
存内计算:提高计算性能和能效的新技术
传统的计算机架构是将数据存储在存储器中,然后将数据传输到计算单元进行处理。这种架构存在一个性能瓶颈,即数据传输延迟。存内计算通过将计算单元集成到存储器中,消除了数据传输延迟,从而提高了系统性能。
什么是存内计算
存内计算(Processing-In-Memory)是指在存储器内部直接进行数据处理的技术。存内计算的实现方式主要有两种:
- 模拟存内计算:这种方法利用存储器单元的模拟特性进行计算。例如,利用存储器单元的阻值或电容进行矩阵乘法。模拟存内计算具有高能效的优势,但精度较低。
- 数字存内计算:这种方法利用存储器单元的数字特性进行计算。例如,利用存储器单元进行加法、乘法等逻辑运算。数字存内计算具有高精度的优势,但能耗较高。

存内计算的优点
存内计算具有以下优点:
- 提高性能:存内计算消除了数据传输延迟,从而提高了系统性能。
- 降低功耗:存内计算减少了数据传输量,从而降低了系统功耗。
- 增加灵活性:存内计算将计算和存储融合在一起,增加了系统的灵活性。
存内计算核心
存内计算(Computing in Memory)是指将计算单元直接嵌入到存储器中,顾名思义就是把计算单元嵌入到内存当中,通常计算机运行的冯·诺依曼体系包括存储单元和计算单元两部分。在本质上消除不必要的数据搬移的延迟和功耗,从而消除了传统的冯·诺依曼架构的瓶颈,打破存储墙。据悉,存内计算特别适用于需要大数据处理的领域,比如云计算、人工智能等领域,最重要的一点是存内计算是基于存储介质的计算架构,而且存内计算是一种新型存储架构且轻松打破传统存储架构的瓶颈。
根据存储介质的不同,存内计算芯片可分为基于传统存储器和基于新型非易失性存储器两种。传统存储器包括SRAM, DRAM和Flash等;新型非易失性存储器包括ReRAM、PCM、FeFET、MRAM等。其中,距离产业化较近的是基于NOR Flash和基于SRAM的存内计算芯片。虽然基于各类存储介质的存算一体芯片研究百花齐放,但是各自在大规模产业化之前都仍然面临一些问题和挑战。存算一体技术在产业界的进展同样十分迅速,国内外多家企业在积极研发,例如我国台湾的台积电,韩国三星、日本东芝、美国Mythic,国内的知存科技等。
但是当前最接近产业化的主要是台积电、Mythic和知存科技。从2019年至今,台积电得益于其强大的工艺能力,已基于SRAM与ReRAM发表了一系列存算一体芯片研究成果,具备量产代工能力。Mythic已于2021年推出基于NOR Flash的存内计算量产芯片M1076,可支持80 MB神经网络权重,单个芯片算力达到25 TOPS,主要面向边缘侧智能场景。国内的知存科技于2021年发布基于NOR Flash的存内计算芯片WTM2101,是率先量产商用的全球首颗存内计算SoC芯片,已经应用于百万级智能终端设备。

** 内存计算架构与技术**
内存计算技术是一个宏观的概念, 是将计算能力集成到内存中的技术统称. 集成了内存计算技 术的计算机系统不仅能直接在内存中执行部分计算, 还能支持传统以 CPU 为核心的应用程序的执行. 区别于内存计算, 存算一体芯片将存储与计算相结合, 是一种 ASIC (application-specific integrated circuit) 芯片, 常用于嵌入式设备中, 针对一类特定的应用设计, 不能处理其他应用程序 . 内存计算包括两大类: 近数据计算和存内计算. 两者的关系如图所示, 它们在形式上不同, 但是在特 定场景下可以融合设计. 近数据计算和存内计算的最大区别就是: 近数据计算的计算单元和存储单元
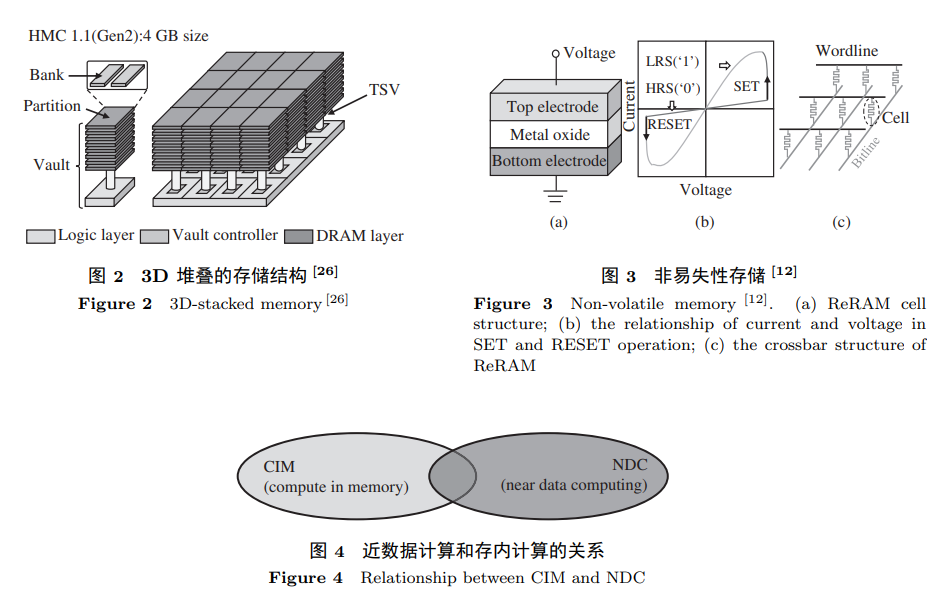
存内计算的应用
存内计算具有广泛的应用前景,包括:
- 人工智能:存内计算可以提高人工智能算法的性能和能效。
- 大数据处理:存内计算可以提高大数据处理的速度和效率。
- 物联网:存内计算可以降低物联网设备的功耗。
存内计算的挑战
存内计算仍处于发展阶段,面临着一些挑战,例如:
- 器件成熟度:存内计算需要使用新型存储器器件,这些器件的成熟度还不够高。
- 软件支持:存内计算需要相应的软件支持,目前还不够完善。
硬件寿命问题
NVM 的寿命有限, 例如 PCM 的 SLC (single level cell, 一个 cell 只能存 0 或 1, 即一个比特位) 的 寿命只有 107 ∼ 108 , ReRAM 的 SLC 的寿命只有 107 ∼ 109 . MLC (multi-level cell, 一个 cell 能存多个比特位) 的寿命问题更加严重, 通常只有 104 ∼ 105 次写, 甚至更低. 对于传统 NVM 存储, 磨 损均衡是延长寿命的有效方法. 磨损均衡算法通过每隔一段时间改变逻辑地址到物理地址的映射, 使 得写操作在整个 NVM 中均衡. 然而这种方法在基于 NVM 的存内计算中并不适用, 因为存储于 NVM 中的数据还直接用作计算. 如果直接使用传统的磨损均衡算法交换数据所存储的位置, 计算结果将是 错误的. 该问题由器件相关问题引起, 除了选择和配置合适的器件外, 还可以通过上层设计来缓解, 例 如应用中算法的设计和内存控制器的设计等. ISAAC [40] 通过在片上加 eDRAM 减少对 NVM 的写. IBM 的研究人员 [45] 通过用 CMOS+PCM 做一个 cell 的方式, 使寿命的 CMOS 单元承受频繁的更新操作. Long-live-time [60] 提出了一种针对神 经网络训练的 CIM 硬件寿命延长方法, 通过改变神经网络权值更新方法 (每次选误差最大的行更新 而不是全部更新), 再结合行粒度的磨损均衡算法, 延长基于 NVM 的存内计算硬件的寿命. 我们正在 进行的工作将神经网络和 NVM 的特点综合考虑, 从而延长基于 NVM 的存内计算硬件寿命. 针对其 余应用的 NVM 存内计算硬件寿命的延长方法仍待探究。
可靠性问题
NVM 写出错问题以及外围电路对输出模拟域电流转成电信号产生误差的问题使基于 NVM 的存 内计算可靠性不佳. NVM 的 cell 会因为写电流过高或寿命已到而产生 stuck-at fault (阻值停留在某 个固定值不可改变). 传统存储中, 可以将发生错误的 cell 值存到别的物理位置, 然后改变原逻辑地址 到物理地址的映射来容这种错误. 而这种方式在基于 NVM 的存内计算中并不适用, 存储在存内计算 的 NVM 中的数据还要直接用作计算, 数据之间的相对物理位置不能被改变, 否则计算结果会出错. 与寿命问题相似, 可靠性问题也是由器件相关问题引起的, 除了选择合适的器件外, 还可以通过上层设 计来缓解. Xia 等[61] 利用神经网络中权值的稀疏性 (一些位置的权值为 0) 来容存内计算 NVM 上 stuck-at-0 的硬件错误. Xia 等 [62] 还通过利用存正负值的一对存内计算 NVM 阵列来互相容错. Liu 等 [63] 提出 分析识别出神经网络中重要的部分, 把此部分放到可靠性高的存内计算硬件上去做. 我们正在进行的 工作将采取更加灵活的方式, 综合利用神经网络和 NVM 本身的特点来容更多类型的 stuck-at 错误. 由于外围电路的误差而造成的可靠性降低问题仍待解决

全球首个存内计算社区创立,涵盖最丰富的存内计算内容,以存内计算技术为核心,绝无仅有存内技术开源内容,囊括云/边/端侧商业化应用解析以及新技术趋势洞察等, 邀请业内大咖定期举办线下存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。
传送门:https://bbs.csdn.net/forums/computinginmemory?category=10003
社区最新活动存内计算大使招募中,享受社区资源倾斜,打造属于你的个人品牌,点击下方一键加入。
https://bbs.csdn.net/topics/617915760](https://bbs.csdn.net/topics/617915760
** 首个存内计算开发者社区,0门槛新人加入,发文享积分兑超值礼品;**
成为存内计算大使,享受资源支持与激励,打造亮眼个人品牌,共同引流存内计算潮流。

结语
存内计算是一种具有广阔应用前景的新技术。随着技术的进步,存内计算将在未来得到更广泛的应用。
存内计算的未来
随着存储器器件技术的不断发展,存内计算将变得更加成熟。在未来,存内计算将成为计算机架构的重要发展方向,它将为提高计算性能和能效提供新的途径。
以下是一些存内计算在未来可能的应用:
- 人工智能:存内计算可以提高人工智能算法的性能和能效,从而推动人工智能的普及和应用。
- 大数据处理:存内计算可以提高大数据处理的速度和效率,从而加速大数据分析和挖掘。
- 物联网:存内计算可以降低物联网设备的功耗,从而延长物联网设备的续航时间。
我们期待着存内计算在未来的应用,它将为我们的生活带来更多便利和改变。
参考文献;
《中国科学》杂志社:内存计算研究进展
版权归原作者 一见已难忘的申公豹 所有, 如有侵权,请联系我们删除。