
大家好,我是K&D,一名10年以上大数据架构&研发经验从业者,目前主要从事云原生大数据方向设计,擅长云原生技术、数据架构、数据平台构建、大数据组件性能调优
问题现象
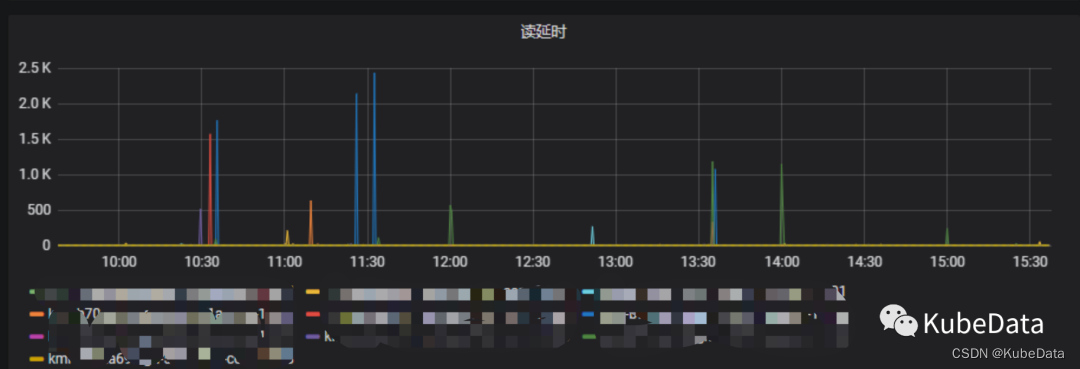
查看监控,业务请求量正常,但是server端毛刺严重
近期在HBase集群中经常会收到写入延迟过高的相关告警信息,同时业务也反馈程序会有一些写入阻塞问题,查看监控图表,发现业务的写入请求是正常的,但是HBase Server段出现了毛刺现象,而且还比较严重,如图:

问题排查
首先查看看regionserver日志:
WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 23062msGC pool 'ParNew' had collection(s): count=1 time=9320ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=13999ms
从日志中可以看到有长时间的GC暂停导致的,同时查看节点的JVM参数,发现内存并不是很大只有12G内存,GC的工作应该很快就能完成才对!
于是,查看gc日志之后,发现有大量的FullGC日志:
2023-12-05T10:00:23.257+0800: 141226.815: [GC (Allocation Failure)
2023-12-05T10:00:23.267+0800: : [ParNew (promotion failed): 2263488K->2263488K(2263488K), 9.3205132 secs]
2023-12-05T10:00:23.277+0800: 141236.136: [CMS CMS: abort preclean due to time
2023-12-05T10:00:23.299+0800: 141236.157: [CMS-concurrent-abortable-preclean: 1.896/13.897 secs] [Times: user=37.36 sys=0.88, real=13.90 secs] (concurrent mode failure): 9169923K->6488842K(10067968K), 13.9993758 secs] 11018174K->6488842K(12331456K), [Metaspace: 57884K->57884K(1105920K)], 23.3212375 secs] [Times: user=26.40 sys=0.50, real=23.32 secs]
从上面日志中可以看到从young GC向 Old GC清理的过程失败了,原因是Old 区虽然有空间,但是都是碎片化的,CMS回退到单线程复制整理算法,从而引发了长时间的暂停。
GC相关内容简单概述
Java内存分配和回收的机制概括来说,就是:分代分配,分代回收。对象将根据存活的时间被分为:年轻代(Young Generation)、年老代(Old Generation)、永久代(Permanent Generation,也就是方法区)
年轻代(Young Generation)
对象被创建时,内存的分配首先发生在年轻代,大部分的对象在创建后很快就不再使用,因此很快变得不可达,于是被年轻代的GC机制清理掉,这个GC机制被称为Minor GC或叫Young GC。注意,Minor GC并不代表年轻代内存不足,它事实上只表示在Eden区上的GC
年老代(Old Generation)
对象如果在年轻代存活了足够长的时间而没有被清理掉(即在几次Young GC后存活了下来),则会被复制到年老代,年老代的空间一般比年轻代大,能存放更多的对象,在年老代上发生的GC次数也比年轻代少。当老年代内存不足时,将执行Major GC,也叫 Full GC。
解决方式
调整老年代在gc时伴随整理,先保守的调整为每4次整理一次old区,解决碎片问题。
将CMSFullGCsBeforeCompaction(设置多少次FullGC后对内存空间进行整理),设置为一个保守值,改为每4次整理一次Old区,解决碎片问题:
jvm参数调整:
-XX:ParallelGCThreads=8
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=4
-XX:MaxTenuringThreshold 6 =>15
调整后,jvm对象晋升失败大大减少,偶尔仍会发生,继续调整更严格的老年代整理:
去掉 -XX:CMSFullGCsBeforeCompaction=4 使每次cms都伴随整理。
在跟踪查看一段时间之后,在gc log中没有发生长时gc问题。
总结
组件服务调优是一项比较艰难的事情,需要很强的意志力才能去排查各项指标,各项参数去对比,希望通过此文能分享出问题排查的基本思路
- 查日志,看日志详情以及报错信息
- 根据信息回顾底层基本原理是什么?那个地方可能会出现类似错误
- 查看相关参数说明,特别是布尔类型参数
- 试着调整参数看看效果

版权归原作者 KubeData 所有, 如有侵权,请联系我们删除。