
一、yolov5s
在yolov5s.ymal文件中,
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple。
通道深度(残差数)及宽度(通道数)相对标准的比例。
标准的backbone中的C3的number分别为:3、6、9、3
yolov5s的backbone中的C3的number为:1,、2、3、1 (depth_multiple*number)
同理网络宽度width_multiple*args[0]。
head类似。
-------------------------------------0-P1/2----------------------------------------------
model.0.conv.weight --------- torch.Size([32, 3, 6, 6])
model.0.bn.weight --------- torch.Size([32])
model.0.bn.bias --------- torch.Size([32])
-------------------------------------1-P2/4----------------------------------------------
model.1.conv.weight --------- torch.Size([64, 32, 3, 3])
model.1.bn.weight --------- torch.Size([64])
model.1.bn.bias --------- torch.Size([64])
-------------------------------------C3----------------------------------------------
**cv1**
model.2.cv1.conv.weight --------- torch.Size([32, 64, 1, 1])
model.2.cv1.bn.weight --------- torch.Size([32]) ***
model.2.cv1.bn.bias --------- torch.Size([32]) ***
**cv2**
model.2.cv2.conv.weight --------- torch.Size([32, 64, 1, 1])
model.2.cv2.bn.weight --------- torch.Size([32])
model.2.cv2.bn.bias --------- torch.Size([32])
**cv3**
model.2.cv3.conv.weight --------- torch.Size([64, 64, 1, 1])
model.2.cv3.bn.weight --------- torch.Size([64])
model.2.cv3.bn.bias --------- torch.Size([64])
bneck:*1
model.2.m.0.cv1.conv.weight --------- torch.Size([32, 32, 1, 1])
model.2.m.0.cv1.bn.weight --------- torch.Size([32]) ***
model.2.m.0.cv1.bn.bias --------- torch.Size([32]) ***
model.2.m.0.cv2.conv.weight --------- torch.Size([32, 32, 3, 3])
model.2.m.0.cv2.bn.weight --------- torch.Size([32]) ***
model.2.m.0.cv2.bn.bias --------- torch.Size([32]) ***
-------------------------------------3-P3/8----------------------------------------------
model.3.conv.weight --------- torch.Size([128, 64, 3, 3])
model.3.bn.weight --------- torch.Size([128])
model.3.bn.bias --------- torch.Size([128])
-------------------------------------C3----------------------------------------------
**cv1**
model.4.cv1.conv.weight --------- torch.Size([64, 128, 1, 1])
model.4.cv1.bn.weight --------- torch.Size([64]) ***
model.4.cv1.bn.bias --------- torch.Size([64]) ***
**cv2**
model.4.cv2.conv.weight --------- torch.Size([64, 128, 1, 1])
model.4.cv2.bn.weight --------- torch.Size([64])
model.4.cv2.bn.bias --------- torch.Size([64])
**cv3**
model.4.cv3.conv.weight --------- torch.Size([128, 128, 1, 1])
model.4.cv3.bn.weight --------- torch.Size([128])
model.4.cv3.bn.bias --------- torch.Size([128])
**bneck1**
model.4.m.0.cv1.conv.weight --------- torch.Size([64, 64, 1, 1])
model.4.m.0.cv1.bn.weight --------- torch.Size([64])
model.4.m.0.cv1.bn.bias --------- torch.Size([64])
model.4.m.0.cv2.conv.weight --------- torch.Size([64, 64, 3, 3])
model.4.m.0.cv2.bn.weight --------- torch.Size([64])
model.4.m.0.cv2.bn.bias --------- torch.Size([64])
**bneck2**
model.4.m.1.cv1.conv.weight --------- torch.Size([64, 64, 1, 1])
model.4.m.1.cv1.bn.weight --------- torch.Size([64])
model.4.m.1.cv1.bn.bias --------- torch.Size([64])
model.4.m.1.cv2.conv.weight --------- torch.Size([64, 64, 3, 3])
model.4.m.1.cv2.bn.weight --------- torch.Size([64])
model.4.m.1.cv2.bn.bias --------- torch.Size([64])
-------------------------------------5-P4/16----------------------------------------------
model.5.conv.weight --------- torch.Size([256, 128, 3, 3])
model.5.bn.weight --------- torch.Size([256])
model.5.bn.bias --------- torch.Size([256])
。。。。。。
二、C3模块
本文选择yolov5s进行通道剪枝,同样根据BN层稀疏化达到剪枝效果。在yolov5s结构中存在shortcut与cat,主路与支路合并操作。其中shortcut是将前层与后层特征相加,cat是通道连接,而shortcut必须保证前后层的通道数一致才可相加。如果shortcut的前后层参与剪枝,就无法保证前后层的通道数一致,所以剪枝过程中必须剔除参与shortcut操作的卷积层,而cat操作则不影响。
yolov5s的C3模块的Bottleneck结构中存在shortcut操作。为了避免BN层稀疏后,通道数不匹配,所以所有的残差结构都不剪枝。
C3:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2 #通道相同直接相加。
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)#支路
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
** C3结构**:
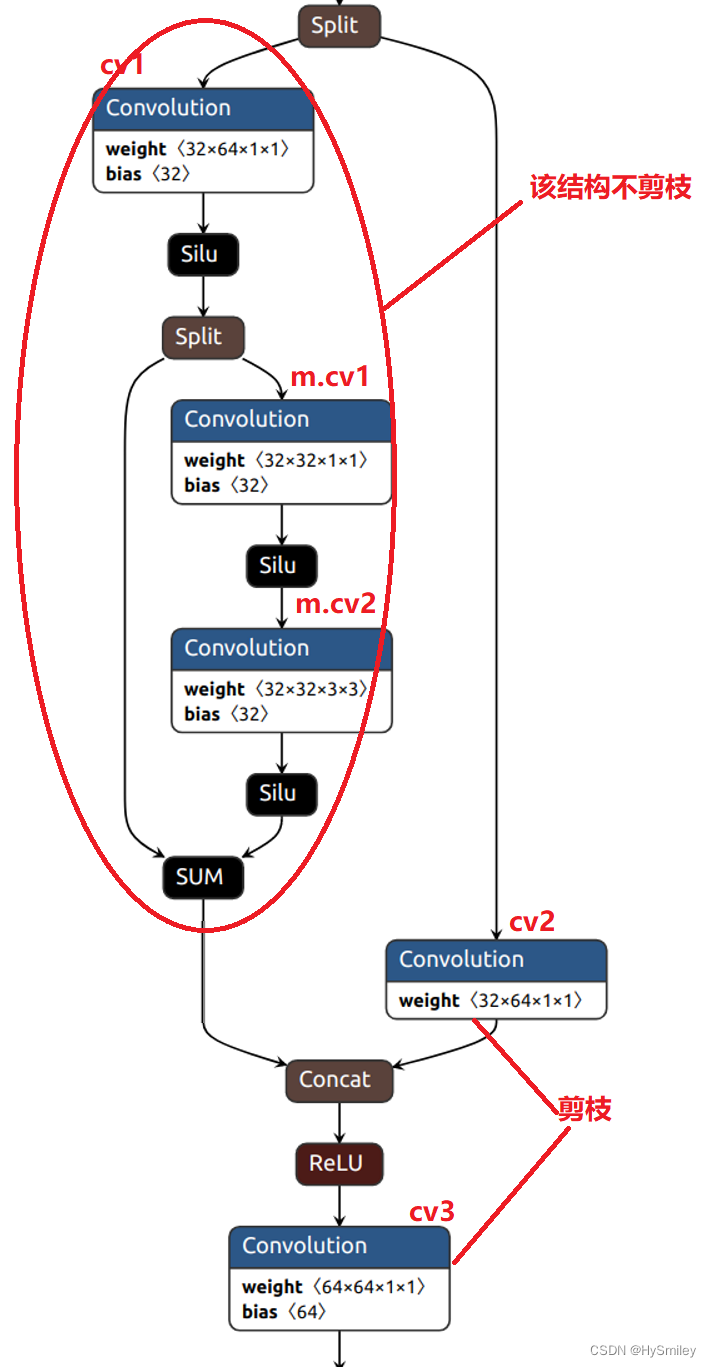
所以C3结构中cv1、cv2参与剪枝。
三、剪枝操作
1、稀疏训练
剔除C3结构中不参与剪枝的卷积层 。
#-------------------------------parse---------------------------
srtmp=opt.sr*(1-0.9*epoch/epochs)
if opt.st:
ignore_bn_list=[]
#记录bottleneck中所有bn层
#C3结构中第一个卷积层与bneck中conv层不剪枝
#即参与add操作有三层conv
for k,m in model.named_modules():
if isinstance(m,Bottleneck):
if m.add:
ignore_bn_list.append(k.split('.',2)[0]+'.cv1.bn')
ignore_bn_list.append(k+ '.cv1.bn')
ignore_bn_list.append(k + '.cv2.bn')
if isinstance(k,nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp*torch.sign(m.weight.data))
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.weight.bias))
print(ignore_bn_list)
2、剪枝操作
规整剪枝与正常剪枝。
正常剪枝
需剪枝的bn层
bn_layers= {}
ignore_bn_layers=[]
for layer_name,layer_model in model.named_modules():
if isinstance(layer_model,Bottleneck):
if layer_model.add:
ignore_bn_layers.append(layer_name.rsplit('.',2)[0]+'.cv1.bn')#C3中第一个conv
ignore_bn_layers.append(layer_name+'.cv1.bn')#bottleneck中第一个conv
ignore_bn_layers.append(layer_name+'.cv2.bn')#bottleneck中第一个conv
if isinstance(layer_model,nn.BatchNorm2d) and (layer_name not in ignore_bn_layers):
# print(ignore_bn_layers,layer_name)
#未剔除全,主要是每次遍历进入C3中时,cv1没剔除,直到bneck中才开始。
bn_layers[layer_name]=layer_model
# print(ignore_bn_layers,)
# print(len(ignore_bn_layers))
# print(bn_layers)
# print(len(bn_layers))
# exit()
#再次过滤4个C3中的第一个cv层
bn_layers= {k:v for k,v in bn_layers.items() if k not in ignore_bn_layers}
# print(bn_names)
# print(len(bn_names))
# exit()
统计所有BN层通道数量及各通道的权重值,对权重进行排序,并计算得到索引阈值。
bn_size=[da.weight.data.shape[0] for da in bn_layers.values()]
total_size=sum(bn_size)
print(total_size)
bn_weights=torch.zeros(total_size)
start=0
for i,w in enumerate(bn_layers.values()):
size=w.weight.data.shape[0]
bn_weights[start:(start+size)] = w.weight.data.abs().clone()
start+=bn_size[i]
print(bn_weights,bn_weights.shape)
bn_data,id=torch.sort(bn_weights)
thresh_index=int(percent*total_size)
thresh_weight=bn_data[thresh_index]
print(thresh_index,thresh_weight)
print(f'Gamma value that less than {thresh_weight:.4f} are set to zero!')
print("=" * 94)
print(f"|\t{'layer name':<25}{'|':<10}{'origin channels':<20}{'|':<10}{'remaining channels':<20}|")
存在问题:
根据阈值来分隔,可能存在某一BN层所有通道均小于阈值,如果将其过滤掉,会造成层层之间的断开,此时需要做判断进行限制,使得每层最少有一个通道得以保留。
解决方法:获取每个bn层的权重的最大值,然后在这些最大值中取最小值与设定的阈值进行对比,如果小于阈值,则提示修改。
# 避免剪掉所有channel的最高阈值(每个BN层的gamma的最大值的最小值即为阈值上限)
highest_thre = []
for bnlayer in bn_layers.values():
highest_thre.append(bnlayer.weight.data.abs().max().item())
# print("highest_thre:",highest_thre)
highest_thre = min(highest_thre)
# 找到highest_thre对应的下标对应的百分比
percent_limit = (bn_data == highest_thre).nonzero()[0, 0].item() / len(bn_weights)
print(f'Suggested Gamma threshold should be less than {highest_thre:.4f}.')
print(f'The corresponding prune ratio is {percent_limit:.3f}, but you can set higher.')
重新设置模型文件
pruned_num=0
pruned_yaml = {}
nc = model.model[-1].nc
with open(cfg, encoding='ascii', errors='ignore') as f:
model_yamls = yaml.safe_load(f) # model dict
# # Define model
pruned_yaml["nc"] = model.model[-1].nc
pruned_yaml["depth_multiple"] = model_yamls["depth_multiple"]
pruned_yaml["width_multiple"] = model_yamls["width_multiple"]
pruned_yaml["anchors"] = model_yamls["anchors"]
anchors = model_yamls["anchors"]
pruned_yaml["backbone"] = [
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3Pruned, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3Pruned, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3Pruned, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3Pruned, [1024]],
[-1, 1, SPPFPruned, [1024, 5]], # 9
]
pruned_yaml["head"] = [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3Pruned, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3Pruned, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3Pruned, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3Pruned, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
模型重构:
maskbndict={}
remain_num=0
for name,layer in model.named_modules():
if isinstance(layer,nn.BatchNorm2d):
bn_model=layer
mask=obtain_bn_mask(bn_model,thresh_weight)
# print(mask)
if name in ignore_bn_layers:
# print('-----')
mask=torch.ones(layer.weight.data.size()).cuda()
maskbndict[name]=mask
# print(mask)
remain_num+=int(mask.sum())
bn_model.weight.data.mul_(mask)
bn_model.bias.data.mul_(mask)
print(f"|\t{name:<25}{'|':<10}{bn_model.weight.data.size()[0]:<20}{'|':<10}{int(mask.sum()):<20}|")
assert int(
mask.sum()) > 0, "Current remaining channel must greater than 0!!! please set prune percent to lower thesh, or you can retrain a more sparse model..."
print("=" * 94)
pruned_model=ModelPruned(maskbndict=maskbndict,cfg=pruned_yaml,ch=3).cuda()
for m in pruned_model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
m.inplace = True # pytorch 1.7.0 compatibility
elif type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
from_to_map=pruned_model.from_to_map
pruned_model_state=pruned_model.state_dict()
参数拷贝:
#-----------------------------参数拷贝----------------------------
modelstate = model.state_dict()
changed_state=[]
for((layername,layermodel),(pruned_layername,pruned_layermodel)) in zip(model.named_modules(),pruned_model.named_modules()):
if isinstance(layermodel,nn.Conv2d) and not layername.startswith("model.24"):
convname=layername[:-4]+"bn"
if convname in from_to_map.keys():
former=from_to_map[convname]
if isinstance(former,str):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
w = layermodel.weight.data[:, in_idx, :, :].clone()
if len(w.shape) == 3: # remain only 1 channel.
w = w.unsqueeze(1)
w = w[out_idx, :, :, :].clone()
pruned_layermodel.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(former, list):
orignin = [modelstate[i + ".weight"].shape[0] for i in former]
formerin = []
for it in range(len(former)):
name = former[it]
tmp = [i for i in range(maskbndict[name].shape[0]) if maskbndict[name][i] == 1]
if it > 0:
tmp = [k + sum(orignin[:it]) for k in tmp]
formerin.extend(tmp)
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layermodel.weight.data[out_idx, :, :, :].clone()
pruned_layermodel.weight.data = w[:, formerin, :, :].clone()
changed_state.append(layername + ".weight")
else:
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layermodel.weight.data[out_idx, :, :, :].clone()
assert len(w.shape) == 4
pruned_layermodel.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(layermodel, nn.BatchNorm2d):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername].cpu().numpy())))
pruned_layermodel.weight.data = layermodel.weight.data[out_idx].clone()
pruned_layermodel.bias.data = layermodel.bias.data[out_idx].clone()
pruned_layermodel.running_mean = layermodel.running_mean[out_idx].clone()
pruned_layermodel.running_var = layermodel.running_var[out_idx].clone()
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
changed_state.append(layername + ".running_mean")
changed_state.append(layername + ".running_var")
changed_state.append(layername + ".num_batches_tracked")
if isinstance(layermodel, nn.Conv2d) and layername.startswith("model.24"):
former = from_to_map[layername]
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
pruned_layermodel.weight.data = layermodel.weight.data[:, in_idx, :, :]
pruned_layermodel.bias.data = layermodel.bias.data
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
missing = [i for i in pruned_model_state.keys() if i not in changed_state]
pruned_model.eval()
pruned_model.names = model.names
# =============================================================================================== #
torch.save({"model": model}, "weights/pruned_model/orign_model.pt")
model = pruned_model
torch.save({"model": model}, "weights/pruned_model/pruned_model.pt")
model.cuda().eval()
参考:
YOLOv5模型剪枝压缩(2)-YOLOv5模型简介和剪枝层选择_MidasKing的博客-CSDN博客_yolov5剪枝
yolov5模型压缩之模型剪枝_小小小绿叶的博客-CSDN博客_yolov5模型裁剪
GitHub - midasklr/yolov5prune
本文转载自: https://blog.csdn.net/m0_37264397/article/details/126292621
版权归原作者 HySmiley 所有, 如有侵权,请联系我们删除。
版权归原作者 HySmiley 所有, 如有侵权,请联系我们删除。