
1 任务内容
1.1 任务背景
2022年12月1日起,新出台的《反电信网络诈骗犯罪法》正式施行,表明了我国治理当前电信网络诈骗乱象的决心。诈骗案件分类问题是打击电信网路诈骗犯罪过程中的关键一环,根据不同的诈骗方式、手法等将其分类,一方面能够便于统计现状,有助于公安部门掌握当前电信网络诈骗案件的分布特点,进而能够对不同类别的诈骗案件作出针对性的预防、监管、制止、侦查等措施,另一方面也有助于在向群众进行反诈宣传时抓住重点、突出典型等。
1.2 任务简介
文本分类是自然语言处理领域的基础任务,面向电信网络诈骗领域的案件分类对智能化案件分析具有重要意义。本任务目的是对给定案件描述文本进行分类。案件文本包含对案件的整体描述(经过脱敏处理)。具体细节参考第2部分。
2 评测数据
2.1 数据简介
数据采集: 案件文本内容为案情简述,即为受害人的笔录,由公安部门反诈大数据平台导出。
数据清洗: 从反诈大数据平台共计导出 13 个类别的数据,去除了“其他类型诈骗”类别,因此最终采用 12 个类别。
脱敏处理: 去除了案件文本中的姓名、出生日期、地址、涉案网址、各类社交账号以及银行卡号码等个人隐私或敏感信息。
分类依据: 类别体系来源于反诈大数据平台的分类标准,主要依据受害人的法益及犯罪分子的手法进行分类,例如冒充淘宝客服谎称快递丢失的,分为冒充电商物流客服类;冒充公安、检察院、法院人员行骗的,分为冒充公检法及政府机关类;谎称可以帮助消除不良贷款记录的,分为虚假政信类等等。
类别数量: 12 个类别。
2.2 数据样例
数据以json格式存储,每一条数据具有三个属性,分别为案件编号、案情描述、案件类别。样例如下:
{"案件编号":28043,"案情描述":"事主(女,20岁,汉族,大专文化程度,未婚,现住址:)报称2022年8月27日13时43分许在口被嫌疑人冒充快递客服以申请理赔为由诈骗3634元人民币。对方通过电话()与事主联系,对方自称是中通快递客服称事主的快递物件丢失现需要进行理赔,事主同意后对方便让事主将资金转入对方所谓的“安全账号”内实施诈骗,事主通过网银的方式转账。事主使用的中国农业银行账号,嫌疑人信息:1、成都农村商业银行账号,收款人:;2、中国建设银行账号,收款人:。事主快递信息:中通快递,.现场勘查号:。","案件类别":"冒充电商物流客服类"},{"案件编号":49750,"案情描述":"2022 年 11 月 13 日 14 时 10 分 23 秒我滨河派出所接到 110 报警称在接到自称疾控中心诈骗电话,被骗元,接到报警民警赶到现场,经查,报警人,在辽宁省 17 号楼 162 家中,接到自称沈阳市疾控报警中心电话,对方称报警人去过,报警人否认后对方称把电话转接到哈尔滨市刑侦大队,自称刑侦大队的人说报警人涉及一桩洗钱的案件让报警人配合调查取证,调查取证期间让报警人把钱存到自己的银行卡中,并向报警人发送一个网址链接,在链接上进行操作,操作完后,对方在后台将报警人存在自己银行卡的钱全部转出,共转出五笔,共计元。","案件类别":"冒充公检法及政府机关类"},{"案件编号":78494,"案情描述":"2022 年 1 月 10 日 11 时至 18 时许,受害人在的家中,接到陌生电话:(对方号码:)对方自称是银保监会的工作人员,说受害人京东 APP 里有个金条借款要关闭,否则会影响征信。后对方就让受害人下载了“银视讯”的会议聊天软件,指导受害人如何操作,让受害人通过手机银行(受害人账户:1、交通银行;2、紫金农商银行;3、中国邮政储蓄银行:;4、中国民生银行:;)转账到对方指定账户:嫌疑人账户:1、中国农业银行;2、中国银行;3、中国银行;4、中国建设银行;5、中国银行;共计损失:元。案件编号:","案件类别":"虚假征信类"}
2.3 数据分布
提供数据共有12个类别,类别具体分布如下表所示。
类别名称样本数量刷单返利类35459冒充电商物流客服类13772虚假网络投资理财类11836贷款、代办信用卡类11105虚假征信类8464虚假购物、服务类7058冒充公检法及政府机关类4563冒充领导、熟人类4407网络游戏产品虚假交易类2155网络婚恋、交友类(非虚假网络投资理财类)1654冒充军警购物类1092网黑案件1197总计102762
注:在数据集(训练集和测试集)中 “冒充军警购物类” 的标注为 “冒充军警购物类诈骗” 。
训练集及测试集划分如下所示。
数据划分样本数量训练集82210测试集A10276测试集B10276总计102762
本次评测任务计划仅采用训练集及测试集A以作评测。
2.4 文本长度分布
下图展示了案情描述文本长度的分布情况,因此在预训练阶段,我们选择了预训练了一个1024长度的Nezha模型。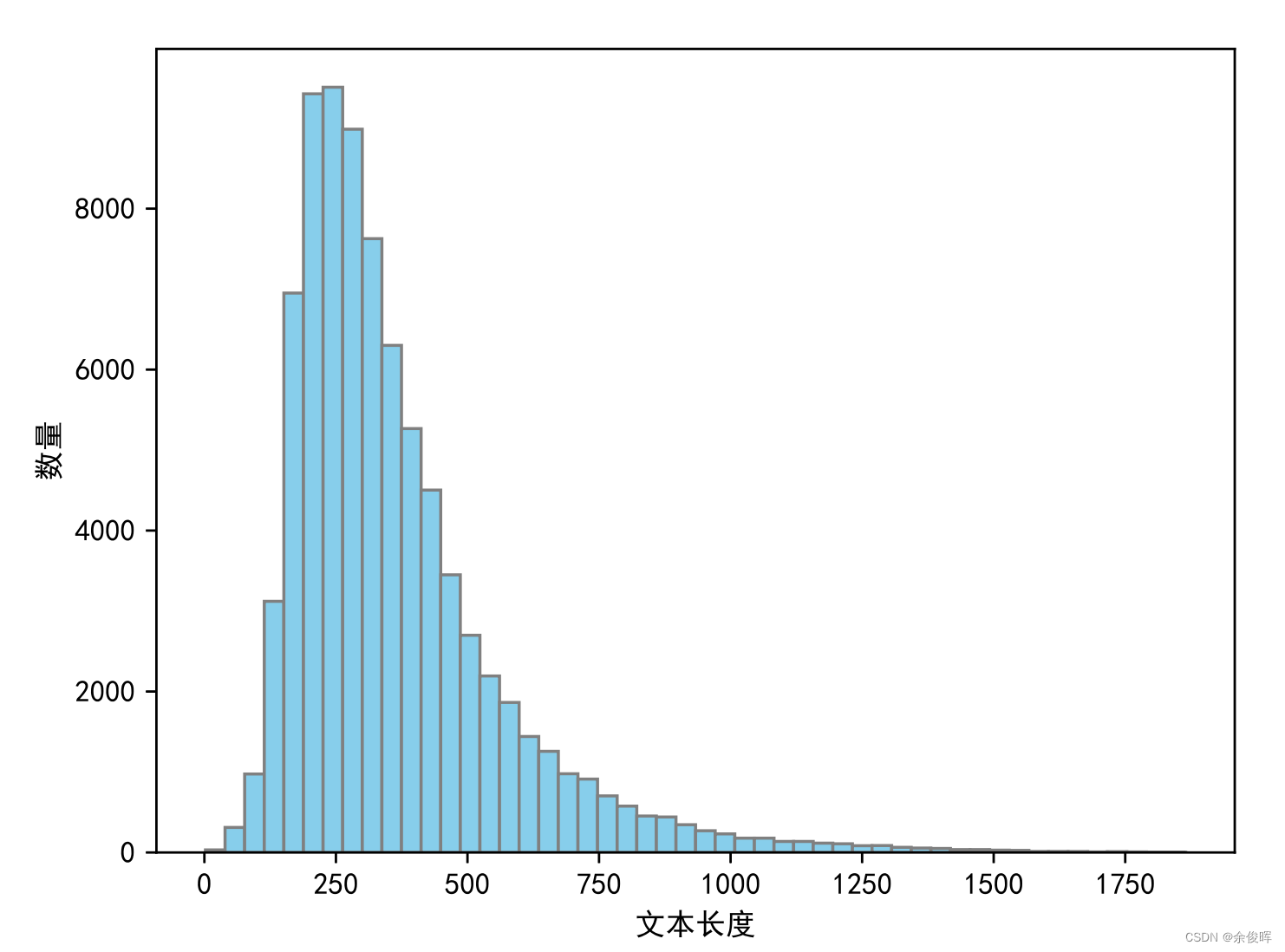
3 评价标准
评测性能时,本任务主要采用宏平均F1值作为评价标准,即对每一类计算F1值,最后取算术平均值,其计算方式如下:
M
a
c
r
o
F
1
=
1
n
∑
i
=
1
n
F
1
i
Macro_{F1} = \frac{1}{n} \sum_{i=1}^{n} F1_{i}
MacroF1=n1i=1∑nF1i
其中
F
1
i
F1_i
F1i 为第i类的
F
1
F1
F1 值,n为类别数,在本任务中n取12。
4 模型架构
本文模型结构如下图所示,基线模型采用BERT(包括其变种)+Linear的文本分类模型架构。并采用预训练、对抗训练和模型融合等三种主要优化策略提升基线模型的性能。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7RgsDA26-1690680329128)(./img/model.jpg)]](https://img-blog.csdnimg.cn/c0fe9782e3f14c46a665fb0a270eb637.png)
4.1 预训练
有效的预训练可以提升模型在下游任务微调的性能。本文提取数据集中的案情描述文本,在预训练阶段添加MLM预训练任务,通过无监督学习使得预训练语言模型获得案件领域的知识,从而使模型具备对案件文本更好的语义理解和特征提取能力。MLM预训练使用了与【1】一致的方式,将输入的案情描述文本随机遮蔽,即为存在15%的概率决定对该token进行修改,其中有80%的概率改为"[MASK]",有10%的概率被替换为一个随机的token,有10%的概率保持不变。MLM预训练任务使用交叉熵损失进行训练,其损失表示为公式:
L
m
l
m
=
−
∑
i
=
0
V
−
1
y
i
m
a
s
k
l
o
g
(
p
i
m
a
s
k
)
L_{mlm}=-\sum_{i=0}^{V-1}y_i^{mask}log(p_i^{mask})
Lmlm=−i=0∑V−1yimasklog(pimask)
其中,V为模型词表大小,
y
i
m
a
s
k
y_i^{mask}
yimask是遮蔽字符的标签,
p
i
m
a
s
k
p_i^{mask}
pimask表示模型预测的概率。
本文在预训练阶段,分别预训练了三种中文模型,分别为nezha、Roberta和Deberta。在使用Nezha-base-wwm预训练语言模型时,输入序列的最大长度为1024,在使用chinese-roberta-wwm-ext-large与Deberta(注:这里使用了两个权重进行实验,320M的进行了预训练,710M的没有进行预训练,相关权重链接:1、Erlangshen-DeBERTa-v2-320M-Chinese:https://huggingface.co/IDEA-CCNL/Erlangshen-DeBERTa-v2-320M-Chinese;2、Erlangshen-DeBERTa-v2-710M-Chinese:https://huggingface.co/IDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese}预训练语言模型时,输入序列的最大长度为512)。
4.2 对抗训练
为了增强模型对干扰和噪声的抵抗能力,本文实验了PGD【3】、FGM【4】、FreeLB【2】等对抗训练技巧提升模型的鲁棒性,通过实验性能对比,最终主要采用了FreeLB对抗训练。FreeLB的核心思想是通过增加对抗样本的生成空间,引入自由生成的方法来提高模型的鲁棒性。传统的对抗训练方法通常使用固定的扰动方法来生成对抗样本,这可能会限制模型的泛化能力和鲁棒性。相比之下,FreeLB提出了自由生成的概念,它允许生成过程中的扰动更加多样和自由,从而提供更丰富的训练信号。都是在word embedding空间上加入扰动,然后对扰动后的embedding进行look up,得到的词向量再喂给模型。其原理伪代码如表1所示。

4.3 模型融合
模型融合是一种常用的技术,在文本分类比赛中被广泛应用,旨在提高分类模型的性能和泛化能力。模型融合通过结合多个不同的分类模型的预测结果,从而得到更准确、更稳定的最终预测结果。本文的模型融合的方法是对于每个分类模型的输出概率进行简单的相加,得到最终的融合概率分布,进一步求取最大概率的下标获取对应的类别标签。
5 评测结果
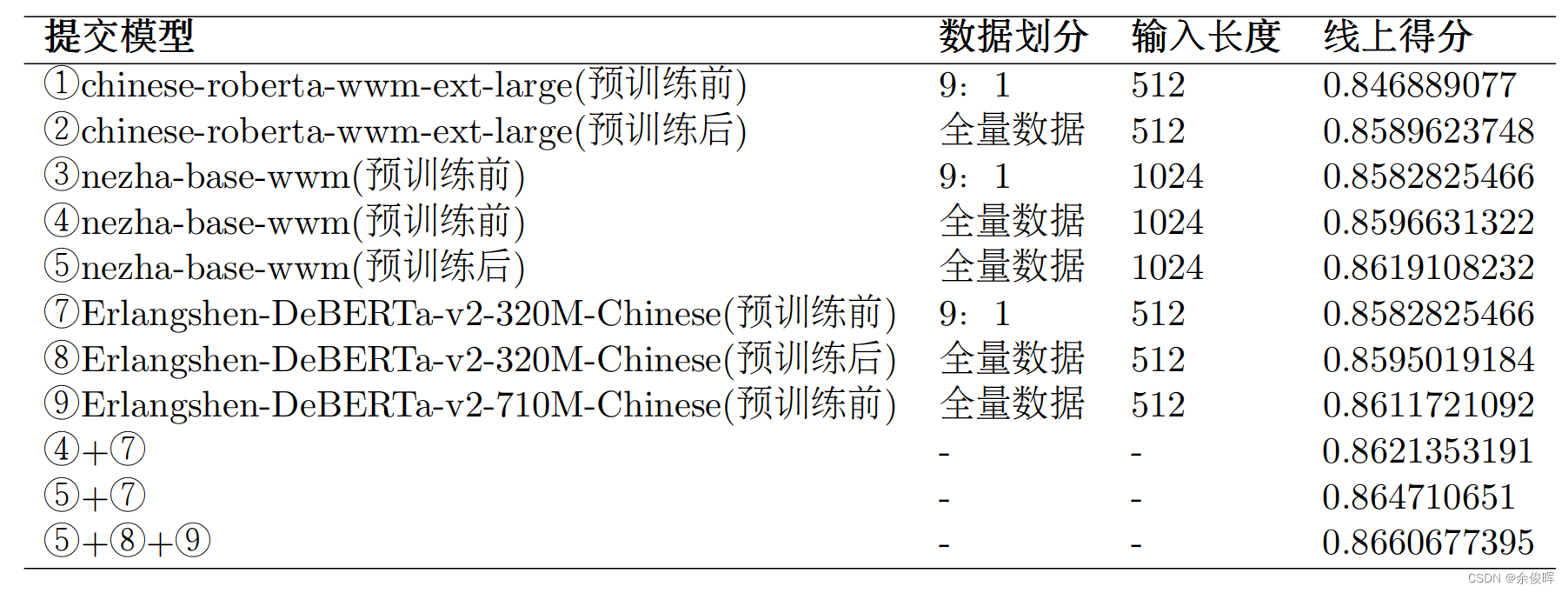
最终相应模型在线上提交评测的结果如下表:
6 结果分析与讨论
模型对比:本文使用了多个不同的预训练模型进行评测,包括chinese-roberta-wwm-ext-large、nezha-base-wwm和Erlangshen-DeBERTa-v2系列模型。从线上得分来看,预训练后的模型普遍表现比预训练前的模型更好。
数据划分:大部分模型使用了9:1的数据划分比例,即将数据集划分为训练集和验证集。只有两个模型(②和③)使用了全量数据进行训练。使用全量数据进行训练通常会有更好的效果,因为模型可以更充分地学习数据中的模式和规律。
输入长度:所有模型的输入长度都为512或1024。较长的输入长度可以提供更多的上下文信息,有助于模型理解文本的语义和逻辑关系。然而,较长的输入长度也会增加模型的计算负担和训练时间。
模型融合:根据给出的实验结果,可以看出模型组合⑤+⑧+⑨获得了最高的线上得分(0.8660677395)。这是因为这个组合中的模型相互补充,模型的融合能够有效的提升模型的泛化能力。
此外,由于比赛提交次数有限,未提交验证FreeLB对抗训练对于结果的影响,根据本人在其他比赛的经验,该策略能有效提升模型的鲁棒性。
7 结论
本研究针对电信网络诈骗案件的分类问题,通过采用一系列优化策略和技巧,包括BERT的继续预训练、FreeLB的对抗训练和模型融合,取得了显著的成果。实验结果在“CCL23-Eval-任务6-电信网络诈骗案件分类评测”技术评测比赛中最终成绩排名第一,证明了所提出的优化策略在提高电信网络诈骗案件分类性能方面的有效性和优越性。
通过BERT的继续预训练,研究者使模型具备更好的语义理解和特征提取能力,有助于准确地分类和检测电信网络诈骗案件。同时,通过FreeLB的对抗训练,模型的鲁棒性得到增强,使其能够更好地处理噪声和干扰,提高了分类的准确性。此外,采用模型融合的方法将多个模型的预测结果进行融合,进一步提升了分类的效果。
参考文献
【1】Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, and Ziqing Yang. 2021. Pre-training with whole word masking for chinese bert. IEEE/ACM Transactions on Audio, Speech, and Language Processing,29:3504–3514.
【2】Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
【3】Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2017.Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083.
【4】Takeru Miyato, Andrew M Dai, and Ian Goodfellow. 2016. Adversarial training methods for semivised text classifification. arXiv preprint arXiv:1605.07725.
【5】Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, and Jingjing Liu. 2019. Freelb: Enhanced adversarial training for natural language understanding. arXiv preprint arXiv:1909.11764.
版权归原作者 余俊晖 所有, 如有侵权,请联系我们删除。