
手把手带你调参最新 YOLOv7 模型 (最新版本)(一)🚀
YOLO系列模型在目标检测领域有着十分重要的地位,随着版本不停的迭代,模型的性能在不断地提升,源码提供的功能也越来越多,那么如何使用源码就显得十分的重要,接下来我会通过文章带大家手把手去了解Yolov7(最新版本)的每一个参数的含义,并且通过具体的图片例子让大家明白每个参数改动将会给网络带来哪些影响。
文章目录
1. 代码获取方式🌟
官方YOLOv7 项目地址:https://github.com/WongKinYiu/yolov7
进入仓库 可以查看项目目前提供的最新版本
我选择的代码是main分支版本
2. 准备项目环境✨
在配置Conda环境后就可以进入项目了,可以通过作者提供的requirements.txt文件进行快速安装。
即在终端中键入如下指令:
pip install -r requirements.txt
requirements.txt文件里面有一些包被注释掉了,这些包是做一些额外的操作时候用的,不安装并不会影响训练和测试;
3. YOLOv7命令行预测方式介绍💡
这里介绍一下官方给提供的预测方式,我们平时都是在Pycharm中点击“运行”按钮去预测模型,其实还可以通过命令行的方式去预测,预测后的结果会自动保存到runs/detect路径下;其实在这条指令后面还可以加上一些参数,具体怎么加后面会详细说明。
ppython detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
4. detect.py文件解读🚀
4.1 检测一下看看效果
我们可以直接运行detect.py文件试试效果,运行后系统会把检测结果保存在runs\detect\exp路径下
检测效果就是这样子的
这两张是项目自带的图片,我们也可以把自己想测试的图片或者视频放到这个路径下:
4.2 参数详解🚀
打开detect.py直接看217行
定位到以下代码,之后就是参数
parser = argparse.ArgumentParser()
4.2.1 “weights”
parser.add_argument('--weights', nargs='+',type=str, default='yolov7.pt',help='model.pt path(s)')
这个就是指定网络权重的路径,默认是“yolov7.pt”,官方提供了很多的版本,我们要更换的时候直接按照Model的名字更换就可以了;例如“yolov7-tiny.pt”“yolov7-e6.pt”,可以去官网下载了,下载好了直接放到根目录下就可以)
这里说一下“default”: default是默认的参数,即使我们在运行时不指定具体参数,那么系统也会执行默认的值。
4.2.2 “source”
parser.add_argument('--source',type=str, default='inference/images',help='source')# file/folder, 0 for webcam
这个参数就是指定网络输入的路径,默认指定的是文件夹,也可以指定具体的文件或者扩展名等
4.2.3 “img-size”
parser.add_argument('--img-size',type=int, default=640,help='inference size (pixels)')
这个意思就是模型在检测图片前会把图片resize成640的size,然后再喂进网络里,并不是说会把们最终得到的结果resize成640大小。
4.2.4 “conf-thres”
parser.add_argument('--conf-thres',type=float, default=0.25,help='object confidence threshold')
这个就是置信度的阈值,置信度这个概念在 @迪菲赫尔曼 的博文“YOLOv1详细解读”里面详细介绍了一下,感兴趣的小伙伴可以看一下,通俗一点来说就是网络对检测目标相信的程度,如果这里设置“0”的话,那么网络只要认为这他预测的这个目标有一点点的概率是正确的目标,他都会给框出来,我们可以通过这几幅图对比一下。
我这里把conf-thres参数依次设置成“0”, “0.25”,“0.8”
原图:
conf-thres=0
conf-thres=0.25
conf-thres=0.8
Q1:这里参数到底设置成多少好呢?
根据自己的数据集情况自行调整
4.2.5 “iou-thres”
parser.add_argument('--iou-thres',type=float, default=0.45,help='IOU threshold for NMS')
这个参数就是调节IoU的阈值,这里简单介绍一下NMS和IoU
4.2.5.1 NMS介绍
在执行目标检测任务时,算法可能对同一目标有多次检测。NMS 是一种让你确保算法只对每个对象得到一个检测框的方法。
在正式使用NMS之前,通常会有一个候选框预清理的工作(简单引入一个置信度阈值),如下图所示:
NMS 算法的大致过程:每轮选取置信度最大的 Bounding Box(简称 BBox) 接着关注所有剩下的 BBox 中与选取的 BBox 有着高重叠(IoU)的,它们将在这一轮被抑制。这一轮选取的 BBox 会被保留输出,且不会在下一轮出现。接着开始下一轮,重复上述过程:选取置信度最大 BBox ,抑制高 IoU BBox。(关于Bounding Box Regression的详细介绍,强力推荐@迪菲赫尔曼另一篇博文)
IoU可以理解预测框和真实框的交并比
NMS步骤:
第一步:对 BBox 按置信度排序,选取置信度最高的 BBox(所以一开始置信度最高的 BBox 一定会被留下来);
第二步:对剩下的 BBox 和已经选取的 BBox 计算 IOU,淘汰(抑制) IOU 大于设定阈值的 BBox(在图例中这些淘汰的 BBox 的置信度被设定为0)。
第三步:重复上述两个步骤,直到所有的 BBox 都被处理完,这时候每一轮选取的 BBox 就是最后结果。
在上面这个例子中,NMS 只运行了两轮就选取出最终结果:第一轮选择了红色 BBox,淘汰了粉色 BBox;第二轮选择了黄色 BBox,淘汰了紫色 BBox 和青色 BBox。注意到这里设定的 IoU 阈值是0.5,假设将阈值提高为0.7,结果又是如何?
可以看到,NMS 用了更多轮次来确定最终结果,并且最终结果保留了更多的 BBox,但结果并不是我们想要的。因此,在使用 NMS 时,IoU 阈值的确定是比较重要的,但一开始我们可以选定 default 值(论文使用的值)进行尝试。
4.2.5.2 不同阈值例子
如果看不懂的话就直接通过例子来理解一下:
这里我“iou-thres”分别取“0”,“0.45”,“0.9”,“1”
iou-thres=0:
iou-thres=0.45:
iou-thres=0.9:
iou-thres=1:
4.2.6 “device”
parser.add_argument('--device', default='',help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
这个参数意思就是指定GPU数量,如果不指定的话,他会自动检测,这个参数是给GPU多的土豪准备的。
4.2.7 “action=‘store_true’”说明
这个类型的参数和之前的有很大区别,大家可以把他理解成一个“开关”,当我们运行程序的时候如果指定了带有action='store_true’类型的参数,那么就相当于启动这个参数所对应的功能,反之则不。我会拿下面的举个例子。
action='store_true' 代表 True
4.2.8 “view-img”
parser.add_argument('--view-img', action='store_true',help='display results')
这个参数意思就是检测的时候是否实时的把检测结果显示出来,即我如果在终端中输入以下指令 :
python detect.py --view-img
那么意思就是我在检测的时候系统要把我检测的结果实时的显示出来,假如我文件夹有5张图片,如果指定了这个参数的话,那么模型每检测出一张就会显示出一张,直到所有图片检测完成。如果我不指定这个参数,那么模型就不会一张一张的显示出来。
4.2.9 “save-txt”
parser.add_argument('--save-txt', action='store_true',help='save results to *.txt')
这个参数的意思就是是否把检测结果保存成一个.txt的格式,我们来看一下指定了这个参数的效果:
终端键入:
python detect.py --save-txt
可以看到输出结果多了一个labels文件夹

打开这个文件夹就可以看到两个.txt文件
这两个.txt文件里面保存了一些类别信息和边框的位置信息
4.2.10 “save-conf”
parser.add_argument('--save-conf', action='store_true',help='save confidences in --save-txt labels')
这个参数的意思就是是否以.txt的格式保存目标的置信度
如果单独指定这个命令是没有效果的;
python detect.py --save-conf #不报错,但没效果
必须和–save-txt配合使用,即:
python detect.py --save-txt --save-conf
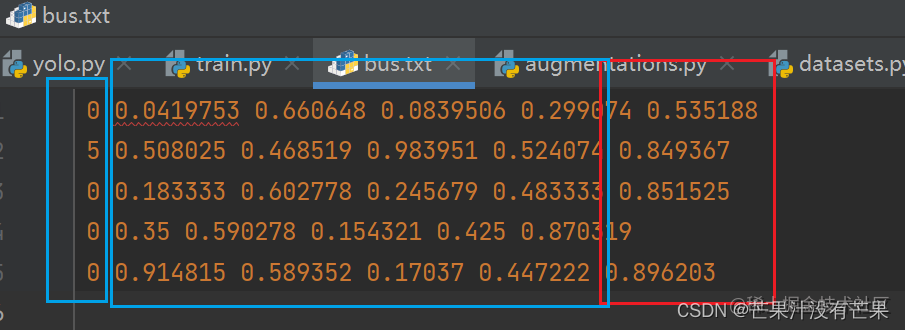
如果指定了这个参数就可以发现,同样是保存txt格式的文件,这次多了红色框里面的置信度值。原来每行只有5个数字,现在有6个了。
4.2.11 “nosave”
parser.add_argument('--nosave', action='store_true',help='do not save images/videos')
开启这个参数就是不保存预测的结果,但是还会生成exp文件夹,只不过是一个空的exp
这个参数应该是和“–view-img”配合使用的
4.2.12 “classes”
parser.add_argument('--classes', nargs='+',type=int,help='filter by class: --class 0, or --class 0 2 3')
这个的意思就是我们可以给变量指定多个赋值,也就是说我们可以把“0”赋值给“classes”,也可以把“0”“2”“4”“6”都赋值给“classes”
接下来说classes参数,这里看一下coco128.yaml的配置文件就明白了,比如说我这里给classes指定“0”,那么意思就是只检测人这个类别。
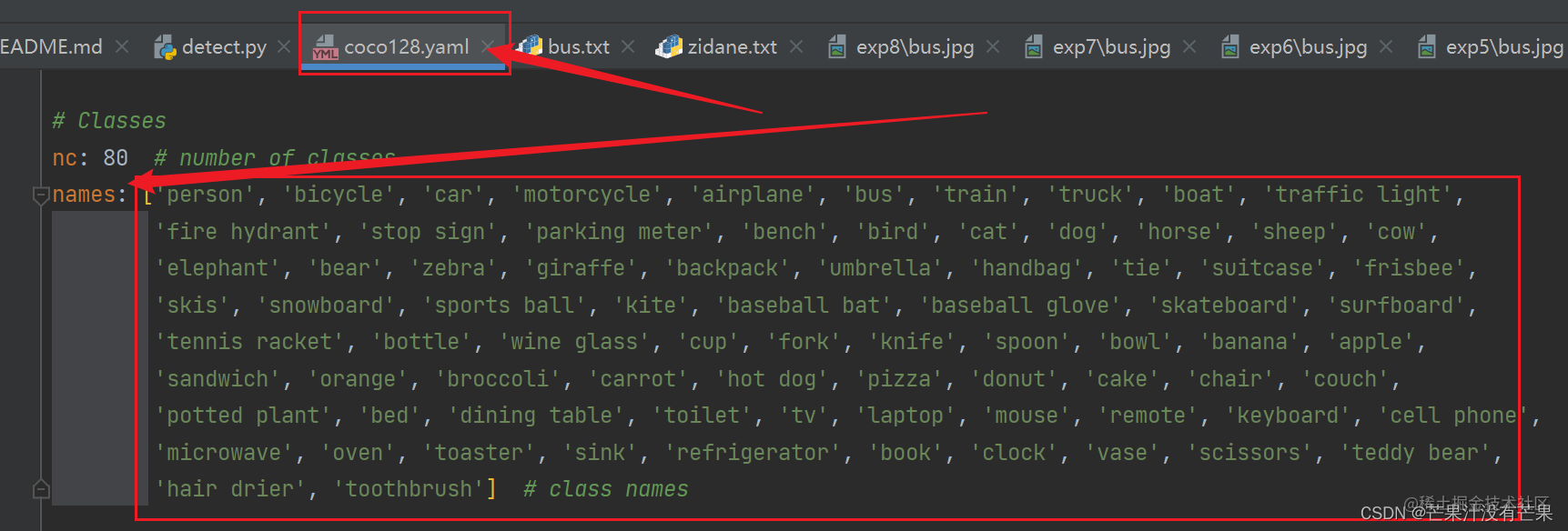
例:键入如下指令:
python detect.py --classes 0
4.2.13 “agnostic-nms”
parser.add_argument('--agnostic-nms', action='store_true',help='class-agnostic NMS')
这个是增强版的nms,算是一种trick吧,通过一个例子对比一下:

启用后:

4.2.14 “augment”
parser.add_argument('--augment', action='store_true',help='augmented inference')
这个参数也是一种增强的方式
启用前:![[)]](https://img-blog.csdnimg.cn/a78940c13a1b419fab16233a2efe8068.png)
启用后:
![[]](https://img-blog.csdnimg.cn/dcd86f8000924632a15a537e9886bd15.png)
这个还是有很明显的区别的
4.2.15 “update”
parser.add_argument('--update', action='store_true',help='update all models')
如果指定这个参数,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息。
4.2.16 “project”
parser.add_argument('--project', default='runs/detect',help='save results to project/name')
这个就是我们预测结果保存的路径。
4.2.17 “name”
parser.add_argument('--name', default='exp',help='save results to project/name')
这个就是预测结果保存的文件夹名字
4.2.18 “exist-ok”
parser.add_argument('--exist-ok', action='store_true',help='existing project/name ok, do not increment')
这个参数的意思就是每次预测模型的结果是否保存在原来的文件夹,如果指定了这个参数的话,那么本次预测的结果还是保存在上一次保存的文件夹里;如果不指定就是每次预测结果保存一个新的文件夹下。
4.2.19 “–no-trace”
parser.add_argument('--no-trace', action='store_true',help='don`t trace model')
这个参数的意思表示不要跟踪模型。
参考文献
非极大值抑制算法
手把手带你调参Yolo v5 (v6.1)(一)
有问题欢迎大家指正
版权归原作者 芒果汁没有芒果 所有, 如有侵权,请联系我们删除。