

目录
🍇前言
本篇文章接《获取Chatgpt3.5免费接口文末付代码(过Authorization认证)》,由于上次更新了代码后,对方做了验证,而且验证码有点难识别,真人都有点难看明白,喜欢爬虫类文章的可以订阅我专栏哦
⭐⭐欢迎订阅⭐⭐ ⭐⭐欢迎订阅⭐⭐
🚀Python爬虫项目实战系列文章!!
⭐⭐欢迎订阅⭐⭐ ⭐⭐欢迎订阅⭐⭐
例如:
🚀Python爬虫项目实战系列文章!!
⭐⭐欢迎订阅⭐⭐
【Python爬虫项目实战一】获取Chatgpt3.5免费接口文末付代码(过Authorization认证)
【Python爬虫项目实战二】Chatgpt还原验证算法-解密某宝伪知网数据接口
⭐⭐欢迎订阅⭐⭐
🍍验证码识别的几个方法
🥥百度AI开放平台
在对接之前,我们先看一下识别效果,可见效果一般,存在个别识别不出来,又因为需要付费于是不考虑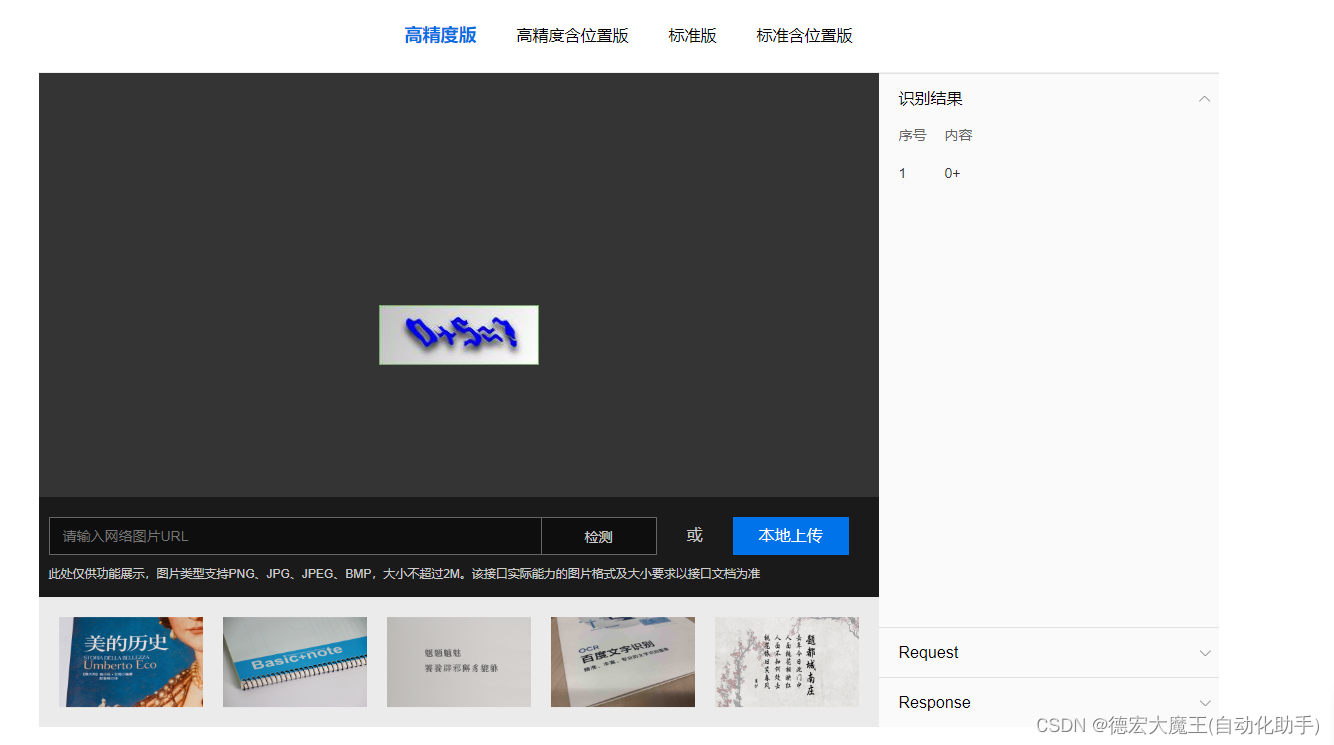
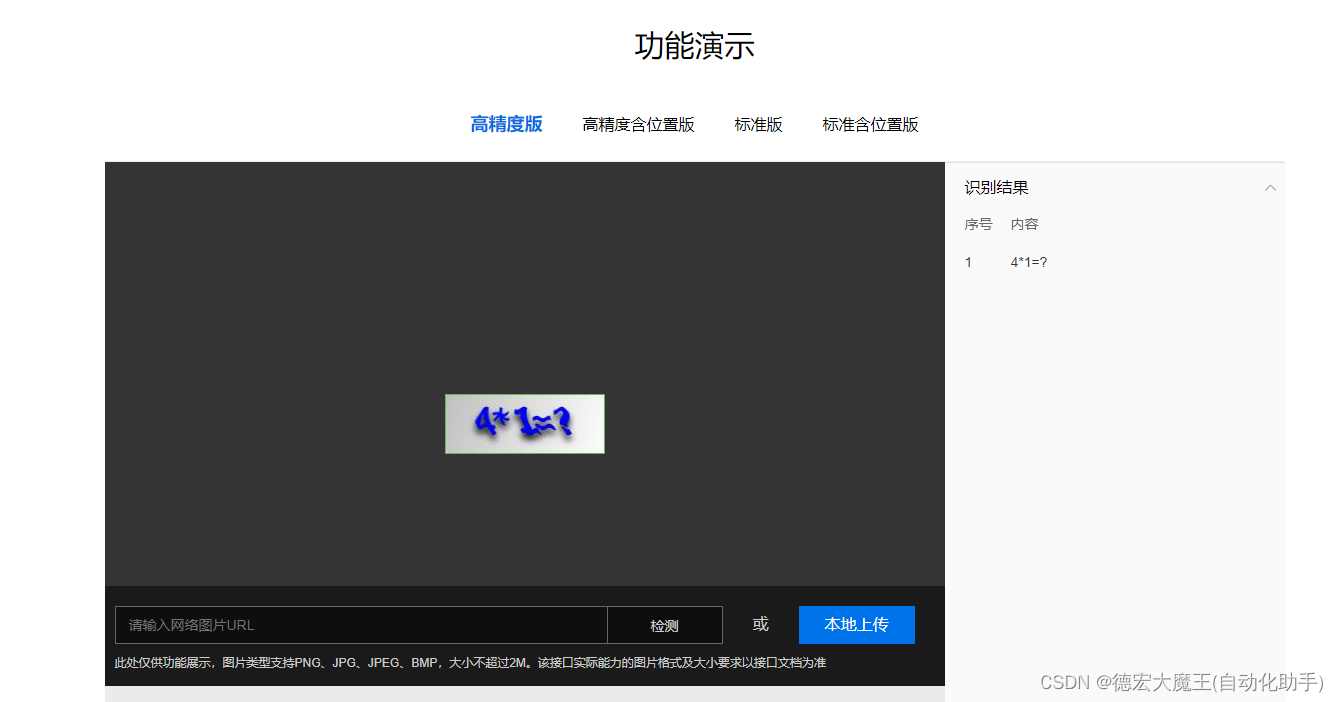
🥥Ddddocr
之前在其他项目中,已经介绍过了Dddocr,可以参考我的文章
《Selenium验证码ddddocr识别:带带ddocr》
识别验证码,5行搞定
ocr = ddddocr.DdddOcr()withopen('image.jpg','rb')asf:
img_bytes = f.read()
res = ocr.classification(img_bytes)print(res)
效果和百度一样遇到几个畸形的就直接识别出错,可以看看我的截图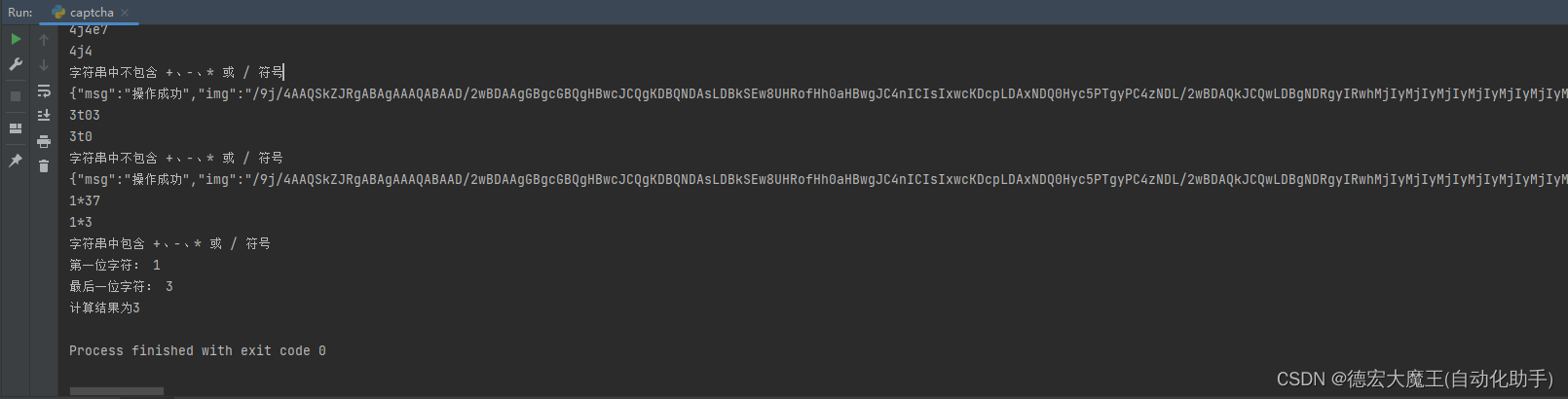
{"msg":"操作成功","img":"","code":200,"captchaEnabled":true,"uuid":"d14f1de7a0b842cfae525f3389d00f86"}
识别结果:9t67
提取结果:9t6
字符串中不包含 +、-、* 或 / 符号
{"msg":"操作成功","img":"","code":200,"captchaEnabled":true,"uuid":"010ed8010fe241c9a8c2e8c0989f9084"}
识别结果:4j4e7
4j4
字符串中不包含 +、-、* 或 / 符号
{"msg":"操作成功","img":"","code":200,"captchaEnabled":true,"uuid":"623dd34830554da49911b2ae75507921"}
识别结果:3t03
3t0
字符串中不包含 +、-、* 或 / 符号
{"msg":"操作成功","img":"","code":200,"captchaEnabled":true,"uuid":"164524dd70e74ae18d3782d7887b8974"}
识别结果:1*37
提取结果:1*3
字符串中包含 +、-、* 或 / 符号
之前识别发现效果不理想,但是在验证码中,存在简单的验证码随机刷新,所以我的做法是:舍弃百度AI通过Ddddocr识别,识别过程中判断
"+、-、*、/"逐步往下获取参数,具体可以往下看
🦑分析验证码位数




在上面的验证码中,都是10内的"+、-、、/“运算,所以只需要匹配”+、-、、/"左右的数字即可
🦑获取验证码接口
def get_captcha():
headers ={'Accept':'application/json, text/plain, */*','Accept-Language':'zh-CN,zh;q=0.9','Connection':'keep-alive','Origin':'https://openmao.panchuang.net','Referer':'https://openmao.panchuang.net/','Sec-Fetch-Dest':'empty','Sec-Fetch-Mode':'cors','Sec-Fetch-Site':'same-site','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36','sec-ch-ua':'"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"','sec-ch-ua-mobile':'?0','sec-ch-ua-platform':'"Windows"',}
response = requests.get('https://mapi.panchuang.net/api/user/captchaImage', headers=headers)print(response.text)return response.json()
🦑算法识别匹配

将获取到的验证码通过解析base64存放在根目录
def decode_base64_to_img(base64_str):
img_data = base64.b64decode(base64_str)withopen('image.jpg','wb')asf:
f.write(img_data)
img = Image.open('image.jpg')
Ddddocr识别,识别到后进行特征提取,提取完毕逐步分析,如果提取失败反复操作
def verification():
# 验证码识别
ocr = ddddocr.DdddOcr()withopen('image.jpg','rb')asf:
img_bytes = f.read()
res = ocr.classification(img_bytes)print(res)
text = res[:3] # 提取前三位子串
print(text) # 输出:8*4if"+"in text or "-"in text or "*"in text or "/"intext:print("字符串中包含 +、-、* 或 / 符号")
first_char = text[0] # 第一位字符
last_char = text[-1] # 最后一位字符
print("第一位字符:", first_char)print("最后一位字符:", last_char)if"+"intext:
result=int(first_char)+int(last_char)if"-"intext:
result=int(first_char)-int(last_char)if"*"intext:
result=int(first_char)*int(last_char)if"/"intext:
result=int(first_char)/int(last_char)print(f"计算结果为{result}")else:print("字符串中不包含 +、-、* 或 / 符号")
result =get_captcha()
# 转换本地
decode_base64_to_img(result['img'])verification()
最后获得计算数据
🦑请求登陆接口
观察login接口
uuid是和验证码一起获取到的
uuid用于定位图片id,带着计算结果和uuid去login接口请求即可
我将计算出来的uuid和验证码结果,显示出来进行构造,这里注释了请求,因为请求了就显示验证码过期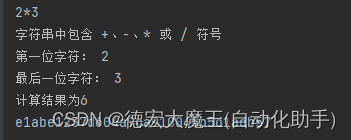
print(uuid)print(result_num)
json_data ={'username':'****9','password':'*****','loginTypeEnum':'ACCOUNT','code': result_num,'uuid': uuid,}
# response = requests.post('https://mapi.panchuang.net/api/user/login', headers=headers, json=json_data)
# print(response.text)
通过拼接手动填上去验证最后获得token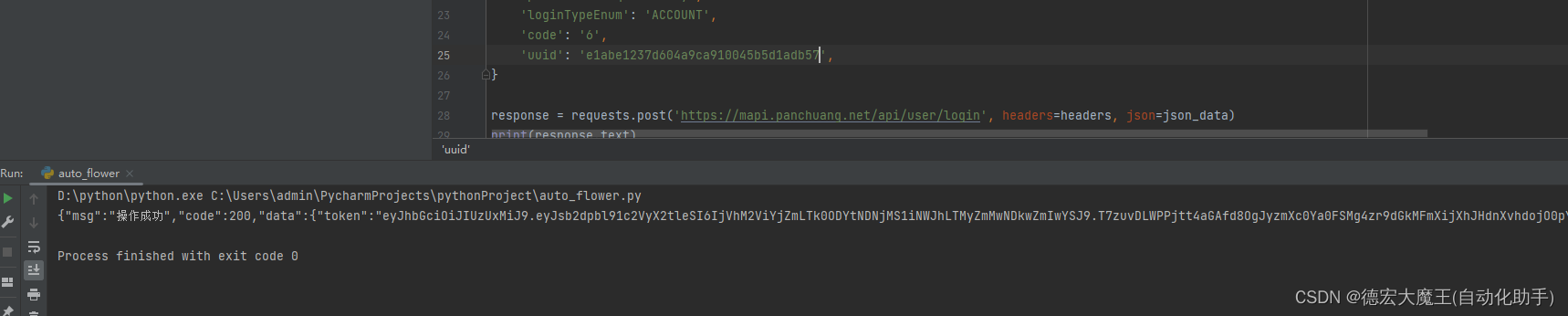
🍋总结:
以上就是今天的教程,代码审核通过后会放在评论区,该项目现在只是demo仅供提取计算验证码,如果需要Chatgpt3.5接口的可以留言哦,该接口现在用于本人账号对接自动回复,长期互动支持的可以互关哈
推荐我的爬虫文章
《记一次云之家签到抓包》
《记一次视频抓包m3u8解密过程》
《抓包部分软件时无网络+过代理检测 解决办法 安卓黄鸟httpcanary+vmos》
《Python】记录抓包分析自动领取芝麻HTTP每日免费IP(成品+教程)》
《某课抓包视频 安卓手机:黄鸟+某课app+VirtualXposed虚拟框架》
推荐专栏:
《Python爬虫脚本项目实战》
该专栏往期文章:
《【Python爬虫项目实战一】获取Chatgpt3.5免费接口文末付代码(过Authorization认证)》
🥦如果感觉看完文章还不过瘾,欢迎查看我的其它专栏
🥦作者对python有很大的兴趣,完成过很多独立的项目:例如滇医通等等脚本,但是由于版权的原因下架了,爬虫这一类审核比较严谨,稍有不慎就侵权违规了,所以在保证质量的同时会对文章进行筛选
如果您对爬虫感兴趣请收藏或者订阅该专栏哦《Python爬虫脚本项目实战》,如果你有项目欢迎联系我,我会同步教程到本专栏!
🚀Python爬虫项目实战系列文章!!
⭐⭐欢迎订阅⭐⭐
【Python爬虫项目实战一】获取Chatgpt3.5免费接口文末付代码(过Authorization认证)
【Python爬虫项目实战二】Chatgpt还原验证算法-解密某宝伪知网数据接口
⭐⭐欢迎订阅⭐⭐
版权归原作者 德宏大魔王(自动化助手) 所有, 如有侵权,请联系我们删除。