
参考:
yty的小迷弟_【头歌平台】人工智能-深度学习初体验
HNU岳麓山大小姐_人工智能导论:深度学习初体验
A橙_人工智能-实验四
一.实验目的
1、了解深度学习的基本原理;
2、能够使用深度学习开源工具;
3、应用深度学习算法求解实际问题。
二、实验要求
1、解释深度学习原理;
2、采用深度学习框架完成课程综合实验,并对实验结果进行分析;
3、回答思考题。
三、实验平台(2选1)
1、课程实训平台 https://www.educoder.net/paths/369
2、华为云平台(推荐使用昇腾910、ModelArts、OCR识别、图像识别等完成综合实验)
https://www.huaweicloud.com/
四、实验内容与步骤
头歌_深度学习初体验
1.第1关 什么是神经网络
(1)题一
全连接网络包含输入层、隐藏层和输出层

- 输入层表示用来接收数据输入的一组神经元。
- 输出层表示用来输出的一组神经元。
- 隐藏层表示介于输入层与输出层之间的一组神经元。
- 对
(2)题二
层数较多的神经网络为深层神经网络
- 如果神经网络的层数比较多,我们就成为这样的神经网络为深层神经网络。
- 如果用深层神经网络来完成我们想要的功能,我们就叫它为深度学习
深度学习:
- 构建多层隐藏层的人工神经网络;
- 通过卷积,池化,误差反向传播等手段,进行特征学习,提高分类或预测的准确性。
- 深度学习通过增加网络的深度,减小每层需要拟合的特征个数,逐层提取底层到高层的信息,达到更好的预测和分类性能。强调模型结构的深度,通常有5层以上的隐藏层。
- 对
(3)题三
ReLU(11)=11
ReLU 函数的公式:f(x)=max(0,x)
图像:
- 对
(4)题四
下列说法错误的是
A、用深层神经网络实现想要的功能就是深度学习
B、神经网络的灵感来自于人类大脑的神经系统的构成
C、含有1层隐藏层的神经网络称之为深层神经网络
- C
2.第2关 反向传播
(1)题一
反向传播主要是为了计算参数对损失函数的梯度?
- 训练与预测: - 预测过程:前向传播的过程;- 训练过程:重复前向传播加反向传播的过程
- 反向传播- 不断地寻找合适的 W 和 b 来让预测输出与真实标签之间差异最小的过程- (1)衡量差异:损失函数- 输入:预测输出和真实标签- 输出:量化差异的大小- 分类问题-使用交叉熵损失;回归问题-使用均方误差等- (2)迭代更新 W 和 b:梯度下降算法- 目的:找到使损失函数下降最快的方向,进行参数调优- 计算 W 和 b 对于损失函数的偏导;- W 和 b 对于神经元中线性计算部分的偏导,线性计算部分对于损失函数的偏导

- 对
(2)题二
梯度下降是一种迭代更新的算法?
- 对
(3)题三
神经网络的训练过程只有前向传播过程?
- 错
3.第3关 CNN识别手写数字;
(1)卷积神经网络CNN
- 作用:常用于图像识别。CNN是识别二维形状的一个多层感知器,对于平移、比例缩放、旋转等其他形式的变相具有一定的不变性
- 算法思想:- 将局部感知,权值共享以及下采样这三种结构结合,达到图像降维的特征学习。- 通过卷积、池化的方式提取图像特征,减少像素信息,然后建立全连接网络进行分类【卷积,池化,全连接网络合理的组合】
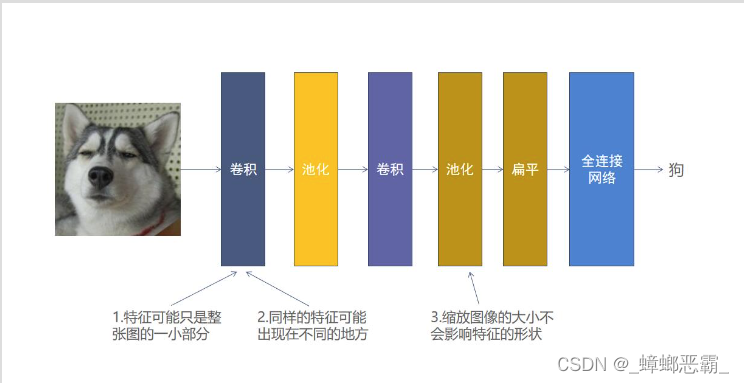
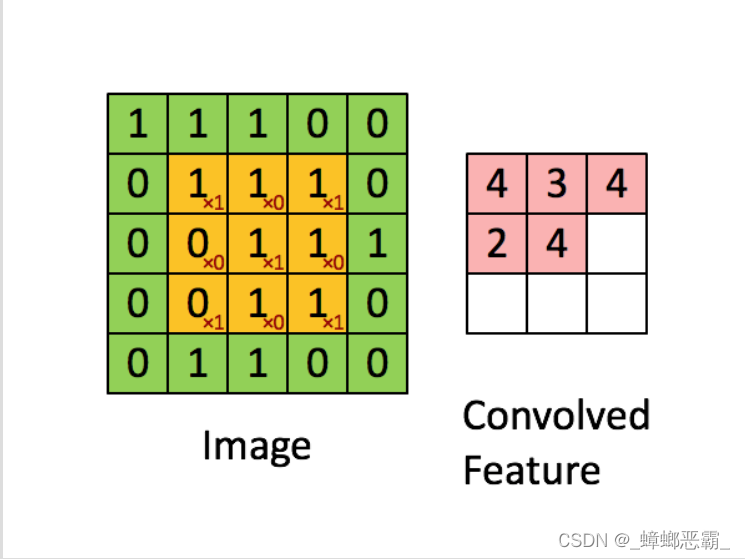
- 卷积- 目的:提取图像中物体的特征(卷积核)- 算法思路:一个卷积核(其实就是一个带权值的滑动窗口)在图像上从左到右,从上到下地扫描,每次扫描时卷积核与当前被卷积核覆盖的矩阵做内积,得到特征图。- 特征图:体现了图像与卷积核的相似程度(也就是内积的计算结果);- 考虑:特征可能只占图像的一小部分、同样的特征可能出现在不同的图像中不同的位置- 卷积核如何确定:训练出来
- 池化- 目的:缩小输入图像,减少像素信息;减少后续卷积的计算量;保留最佳的特征- 算法思路-最大池化:保留了每一小块内(2*2的矩阵)的最大值,也就是相当于保留了这一块最佳的匹配结果(卷积得到的特征图,值越大,与卷积核越相似)- 考虑:缩放图像的大小对物体的特征影响可能不大

- 全连接网络- 目的:卷积与池化提取图像中物体的特征后,使用全连接网络来进行分类- 输入层:对图像进行卷积,池化等计算之后并进行扁平后的特征图- 隐藏层:每一个神经元可以看成是一个很简单的线性分类器和激活函数的组合- 输出层:神经元的数量一般为标签类别的数量,激活函数为 softmax (因为将该图像是猫或者狗的得分进行概率化)

(2)使用 Keras 构建卷积神经网络
- 不用自己实现细节,直接实例化sequential对象,然后添加层(卷积、池化、全连接训练)就行
- ①实例化Sequential对象:
from keras.models import Sequential
model = Sequential()
- 往 Sequential 对象中添加层add - add 的对象是 Layer 对象, Layer 对象有很多种,例如 Conv2D (卷积层), MaxPooling2D (最大池化层), Flatten (扁平层), Dense (全连接层)等
- ②add全连接层
'''
units=64表示这层有64个神经元
activation='relu'表示这层的激活函数是relu
'''
model.add(Dense(units=64, activation='relu')
- ③add 一层卷积层
'''
16表示该卷积层有16个卷积核
kernel_size=3表示卷积核的大小为3*3
activation='relu'表示卷积层的激活函数是relu
input_shape=[IMAGE_HEIGHT, IMAGE_WIDTH, 3]表示待卷积图像为32*32的3通道图像
'''
model.add(Conv2D(16, kernel_size=3, activation='relu', input_shape=[32,32,3]))
- ④add 一层最大池化层
'''
pool_size=2表示池化窗口的大小为2*2
'''
model.add(MaxPooling2D(pool_size=2))
- ⑤add 一层扁平层
'''
卷积或者池化后想要接上全连接层之前需要接入扁平层
'''
model.add(Flatten())
- ⑥compile函数编译模型 作用:指定损失函数、参数的更新方法等信息。
'''
loss='categorical_crossentropy'表示使用交叉熵损失函数
optimizer=keras.optimizers.SGD(lr=0.0001)表示训练时使用mini-batch梯度下降方法来更新参数,学习率为0.0001
metrics=['accu\fracy']表示训练时模型主要考量正确率
'''
model.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.SGD(lr=0.0001),
metrics=['accu\fracy'])
- ⑦ fit 函数训练模型 传入训练集的图像、训练集图像所对应的 onehot 编码、训练的迭代次数以及 batch 数量即可
'''
images表示的是训练集图像
onehot表示的是训练集图像所对应的onehot编码
epochs=5表示的是迭代5次
batch=32表示batch的数量是32
verbose=0表示在训练过程中不打印损失值、正确率等信息
'''
model.fit(images, onehot, epochs=5, batch_size=32, verbose=0)
- ⑧predict 函数预测模型
'''
images表示待预测图像
batch_size表示batch的数量
'''
result = model.predict(images, batch_size=32)
(3)编程-完整代码
- 要求- 64 个 55 的卷积核组成的卷积层,激活函数为 relu;- 最大池化层,池化核大小为 22;- 扁平;- 128 个神经元的全连接层,激活函数为 relu;- 10 个神经元的全连接层,激活函数为 softmax。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
import numpy as np
# 设置随机种子
np.random.seed(1447)defbuild_model():'''
在Begin-End段中构建出如下结构的卷积神经网络
1.64个5*5的卷积核组成的卷积层,激活函数为relu
2.最大池化层,池化核大小为2*2
3.扁平
4.128个神经元的全连接层,激活函数为relu
5.10个神经元的全连接层,激活函数为softmax
:return: 构建好的模型
'''
model = Sequential()
model.add(Conv2D(32,(5,5), activation='relu', input_shape=[28,28,1]))#********* Begin *********#
model.add(Conv2D(64,(5,5), activation='relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))#********* End *********#return model
# 包含两个卷积层,一个池化层,然后连接了一个扁平层,# 扁平层的作用是将多维的输入一维化,用在从卷积层到全连接层的过渡,# 最后连接了两个全连接层,输出结果。
4.第4关 RNN分析影评情感
(1)循环神经网络RNN
- 与卷积神经网络CNN的对比- CNN :通常用于计算机视觉领域- RNN :通常作用于语言处理( RNN 或者 RNN 的变种)- 语言处理用RNN的原因: - 语言的数据量十分庞大,使用 CNN 进行训练需要的参数存在几何倍增加- 语言有一定的时序,CNN 的层与层之间是独立的,处理非时序的问题比较强大,而RNN 会“记住”之前的内容
- 算法思想:两部分输入 - x:当前时刻输入的外部数据- 上一个神经元传递的 s,s 代表的是内部数据也就是上一个神经元经过计算后保留的记忆

(2)使用 Keras 构建循环神经网络
Embedding层:
- 实现语义空间到向量空间的映射
- 把每个词语都转换为固定维数的向量,并且使语义接近的两个词转化为向量后,这两个向量的相似度也高。
from keras.layers import Embedding, SimpleRNN, Dense
from keras import Sequential
model = Sequential()# 对输入的影评进行word embedding,一般对于自然语言处理问题需要进行word embedding
model.add(Embedding(1000,64))# 构建一层有40个神经元的RNN层
model.add(SimpleRNN(40))# 将RNN层的输出接到只有一个神经元全连接层
model.add(Dense(1, activation='sigmoid'))
(3)编程-完整代码
- 要求- 有 30 个神经元的 SimpleRNN 层;- 有 16 个神经元的全连接层,激活函数为 relu;- 有 1 个神经元的全连接层,激活函数为 sigmoid
from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN, Dense
defbuild_model():'''
在Begin-End段中构建如下结构的循环神经网络
1.有30个神经元的SimpleRNN层
2.有16个神经元的全连接层,激活函数为relu
3.有1个神经元的全连接层,激活函数为sigmoid
:return: 构建好的模型
'''
model = Sequential()
model.add(Embedding(1000,64))#********* Begin *********#
model.add(SimpleRNN(30))
model.add(Dense(units=16, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))#********* End *********#return model
5.第5关 猫狗大战(猫狗识别)
(1)数据简介
- Dogs vs. Cats 比赛的训练数据集总共有 25000 张图片(狗= 1 ,猫= 0 )
- 实训从该数据集中随机抽取了 500 张图作为训练集,100 张图作为测试集,并分别位于 train_data 和 test_data 两个目录中 - 其中 train_data 目录中的图片的文件名命名格式如下图所示:

(2)数据的读取与预处理
- ①读取图片- OpenCV库:读取图片,并缩放到固定的宽和高
# 导入 cv2 import cv2
#使用 imread 函数来读取图片,其中 filename 是想要读取的图片路径。
img = cv2.imread(filename)#由于训练集中的图片大小不一,所以需要将读取到的图片强制缩放到固定的宽和高# resize 函数,其中 (32, 32) 的意思是将源图像缩放成宽和高都是 32 个像素的图像。
resized_image = cv2.resize(img,(32,32))
- ②图像归一化- 目的:提高卷积神经网络在梯度下降时的速度,减少损失的震荡程度- 图像的数据结构:opencv 读取后的图像是使用 numpy 的 ndarray 这一数据结构来表示的
img = img /255.0
- ③onehot编码- 背景: - 遍历 train_data 目录中的图片时,可以根据图片的名字来确定图片对应的标签( 0 (猫),1 (狗))- 在使用神经网络训练前,需要对标签进行 onehot 编码处理。- onehot编码:分类变量作为二进制向量的表示。 - 首先,将分类值映射到整数值。- 然后,每个整数值被表示为二进制向量;- 除了整数的索引之外,它都是零值,被标记为 1
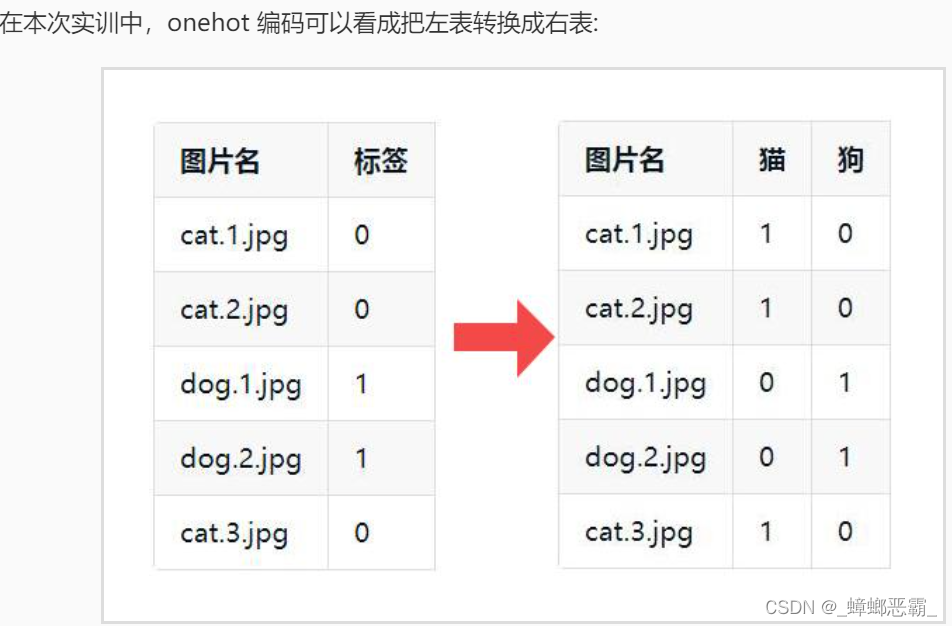 - 把真实标签中所有可能的结果作为列(这里只有猫和狗,所以猫和狗作为列),然后把对应的列填上 1 和 0
- 把真实标签中所有可能的结果作为列(这里只有猫和狗,所以猫和狗作为列),然后把对应的列填上 1 和 0
# 先用 numpy 的 zeros 函数分配好空间# row 指的是有多少张训练集图片,col 指的是有多少种标签
onehot = np.zeros((row, col))# 然后根据图片名字在对应的列上填 1 即可#(在这里假设 onehot 的第 1 列是猫,第 2 列是狗)
- ④实现猫狗分类- 建立、训练模型:
model = keras.Sequential()
model.add(Conv2D(32, kernel_size=3, activation='relu', input_shape=[IMAGE_HEIGHT, IMAGE_WIDTH,3]))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(32, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
model.add(Dense(96, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.Adam(lr=0.0001),
metrics=['accu\fracy'])
model.fit(images, onehot, epochs=20, batch_size=32, verbose=0)
- 预测:
result = model.predict(images, batch_size=32)# 得到预测结果
predict_idx = np.argmax(result, axis=1)
(3)可以通过、不可以通过的代码,及对比
①可以通过的
yty的小迷弟_【头歌平台】人工智能-深度学习初体验
from keras.layers import Dense, Activation, Flatten, Dropout, Conv2D, MaxPooling2D
import keras
import os
import numpy as np
import cv2
# 设置随机种子
np.random.seed(1447)
IMAGE_HEIGHT =128
IMAGE_WIDTH =128defget_train_data(data_path):'''
读取并处理数据
:return:处理好的图像和对应的one-hot编码
'''
images =[]
onehot = np.zeros((500,2))#********* Begin *********#for i, img_name inenumerate(os.listdir(data_path)):if'cat'in img_name:
onehot[i,0]=1else:
onehot[i,1]=1
img = cv2.imread(os.path.join(data_path, img_name))
img = cv2.resize(img,(IMAGE_HEIGHT, IMAGE_WIDTH))
images.append(np.array(img,"float32")/255.0)#********* End *********#return np.array(images), onehot
defbuild_model():'''
构建模型
:return:构建好的模型
'''
model = keras.Sequential()#********* Begin *********#
model.add(Conv2D(32, kernel_size=3, activation='relu', input_shape=[IMAGE_HEIGHT, IMAGE_WIDTH,3]))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(32, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
model.add(Dense(96, activation='relu'))
model.add(Dense(2, activation='softmax'))#********* End *********#return model
deffit_and_predict(model, train_images, onehot, test_images):'''
训练模型,并对测试图像进行预测
:param model: 训练好的模型
:param train_images: 训练集图像
:param onehot: 训练集的one-hot编码
:param test_images: 测试集图像
:return: 预测结果
'''#********* Begin *********## 编译模型
model.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.Adam(lr=0.0001), metrics=['accuracy'])#********* End *********#
model.fit(train_images, onehot, epochs=20, batch_size=32, verbose=0)
result = model.predict(test_images, batch_size=10)
predict_idx = np.argmax(result, axis=1)return predict_idx
②不能通过的
from keras.layers import Dense, Activation, Flatten, Dropout, Conv2D, MaxPooling2D
import keras
import os
import numpy as np
import cv2
# 设置随机种子
np.random.seed(1447)
IMAGE_HEIGHT =128
IMAGE_WIDTH =128defget_train_data(data_path):'''
读取并处理数据
:return:处理好的图像和对应的one-hot编码
'''
images =[]
onehot = np.zeros((500,2))#********* Begin *********#for i, img_name inenumerate(os.listdir(data_path)):if'cat'in img_name:
onehot[i,0]=1else:
onehot[i,1]=1
img = cv2.imread(os.path.join(data_path, img_name))
img = cv2.resize(img,(IMAGE_HEIGHT, IMAGE_WIDTH))
img = img /255.0
images.append(img)#********* End *********#return np.array(images), onehot
defbuild_model():'''
构建模型
:return:构建好的模型
'''
model = keras.Sequential()#********* Begin *********#
model.add(Conv2D(32, kernel_size=3, activation='relu', input_shape=[IMAGE_HEIGHT, IMAGE_WIDTH,3]))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(32, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
model.add(Dense(96, activation='relu'))
model.add(Dense(2, activation='softmax'))#********* End *********#return model
deffit_and_predict(model, train_images, onehot, test_images):'''
训练模型,并对测试图像进行预测
:param model: 训练好的模型
:param train_images: 训练集图像
:param onehot: 训练集的one-hot编码
:param test_images: 测试集图像
:return: 预测结果
'''#********* Begin *********## 编译模型
model.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.Adam(lr=0.0001), metrics=['accuracy'])#********* End *********#
model.fit(train_images, onehot, epochs=20, batch_size=32, verbose=0)
result = model.predict(test_images, batch_size=10)
predict_idx = np.argmax(result, axis=1)return predict_idx
③不同
- 上面通过、不通过的不同之处只在于函数get_train_data(data_path)的图像归一化部分:
# 通过版本
images.append(np.array(img,"float32")/255.0)# 不通过版本
img = img /255.0
images.append(img)
- 两种实现的异同:- 同:都是将图像数据归一化到[0, 1]范围内- 异: - error(img=img/255.0): 假设img是一个包含像素值的数组或矩阵,其数据类型为浮点数或整数。- rigth(np.array(img, “float32”)):首先将图像img转换为浮点数数组,然后再将其归一化到[0, 1]范围内
- 结论:把img先变成float32类型,再进行除法就可以通过(这里改成float64的话也会出错)
# right
img = img.astype("float32")/255.0
img = img.astype(np.float32)/255.0# error
img = img.astype(float)/255.0
img = img.astype("float")/255.0
img = img.astype(np.float)/255.0
img = img.astype("float64")/255.0
img = img.astype(np.float64)/255.0
五、思考题:
1.深度算法参数的设置对算法性能的影响?
深度学习中的参数是控制模型结构、训练效率、训练效果的关键。常见的参数及对模型训练的影响如下:
- **学习率(Learning rate)**:决定在优化算法中更新参数权重的幅度。学习率可以是恒定的,逐渐降低的,基于动量的等- 学习率的值过小会降低收敛速度,增加训练时间;过大则可能导致参数在最优解两侧振荡- 可以进行动态调整,一般在开始时较大,随着迭代次数的增加减小学习率,提高稳定性
- **迭代次数(Epoch)**:训练次数;- 次数少则训练效果可能不够好- 次数过多可能导致过拟合
- 一次训练选取的**样本数(Batch size)**:影响训练时间;- 过小则可能存在梯度振荡,- 过大则梯度准确,收敛快,但容易陷入局部最优
- 优化器:常见的有SGD(随机梯度下降),dagrad(自适应梯度下降,不同参数学习率不同)等
- 激活函数:增加神经网络模型的非线性,要根据具体问题选择合适的激活函数。
- 损失函数:影响收敛速度和模型整体性能。- 回归模型常用的损失函数有均方损失函数MSE,平滑L1损失Huber,平均绝对误差MAE;- 分类问题常用交叉熵损失函数。
本文转载自: https://blog.csdn.net/qq_62323523/article/details/138504757
版权归原作者 _蟑螂恶霸_ 所有, 如有侵权,请联系我们删除。
版权归原作者 _蟑螂恶霸_ 所有, 如有侵权,请联系我们删除。