
1.关于mmdeploy
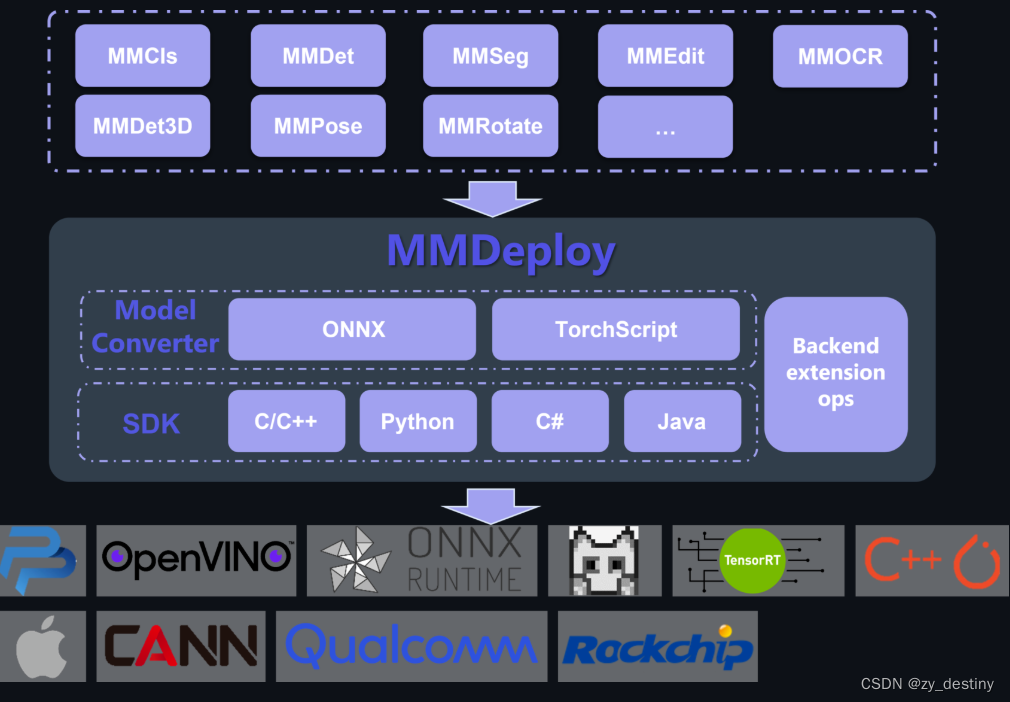
MMDeploy 是 OpenMMLab 模型部署工具箱,为各算法库提供统一的部署体验。基于 MMDeploy,开发者可以轻松从训练 repo 生成指定硬件所需 SDK,省去大量适配时间。MMDeploy 提供了一系列工具,帮助您更轻松的将 OpenMMLab 下的算法部署到各种设备与平台上。
2.环境安装
提示:不要使用mmseg工程里的deploy工具,建议使用openmmlab下的mmdeploy工程(血泪教训)。
既然是要推理部署,大概率是已经训练好模型了,基础的openmmlab环境包(mmsegmentation,mmcv-full......)应该已经安装过了,因此官网中的步骤(安装mmseg、mmcv)可以不用操作了,只需要激活本地的训练时的环境(比如:openmmlab),再安装缺少的包就可以了。
需要安装的包有:mmdeploy\onnx\tensorrt\pycuda。。。
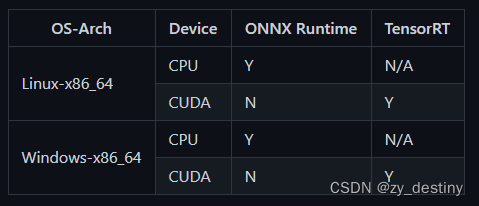
预编译好的平台和设备如下,不在的请自行下载源码编译安装。
2.1预编译安装(Linux-x86_64, CUDA 11.x, TensorRT 8.2.3.0):
wget https://github.com/open-mmlab/mmdeploy/releases/download/v0.12.0/mmdeploy-0.12.0-linux-x86_64-cuda11.1-tensorrt8.2.3.0.tar.gz
tar -zxvf mmdeploy-0.12.0-linux-x86_64-cuda11.1-tensorrt8.2.3.0.tar.gz
cd mmdeploy-0.12.0-linux-x86_64-cuda11.1-tensorrt8.2.3.0
pip install dist/mmdeploy-0.12.0-py3-none-linux_x86_64.whl
pip install sdk/python/mmdeploy_python-0.12.0-cp38-none-linux_x86_64.whl
cd ..
# 安装推理引擎 TensorRT
# !!! 从 NVIDIA 官网下载 TensorRT-8.2.3.0 CUDA 11.x 安装包并解压到当前目录
pip install TensorRT-8.2.3.0/python/tensorrt-8.2.3.0-cp38-none-linux_x86_64.whl
pip install pycuda
export TENSORRT_DIR=$(pwd)/TensorRT-8.2.3.0
export LD_LIBRARY_PATH=${TENSORRT_DIR}/lib:$LD_LIBRARY_PATH
# !!! 从 NVIDIA 官网下载 cuDNN 8.2.1 CUDA 11.x 安装包并解压到当前目录
export CUDNN_DIR=$(pwd)/cuda
export LD_LIBRARY_PATH=$CUDNN_DIR/lib64:$LD_LIBRARY_PATH
2.2预编译安装(Linux-x86_64, CUDA 11.x, ONNX):
wget https://github.com/open-mmlab/mmdeploy/releases/download/v0.12.0/mmdeploy-0.12.0-linux-x86_64-onnxruntime1.8.1.tar.gz
tar -zxvf mmdeploy-0.12.0-linux-x86_64-onnxruntime1.8.1.tar.gz
cd mmdeploy-0.12.0-linux-x86_64-onnxruntime1.8.1
pip install dist/mmdeploy-0.12.0-py3-none-linux_x86_64.whl
pip install sdk/python/mmdeploy_python-0.12.0-cp3X-none-linux_x86_64.whl #注意自己python版本对应
cd ..
# 安装推理引擎 ONNX
pip install onnxruntime-gpu==1.8.1 #安装GPU版本
pip install onnxruntime==1.8.1 #安装CPU版本
wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-1.8.1.tgz
tar -zxvf onnxruntime-linux-x64-1.8.1.tgz
export ONNXRUNTIME_DIR=$(pwd)/onnxruntime-linux-x64-1.8.1
export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH
3.mmseg工程torch转onnx
在准备工作就绪后,我们可以使用 MMDeploy 中的工具
tools/deploy.py
,将 OpenMMLab 的 PyTorch 模型转换成推理后端支持的格式。
python tools/deploy.py \
$DEPLOY_CFG \
$MODEL_CFG \
$PTH_MODEL_PATH \
--work-dir $OUT_PATH \
--show --device cuda --dump-info
其中:
DEPLOY_PATH为mmdeploy工程下./mmedeploy/configs/mmseg/XXX.py的config文件路径
MODEL_CFG为自己训练时的config文件,一般在pth模型同目录下就有
PTH_MODEL_PATH为需要转的pth模型文件地址
OUT_PATH为输出的onnx模型文件地址和对应的json存放地址
举个栗子:
python tools/deploy.py \
/root/workspace/mmdeploy/configs/mmseg/segmentation_onnxruntime_dynamic.py \
/root/workspace/mmseg/MMSEG_DEPLOY/uper_swin_base.py \
/root/workspace/mmseg/MMSEG_DEPLOY/best_mIoU_epoch_500.pth \
--work-dir /root/workspace/mmseg/MMSEG_DEPLOY/OUTPUT \
--show --device cuda --dump-info
紧接着就等待去结果路径中寻找生成的onnx模型文件吧!
4.使用onnx模型文件进行推理
推理过程比较简单,可以自行花式修改
from mmdeploy.apis import inference_model
result = inference_model(model_cfg = 'data/project/mmseg/weights/ersi_uper_swin_base.py',
deploy_cfg = '/data/project/mmdeploy-master/configs/mmseg/segmentation_onnxruntime_dynamic.py',
backend_files = ['/data/project/end2end.onnx'],
img ='in_img_path/xxx.png',
device='cuda:0')
其中:
model_cfg为训练时的config文件
deploy_cfg为mmdeploy工程下的/configs/mmseg/XXX.py文件
backend_file为刚才转出来的onnx模型地址
img就是要推理的原始影像
注意:此处输出的result为list格式,如果需要保存结果的话,需要先转成numpy再取对应的维度,最后保存成影像格式。或者参考mmseg/tools/test.py的处理方法,把所有影像预测结果append到一个大的list中,最后依次保存。
pred = (np.array(result)[0,:,:]).astype(np.uint8) #将result保存成一张影像
cv2.imwrite(out_img_path,pred)
至此,torch转ONNX的全流程就走完了,欢迎交流debug!
整理不易,欢迎一键三连!!!
版权归原作者 zy_destiny 所有, 如有侵权,请联系我们删除。