
(一)前情
这个工作已经有大佬用在自己的工程里了,他的帖子链接:https://blog.csdn.net/weixin_45829462/article/details/120372921
但他的这个lite主要不是研究repvgg的,是做移动端的,但是里面加了这个repvgg
他的代码链接:https://github.com/ppogg/YOLOv5-Lite/tree/ca7ed7ca0bb578fe6e5eaa777e84f661ad457e49
我是看了看他的代码,然后把关于repvgg的地方加到了自己的yolov5-7.0中(但后续我没用seg去做训练,就正常训练)
后续我还试着把rep-vgg官方的预训练模型的backbone移植到了自己的yolov5-repvgg训练了50epoch的pt中,效果不好。
理论知识:
我先看了个原作者写的帖子:结构重参数化:利用参数转换解耦训练和推理结构,大致看了看
后来去看了原作者的一个视频:丁霄汉:结构重参数化是怎么来的【深度学习】【直播回放】
主要是讲作者写这个的一个思路,和为什么写这个,有助于理解
又看了个我比较喜欢的up主的讲解:RepVGG网络讲解
还有他的csdn:RepVGG网络简介
(二)YOLOv5改进之结合RepVGG
1.配置common.py文件
# build repvgg block# -----------------------------
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))return result
#RepVGGBlock
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups =groups
self.in_channels = in_channels
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.SiLU()# self.nonlinearity = nn.ReLU()if use_se:
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else:
self.se = nn.Identity()if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels)if out_channels == in_channels and stride ==1else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=padding_11, groups=groups)# print('RepVGG Block, identity = ', self.rbr_identity)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return0, 0if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim,3,3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim,1,1] =1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std =(running_var + eps).sqrt()
t =(gamma / std).reshape(-1,1,1,1)
return kernel * t, beta - running_mean * gamma / std
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))if self.rbr_identity is None:
id_out =0
else:
id_out = self.rbr_identity(inputs)return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
def fusevggforward(self, x):
return self.nonlinearity(self.rbr_dense(x))
我看网上有些帖子的代码,加到自己工程里有问题,是因为缺conv_bv代码块。自己加上就行了,我这个上面是加进去的。
2.配置yolo.py文件
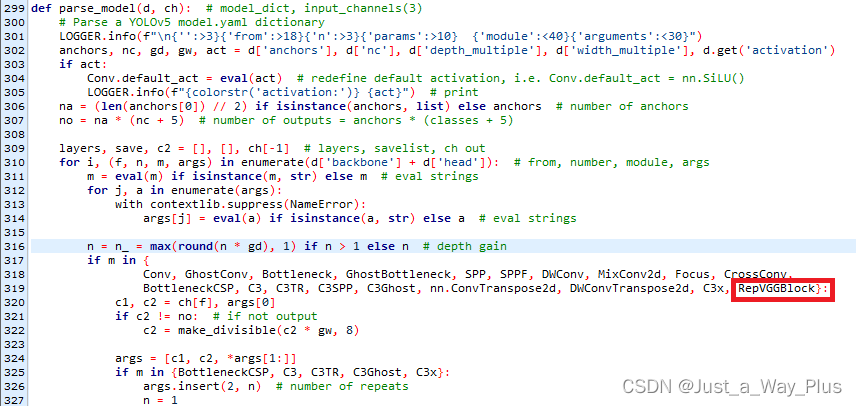
3.配置yolov5_RepVGG.yaml文件
我新建了一个yolov5s-repvgg.yaml
# YOLOv5 馃殌 by Ultralytics, GPL-3.0 license# Parameters
nc: 4# number of classes
depth_multiple: 1# model depth multiple
width_multiple: 1# layer channel multiple
anchors:
- [10,13, 16,30, 33,23]# P3/8
- [30,61, 62,45, 59,119]# P4/16
- [116,90, 156,198, 373,326]# P5/32# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args][[-1, 1, RepVGGBlock, [64, 3, 2]], # 0-P1/2[-1, 1, RepVGGBlock, [64, 3, 2]], # 1-P2/4[-1, 1, RepVGGBlock, [64, 3, 1]], # 2-P2/4[-1, 1, RepVGGBlock, [128, 3, 2]], # 3-P3/8[-1, 3, RepVGGBlock, [128, 3, 1]],
[-1, 1, RepVGGBlock, [256, 3, 2]], # 5-P4/16[-1, 13, RepVGGBlock, [256, 3, 1]],
[-1, 1, RepVGGBlock, [512, 3, 2]], # 7-P4/16]# YOLOv5 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 1, C3, [256, False]], # 11[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 1, C3, [128, False]], # 15 (P3/8-small)[-1, 1, Conv, [128, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P4[-1, 1, C3, [256, False]], # 18 (P4/16-medium)[-1, 1, Conv, [256, 3, 2]],
[[-1, 8], 1, Concat, [1]], # cat head P5[-1, 1, C3, [512, False]], # 21 (P5/32-large)[[15, 18, 21], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
至于number那里为什么是1,1,1,1,3,1,13,1
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
是为了和repvgg原网络的A1结构保持一致,方便后续做一个预训练模型的迁移
训练结果
开始训练
python train.py --weights ./weights/yolov5s.pt --data ./data/coco-repvgg.yaml --epochs50--img640--cfg models/yolov5s-repvgg.yaml --name yolov5s-repvgg
这里加不加预训练都行,但是我的实验结果发现,加了预训练模型,会导致训练50epoch,没有原来的yolov5s训练50epoch以后的结果好。
但是yolov5s与改进的yolov5-repvgg俩模型,都不加预训练模型,一起训50,yolov5-repvgg的效果是要更好的!也就是很有效其实。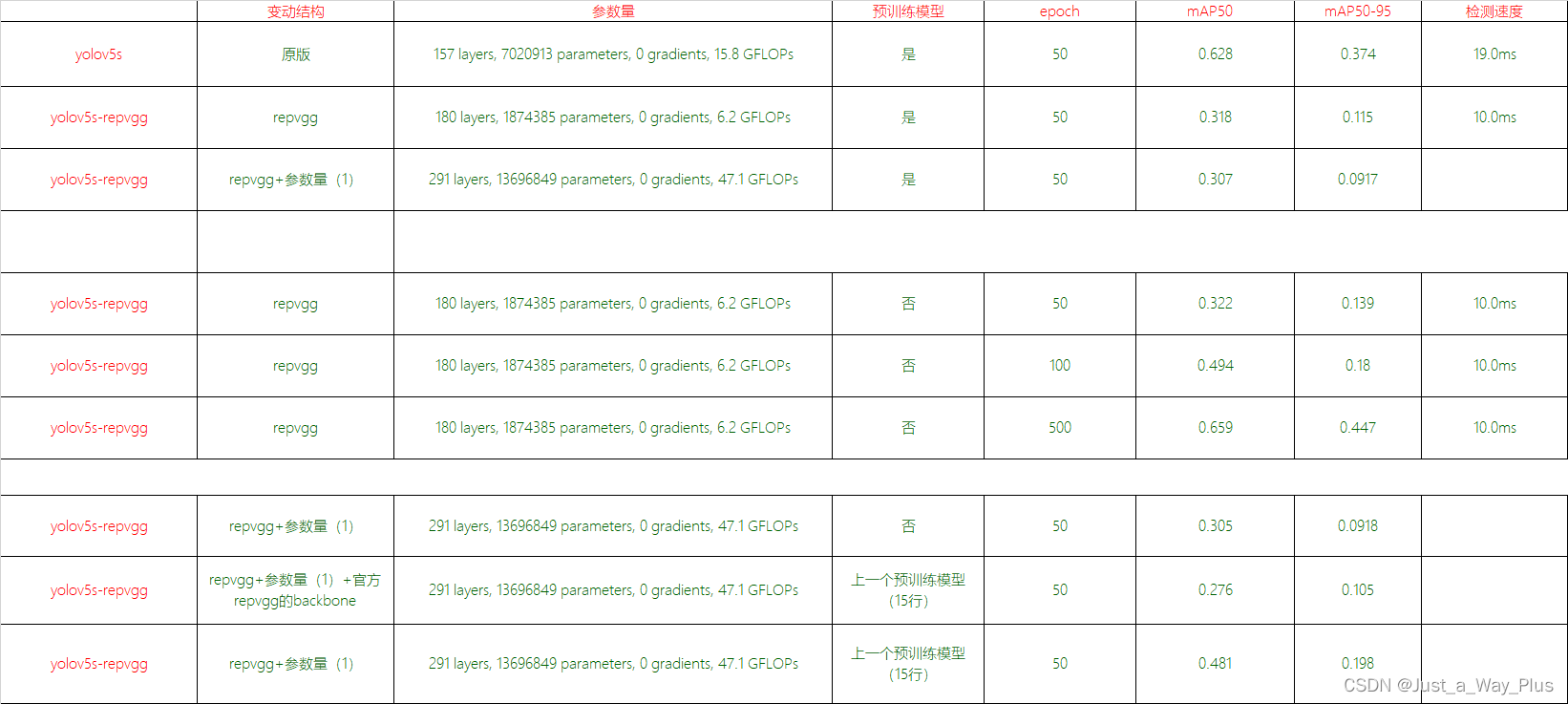
后面迁移repvgg预训练模型的代码,后续也会发出来。
版权归原作者 Just_a_Way_Plus 所有, 如有侵权,请联系我们删除。