
视觉-语言模型(VLMs)如 CLIP 彻底改变了零样本图像识别的处理方式。这类模型在包含 4 亿个图像-文本对的大规模数据集上进行训练,捕获了海量通用知识,具备了识别未被明确训练过对象的能力。
当尝试通过 Prompt Tuning 过程将这些全能型模型适配到特定下游任务时通常会遇到瓶颈。这是因为模型在特定任务上变成了专家,却不可避免地牺牲了原有的基础智能;这种现象在业内被称为 Base-to-New 泛化困境。
论文《Visual-Language Prompt Tuning with Knowledge-guided Context Optimization》(KgCoOp)深入研究了这一问题,提出了一种简单有效的约束机制。
现代机器学习系统经常被部署在不断有新类别出现的环境中。如果一个模型只能在已知类别上保持高准确率,面对新类别时却表现糟糕,其在实际工程应用中的可靠性就会大打折扣。提高对未见类别的泛化能力,是构建泛化的视觉-语言系统的必由之路。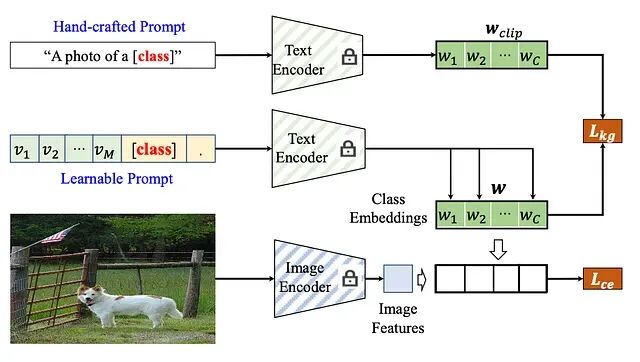
Knowledge-guided Context Optimization(KgCoOp)框架概述,展示了如何使用知识引导损失对可学习 Prompt 进行正则化以保持泛化能力。
为什么 CoOp 在未见类别上失败
Prompt Tuning 的具体实现之一 Context Optimization(CoOp),用可学习的上下文向量替代了固定的手工模板(如 a photo of a [Class])。这种微调方式拉升了模型在训练期见过的 Base 类别上的表现,随之而来的却是灾难性知识遗忘。
在少量标注样本上微调时,模型会学习到仅对这些特定类别有判别性的文本知识,从而严重偏离其他所有类别。跨 11 个基准测试的实证数据揭示了一个明显的趋势——标准微调(CoOp)虽然提升了 Base 准确率,却把新类别上的性能压低到了不仅不及预期,甚至低于原始零样本模型的水准。零样本 vs. 标准微调的性能对比:
Data averaged across 11 benchmarks using ViT-B/16.
遗忘的几何学
新类别性能损失的程度(▽new)与可学习 Prompt 嵌入(wcoop) 和原始手工 CLIP 嵌入(wclip) 之间的欧几里得距离直接一致。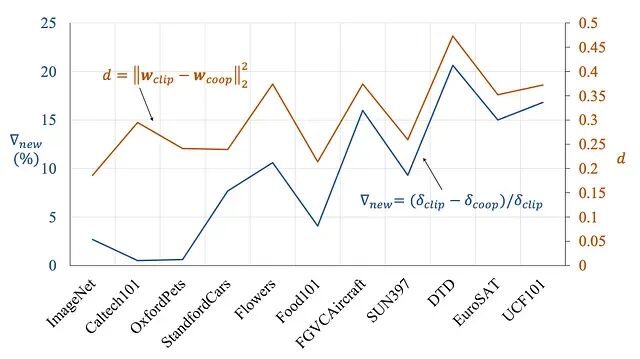
Base-to-New 泛化对比,显示标准 Prompt Tuning 提高了已见类别的性能,但降低了未见类别的准确率。
学习到的 Prompt 与手工 Prompt 之间的距离越大,未见类别上的性能退化越严重。
在 DTD(纹理)和 EuroSAT(卫星影像)等数据集中,学习到的 Prompt 偏离 CLIP 锚点最远,泛化差距也最为悬殊。如果能将可学习 Prompt 限制在原始通用知识的附近,就可以维持原有的泛化能力。
Knowledge-guided Context Optimization(KgCoOp)
KgCoOp 引入了一种新的正则化框架。该框架不再允许 Prompt 在优化过程中自由漂移,专门加入了一个知识引导损失 ***(Lkg)***,专门用于最小化可学习 Prompt 与手工 Prompt 之间的差距。
**A. 前置知识 - CLIP 和 CoOp **
零样本 CLIP 中,图像嵌入 x 和类别 y 的预测概率 p(y|x) 计算方式为: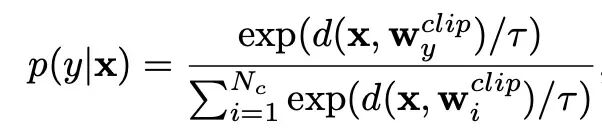
其中 d(x,__wy^__clip) 代表余弦相似度,(w^__clip) 代表来自手工模板的嵌入。CoOp 将这些模板替换为 M 个可学习的上下文向量 *V= {v1, v2, …, vM }*;此时 Prompt 变为 ti^coop = {v1 , v2 , ..., vM , ci },c**i 为类别 Token。
B. KgCoOp 公式
KgCoOp 提出,减少可学习 Prompt 与手工 Prompt 之间的物理距离,能够有效缓解底层知识的遗忘。其训练目标是在标准交叉熵损失 (Lce) 的基础上叠加这一新约束: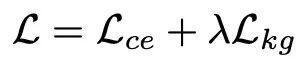
其中引入的知识引导损失 (Lkg),定义为微调后的嵌入 wi 与 CLIP 锚点 (wi^clip) 之间的均方欧几里得距离: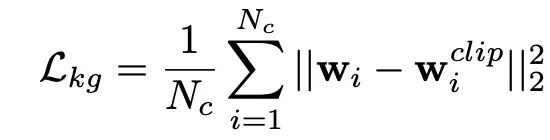
在最小化这个距离的过程中,KgCoOp 强制模型在针对当前任务进行参数优化的同时"记住"其通用预训练特征。
实验设置与基准测试
相关指标在 11 个多样化的图像分类基准上对 KgCoOp 进行了评估;实验骨干网络选用 ResNet-50 和 ViT-B/16,测试条件主要设定为 16-shot。
覆盖的数据集包含了 ImageNet、Caltech101 等通用对象,OxfordPets、StanfordCars、Flowers102、Food101、FGVCAircraft 等细粒度类别,以及 EuroSAT(卫星影像)、UCF101(动作识别)、DTD(纹理)、SUN397(场景)等专业领域。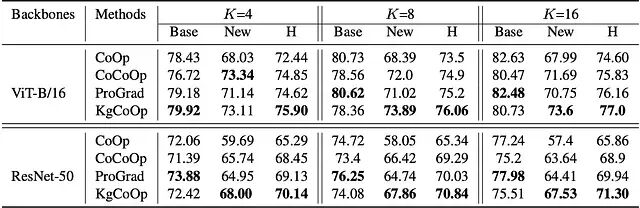
Comparison in the base-to-new setting with different K-shot samples in terms of the average performance among all 11 datasets and backbones(ViT-B/16 and ResNet-50)
测试结果显示,KgCoOp 在所有参测设置的平均统计中取得了最高的调和均值。ProGrad 在 Base 类别上确实表现更好,但在处理新类别时与 KgCoOp 存在量级差异。具体到 ViT-B/16 骨干网络配合 16 个样本的场景下,KgCoOp 把新类别的准确率相较于 CoOp 基线拉高了 5.61%,比 CoCoOp 也高出 1.91%。这一数据佐证了 KgCoOp 较好地平衡了任务特定性能与通用性,基本化解了 Base-Novel 困境。
应对 Base-to-New 挑战
工程上的核心诉求是在不牺牲 Base(已见)类别准确率的前提下,尽可能挖掘 New(未见)类别的性能潜力。采用 ViT-B/16 前置配合 16-shot,KgCoOp 在新类别准确率指标上相对标准 CoOp 基线提升了 5.61%。综合 11 个数据集的数据,KgCoOp 测得 77.0% 的调和均值峰值,压制了 CoCoOp(75.83%)和 ProGrad(76.16%)等路线。在 EuroSAT、UCF101 这类特征专业性较强的数据集上,KgCoOp 也在 8 个基准中拿到了新类别的最高分。
领域泛化场景中的表现
领域泛化(DG)主要用于测试类别标签恒定但数据源发生分布偏移时,模型展现出的抵抗衰减能力。实验流程上,先使用 16-shot 样本在标准 ImageNet 集中进行训练,随后转至四个分布外的变体集(ImageNetV2、ImageNet-Sketch、对抗样本集 ImageNet-A 和渲染集 ImageNet-R)中跑评估。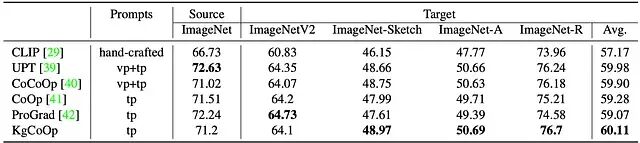
Comparison of prompt learning in the domain generalization with 16-shot source samples where "vp" and "tp" denote the visual prompting and textual prompting, respectively.
效率与泛化的指标分解
超参数 λ 的敏感度表现。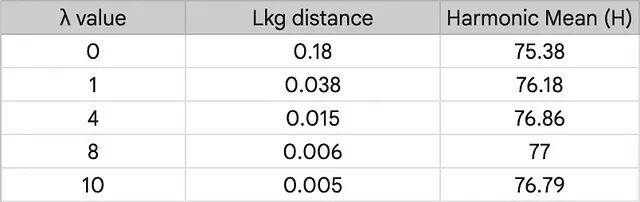
定量分析揭示出一个直接规律:增大 λ 可以减小 Lkg 距离,迫使学习得到的 Prompt 进一步贴近手工 Prompt。距离收窄带动的调和均值拉升在 λ=8.0 时见顶。继续加大 λ 会让约束变得过于苛刻,反而阻断了模型对当前任务特有判别特征的吸收,引发指标回落。只要约束在一个合理的区间内,最小化学习知识与通用知识间的偏差,确实是保持未见领域泛化水位的主力手段。
计算开销与训练耗时比对。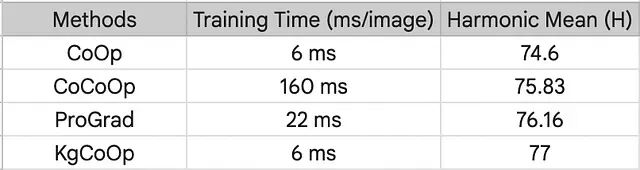
计算嵌入空间的欧几里得距离带来的算力开销微乎其微。CoCoOp 因为需要给每一个实例单独生成图像条件的上下文,速度慢了将近 26 倍(160 ms/image)。ProGrad 要计算梯度并为每次参数更新做对齐检查,耗时同样居高不下(22 ms/image)。相比之下,KgCoOp 的吞吐量达到了 6m/s,基本做到了用最低的时间成本换取第一梯队的精度。
Lkg 项在现有框架里的兼容性。Lkg 约束不是一个孤立的技巧,它完全可以作为插件融合到其他的 Prompt Tuning 架构当中。从 ViT-B/16 的训练时间与性能表可以看出,外挂知识引导约束后,CoCoOp 和 ProGrad 的新类别性能和调和均值都出现了一致的上扬。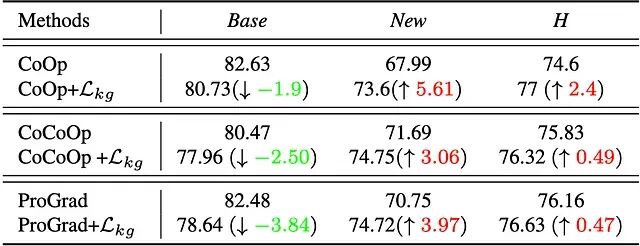
CoCoOp 叠加 Lkg 后,新类别准确率从 71.69% 升至 74.75%,调和均值涨了 0.49%。ProGrad 叠加 Lkg 后,新类别准确率从 70.75% 升至 74.72%,调和均值由 76.16% 爬到 76.63%。
针对标准文本 Prompt Tuning 发现的"灾难性遗忘",已被证实是跨网络架构的底层通病;而 KgCoOp 这一套逻辑,具备横向拓展到更多 Prompt 体系落地应用的潜力。
上下文长度的影响因素。
为了对标现有的基线,实验虽然把上下文长度 M=4 作为了默认测试标准,但在消融分析中发现:把长度设定为 8 个 Token,能在已见和未见类别上挤出更大的性能空间。如果有算力支撑稍长的序列长度,这是一个低成本的性能调优发力点。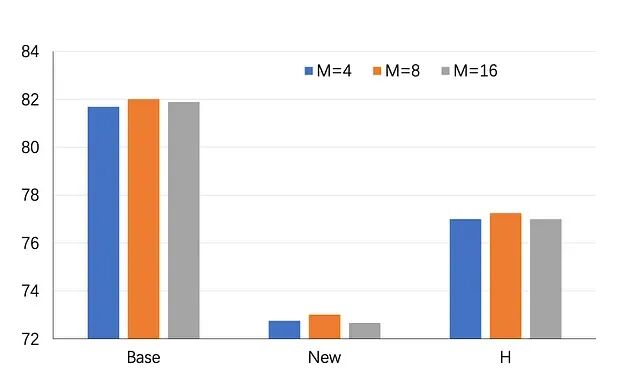
Effect of contect length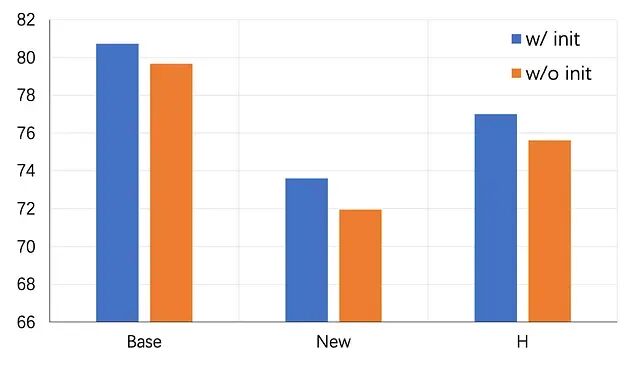
Effect of Initialization
局限探讨
KgCoOp 在提拉未见类别泛化能力的同时,依然面临着稳定性与适应性博弈的老问题。给知识引导约束加码,未见类别的评分会变好看,但已见类别的上限往往会被压低几分。
这种此消彼长折射出一个硬约束的副作用:限定了学习到的 Prompt 与原始 CLIP 表征的物理距离,扼杀了过拟合的风险,也削弱了模型向特定偏门场景彻底倾斜的灵活性。
引入超参数 λ 意味着多了一层调参负担。设定偏差,轻则导致欠拟合,重则让 Prompt 机制的自适应能力名存实亡。
总结
自动匹配约束强度的机制依然是工程界亟待攻克的盲区。未来的迭代如果尝试引入数据驱动的超参数自适应,模型在稳定性和灵活性之间的切换将更加从容。
调整乃至约束本身,跟基础模型的参数优化处于同等地位。KgCoOp 提供了一套务实的调优路径参考清单。
面对基座模型,首要动作是跑通零样本基线,摸清泛化指标的绝对谷底在哪。在遇到硬件算力瓶颈或是延迟卡控严格的生产环境,KgCoOp 是直接拿来保底的降本方案。调试期间密切监测期望校准误差(ECE),可以规避 Lkg 约束过重引发的概率输出欠置信。
维护微调参数与源知识的几何对齐关系,是一套经过验证的轻量级技法;仅凭一个欧几里得距离损失便兜住了在新领域的下限,摆脱了对新样本增量数据的过度依赖。
by Gauri Kosurkar