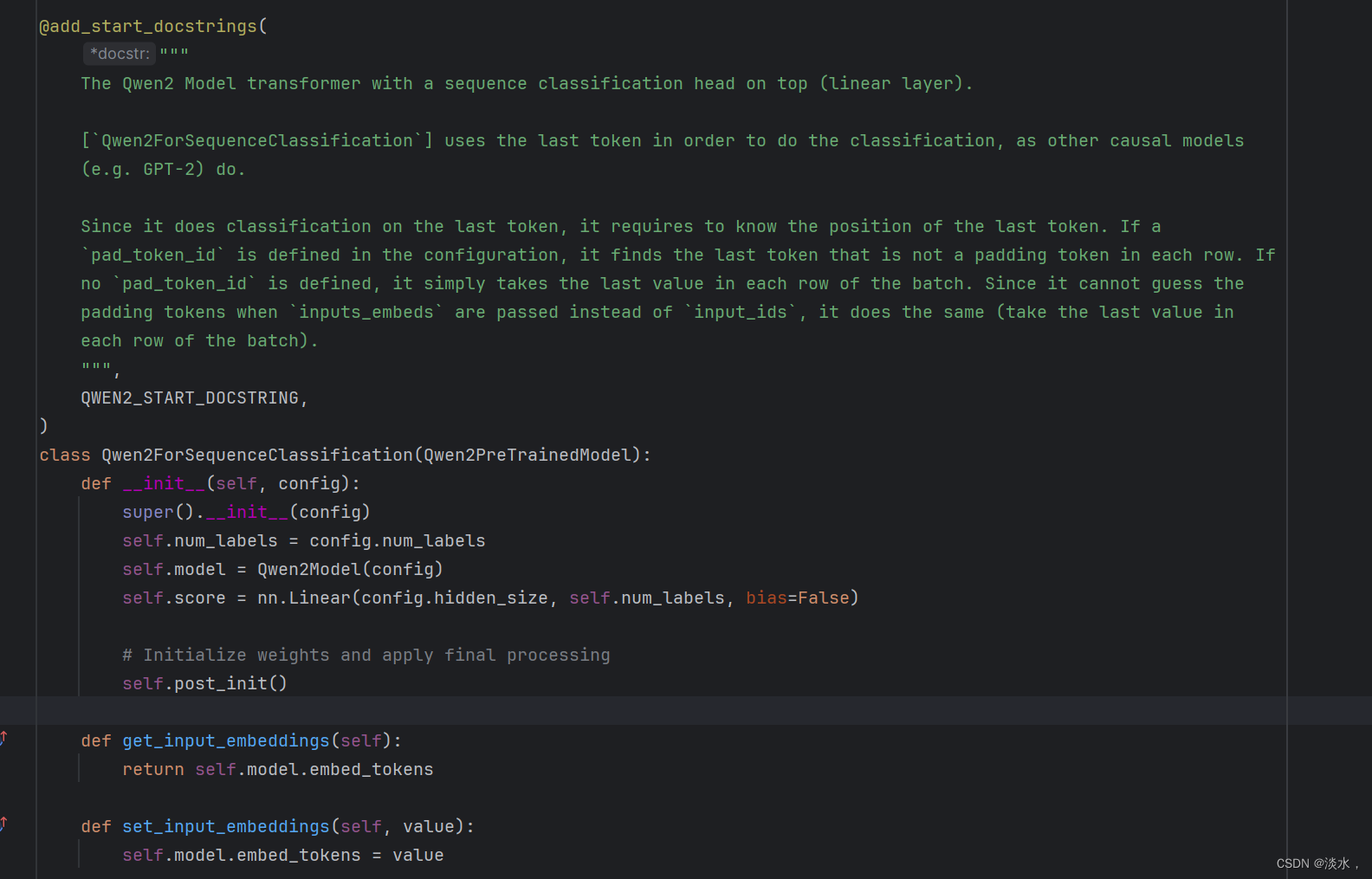
再进一步,我们看到
self.score
是一个线性层被添加到了QWEN模型中。进一步看下面代码: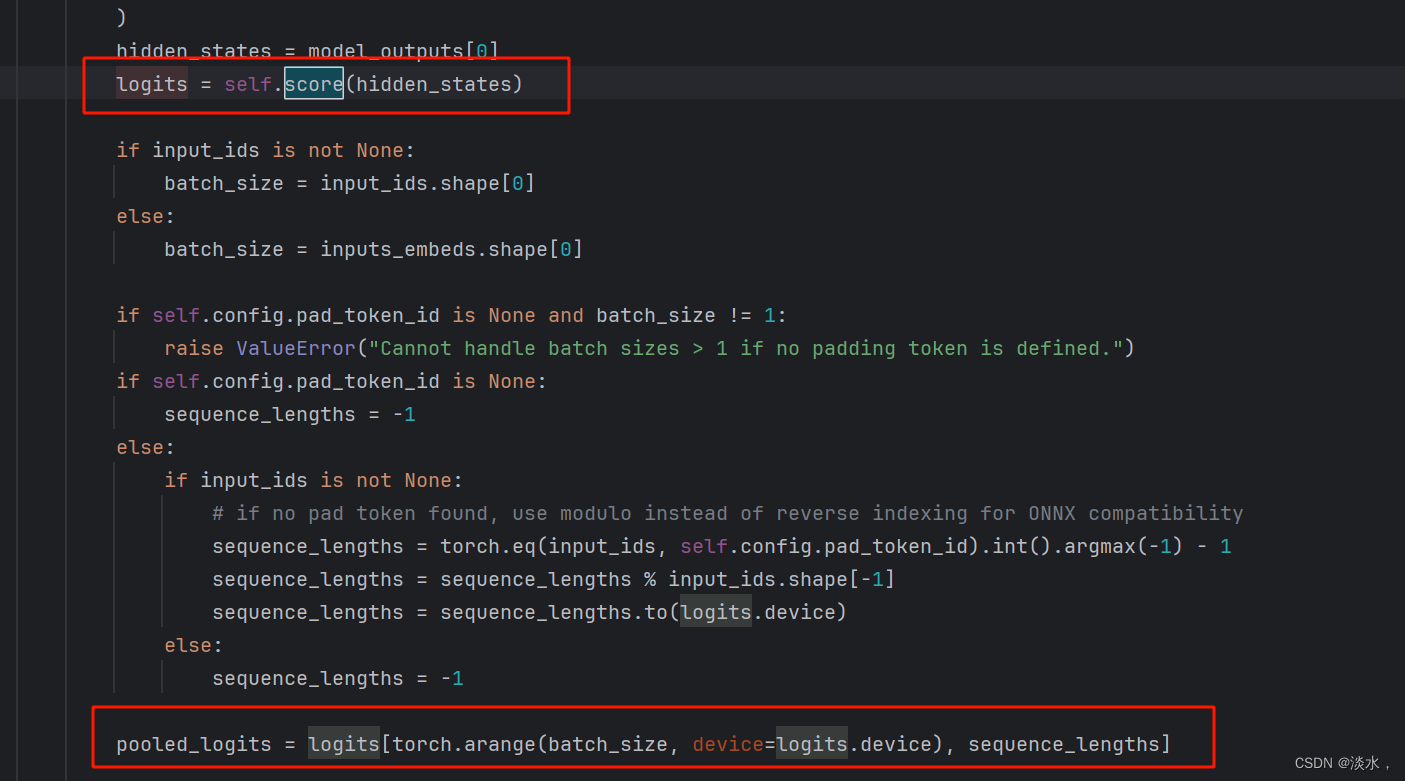
经过一个线性层后的logits维度为:***[batch_size, sequence_length, num_classes],经过图上第二个红框的操作后logits维度变为:[batch_size, num_classes],这里实现的逻辑是对于每句话,选最后一个词的得分作为这句话的得分*,以供后续reward 训练。
由于模型大小原因,我们本次以小一点的Phi-3为例进行reward的训练
代码示例:
from transformers import Phi3ForSequenceClassification # 不同模型需要替换不同接口
model = Phi3ForSequenceClassification.from_pretrained(
model_config.model_name_or_path, num_labels=1,**model_kwargs
)
另外一种方法
如果你觉得大模型作为reward model太大的话,也可以通过config进行设置,以减少模型的层数等,看自己偏好了,以下是一个代码示例:
import torch
import torch.nn.functional as F
from transformers import LlamaModel, LlamaConfig, LlamaForCausalLM, LlamaForSequenceClassification
torch.manual_seed(1)# 本地创建模型
config = LlamaConfig(vocab_size =100,# default is 32000
hidden_size =256,
intermediate_size =512,
num_hidden_layers =2,
num_attention_heads =4,
num_key_value_heads =4,)
model = LlamaForCausalLM(config)
model.save_pretrained('./lm_pretrained')# load LLaMA with "one labels" sequence classification model
rm_model = LlamaForSequenceClassification.from_pretrained('./lm_pretrained', num_labels=1)print(rm_model)
通过上述代码减少模型层数后,又可以作为一个新的reward model了。
Reward Train
使用hf的trl库我们可以很容易的进行Reward Train的训练工作。我们以huggingface的Anthropic/hh-rlhf数据集为例:
使用其他数据集的话将其改成这种格式即可。这里我们并没有适配每个模型的chat template,如果想做的话可以参考上述git项目中的做法,为了简化流程我这里就直接用这个数据集进行下一步操作了。
RewardTrainer 接受的数据需要有非常特定的格式,需要包括:
- input_ids_chosen
- attention_mask_chosen
- input_ids_rejected
- attention_mask_rejected
所以我们需要先进行数据处理操作,代码放在下面,也是比较简单了,因为现在的库真的是越来越好用了:
defpreprocess_function(examples):
new_examples ={"input_ids_chosen":[],"attention_mask_chosen":[],"input_ids_rejected":[],"attention_mask_rejected":[],}for chosen, rejected inzip(examples["chosen"], examples["rejected"]):
tokenized_chosen = tokenizer(chosen)
tokenized_rejected = tokenizer(rejected)
new_examples["input_ids_chosen"].append(tokenized_chosen["input_ids"])
new_examples["attention_mask_chosen"].append(tokenized_chosen["attention_mask"])
new_examples["input_ids_rejected"].append(tokenized_rejected["input_ids"])
new_examples["attention_mask_rejected"].append(tokenized_rejected["attention_mask"])return new_examples
有需要的话可以进行一下长度截断等过滤,以及划分一下train 和 test。
最后在配置一下相关的参数即可开始训练了。
然后将数据集送入Trainer开始训练.
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
args=config,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=get_peft_config(model_config),)
trainer.train()
trainer.save_model(config.output_dir)
metrics = trainer.evaluate()
trainer.log_metrics("eval", metrics)print(metrics)
RL (Reinforcement Learning): PPO 、RLOO
完成奖励模型的训练后我们来到最后一步,强化学习阶段。需要用到上一步的 Reward模型和原始的SFT模型。
训练用到的PPO Trainer依然是来自我们的huggingface trl库,可以很方便的使用及训练。目前最新版本是PPOv2Trainer,其是之前的PPOTrainer的改进版本,作者原话如下:
The PPOv2Trainer is the new experimental PPO trainer we now recommend to the users. It’s a refactor of PPOTrainer and PPOv2Trainer introduces more uniform APIs, better logging, documentations, and more benchmark results.
这里用到的数据集只需要prompt部分,所以应该跟上述的Reward Model训练的数据集相吻合(只用到了chosen和reject部分)。
首先需要加载四个模型:分别是value_model、reward_model、ref_policy、policy。
value_model = AutoModelForSequenceClassification.from_pretrained(
config.reward_model_path, trust_remote_code=model_config.trust_remote_code, num_labels=1)
reward_model = AutoModelForSequenceClassification.from_pretrained(
config.reward_model_path, trust_remote_code=model_config.trust_remote_code, num_labels=1)
ref_policy = AutoModelForCausalLM.from_pretrained(
config.sft_model_path, trust_remote_code=model_config.trust_remote_code
)
policy = AutoModelForCausalLM.from_pretrained(
config.sft_model_path, trust_remote_code=model_config.trust_remote_code
)
其中我们要训练的就是policy模型,加载完模型后还需要进行数据处理操作,与上述reward训练时有所不同,RL训练只需要返回prompt编码后的input_ids即可。
defprepare_dataset(dataset, tokenizer):"""pre-tokenize the dataset before training; only collate during training"""deftokenize(element):
outputs = tokenizer(
element[dataset_text_field],
padding=False,)return{"input_ids": outputs["input_ids"]}return dataset.map(
tokenize,
remove_columns=dataset.column_names,
batched=True,
num_proc=4,# multiprocessing.cpu_count(),
load_from_cache_file=False,)
最后将所有传入PPOv2Trainer即可开启训练!
trainer = PPOv2Trainer(
config=config,
tokenizer=tokenizer,
policy=policy,
ref_policy=ref_policy,
reward_model=reward_model,
value_model=value_model,
train_dataset=prepare_dataset(train_dataset, tokenizer),
eval_dataset=prepare_dataset(eval_dataset, tokenizer),)
trainer.train()
最后对显存做了一下PPO的实验,使用deepspeed的zero3,可以降低很多:
RLHFdeepspeed方式Reward ModelSFT Model****显存占用PPOZero 2LoraMiniCPM(2B)Deepseek(6.7B)2 x A100(40GB): OOMPPOZero 3LoraMiniCPM(2B)Deepseek(6.7B)2 x A100(40GB): 20-25GPPOZero 2QloraMiniCPM(2B)Deepseek(6.7B)2 x A100(40GB): 30G
Reference
1、https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo
版权归原作者 淡水, 所有, 如有侵权,请联系我们删除。