
Prompt Space Optimizing Few-shot Reasoning Success with Large Language Models
https://arxiv.org/abs/2306.03799
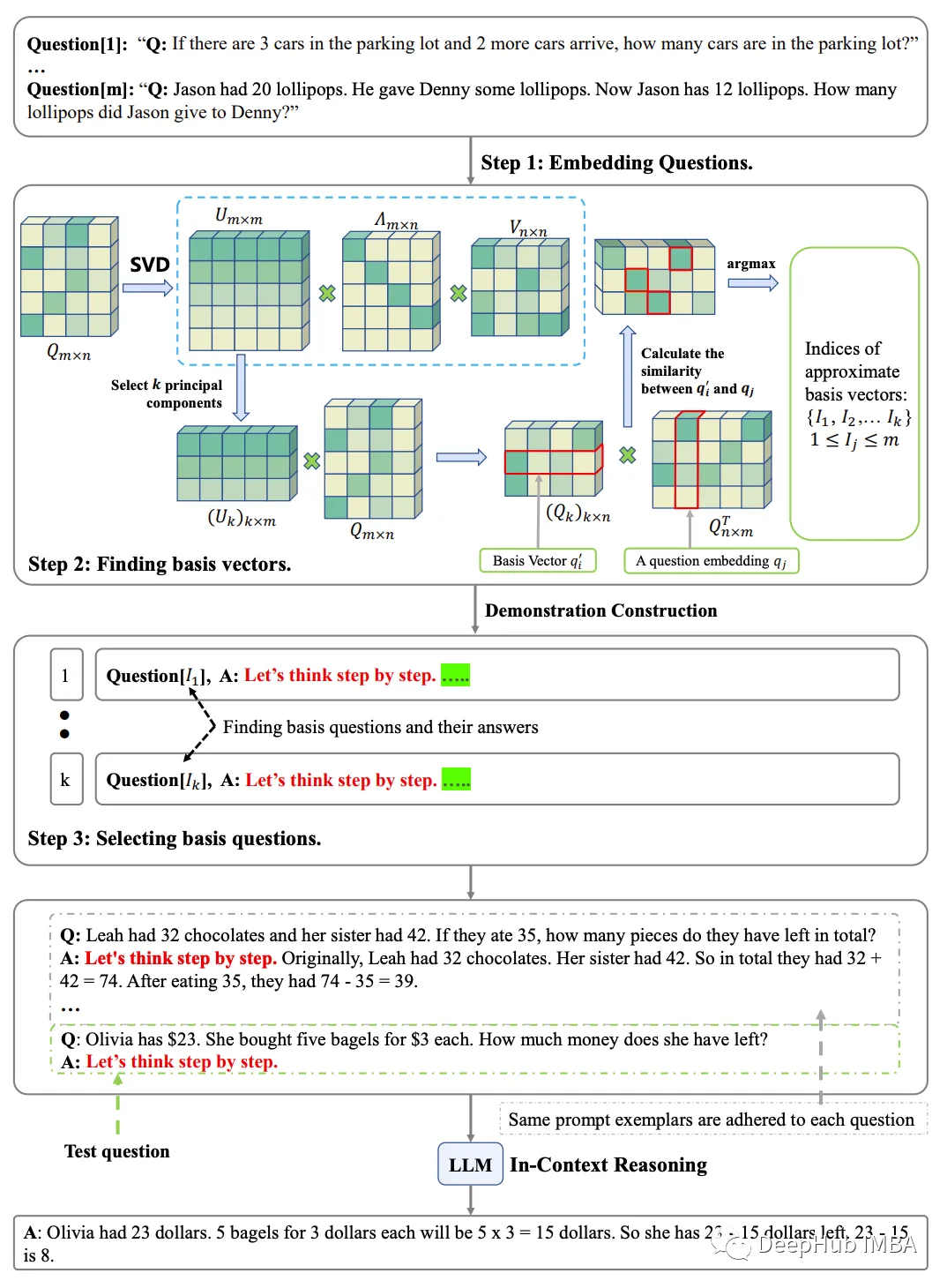
Prompt engineering 是通过提供明确和具体的指令来增强大型语言模型(llm)能力的基本技术。它使LLM能够在各种任务中脱颖而出,例如算术推理、问题回答、摘要、关系提取、机器翻译和情感分析。研究人员一直在积极探索不同的提示工程策略,如思维链(CoT)、零样本思维链(Zero-CoT)和情境学习(In-context learning)。但是一个尚未解决的问题是,目前的方法缺乏确定最佳提示的坚实理论基础。为了解决提示工程中的这一问题,论文提出了一种新的、有效的方法——提示空间。
ESL-SNNs: An Evolutionary Structure Learning Strategy for Spiking Neural Networks
https://arxiv.org/abs/2306.03693
减少SNN模型大小和计算,同时在训练过程中通过修剪和再生连接的进化过程保持准确性。
在推理过程中,Spiking neural networks在功耗和事件驱动特性方面表现出显著的优势。为了充分利用低功耗的优势,进一步提高这些模型的效率,论文探索了在训练后寻找冗余连接的稀疏snn的剪枝方法。在人脑中,神经网络的重新布线过程是高度动态的,而突触连接在大脑发育过程中保持相对稀疏。受此启发,轮文提出了一种高效的SNN进化结构学习(ESL)框架,命名为ESL-SNN,用于从头开始实现稀疏SNN的训练。

Segment Anything in High Quality
https://arxiv.org/abs/2306.01567
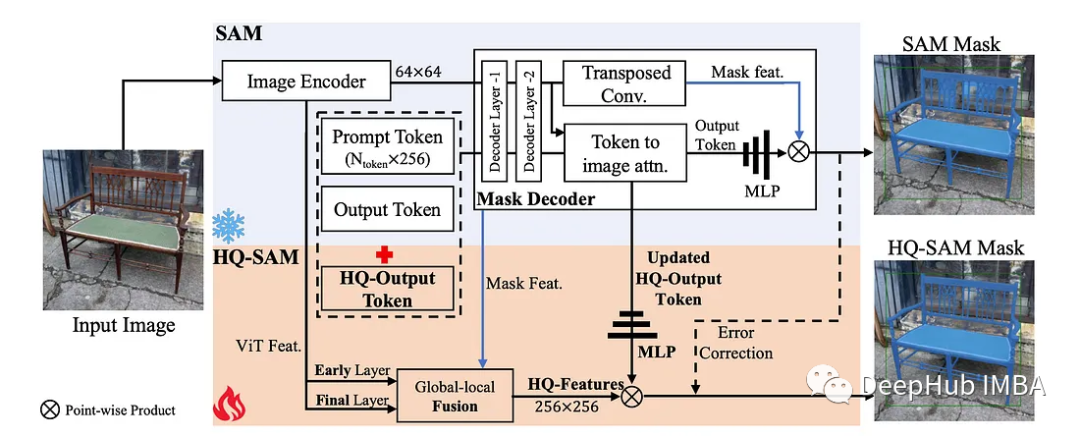
用掩码校正对SAM进行修改可以提高性能,特别是在边缘情况下。
SAM代表了一个巨大的飞跃,尽管使用了11亿个掩码进行训练,但SAM的掩码预测质量在许多情况下都存在不足,特别是在处理结构复杂的物体时。论文精心设计重用并保留了SAM的预训练模型权重,同时只引入了最小的额外参数和计算。
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
https://arxiv.org/abs/2306.03078
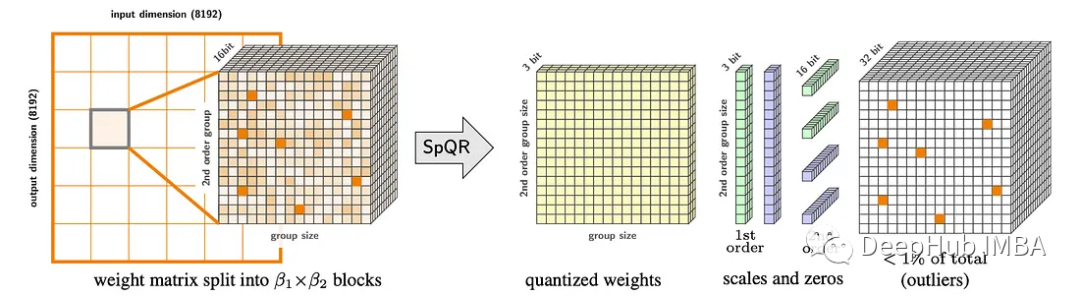
通过量化将llm压缩到每个Int4,可以适用于笔记本电脑和移动电话等内存有限的设备,从而实现个性化使用。但是量化到每个参数3-4位通常会导致中等到高的精度损失,特别是对于1-10B参数范围内的较小模型。为了解决这个准确性问题,论文引入了稀疏量化表示(SpQR),这是一种新的压缩格式和量化技术,首次实现了llm跨模型尺度的近无损压缩,同时达到了与以前方法相似的压缩水平。SpQR的工作原理是识别和隔离导致特别大的量化误差的异常权重,并以更高的精度存储它们,同时将所有其他权重压缩到3-4位。
Tracking Everything Everywhere All at Once
https://arxiv.org/abs/2306.05422
从视频序列中估计密集和远距离运动的测试时间优化方法。
先前的光流或粒子视频跟踪算法通常在有限的时间窗口内运行,难以通过遮挡进行跟踪并保持估计运动轨迹的全局一致性。论文提出了一种完整且全局一致的运动表示,称为OmniMotion,它允许对视频中的每个像素进行准确的全长运动估计。OmniMotion使用准3d规范体积表示视频,并通过本地和规范空间之间的双射执行逐像素跟踪

Leveraging Large Language Models for Scalable Vector Graphics-Driven Image Understanding
https://arxiv.org/abs/2306.06094
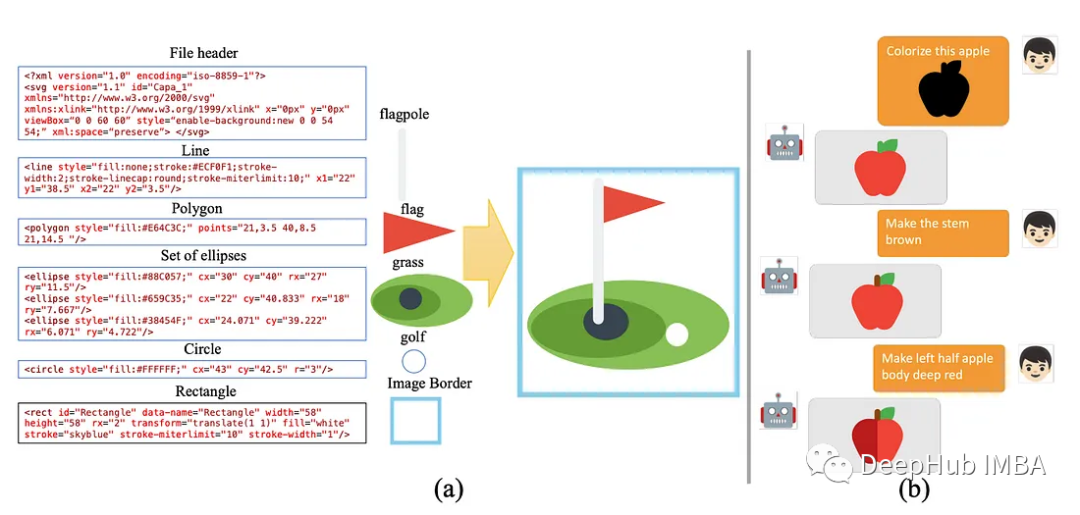
大型语言模型(llm)在自然语言理解和生成方面取得了重大进展。但是它们在计算机视觉方面的潜力在很大程度上仍未被探索。论文介绍了一种新的探索性方法,使llm能够使用可缩放矢量图形(SVG)格式处理图像。通过利用基于xml的SVG表示的文本描述而不是光栅图像,目标是弥合视觉和文本模式之间的差距,允许llm直接理解和操作图像,而不需要参数化的视觉组件
TrajectoryFormer: 3D Object Tracking Transformer with Predictive Trajectory Hypotheses
https://arxiv.org/abs/2306.05888
三维MOT技术在常用的检测跟踪模式下取得了重要进展。但是这些方法仅使用当前帧的检测盒来获得轨迹盒关联结果,这使得跟踪器无法恢复检测器错过的目标。论文提出了一种新的基于点云的3D MOT框架——TrajectoryFormer。

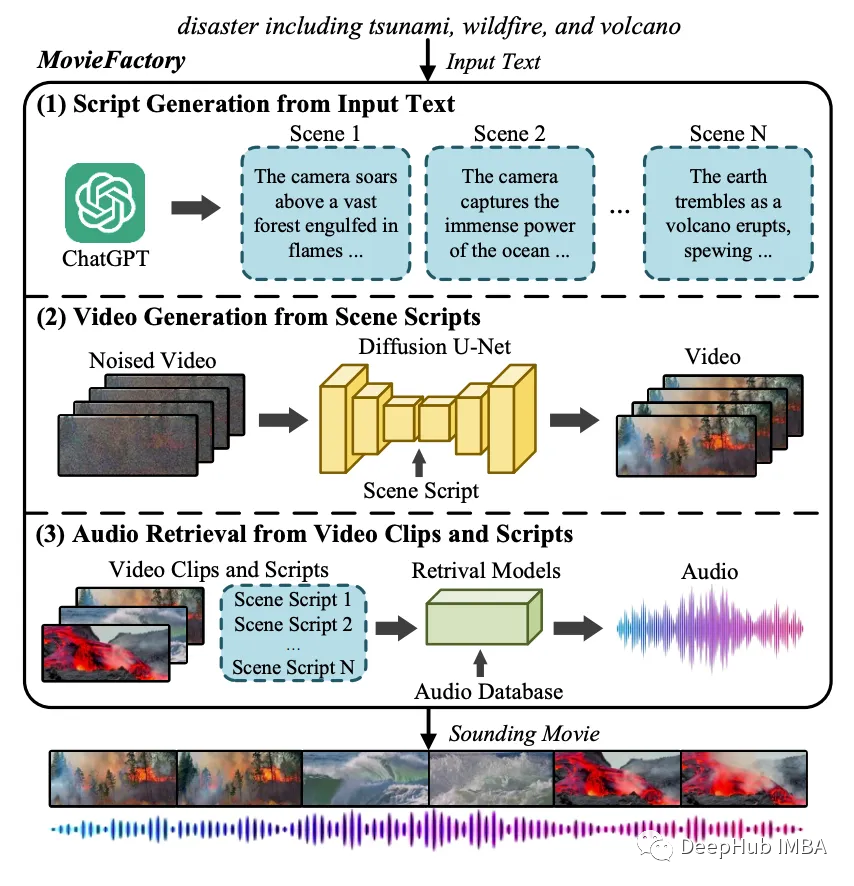
MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
https://arxiv.org/abs/2306.07257
MovieFactory是一个强大的框架,可以根据自然语言的需求生成电影图片(3072×1280),电影风格(多场景)和多模态(声音)电影。作为所知的第一个完全自动化的电影生成模型,论文的方法使用户能够使用简单的文本输入创建具有流畅过渡的迷人电影,超越了现有的制作无声视频的方法,这些无声视频仅限于一个中等质量的场景。为了促进这种独特的功能,利用ChatGPT将用户提供的文本扩展为用于电影生成的详细顺序脚本。然后通过视觉生成和音频检索使脚本在视觉和听觉上栩栩如生。
DEYOv2: Rank Feature with Greedy Matching for End-to-End Object Detection
https://arxiv.org/abs/2306.09165
通过改进对Ground Truth匹配的预测来改进用于目标检测任务的transformer。
提出了一种新的目标检测器DEYOv2,它是第一代DEYO(带有YOLO的DETR)模型的改进版本。与其前身类似,DEYOv2采用渐进式推理方法来加速模型训练并提高性能。论文深入研究了一对一匹配在优化中的局限性,并提出了有效的解决方案,如Rank Feature和Greedy matching。这种方法使DEYOv2的第三阶段能够在不需要NMS的情况下最大限度地从第一阶段和第二阶段获取信息,实现端到端优化。
