
1. 基本概念
1.1 Row & Column
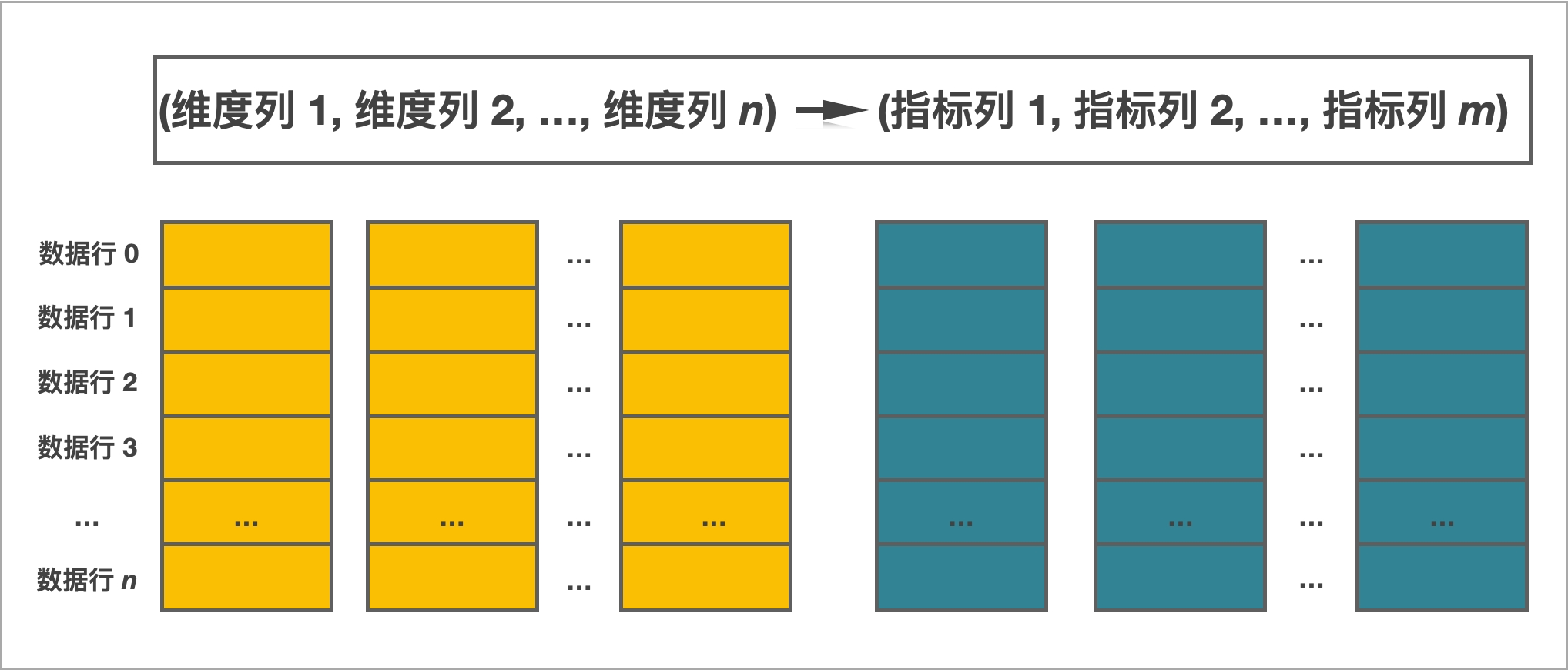
一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
⚫ 在默认的数据模型中,Column 只分为排序列和非排序列。存储引擎会按照排序列对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找。
⚫ 而在聚合模型中,Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key 列相同的行,会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。
1.2 Partition & Tablet
在 Doris 的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步的按照 Hash 的方式分桶,分桶的规则是要找用户指定的分桶列的值进行 Hash 后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
⚫ Tablet 之间的数据是没有交集的,独立存储的。Tablet 也是数据移动、复制等操作的最小物理存储单元。
⚫ Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
2. OLAP表定义
建表的基本语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS][database.]table_name
(column_definition1[, column_definition2, ...][, index_definition1[, index_definition2, ...]])[ENGINE =[olap|mysql|elasticsearch|hive|iceberg|hudi|jdbc]][key_desc][COMMENT "table comment"][partition_desc][distribution_desc][rollup_index][ORDER BY (column_definition1,...)][PROPERTIES ("key"="value", ...)][BROKER PROPERTIES ("key"="value", ...)]
参数说明
2.1 表分为内部表和外部表
默认未内部表,3.0版本开始集成外部数据建议使用catalog,外部表的建表方式将被弃用
2.2 列定义
语法:
col_name col_type [agg_type][NULL | NOT NULL][DEFAULT "default_value"][AUTO_INCREMENT][AS generation_expr]
col_name:列名称
注意,在一般情况下,不能直接创建以以 __op 或 __row 开头命名的列,因为此类列名被 StarRocks 保留用于特殊目的,创建这样的列可能导致未知行为。如需创建这样的列,必须将 FE 动态参数 allow_system_reserved_names 设置为 TRUE。
col_type:列数据类型
之前博文数据类型
agg_type:聚合类型,如果不指定,则该列为 key 列。否则,该列为 value 列。
支持的聚合类型如下:
- SUM、MAX、MIN、REPLACE
- HLL_UNION(仅用于 HLL列,为 HLL 独有的聚合方式)。
- BITMAP_UNION(仅用于 BITMAP 列,为 BITMAP 独有的聚合方式)。
- REPLACE_IF_NOT_NULL:这个聚合类型的含义是当且仅当新导入数据是非 NULL 值时会发生替换行为。如果新导入的数据是 NULL,那么 StarRocks 仍然会保留原值。
注意:
BITMAP_UNION 聚合类型列在导入时的原始数据类型必须是 TINYINT, SMALLINT, INT, BIGINT。
如果在建表时 REPLACE_IF_NOT_NULL 列指定了 NOT NULL,那么 StarRocks 仍然会将其转化 NULL,不会向用户报错。用户可以借助这个类型完成「部分列导入」的功能。 该类型只对聚合模型有用 (key_desc 的 type 为 AGGREGATE KEY)。
NULL | NOT NULL:列数据是否允许为 NULL。其中明细模型、聚合模型和更新模型表中所有列都默认指定 NULL。主键模型表的指标列默认指定 NULL,维度列默认指定 NOT NULL。如源数据文件中存在 NULL 值,可以用 \N 来表示,导入时 StarRocks 会将其解析为 NULL。
DEFAULT “default_value”:列数据的默认值。导入数据时,如果该列对应的源数据文件中的字段为空,则自动填充 DEFAULT 关键字中指定的默认值。支持以下三种指定方式:
DEFAULT current_timestamp:默认值为当前时间。参见 current_timestamp() 。
DEFAULT <默认值>:默认值为指定类型的值。例如,列类型为 VARCHAR,即可指定默认值为 DEFAULT “beijing”。当前不支持指定 ARRAY、BITMAP、JSON、HLL 和 BOOLEAN 类型为默认值。
DEFAULT (<表达式>):默认值为指定函数返回的结果。目前仅支持 uuid() 和 uuid_numeric() 表达式。
AUTO_INCREMENT:指定自增列。自增列的数据类型只支持 BIGINT,自增 ID 从 1 开始增加,自增步长为 1。有关自增列的详细说明,请参见 AUTO_INCREMENT。自 v3.0,StarRocks 支持该功能。
AS generation_expr:指定生成列和其使用的表达式。生成列用于预先计算并存储表达式的结果,可以加速包含复杂表达式的查询。自 v3.1,StarRocks 支持该功能。
2.3 键的描述
语法:
`key_type(k1[,k2 ...])`
数据按照指定的 key 列进行排序,且根据不同的 key_type 具有不同特性。 key_type 支持以下类型:
AGGREGATE KEY: key 列相同的记录,value 列按照指定的聚合类型进行聚合,适合报表、多维分析等业务场景。
UNIQUE KEY/PRIMARY KEY: key 列相同的记录,value 列按导入顺序进行覆盖,适合按 key 列进行增删改查的点查询 (point query) 业务。
DUPLICATE KEY: key 列相同的记录,同时存在于 StarRocks 中,适合存储明细数据或者数据无聚合特性的业务场景。
默认为 DUPLICATE KEY,数据按 key 列做排序。
除 AGGREGATE KEY 外,其他 key_type 在建表时,value 列不需要指定聚合类型 (agg_type)。
2.4 分布式描述
支持随机分桶(Random bucketing)和哈希分桶(Hash bucketing)。如果不指定分桶信息,则 StarRocks 默认使用随机分桶且自动设置分桶数量。
DISTRIBUTED BY RANDOM BUCKETS <num>
不支持主键模型表、更新模型表和聚合表。
不支持指定 Colocation Group。
不支持 Spark Load。
自 2.5.7 版本起,建表时无需手动指定分桶数量,StarRocks 自动设置分桶数量。
DISTRIBUTED BY HASH (k1[,k2 ...])[BUCKETS num]
如果查询比较复杂,则建议选择高基数的列为分桶键,保证数据在各个分桶中尽量均衡,提高集群资源利用率。
如果查询比较简单,则建议选择经常作为查询条件的列为分桶键,提高查询效率。 并且,如果数据倾斜情况严重,您还可以使用多个列作为数据的分桶键,但是建议不超过 3 个列。
建表时,必须指定分桶键。
作为分桶键的列,该列的值不支持更新。
分桶键指定后不支持修改。
自 2.5.7 版本起,建表时无需手动指定分桶数量,StarRocks 自动设置分桶数量。
2.5 PROPERTIES
设置数据的初始存储介质、自动降冷时间和副本数
如果 ENGINE 类型为 OLAP,可以在属性 properties 中设置该表数据的初始存储介质(storage_medium)、自动降冷时间(storage_cooldown_time)或者时间间隔(storage_cooldown_ttl)和副本数(replication_num)。
属性生效范围:当表为单分区表时,以上属性为表的属性。当表划分成多个分区时,以上属性属于每一个分区。并且如果希望不同分区有不同属性,则建表后可以执行 ALTER TABLE … ADD PARTITION 或 ALTER TABLE … MODIFY PARTITION。
设置数据的初始存储介质、自动降冷时间
PROPERTIES ("storage_medium"="[SSD|HDD]",
{"storage_cooldown_ttl"="<num> { YEAR | MONTH | DAY | HOUR } "|"storage_cooldown_time"="yyyy-MM-dd HH:mm:ss"})
目前 StarRocks 提供如下数据自动降冷的相关参数,对比如下:
storage_cooldown_ttl:表的属性,指定该表中分区自动降冷时间间隔,由系统自动降冷表中到达时间点(时间间隔+分区时间上界)的分区。并且表按照分区粒度自动降冷,更加灵活。
storage_cooldown_time:表的属性,指定该表的自动降冷时间点(绝对时间)。建表后也可以为不同分区配置不同时间点。
storage_cooldown_second:FE 静态参数,指定集群范围内所有表的自动降冷时延。
表属性 storage_cooldown_ttl 或 storage_cooldown_time 比 FE 静态参数 storage_cooldown_second 优先级高。
配置以上参数时,必须指定 "storage_medium = “SSD”。
不配置以上参数时,则不进行自动降冷。
执行 SHOW PARTITIONS FROM <table_name> 查看各个分区的自动降冷时间点。
不支持表达式分区和 List 分区。
不支持分区列为非日期类型。
不支持多个分区列。
不支持主键模型表。
设置分区 Tablet 副本数
replication_num:分区 Tablet 副本数。默认为 3。
PROPERTIES ("replication_num"="<num>")
创建表时为列添加 bloom filter 索引
如果 Engine 类型为 olap, 可以指定某列使用 bloom filter 索引。bloom filter 索引使用时有如下限制:
主键模型和明细模型中所有列都可以创建 Bloom filter 索引;聚合模型和更新模型中,只有维度列(即 Key 列)支持创建 Bloom filter 索引。
不支持为 TINYINT、FLOAT、DOUBLE 和 DECIMAL 类型的列创建 Bloom filter 索引。
Bloom filter 索引只能提高查询条件为 in 和 = 的查询效率,值越分散效果越好。
PROPERTIES ("bloom_filter_columns"="k1, k2, k3")
添加属性支持 Colocate Join
如果希望使用 Colocate Join 特性,需要在 properties 中指定:
PROPERTIES ("colocate_with"="table1")
设置动态分区
如果希望使用动态分区特性,需要在 properties 中指定如下参数:
PROPERTIES ("dynamic_partition.enable"="true|false",
"dynamic_partition.time_unit"="DAY|WEEK|MONTH",
"dynamic_partition.start"="${integer_value}",
"dynamic_partition.end"="${integer_value}",
"dynamic_partition.prefix"="${string_value}",
"dynamic_partition.buckets"="${integer_value}")
设置随机分桶表中分桶大小
自 3.2 版本起,对于随机分桶的表,您可以在建表时在 PROPERTIES 中设置 bucket_size 参数来指定分桶大小,启用按需动态增加分桶数量。单位为 B。
PROPERTIES ("bucket_size"="1073741824")
设置数据压缩算法
您可以在建表时通过增加属性 compression 为该表指定数据压缩算法。
compression 有效值包括:
LZ4:LZ4 算法。
ZSTD:Zstandard 算法。
ZLIB:zlib 算法。
SNAPPY:Snappy 算法。
如不指定数据压缩算法,StarRocks 默认使用 LZ4。
版权归原作者 运维仙人 所有, 如有侵权,请联系我们删除。