
一、引言(环境)
- 本代码基于Pytorch构成,IDE为VSCode,请在学习代码前寻找相应的教程完成环境配置。Anaconda和Pytorch的安装教程一抓一大把,这里给一个他人使用VSCode编辑器的教程:vscode+pytorch使用经验记录(个人记录+不定时更新)
- 本代码本体来源指路:用PyTorch实现MNIST手写数字识别(非常详细)
- 本教程目的在于看懂每一行代码甚至每一个参数。拒绝含混过关!非常适合初学者学习。
二、正文
1. 代码基本情况介绍
此代码在Pytorch中构建的是一个卷积神经网络(CNN),使用了两个卷积层、两个线性层,同时中间附带了Dropout2d层防止过拟合。优化器方面选择的是带有动量的随机梯度下降法(SGD),损失函数使用的是负对数似然损失函数(negative log likelihood loss)
上面很多专有名词听不懂?没关系,下面会一个一个解释!
在功能上,代码包含了MNIST数据集的下载与保存与加载、卷积神经网路的构建、模型的训练、模型的测试、模型的保存、模型的加载与继续训练和测试、模型训练过程、测试过程的可视化、模型的使用。
2. MNIST数据集介绍
MNIST数据集是一个手写数字识别数据集,由60,000个训练图像和10,000个测试图像组成。每个图像都是28x28像素的灰度图像,表示0到9之间的数字。数据集中的图像已经被标记为它们所代表的数字。
该数据集最初由Yann LeCun等人创建,用于评估机器学习算法在手写数字识别任务上的性能。由于其简单性和广泛使用,它已成为机器学习领域的基准数据集之一,也被广泛用于计算机视觉和深度学习的教学和研究。
3. 代码输出结果介绍
为了更方便更直观的感受本代码的运行,并考察本代码是否满足需求,这里提供代码的输出,如果对输出结果也一头雾水也不要紧,直接去看代码!
数据集取样:

这里抽取了6个MNIST数据集中的内容,Ground Truth代表其图片本身所表示的正确数字,也是所谓的“标签”。
训练信息输出:

这是训练和测试的信息输出,第一波训练会进行【3】次 ,第二波加载模型和优化器后继续训练会训练【5】次。训练信息包括当前epoch、batch号、已处理的样本数、总样本数、当前batch的损失值等;测试信息包括测试集的平均损失、正确预测的样本数量、测试集的总样本数量以及正确预测的样本占比。
前三次训练成果以及预测:
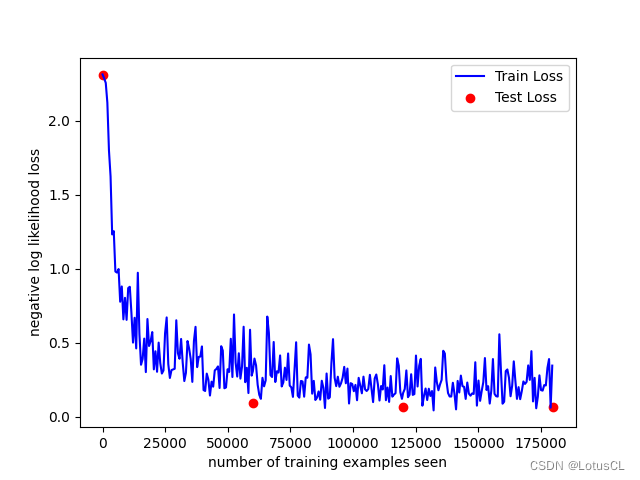

前一张图像是对前三次训练过程进行可视化,y轴是负对数似然损失函数值,即代表模型的训练效果,损失越小越好;x轴则是参与训练的样本数量。蓝色的线是训练loss,红色的点是测试loss。
后一张图片则是随机抽样并对图片进行预测。上方的prediction后的数字就是用模型预测出来的值,可以跟下方的图片进行对照观察模型预测是否正确。
八次训练的结果:
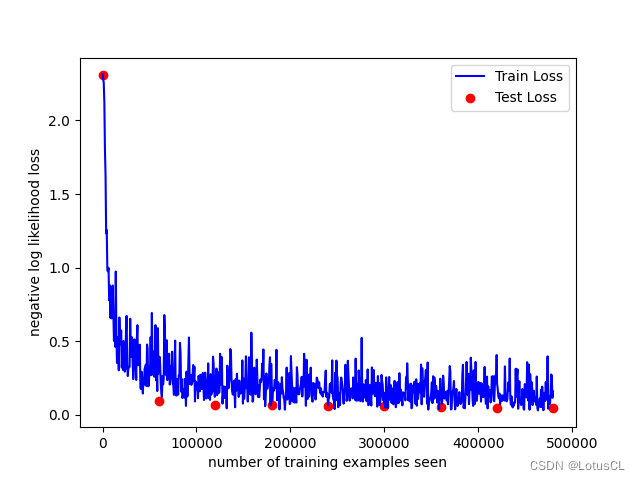
这是在进行了8次训练后的结果图像。
4. 代码拆解讲解
这里将会分部分对代码进行拆解讲解,大家也可以滑倒最下面直接复制走完整代码进行学习,完整代码中的注释将包含本拆解讲解的所有内容。 如果代码注释中出现“具体看上面”等字眼,那么说明这里有对概念作详细的解释,解释内容以引用块的形式放在了代码下方。
基本的参数设定
# 循环整个训练数据集的次数
n_epochs = 3
# 一次训练的样本数量
batch_size_train = 64
# 一次测试的样本数量
batch_size_test = 1000
# 学习率,也可以理解为梯度下降法的速度
learning_rate = 0.01
# 动量,在后续的SGD中会使用
momentum = 0.9
# 记录的频率,后续会看到
log_interval = 10
# 为所有随机数操作设置随机种子
random_seed = 1
torch.manual_seed(random_seed)
这里包含了代码需要用到的所有重要参数,包括训练次数、训练batch(训练将被拆解成多个批次(batch))设置、测试batch设置、学习率(即优化器,也即梯度下降的速度)、动量、记录频率等。
MNIST数据集下载、保存与加载
# batch_size (int): 每个批次的大小,即每次迭代中返回的数据样本数。
# shuffle (bool): 是否在每个 epoch 之前打乱数据。如果设置为 True,则在每个 epoch 之前重新排列数据集以获得更好的训练效果。
# torchvision.datasets.MNIST
# root:下载数据的目录;
# train决定是否下载的是训练集;
# download为true时会主动下载数据集到指定目录中,如果已存在则不会下载
# transform是接收PIL图片并返回转换后版本图片的转换函数,
# transform 函数是一个 PyTorch 转换操作,它将图像转换为张量并对其进行标准化,其中均值为 0.1307,标准差为 0.3081。
# 即将每一个图像像素的值减去均值,除以标准差,如此使它们有相似的尺度,从而更容易地训练模型。
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
torch.utils.data.DataLoader 是 PyTorch 中的一个数据加载器,用于将数据集封装成可迭代对象,方便数据的批量读取和处理。它可以自动进行数据的分批、打乱顺序、并行加载等操作,同时还支持多进程加速。通常在训练神经网络时会使用 DataLoader 来读取数据集,并配合 Dataset 类一起使用。
epoch的解释:一个 epoch 表示对整个数据集进行一次完整的训练。通常情况下,一个 epoch 的迭代次数等于数据集的大小除以批次大小。例如,如果数据集包含 1000 个样本,批次大小为 10,则一个 epoch 的迭代次数为 100。
·
在训练深度神经网络时,需要多次执行 epoch 过程。通过多次迭代整个数据集,模型可以在训练过程中不断优化参数,不断提升预测性能。一个 epoch 包括将整个数据集中的所有样本都输入到模型中进行前向传播、计算损失、反向传播更新参数的过程。在完成一个 epoch 后,模型就会基于整个数据集上的训练结果进行了一次更新。
PIL的解释:PIL(Python Imaging Library)是一个用于处理图像的Python库,它提供了几种常见的图像处理操作,例如缩放、剪裁、旋转和滤镜等。PIL图像是由PIL库加载的图像对象,可以使用PIL中提供的方法对其进行各种操作和处理。
神经网络模型
# 开始建立神经网络模型,Net类继承nn.Module类,
class Net(nn.Module):
def __init__(self):
# 完成一些模型初始化和必要的内存分配等工作。确保Net类正确继承了nn.Module的所有功能。
super(Net, self).__init__()
# 定义了一个名为self.conv1的卷积层对象,输入通道数为1(因为是灰度图像),输出通道数为10,卷积核大小为5x5。
# 这意味着该卷积层将对输入进行一次5x5的卷积操作,并将结果映射到10个输出通道上。
# 不过这里的卷积操作有说每个卷积核都会随机初始化权重和偏置项。这里我比较好奇是什么意思, 是一开始随即赋值,然后在模型的反向传播过程中,它们会被更新以最小化损失函数,并使神经网络能够更准确地进行预测吗
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
# 同理,第二行代码定义了一个名为self.conv2的卷积层对象,输入通道数为10(因为self.conv1的输出通道数为10),
# 输出通道数为20,卷积核大小为5x5。该卷积层也将对其输入进行一次5x5的卷积操作,并将结果映射到20个输出通道上。
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
# 设置Dropout2d层,这个的解释可以看最上面,作用是随机丢弃部分数据,防止过拟合
self.conv2_drop = nn.Dropout2d()
# 创建线性层(全连接层)接收一个320维的输入张量,并将其映射到一个50维的特征空间中。
self.fc1 = nn.Linear(320, 50)
# 同理,此线性层接收50维的特征向量,并将其映射到10维的输出空间中。
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
# relu函数用于执行ReLU(Rectified Linear Unit)激活函数,将小于0的数据替换为0。max_pool2d函数用于执行最大池化层采样操作,具体含义见上
# 这里就是先对输入数据x执行一次卷积操作,将其映射到10个输出通道上,然后对卷积操作的结果进行2x2的最大池化操作。
# 最大池化操作中参数为:input,输入张量;kernel_size,池化层窗口大小,stride:步幅,默认为kernel_size
x = F.relu(F.max_pool2d(self.conv1(x), 2))
# 和上面同理,不同的是增加了Dropout2d层,防止数据过拟合
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# 将输入x的形状从(batch_size, num_channels, height, width)变换为(batch_size, 320),
# 其中batch_size表示输入的数据样本数,num_channels表示输入数据的通道数,height表示输入数据的高度,width表示输入数据的宽度。
# 在这里,-1参数表示自动推断该维度上的大小,因为可以根据输入数据的大小自动确定batch_size的大小。
# 另外,320的大小是通过卷积层和池化层的输出计算得到的。具体计算过程可以看上面。
x = x.view(-1, 320)
# 将输入x通过全连接层self.fc1进行线性变换,然后使用ReLU激活函数对输出结果进行非线性变换
x = F.relu(self.fc1(x))
# 在传递给全连接层之前,在输入张量x上应用dropout操作。
# 其中,self.training是Net类中的一个布尔值参数,用于指示当前模型是否处于训练模式。
# 当self.training为True时,dropout操作将被启用,否则所有神经元都被保留,不进行dropout操作。
# 这样,在测试或评估模型的时候,dropout操作就会被关闭,模型将使用完整的权重来进行预测,以提高预测准确性。
# 对于其的补充说明可以看上面
x = F.dropout(x, training=self.training)
# 将输入x通过全连接层self.fc1进行线性变换,最终映射至10个通道中,这是因为我们想将其分为10个类别
x = self.fc2(x)
# 进行softmax操作然后再取对数,softmax这个操作的含义可以看上面,简而言之就是求取每个类别的概率并归一化
# dim=1 意思是对x的第二维度进行操作,x现在为(batch_size, 10),也就是在10(num_classes)这个地方进行操作。
# 取对数的原因也是为了更方便计算和求取损失,具体可以看上面的补充解释。
return F.log_softmax(x, dim=1)
torch.nn:torch.nn是PyTorch深度学习框架中的一个模块,它提供了各种用于搭建神经网络的类和函数,例如各种层(如全连接层、卷积层等)、激活函数(如ReLU、sigmoid等)以及损失函数(如交叉熵、均方误差等),可以帮助用户更方便地搭建、训练和评估神经网络模型。
卷积层的工作原理:卷积层是神经网络中常用的一种层类型,它通过卷积操作对输入数据进行特征提取和转换。在卷积层中,输入数据通常是一个多通道的二维矩阵,例如一张彩色图像。卷积层包括若干个卷积核(也称过滤器),每个卷积核都是一个小的二维矩阵,其大小一般远小于输入数据的大小。卷积操作就是将卷积核在输入数据上滑动并按元素相乘得到一个新的二维矩阵。这个过程可以看作是一种局部的线性变换,将输入数据中的某些位置和周围邻域的信息合并起来得到新的特征表示。
·
在卷积操作后,可以使用激活函数(如ReLU)对结果进行非线性变换,从而增强卷积层的表达能力。此外,还可以加入偏置项进行平移操作,以进一步增强模型的灵活性和表达能力。卷积层的输出通常会被送入下一层进行处理,或者直接作为模型的输出结果。由于卷积核的参数可以共享,卷积层具有很强的参数复用性,可以大大减少模型的参数数量和计算量,从而提高模型的效率和性能。
Dropout2d层:Dropout2d层是深度学习中常用的一种正则化技术,可以随机地“丢弃”(即将它们的值设置为0)输入张量中的部分特征图。这有助于减少模型对输入数据的过拟合程度,提高泛化能力。
·
Dropout2d层的补充说明:正则化:
在机器学习中,正则化是一种用于减少过拟合的技术。在训练模型时,如果模型过度拟合训练数据,那么它将不能很好地泛化到新的数据上,这将导致性能下降。正则化技术通过修改模型的损失函数,在训练过程中“惩罚”模型参数的大小或复杂性,从而限制模型的学习能力,防止其过拟合训练数据。正则化技术可以应用于不同类型的模型和任务,包括线性回归、逻辑回归、神经网络等,在实践中被广泛使用。
线性层(全连接层):线性层是深度学习神经网络的基本组成部分之一,其工作原理是将输入数据进行矩阵乘法并加上一个偏置向量,得到输出结果。具体地说,每个输入特征都与权重矩阵中的对应元素相乘,然后将所有结果相加,在加上偏置向量。这个过程可以用下面的公式表示:
·
y = Wx + b其中,W是权重矩阵,x是输入向量,b是偏置向量,y是输出向量。
·
线性层的作用在于对输入数据进行线性转换,从而为神经网络提供更高级别的特征。权重矩阵和偏置项是通过训练神经网络来确定的。在训练过程中,神经网络根据给定的输入和正确的输出来不断调整权重矩阵和偏置项,以使得网络能够更准确地预测输出。训练使用反向传播算法进行,该算法计算每个权重对误差的贡献,并相应地更新权重矩阵和偏置项。最终,经过足够的训练,权重矩阵和偏置项将被优化以使得神经网络能够更好地适应输入输出的关系。
最大池化操作:在卷积神经网络中,池化(Pooling)是一种常用的操作。其中最大池化(Max Pooling)是一种常见的降采样函数,通常用于减小特征图的空间尺寸大小并增强模型的位置不变性。最大池化层的工作原理是在输入的局部感受野中选取最大响应值,并将其作为输出。池化窗口在输入张量上滑动,并计算每个窗口内元素的最大值。具体来说,最大池化层将目标图像的每个矩形区域替换为该区域内的最大的数值。池化窗口的大小和步幅是可以调节的,通常在池化过程中间隔着一个固定的滑动窗口,它的大小和步幅可以设置。
·
例如,对于一个2x2的池化窗口,如果输入数据是4x4大小,一般会将池化窗口从左到右、从上到下遍历整个输入数据,然后选出每个窗口内的最大值作为池化操作的输出。这样,就能够将输入数据的尺寸缩小到原来的1/4,而且仍然保留了最显著的特征信息。需要注意的是,最大池化层并不会学习任何参数,它只是对输入进行固定的数值计算。因此,最大池化层通常被用于特征降维和提取。
** 这里的ReLU激活函数**:当输入张量中元素小于零时,该函数将它们替换为零;否则保持不变。ReLU激活函数在深度学习中被广泛使用,因为它可以增加模型的稀疏性和非线性特征表达能力,并且计算速度快。
320是如何计算出来的:假设输入数据的大小为(1, 1, 28, 28),其中1表示batch_size,1表示输入数据的通道数,28表示输入数据的高度,28表示输入数据的宽度。事实上,在MNIST数据集中,每张图片也是28*28的灰度图片
·
在经过第一个卷积层之后,输出的形状为(1, 10, 24, 24),其中10表示输出特征图的数量,24表示特征图的高度和宽度都减少了4个像素(由于卷积核大小为5,步长为1,因此特征图的高度和宽度都会减少4个像素)。
·
接着,经过第一个池化层之后,输出的形状为(1, 10, 12, 12),其中12=24/2,即特征图的高度和宽度都减少了一半。同理,经过第二个卷积层之后,输出的形状为(1, 20, 8, 8),其中20表示输出特征图的数量,8=12-2x2,即特征图的高度和宽度都减少了4个像素。最后,经过第二个池化层之后,输出的形状为(1, 20, 4, 4),其中4=8/2,即特征图的高度和宽度都减少了一半。
·
因此,假设输入数据的大小为(1, 1, 28, 28),并且经过了两个卷积层和两个池化层之后,其输出大小为(1, 20, 4, 4)。因此320 = 20 * 4 * 4,将每个样本的所有通道的像素值拉成一行,最终得到一个(batch_size, 320)的输出张量。
F.dropout函数补充说明(其实和之前的dropout层差不多):在神经网络中,Dropout是一种常用的正则化技术,它可以随机地在神经网络的某些神经元之间添加断开连接。这个过程可以强制使神经网络学习到更加健壮和泛化的特征,因为它会防止任何一个单独的神经元对结果产生太大的影响。
softmax操作:softmax操作是一种常用的归一化方法,将一个向量中的每个元素转化为一个介于0~1之间的值,并且这些值的和等于1。它通常用于多分类问题中,以便计算损失函数和模型预测的准确性。具体来说,对于输入x的每一行,softmax操作将计算其指数值(exp(xi)),并将其除以该行所有元素的指数之和(也称为归一化常数)
·
补充:接着通常也会取对数,这是为了防止出现概率太小的情况影响计算,于是我们一般取对数以便更容易计算和优化损失。
训练前的准备
# 创建神经网络
network = Net()
# 使用SGD(随机梯度下降)优化器,注意这里的SGD是带动量的,具体解释可以看上面,还有SGD和GD的区别
# network.parameters()是要训练的参数,lr是学习率,超参数之一;momentum是动量,也是超参数之一。不过这里的动量最好设置为0.9
# network.parameters()返回一个包含了Net类中所有可训练参数的迭代器。这些可训练参数包括神经网络中的权重和偏置项等。
# 在优化器中使用这个迭代器,可以告诉优化器需要更新哪些参数以最小化损失函数。
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
# 用于记录和绘图的参数
train_losses = []
train_counter = []
test_losses = []
# [0, 60000, 120000, 180000]
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
# print(test_counter)
# breakpoint1 = input("print(test_counter): ") # 看看这里是什么
带动量的SGD:带动量的SGD算法(Momentum SGD)是SGD的一种改进,它可以加速模型的收敛并减少参数更新的震荡。SGD是随机梯度下降法,每次会抽取一定样本计算它们的梯度平均值进行更新,这也是随机梯度下降法和梯度下降法的区别,梯度下降法每次是计算所有样本。
·
具体来说,带动量的SGD算法在计算参数更新时,不仅考虑当前时刻的梯度,还会考虑之前梯度更新的方向。这个方向被称为“动量”。动量是为了进行指数加权平均操作解释可以看https://zhuanlan.zhihu.com/p/73264637,这个里面解释的比较详细,梯度每次更新的方向中都会包含前面梯度更新的方向的信息
·
补充,SGD和GD区别:普通的梯度下降法每次需要遍历全部训练数据来计算梯度并更新模型参数,而随机梯度下降法每次只使用一个样本来计算梯度并更新模型参数。经典的梯度下降法在每次对模型参数进行更新时,需要遍历所有的训练数据。当M很大的时候,就需要耗费巨大的计算资源和计算时间,这在实际过程中基本不可行。
·
随机梯度下降法(Stochastic Gradient Descent, SGD)应运而生。它采用单个训练样本的损失来近似平均损失相对于普通的梯度下降法,随机梯度下降法的优势在于速度更快、更容易逃离局部极小点、能够处理大规模数据集以及可以实时学习在线数据。然而,由于随机梯度下降法所使用的样本是随机选择的,因此其更新过程具有一定的噪声性质,需要更多的迭代次数才能收敛到全局最优解。同时,随机梯度下降法也比较难以用于处理稀疏数据。
样本训练函数
def train(epoch):
# 用于将神经网络设置为训练模式。在训练神经网络时,需要将其切换到训练模式,以便启用Batch Normalization和Dropout等高级优化技术,
# 并且在每个batch处理完毕后,可以清除所有中间状态(如梯度)以准备下一次训练。
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 是用于清除模型参数的梯度信息。在训练过程中,优化器会累加每个参数的梯度,
# 因此在每个 batch 计算结束后,需要使用 zero_grad() 清空之前累计的梯度,避免对下一个 batch 的计算造成影响。
optimizer.zero_grad()
# 获取训练结果
output = network(data)
# 损失函数定义,这里使用的是负对数似然损失函数(negative log likelihood loss),具体解释可以看上面
# F.nll_loss()函数计算了模型输出和目标输出之间的差异,并返回一个标量值作为损失值,该值越小表示模型越接近目标。
loss = F.nll_loss(output, target)
# loss.backward() 就是用来计算当前 mini-batch 的损失函数关于模型参数的梯度的代码。
# 该函数会在计算完梯度之后将它们存储在参数的 grad 属性中。接着,我们可以使用 optimizer.step() 函数来更新模型参数。
# 这里使用的是反向传播算法(backpropagation)来计算网络参数的梯度,
loss.backward()
# 使用优化器更新模型参数
optimizer.step()
# 每隔log_interval个batch打印一次训练信息,包括当前epoch、batch号、已处理的样本数、总样本数、当前batch的损失值等
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item()))
# 记录损失值
train_losses.append(loss.item())
# 记录目前已训练完成的样本数量
train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
# 将神经网络的权重和优化器的状态保存到硬盘上,方便之后加载和使用。
# network.state_dict() 返回一个字典,其中包含了神经网络的所有参数(即权重和偏置项),以及它们对应的名称。这些参数可以用来恢复网络的状态。
# torch.save() 函数将字典对象保存到指定的文件路径上。第一个参数是要保存的对象,第二个参数是文件路径。
torch.save(network.state_dict(), './model.pth')
# 这是在保存优化器的状态。
torch.save(optimizer.state_dict(), './optimizer.pth')
负对数似然损失函数(negative log likelihood loss):通常用于多分类问题。它的基本思想是将模型输出的概率分布与真实标签的 one-hot 编码进行比较,计算两者之间的差异。该损失函数先取每个样本真实标签对应的预测概率的自然对数,再对它们求平均值并取相反数,所以称为“负对数似然”损失函数。使用该损失函数最终得到的模型会使得正确分类的样本的损失越小越好,而错误分类的样本的损失越大越好,因此能够有效地训练出具有良好泛化性能的模型。
测试函数
def test():
# 将神经网络设置为评估模式。在评估模式下,模型会停用特定步骤,如Dropout层、Batch Normalization层等,
# 并且使用训练期间学到的参数来生成预测,而不是在训练集上进行梯度反向传播和权重更新。
network.eval()
test_loss = 0
correct = 0
# 关闭梯度计算,以减少内存消耗和加快模型评估过程。这意味着,在使用torch.no_grad()时,模型的参数不会被更新和优化;
# 同时,计算图也不会被跟踪和记录,这使得前向传播的速度更快。
with torch.no_grad():
for data, target in test_loader:
output = network(data)
# 记录模型的损失值。reduction='sum'表示将每个样本的损失求和后再返回。
test_loss += F.nll_loss(output, target, reduction='sum').item()
# 找到输出结果(张量)中,每一行(即第1维度)最大的那个数以及它所在的位置,返回一个元组。其中元组的第一个元素就是最大的那个数,第二个元素是最大数的位置。
# 这里的 keepdim=True 参数表示保持维度不变,也就是说返回的结果张量维度与原始张量相同。
# [1] 表示取出这个元组的第二个元素,也就是位置信息,赋给了变量 pred。这个 pred 变量就是神经网络预测出来的类别标签,
# 它的维度与原始张量第 1 维度相同,表示每一个输入数据样本对应的类别标签。
pred = output.data.max(1, keepdim=True)[1]
# target.data.view_as(pred)将 target 张量按照 pred 张量的形状进行重塑(reshape)。
# 具体地说,它会返回一个和 pred 张量形状相同、但数据来自 target 张量的新张量。
# .eq()方法来进行张量之间的逐元素比较,得到一个由布尔值组成的张量,表示pred和target.data.view_as(pred)中的每个元素是否相等。
# 如果该元素相等,则对应位置为True,否则为False。
# .sum():对前一步得到的True/False tensor沿着所有维度求和,得到预测正确的样本数。
# +=:将这个batch中预测正确的样本数添加到之前已经处理过的样本中,累加得到整个数据集中预测正确的样本数(correct)。
correct += pred.eq(target.data.view_as(pred)).sum()
# 计算样本的平均损失
test_loss /= len(test_loader.dataset)
# 记录本次的测试结果
test_losses.append(test_loss)
# 打印本次测试结果,包括测试集的平均损失、正确预测的样本数量、测试集的总样本数量以及正确预测的样本占比。
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
模型的正式训练、测试、训练测试过程可视化、模型的使用
test() # 不加这个,后面画图就会报错:x and y must be the same size,因为test_counter中包含了模型未经训练时的情况(上面打印中的“0”)
# 进入正式的训练、测试过程,根据设定的epoch进行训练
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
# 绘制整个训练和测试的图像,包括记录训练的损失变化、测试的损失变化
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
从磁盘中加载模型并继续训练
# ----------------------------------------------------------- #
# 检查点的持续训练,继续对网络进行训练,或者看看如何从第一次培训运行时保存的state_dicts中继续进行训练。
# 初始化一组新的网络和优化器。
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
# 加载网络的内部状态、优化器的内部状态
network_state_dict = torch.load('model.pth')
continued_network.load_state_dict(network_state_dict)
optimizer_state_dict = torch.load('optimizer.pth')
continued_optimizer.load_state_dict(optimizer_state_dict)
# 为什么是“4”开始呢,因为n_epochs=3,上面用了[1, n_epochs + 1)
# 继续进行5次训练
for i in range(4, 9):
test_counter.append(i*len(train_loader.dataset))
train(i)
test()
# 绘制训练的曲线
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
5. 总体代码
注意,下面这段代码已经包含上方所有科普信息和几乎每一段代码的注释,包含函数所使用的所有参数所表达的含义。大家可以直接把代码拿走一点一点看就行啦。
代码上半部分集中解释了部分的概念,但还是建议大家从第一行正式的代码看起,注释中如果有涉及到概念解释的都会进行标注,大家如果有需要可以再回到上方观看概念性注释。
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# epoch的解释:
# 一个 epoch 表示对整个数据集进行一次完整的训练。通常情况下,一个 epoch 的迭代次数等于数据集的大小除以批次大小。
# 例如,如果数据集包含 1000 个样本,批次大小为 10,则一个 epoch 的迭代次数为 100。
# 在训练深度神经网络时,需要多次执行 epoch 过程。通过多次迭代整个数据集,模型可以在训练过程中不断优化参数,不断提升预测性能。
# 一个 epoch 包括将整个数据集中的所有样本都输入到模型中进行前向传播、计算损失、反向传播更新参数的过程。
# 在完成一个 epoch 后,模型就会基于整个数据集上的训练结果进行了一次更新。
# PIL的解释:
# PIL(Python Imaging Library)是一个用于处理图像的Python库,它提供了几种常见的图像处理操作,例如缩放、剪裁、旋转和滤镜等。
# PIL图像是由PIL库加载的图像对象,可以使用PIL中提供的方法对其进行各种操作和处理。
# torch.nn
# torch.nn是PyTorch深度学习框架中的一个模块,它提供了各种用于搭建神经网络的类和函数,
# 例如各种层(如全连接层、卷积层等)、激活函数(如ReLU、sigmoid等)以及损失函数(如交叉熵、均方误差等),
# 可以帮助用户更方便地搭建、训练和评估神经网络模型。
# 卷积层的工作原理:
# 卷积层是神经网络中常用的一种层类型,它通过卷积操作对输入数据进行特征提取和转换。
# 在卷积层中,输入数据通常是一个多通道的二维矩阵,例如一张彩色图像。卷积层包括若干个卷积核(也称过滤器),每个卷积核都是一个小的二维矩阵,其大小一般远小于输入数据的大小。
# 卷积操作就是将卷积核在输入数据上滑动并按元素相乘得到一个新的二维矩阵。这个过程可以看作是一种局部的线性变换,将输入数据中的某些位置和周围邻域的信息合并起来得到新的特征表示。
# 在卷积操作后,可以使用激活函数(如ReLU)对结果进行非线性变换,从而增强卷积层的表达能力。
# 此外,还可以加入偏置项进行平移操作,以进一步增强模型的灵活性和表达能力。
# 卷积层的输出通常会被送入下一层进行处理,或者直接作为模型的输出结果。由于卷积核的参数可以共享,卷积层具有很强的参数复用性,
# 可以大大减少模型的参数数量和计算量,从而提高模型的效率和性能。
# Dropout2d层:
# Dropout2d层是深度学习中常用的一种正则化技术,可以随机地“丢弃”(即将它们的值设置为0)输入张量中的部分特征图。
# 这有助于减少模型对输入数据的过拟合程度,提高泛化能力。
# Dropout2d层的补充说明:正则化:
# 在机器学习中,正则化是一种用于减少过拟合的技术。在训练模型时,如果模型过度拟合训练数据,那么它将不能很好地泛化到新的数据上,这将导致性能下降。
# 正则化技术通过修改模型的损失函数,在训练过程中“惩罚”模型参数的大小或复杂性,从而限制模型的学习能力,防止其过拟合训练数据。
# 正则化技术可以应用于不同类型的模型和任务,包括线性回归、逻辑回归、神经网络等,在实践中被广泛使用。
# 线性层(全连接层):
# 线性层是深度学习神经网络的基本组成部分之一,其工作原理是将输入数据进行矩阵乘法并加上一个偏置向量,得到输出结果。
# 具体地说,每个输入特征都与权重矩阵中的对应元素相乘,然后将所有结果相加,在加上偏置向量。这个过程可以用下面的公式表示:
# y = Wx + b
# 其中,W是权重矩阵,x是输入向量,b是偏置向量,y是输出向量。
# 线性层的作用在于对输入数据进行线性转换,从而为神经网络提供更高级别的特征。
# 权重矩阵和偏置项是通过训练神经网络来确定的。在训练过程中,神经网络根据给定的输入和正确的输出来不断调整权重矩阵和偏置项,
# 以使得网络能够更准确地预测输出。训练使用反向传播算法进行,该算法计算每个权重对误差的贡献,并相应地更新权重矩阵和偏置项。
# 最终,经过足够的训练,权重矩阵和偏置项将被优化以使得神经网络能够更好地适应输入输出的关系。
# 最大池化操作:
# 在卷积神经网络中,池化(Pooling)是一种常用的操作。其中最大池化(Max Pooling)是一种常见的降采样函数,通常用于减小特征图的空间尺寸大小并增强模型的位置不变性。
# 最大池化层的工作原理是在输入的局部感受野中选取最大响应值,并将其作为输出。池化窗口在输入张量上滑动,并计算每个窗口内元素的最大值。
# 具体来说,最大池化层将目标图像的每个矩形区域替换为该区域内的最大的数值。池化窗口的大小和步幅是可以调节的,通常在池化过程中间隔着一个固定的滑动窗口,它的大小和步幅可以设置。
# 例如,对于一个2x2的池化窗口,如果输入数据是4x4大小,一般会将池化窗口从左到右、从上到下遍历整个输入数据,然后选出每个窗口内的最大值作为池化操作的输出。
# 这样,就能够将输入数据的尺寸缩小到原来的1/4,而且仍然保留了最显著的特征信息。
# 需要注意的是,最大池化层并不会学习任何参数,它只是对输入进行固定的数值计算。因此,最大池化层通常被用于特征降维和提取。
# 这里的ReLU激活函数:
# 当输入张量中元素小于零时,该函数将它们替换为零;否则保持不变。ReLU激活函数在深度学习中被广泛使用,因为它可以增加模型的稀疏性和非线性特征表达能力,并且计算速度快。
# 320是如何计算出来的:
# 假设输入数据的大小为(1, 1, 28, 28),其中1表示batch_size,1表示输入数据的通道数,28表示输入数据的高度,28表示输入数据的宽度。
# 事实上,在MNIST数据集中,每张图片也是28*28的灰度图片
# 在经过第一个卷积层之后,输出的形状为(1, 10, 24, 24),其中10表示输出特征图的数量,
# 24表示特征图的高度和宽度都减少了4个像素(由于卷积核大小为5,步长为1,因此特征图的高度和宽度都会减少4个像素)。
# 接着,经过第一个池化层之后,输出的形状为(1, 10, 12, 12),其中12=24/2,即特征图的高度和宽度都减少了一半。
# 同理,经过第二个卷积层之后,输出的形状为(1, 20, 8, 8),其中20表示输出特征图的数量,8=12-2x2,即特征图的高度和宽度都减少了4个像素。
# 最后,经过第二个池化层之后,输出的形状为(1, 20, 4, 4),其中4=8/2,即特征图的高度和宽度都减少了一半。
# 因此,假设输入数据的大小为(1, 1, 28, 28),并且经过了两个卷积层和两个池化层之后,其输出大小为(1, 20, 4, 4)。
# 因此320 = 20 * 4 * 4,将每个样本的所有通道的像素值拉成一行,最终得到一个(batch_size, 320)的输出张量。
# F.dropout函数补充说明(其实和之前的dropout层差不多):
# 在神经网络中,Dropout是一种常用的正则化技术,它可以随机地在神经网络的某些神经元之间添加断开连接。
# 这个过程可以强制使神经网络学习到更加健壮和泛化的特征,因为它会防止任何一个单独的神经元对结果产生太大的影响。
# softmax操作:
# softmax操作是一种常用的归一化方法,将一个向量中的每个元素转化为一个介于0~1之间的值,并且这些值的和等于1。它通常用于多分类问题中,以便计算损失函数和模型预测的准确性。
# 具体来说,对于输入x的每一行,softmax操作将计算其指数值(exp(xi)),并将其除以该行所有元素的指数之和(也称为归一化常数)
# 补充:接着通常也会取对数,这是为了防止出现概率太小的情况影响计算,于是我们一般取对数以便更容易计算和优化损失。
# 带动量的SGD:
# 带动量的SGD算法(Momentum SGD)是SGD的一种改进,它可以加速模型的收敛并减少参数更新的震荡。
# SGD是随机梯度下降法,每次会抽取一定样本计算它们的梯度平均值进行更新,这也是随机梯度下降法和梯度下降法的区别,梯度下降法每次是计算所有样本。
# 具体来说,带动量的SGD算法在计算参数更新时,不仅考虑当前时刻的梯度,还会考虑之前梯度更新的方向。这个方向被称为“动量”。动量是为了进行指数加权平均操作
# 解释可以看https://zhuanlan.zhihu.com/p/73264637,这个里面解释的比较详细,梯度每次更新的方向中都会包含前面梯度更新的方向的信息
# 补充,SGD和GD区别:
# 普通的梯度下降法每次需要遍历全部训练数据来计算梯度并更新模型参数,而随机梯度下降法每次只使用一个样本来计算梯度并更新模型参数。
# 经典的梯度下降法在每次对模型参数进行更新时,需要遍历所有的训练数据。当M很大的时候,就需要耗费巨大的计算资源和计算时间,这在实际过程中基本不可行。
# 随机梯度下降法(Stochastic Gradient Descent, SGD)应运而生。它采用单个训练样本的损失来近似平均损失
# 相对于普通的梯度下降法,随机梯度下降法的优势在于速度更快、更容易逃离局部极小点、能够处理大规模数据集以及可以实时学习在线数据。
# 然而,由于随机梯度下降法所使用的样本是随机选择的,因此其更新过程具有一定的噪声性质,需要更多的迭代次数才能收敛到全局最优解。
# 同时,随机梯度下降法也比较难以用于处理稀疏数据。
# 负对数似然损失函数(negative log likelihood loss):
# 通常用于多分类问题。它的基本思想是将模型输出的概率分布与真实标签的 one-hot 编码进行比较,计算两者之间的差异。
# 该损失函数先取每个样本真实标签对应的预测概率的自然对数,再对它们求平均值并取相反数,所以称为“负对数似然”损失函数。
# 使用该损失函数最终得到的模型会使得正确分类的样本的损失越小越好,而错误分类的样本的损失越大越好,因此能够有效地训练出具有良好泛化性能的模型。
# 循环整个训练数据集的次数
n_epochs = 3
# 一次训练的样本数量
batch_size_train = 64
# 一次测试的样本数量
batch_size_test = 1000
# 学习率,也可以理解为梯度下降法的速度
learning_rate = 0.01
# 动量,在后续的SGD中会使用
momentum = 0.9
# 记录的频率,后续会看到
log_interval = 10
# 为所有随机数操作设置随机种子
random_seed = 1
torch.manual_seed(random_seed)
# torch.utils.data.DataLoader 是 PyTorch 中的一个数据加载器,用于将数据集封装成可迭代对象,方便数据的批量读取和处理。
# 它可以自动进行数据的分批、打乱顺序、并行加载等操作,同时还支持多进程加速。通常在训练神经网络时会使用 DataLoader 来读取数据集,并配合 Dataset 类一起使用。
# batch_size (int): 每个批次的大小,即每次迭代中返回的数据样本数。
# shuffle (bool): 是否在每个 epoch 之前打乱数据。如果设置为 True,则在每个 epoch 之前重新排列数据集以获得更好的训练效果。
# torchvision.datasets.MNIST
# root:下载数据的目录;
# train决定是否下载的是训练集;
# download为true时会主动下载数据集到指定目录中,如果已存在则不会下载
# transform是接收PIL图片并返回转换后版本图片的转换函数,
# transform 函数是一个 PyTorch 转换操作,它将图像转换为张量并对其进行标准化,其中均值为 0.1307,标准差为 0.3081。
# 即将每一个图像像素的值减去均值,除以标准差,如此使它们有相似的尺度,从而更容易地训练模型。
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
# 使用了Python内置函数"enumerate"将test_loader转换为带有索引的可迭代对象,然后使用"next"函数获取下一个批次的数据和目标。
# 最终,example_data里是这个batch的数据,example_targets里是这个batch对应的所有标签
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
# print(example_targets)
# print(example_data.shape)
# 这是在绘制刚刚获取的样本batch的内容
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
# 开始建立神经网络模型,Net类继承nn.Module类,
class Net(nn.Module):
def __init__(self):
# 完成一些模型初始化和必要的内存分配等工作。确保Net类正确继承了nn.Module的所有功能。
super(Net, self).__init__()
# 定义了一个名为self.conv1的卷积层对象,输入通道数为1(因为是灰度图像),输出通道数为10,卷积核大小为5x5。
# 这意味着该卷积层将对输入进行一次5x5的卷积操作,并将结果映射到10个输出通道上。
# 不过这里的卷积操作有说每个卷积核都会随机初始化权重和偏置项。这里我比较好奇是什么意思, 是一开始随即赋值,然后在模型的反向传播过程中,它们会被更新以最小化损失函数,并使神经网络能够更准确地进行预测吗
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
# 同理,第二行代码定义了一个名为self.conv2的卷积层对象,输入通道数为10(因为self.conv1的输出通道数为10),
# 输出通道数为20,卷积核大小为5x5。该卷积层也将对其输入进行一次5x5的卷积操作,并将结果映射到20个输出通道上。
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
# 设置Dropout2d层,这个的解释可以看最上面,作用是随机丢弃部分数据,防止过拟合
self.conv2_drop = nn.Dropout2d()
# 创建线性层(全连接层)接收一个320维的输入张量,并将其映射到一个50维的特征空间中。
self.fc1 = nn.Linear(320, 50)
# 同理,此线性层接收50维的特征向量,并将其映射到10维的输出空间中。
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
# relu函数用于执行ReLU(Rectified Linear Unit)激活函数,将小于0的数据替换为0。max_pool2d函数用于执行最大池化层采样操作,具体含义见上
# 这里就是先对输入数据x执行一次卷积操作,将其映射到10个输出通道上,然后对卷积操作的结果进行2x2的最大池化操作。
# 最大池化操作中参数为:input,输入张量;kernel_size,池化层窗口大小,stride:步幅,默认为kernel_size
x = F.relu(F.max_pool2d(self.conv1(x), 2))
# 和上面同理,不同的是增加了Dropout2d层,防止数据过拟合
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# 将输入x的形状从(batch_size, num_channels, height, width)变换为(batch_size, 320),
# 其中batch_size表示输入的数据样本数,num_channels表示输入数据的通道数,height表示输入数据的高度,width表示输入数据的宽度。
# 在这里,-1参数表示自动推断该维度上的大小,因为可以根据输入数据的大小自动确定batch_size的大小。
# 另外,320的大小是通过卷积层和池化层的输出计算得到的。具体计算过程可以看上面。
x = x.view(-1, 320)
# 将输入x通过全连接层self.fc1进行线性变换,然后使用ReLU激活函数对输出结果进行非线性变换
x = F.relu(self.fc1(x))
# 在传递给全连接层之前,在输入张量x上应用dropout操作。
# 其中,self.training是Net类中的一个布尔值参数,用于指示当前模型是否处于训练模式。
# 当self.training为True时,dropout操作将被启用,否则所有神经元都被保留,不进行dropout操作。
# 这样,在测试或评估模型的时候,dropout操作就会被关闭,模型将使用完整的权重来进行预测,以提高预测准确性。
# 对于其的补充说明可以看上面
x = F.dropout(x, training=self.training)
# 将输入x通过全连接层self.fc1进行线性变换,最终映射至10个通道中,这是因为我们想将其分为10个类别
x = self.fc2(x)
# 进行softmax操作然后再取对数,softmax这个操作的含义可以看上面,简而言之就是求取每个类别的概率并归一化
# dim=1 意思是对x的第二维度进行操作,x现在为(batch_size, 10),也就是在10(num_classes)这个地方进行操作。
# 取对数的原因也是为了更方便计算和求取损失,具体可以看上面的补充解释。
return F.log_softmax(x, dim=1)
# 创建神经网络
network = Net()
# 使用SGD(随机梯度下降)优化器,注意这里的SGD是带动量的,具体解释可以看上面,还有SGD和GD的区别
# network.parameters()是要训练的参数,lr是学习率,超参数之一;momentum是动量,也是超参数之一。不过这里的动量最好设置为0.9
# network.parameters()返回一个包含了Net类中所有可训练参数的迭代器。这些可训练参数包括神经网络中的权重和偏置项等。
# 在优化器中使用这个迭代器,可以告诉优化器需要更新哪些参数以最小化损失函数。
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
# [0, 60000, 120000, 180000]
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
# print(test_counter)
# breakpoint1 = input("print(test_counter): ") # 看看这里是什么
def train(epoch):
# 用于将神经网络设置为训练模式。在训练神经网络时,需要将其切换到训练模式,以便启用Batch Normalization和Dropout等高级优化技术,
# 并且在每个batch处理完毕后,可以清除所有中间状态(如梯度)以准备下一次训练。
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 是用于清除模型参数的梯度信息。在训练过程中,优化器会累加每个参数的梯度,
# 因此在每个 batch 计算结束后,需要使用 zero_grad() 清空之前累计的梯度,避免对下一个 batch 的计算造成影响。
optimizer.zero_grad()
# 获取训练结果
output = network(data)
# 损失函数定义,这里使用的是负对数似然损失函数(negative log likelihood loss),具体解释可以看上面
# F.nll_loss()函数计算了模型输出和目标输出之间的差异,并返回一个标量值作为损失值,该值越小表示模型越接近目标。
loss = F.nll_loss(output, target)
# loss.backward() 就是用来计算当前 mini-batch 的损失函数关于模型参数的梯度的代码。
# 该函数会在计算完梯度之后将它们存储在参数的 grad 属性中。接着,我们可以使用 optimizer.step() 函数来更新模型参数。
# 这里使用的是反向传播算法(backpropagation)来计算网络参数的梯度,
loss.backward()
# 使用优化器更新模型参数
optimizer.step()
# 每隔log_interval个batch打印一次训练信息,包括当前epoch、batch号、已处理的样本数、总样本数、当前batch的损失值等
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item()))
# 记录损失值
train_losses.append(loss.item())
# 记录目前已训练完成的样本数量
train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
# 将神经网络的权重和优化器的状态保存到硬盘上,方便之后加载和使用。
# network.state_dict() 返回一个字典,其中包含了神经网络的所有参数(即权重和偏置项),以及它们对应的名称。这些参数可以用来恢复网络的状态。
# torch.save() 函数将字典对象保存到指定的文件路径上。第一个参数是要保存的对象,第二个参数是文件路径。
torch.save(network.state_dict(), './model.pth')
# 这是在保存优化器的状态。
torch.save(optimizer.state_dict(), './optimizer.pth')
def test():
# 将神经网络设置为评估模式。在评估模式下,模型会停用特定步骤,如Dropout层、Batch Normalization层等,
# 并且使用训练期间学到的参数来生成预测,而不是在训练集上进行梯度反向传播和权重更新。
network.eval()
test_loss = 0
correct = 0
# 关闭梯度计算,以减少内存消耗和加快模型评估过程。这意味着,在使用torch.no_grad()时,模型的参数不会被更新和优化;
# 同时,计算图也不会被跟踪和记录,这使得前向传播的速度更快。
with torch.no_grad():
for data, target in test_loader:
output = network(data)
# 记录模型的损失值。reduction='sum'表示将每个样本的损失求和后再返回。
test_loss += F.nll_loss(output, target, reduction='sum').item()
# 找到输出结果(张量)中,每一行(即第1维度)最大的那个数以及它所在的位置,返回一个元组。其中元组的第一个元素就是最大的那个数,第二个元素是最大数的位置。
# 这里的 keepdim=True 参数表示保持维度不变,也就是说返回的结果张量维度与原始张量相同。
# [1] 表示取出这个元组的第二个元素,也就是位置信息,赋给了变量 pred。这个 pred 变量就是神经网络预测出来的类别标签,
# 它的维度与原始张量第 1 维度相同,表示每一个输入数据样本对应的类别标签。
pred = output.data.max(1, keepdim=True)[1]
# target.data.view_as(pred)将 target 张量按照 pred 张量的形状进行重塑(reshape)。
# 具体地说,它会返回一个和 pred 张量形状相同、但数据来自 target 张量的新张量。
# .eq()方法来进行张量之间的逐元素比较,得到一个由布尔值组成的张量,表示pred和target.data.view_as(pred)中的每个元素是否相等。
# 如果该元素相等,则对应位置为True,否则为False。
# .sum():对前一步得到的True/False tensor沿着所有维度求和,得到预测正确的样本数。
# +=:将这个batch中预测正确的样本数添加到之前已经处理过的样本中,累加得到整个数据集中预测正确的样本数(correct)。
correct += pred.eq(target.data.view_as(pred)).sum()
# 计算样本的平均损失
test_loss /= len(test_loader.dataset)
# 记录本次的测试结果
test_losses.append(test_loss)
# 打印本次测试结果,包括测试集的平均损失、正确预测的样本数量、测试集的总样本数量以及正确预测的样本占比。
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
test() # 不加这个,后面画图就会报错:x and y must be the same size,因为test_counter中包含了模型未经训练时的情况(上面打印中的“0”)
# 进入正式的训练、测试过程,根据设定的epoch进行训练
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
# 绘制整个训练和测试的图像,包括记录训练的损失变化、测试的损失变化
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
# 选取6个样本进行测试,即模型的使用
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = network(example_data)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
# ----------------------------------------------------------- #
# 检查点的持续训练,继续对网络进行训练,或者看看如何从第一次培训运行时保存的state_dicts中继续进行训练。
# 初始化一组新的网络和优化器。
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
# 加载网络的内部状态、优化器的内部状态
network_state_dict = torch.load('model.pth')
continued_network.load_state_dict(network_state_dict)
optimizer_state_dict = torch.load('optimizer.pth')
continued_optimizer.load_state_dict(optimizer_state_dict)
# 为什么是“4”开始呢,因为n_epochs=3,上面用了[1, n_epochs + 1)
# 继续进行5次训练
for i in range(4, 9):
test_counter.append(i*len(train_loader.dataset))
train(i)
test()
# 绘制训练的曲线
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
版权归原作者 LotusCL 所有, 如有侵权,请联系我们删除。