

gpu对于机器学习是必不可少的。可以通过AWS或谷歌cloud轻松地启动这些机器的集群。NVIDIA拥有业内领先的GPU,其张量核心为 V100和 A100加速哪种方法最适合你的神经网络?为了以最低的成本设计出最快的神经网络,机器学习架构师必须解决许多问题。此外,仅仅使用带有GPU和张量核心的机器并不能保证最高性能。那么,作为一个机器学习架构师,应该如何处理这个问题呢?当然,您不能是硬件不可知论者。您需要了解硬件的功能,以便以最低的成本获得最大的性能。
作为一个机器学习架构师,你应该如何设计神经网络来最大化GPU的性能?
在本文中,我们将深入了解机器学习架构师实现性能最大化的手段。我们将特别关注矩阵-矩阵乘法,因为它是机器学习中最常见和最繁重的数学操作。
让我们从一个简单的全连接的一个隐藏层神经网络开始:
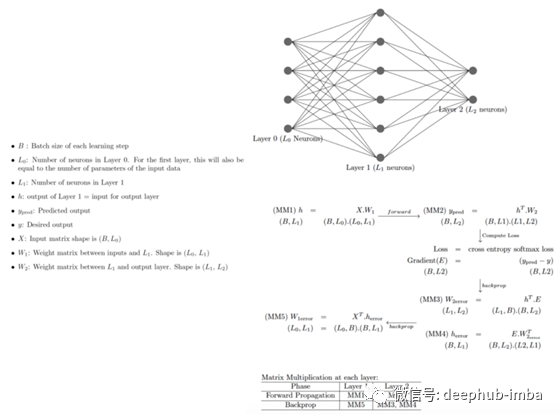
图1:在神经网络的每一层进行矩阵乘法,每一步的矩阵乘法的形状如括号所示。例如(B, L1)是B行L1列的矩阵的形状。MM1, MM2,…MM5是各种矩阵-矩阵乘法。
从基本神经网络可以看出,在第L2层,我们进行了3次矩阵-矩阵乘法(1向前,2向后)。在第L1层,我们执行2个矩阵-矩阵乘法(1向前,1向后)。事实上,除了第一层(L1)之外,我们在每一层都执行了3次矩阵乘法。如果神经网络有n层,则需要进行3n-1个矩阵-矩阵乘法,即时,它随神经网络的大小线性增长。
一个快速观察方法是将批大小设置成1,我们看下B=1时的情况,即一次只学习一个数据点。在这种情况下,矩阵-矩阵退化为矩阵-向量的乘法。然而,在实践中,批大小从不为1。在梯度下降中,在每个学习步骤中考虑整个数据集,而在随机梯度下降中,在每个学习步骤中考虑一批B > 1(但比整个数据集要少得多)。
在本文中,让我们关注两个维数(M, K)和(K, N)的矩阵a和B之间的单个矩阵-矩阵乘法,分别得到维数(M, N)的矩阵C。
维数M, N, K由每层神经网络的结构决定。例如,在AlexNet中,批处理大小为128,有几个密集的层(4096个节点)和一个输出层(1000个节点)。这将导致(128,4096)和(409,1000)矩阵的乘法。这些是相当大的矩阵。
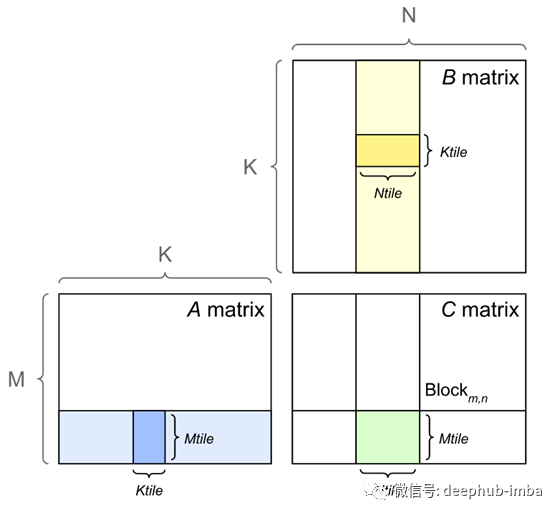
图2。平铺的矩阵乘法
“大”是什么意思?这些矩阵是如何相乘的?所谓“大”,是指任何不能装入内存的矩阵。让我们更深入地研究大矩阵乘法。我们在教科书中学习的矩阵乘法假设矩阵与记忆相吻合。但在现实中,情况可能并非如此,尤其是在机器学习方面。此外,为了获得最佳性能,精细调优的矩阵乘法算法必须考虑到计算机中的内存层次结构。对于无法装入内存的矩阵乘法,最常用的方法是平铺/阻塞矩阵乘法算法。块矩阵乘法,矩阵分割成更小的块,适合到内存中,然后计算部分的合成产品矩阵(参见图2)。图3展示了块矩阵乘法如何递归地应用在每一个级别的内存层次结构。
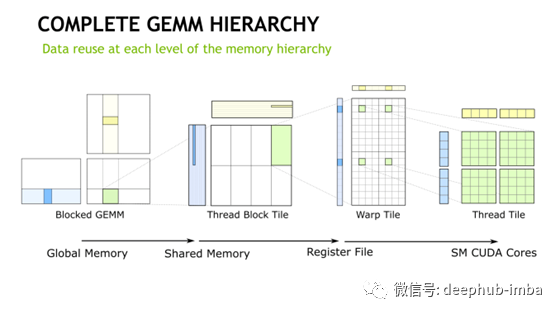
图3:在NVIDIA CPU-GPU系统的完整内存层次中递归应用平铺/块矩阵-矩阵乘法。GEMM表示一般矩阵乘法。
我们不会在这里进入精确的平铺矩阵乘法算法,感兴趣的读者参阅本文。BLAS中用于一般矩阵乘法的库例程称为GEMM。NVBLAS是GEMM的Nvidia实现,它利用了内部的GPU架构,实现了平铺/块矩阵乘法。PyTorch和TensorFlow链接到Nvidia GPU上的这个库。类库为你做所有繁重的工作。但是设计糟糕的神经网络肯定会降低性能。
对于我们来说,最直接的目标是尽可能快地找出矩阵-矩阵乘法执行的条件。这是可能的,只有当GPU是100%忙,而不是为了等待数据而空闲。为此,我们需要查看内存层次结构,以及数据在内存层次结构中移动的速度有多快。
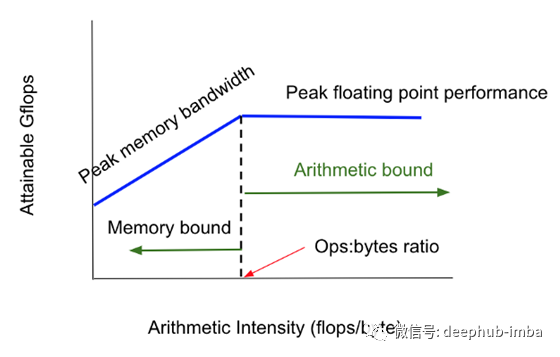
图4:Roofline 模型
内存层次结构为提高性能提供了关键优势:1)它们隐藏了CPU、GPU、内存组件之间的延迟差异,2)它们利用了程序局部性。此外,一个设计良好的内存层次结构以最低的成本/字节提供最高的性能。为了让gpu持续地忙碌,数据块必须快速地输入gpu。这是由数据传输带宽和GPU处理数据的速度决定的。这个性能度量由Roofline 模型中的ops:字节比率捕获(图4)。
图5显示了如何从供应商的规格中计算这个。我们看到,ops:字节比是139 V100,和416 A100。越大的ops:字节比率,会提供更大计算速度,如果计算是内存或算术限制。换句话说,一个具有较高ops: bytes ratio的系统比一个较小的系统更强大。这就是为什么 A100比 V100更强大。

图5:计算ops:字节比率规范。
ops:字节比对于机器学习和矩阵乘法意味着什么?要了解这一点,我们现在必须看看矩阵乘法的计算和数据要求。算术强度定义为浮点运算/秒与字节的比率。图6显示了如何计算算术强度。

图6:计算矩阵乘法的算术强度
如果算术强度> ops:bytes,那么矩阵乘法就是算术界限,否则就是内存界限。
因此,第一个问题是,所涉及矩阵的维数应该被设计成算术强度大于ops:字节。这将确保GPU被充分利用。例如批处理大小= 512,N=1024, M=4096,算术强度为315,大于Volta V100 GPU的139。因此,该矩阵乘法是在Volta V100上的算术界,GPU将得到充分利用。图7显示了机器学习中一些常见操作的算法强度。第二行对应于批大小= 1。在这种情况下,线性层变成了内存界而不是算术界。这就是为什么批量大小为1一般不用于生产机器学习算法的原因。

图7。机器学习中一些常见操作的算术强度。来源:NVIDIA文档
然而,通过选择正确的矩阵维数来保证正确的算法强度并不足以实现算法性能的峰值,还需要保证所有张量核都处于繁忙状态。为了有效地使用Nvidia的张量核心,对于FP16算法,M, N, K必须是8的倍数,对于FP32算法必须是16的倍数。Nvidia核库检查矩阵的维数,如果满足条件,则将操作路由到张量核。这可以导致在Volta上使用张量磁心比使用没有张量磁心6倍的加速。因此,第二个要点是,如果尺寸不是8或16的倍数,那么建议适当填充尺寸。
作为一名机器学习架构师,在您寻求提高性能的过程中,您将不可避免地面临是否要从Volta升级到Ampere并支付更高的成本的决定。为此,必须使用Roofline模型确定神经网络是算术界限还是内存界限。如果两者都不是,那么升级到更强大的机器就没有价值了。这是第三个要点。Nvidia提供了Nsight Compute等工具来执行应用程序分析。(https://developer.nvidia.com/nsight-compute)
总结
- 矩阵-矩阵乘法是神经网络训练和推理中最常用的运算。矩阵乘法的次数几乎是神经网络层数的3n。因此,尽可能快地计算这些是很重要的。
- 在神经网络中,矩阵是非常大的。因此,我们总是使用GPU来加速矩阵乘法。为了做到这一点,我们必须了解GPU的ops:字节比,并设计层的算法强度要大于ops:字节比,如果可能的话。
- 为了达到使用所有张量核心的峰值算术性能,矩阵的维数也必须满足NVIDIA架构对使用张量核心的要求。通常,它是8 (FP16算术)或16 (FP32算术)的倍数。最好查看文档以确保满足需求。
- 您应该确定应用程序是内存绑定还是算术绑定。如果两者都不是,那么升级到更强大的GPU就没有意义了。否则,我们可以通过升级进一步加速。
- 了解硬件功能及其对最大化性能的要求将有助于明智地选择矩阵维数和批大小。这将导致神经网络的设计,使训练可以在最短的时间内以最低的成本完成。
引用
- Nvidia docs: Deep Learning performance documentation
- Nvidia: It’s all about Tensor Cores, AnandTech Blog 2018
- Fast Implementation of DGEMM on Fermi GPU, Proceeding of the 2011 International Conference on High Performance, Storage, and Analysis
- Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures,Comm. of the ACM, April 2009
- Performance Analysis of GPU-Accelerated Applications using the Roofline Model, NVIDIA, 2019
- Intel Advisor Roofline Analysis
- Nvidia Nsight Compute
- Nvidia Ampere A100 Datasheet
- Nvidia Volta V100 Datasheet
这篇文章触及了加速机器学习的一个方面。这个问题还有其他方面。希望这篇文章对您有用。
作者:Kiran Achyutuni
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********