
Title:Large Language Models for Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering
Paper: https://arxiv.org/pdf/2305.03403.pdf
GitHub: https://github.com/automl/CAAFE
PS:该论文已被NeurIPS 2023接收!
I. 方法概要
本文介绍了一种名为Context-Aware Automated Feature Engineering (CAAFE)的方法,该方法利用大型语言模型(LLMs)来自动生成针对表格数据集的特征工程代码。CAAFE通过迭代生成语义有意义的特征,并为生成的特征提供解释,从而改善了14个数据集中11个数据集的性能。该方法的效果类似于使用随机森林而不是逻辑回归来处理数据集。CAAFE的优势在于自动化地整合领域知识到AutoML过程中,从而减少了从数据到训练模型的延迟,降低了创建机器学习模型的成本,并增强了解决方案的鲁棒性和可重复性。该方法结合了传统机器学习的优势(鲁棒性、可预测性和一定程度的可解释性)和LLMs的优势(领域知识和创造力)。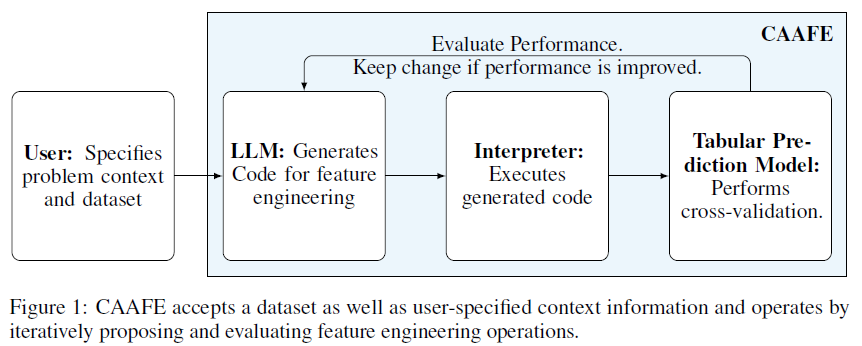
II. CAAFE算法原理
CAAFE(Context-Aware Automated Feature Engineering)是一种利用大型语言模型(LLMs)自动生成特征工程代码的方法。其算法原理如下:
- 用户提供数据集描述和上下文信息作为输入,包括数据类型、缺失值比例和数据集的随机样本。
- CAAFE构建一个提示(prompt),包含了对LLMs的指令,指导LLMs生成有用的特征工程代码,并提供对生成特征的解释。
- CAAFE执行多次特征修改和验证,每次LLMs生成代码,然后在当前训练集和验证集上执行,得到转换后的数据集。
- 生成的代码会对数据集进行修改,包括创建有意义的特征、删除不必要的特征等。
- CAAFE会评估生成的特征对下游预测任务的性能改善,并保留性能提升的特征。
总的来说,CAAFE利用LLMs自动生成特征工程代码,从而改善数据科学任务的性能,并提供对生成特征的解释,使得自动化特征工程更加透明和可解释。进一步地,大语言模型(LLMs)扮演了生成特征工程代码的角色。LLMs被用来自动生成Python代码,该代码用于创建新的语义有意义的特征,以改善下游预测任务的性能。LLMs通过对数据集描述和上下文信息进行理解和推理,生成能够提升预测性能的特征工程代码。这样,LLMs在CAAFE中起到了自动生成特征工程代码的关键作用。
III. Prompt的设计
CAAFE中的Prompt设计非常重要,因为它指导LLMs生成特征工程代码并提供对生成特征的解释。Prompt的设计包括以下内容:
- 用户生成的数据集描述,其中包含有关数据集的上下文信息和语义信息。
- 特征名称,用于为LLMs提供上下文信息,并允许LLMs根据特征名称生成代码。
- 期望生成代码和解释的模板,以指导LLMs生成特征工程代码和提供解释。
此外,Prompt还包括了一系列中间推理步骤的指令,这些指令对于提高LLMs的响应质量非常有效。整个Prompt的设计旨在为LLMs提供足够的信息和指导,以确保生成的特征工程代码和解释能够提高预测性能并具有可解释性。
IV. 实验设计
在CAAFE的算法实验设计中,研究人员进行了以下工作:
- 使用了14个数据集进行实验,包括来自OpenML和Kaggle的数据集。
- 对比了CAAFE与传统自动特征工程方法(如Deep Feature Synthesis和AutoFeat)的性能。
- 评估了不同的下游分类器和特征扩展方法的性能。
- 进行了对比实验,验证了CAAFE在不同情况下的性能表现。
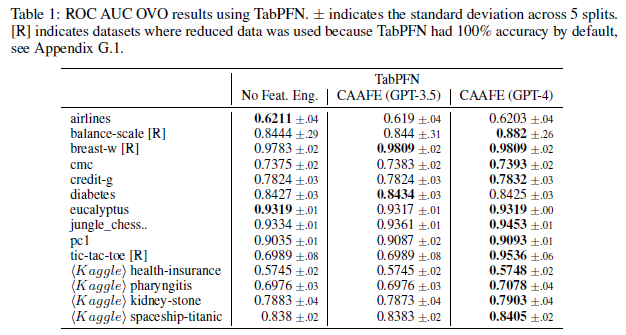
主要结论如下:
- CAAFE能够在11个数据集中提高预测性能,平均ROC AUC从0.798提升到0.822。
- CAAFE的效果类似于使用随机森林而不是逻辑回归来处理数据集。
- CAAFE结合了传统机器学习的鲁棒性和可解释性,以及LLMs的领域知识和创造力,为自动化特征工程提供了一种新的方法。
- CAAFE的性能在不同的数据集和分类器上都得到了验证,表现出了稳健的性能和可扩展性。
V. 结论与启示
本文的主要结论和启示如下:
主要结论:
- CAAFE利用大型语言模型(LLMs)自动生成特征工程代码,从而改善数据科学任务的性能,并提供对生成特征的解释,使得自动化特征工程更加透明和可解释。
- CAAFE在11个数据集中提高了预测性能,平均ROC AUC从0.798提升到0.822,类似于使用随机森林而不是逻辑回归来处理数据集。
- CAAFE结合了传统机器学习的鲁棒性和可解释性,以及LLMs的领域知识和创造力,为自动化特征工程提供了一种新的方法。
- CAAFE的性能在不同的数据集和分类器上都得到了验证,表现出了稳健的性能和可扩展性。
启示:
- 结合大型语言模型和传统机器学习方法可以提高自动化特征工程的效果,为数据科学任务提供更多的自动化解决方案。
- 自动化特征工程的透明性和可解释性对于用户理解和修改自动生成的特征至关重要,这有助于提高用户对自动化过程的信任和接受度。
- 领域知识和上下文信息对于自动生成特征工程代码的质量和效果至关重要,用户提供的数据集描述和上下文信息对于LLMs的性能起到了关键作用。
本文的研究为自动化数据科学任务提供了一种新的方法,强调了大型语言模型在自动化特征工程中的潜在作用,并展示了其在提高预测性能和可解释性方面的优势。
版权归原作者 小数志 所有, 如有侵权,请联系我们删除。