
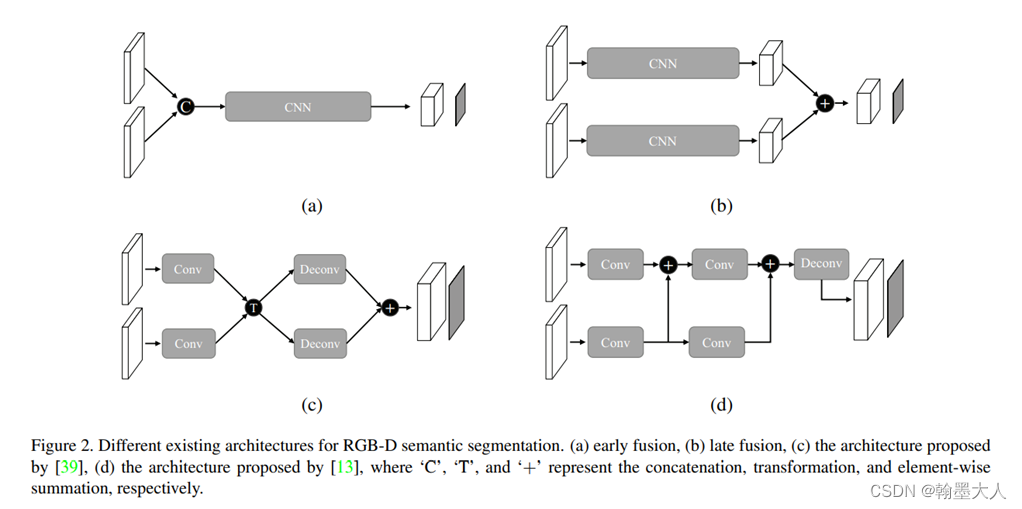
1:在MMFNet中作者提出了几种传统的融合方法,(a)将RGB和Depth首先concat然后经过卷积最后生成特征图。(b)将RGB和Depth分别进行卷积,然后再add融合。(c)将RGB和Depth先进行卷积,经过transformation,再经过反卷积,融合起来。(d)RGB和Depth分别卷积,将depth融合再分别经过卷积,最后经过反卷积。这些经典的方法仍然有参考意义。
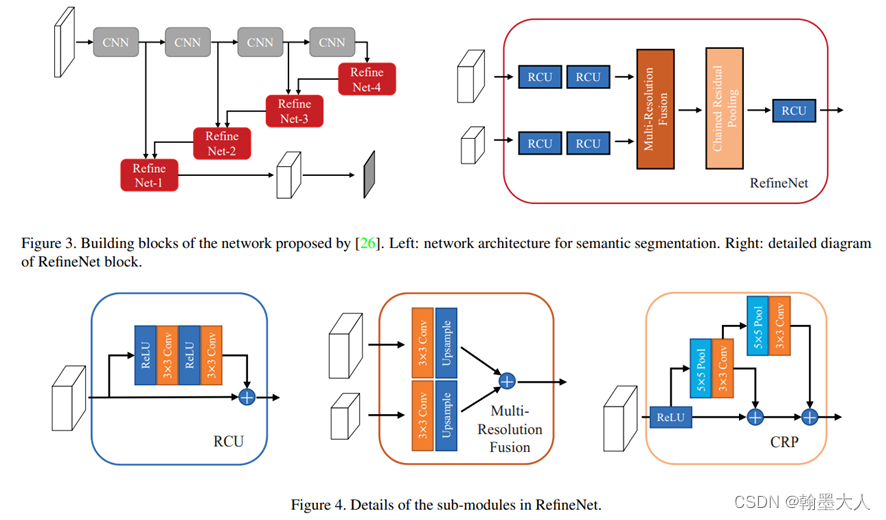
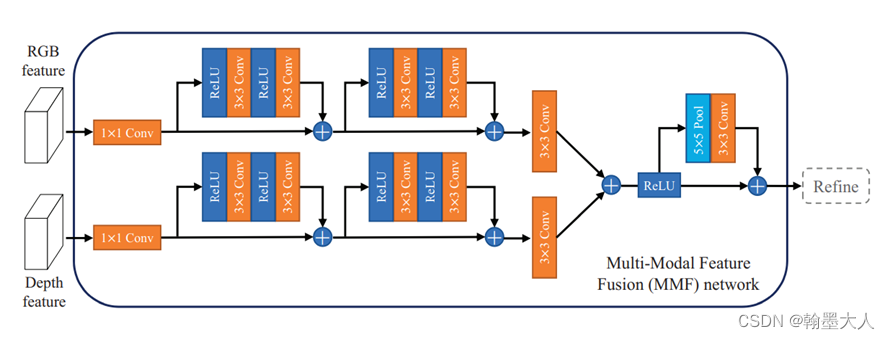
2:MMFNet的融合方法,其中RCU模块就像是SENet的雏形,不过当时还没有提出注意力机制。MRF模块就参考了上图中的b。
3:我自己试过的通过ASPP来对RGB和Depth进行特征提取,但是效果很不好。类似于这一种,分别对RGB和Depth进行PPM或者ASPP操作,然后进行拼接,最后经过1x1卷积,效果都不够好,可以说不如注意力机制。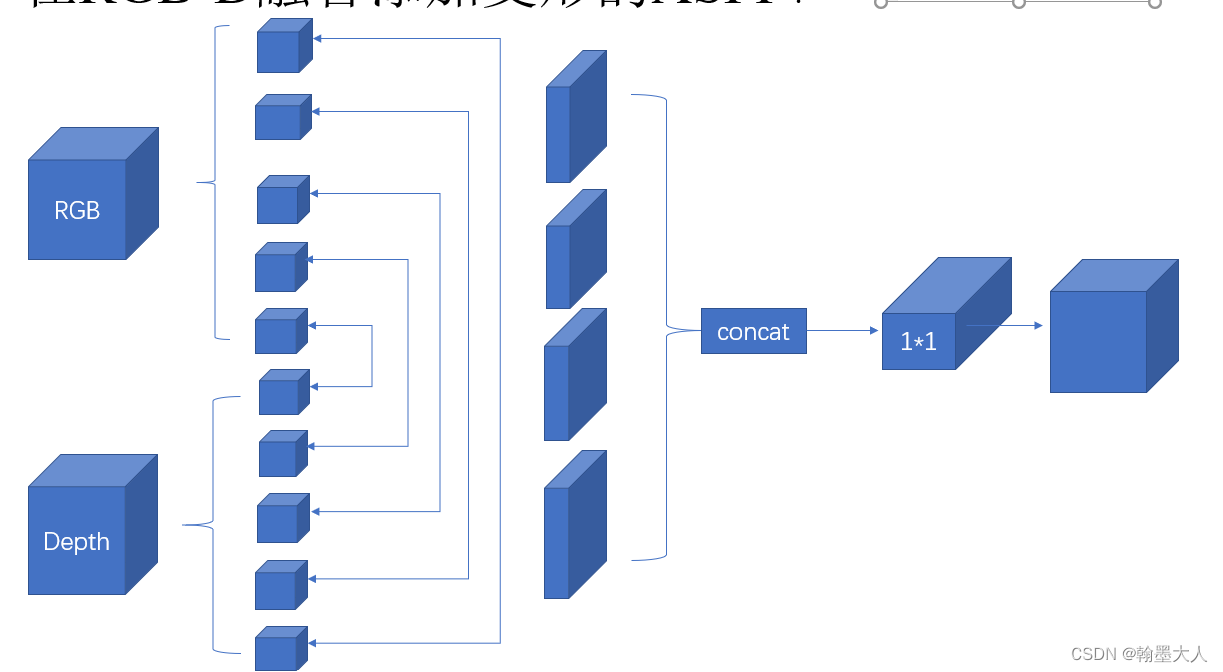
4:出自Deep Surface Normal Estimation with Hierarchical RGB-D Fusion,是用来预测表面法线的,还没有看,先挖个坑。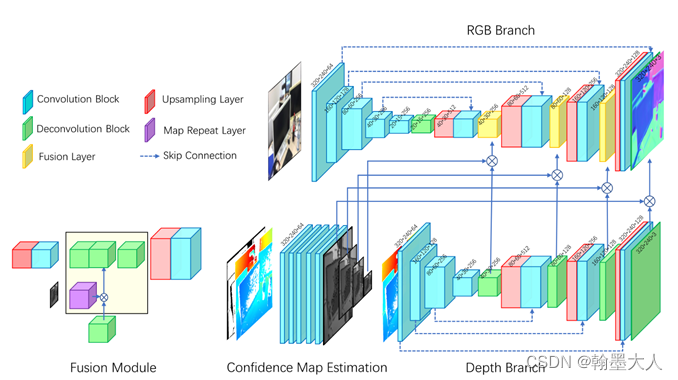
5:接着就是注意力机制,包括SA-Gate,将RGB和Depth进行拼接,然后经过global pooling操作,得到1x1卷积再与本身相乘,然后再经过拼接,经过softmax得到一个权重,与原始图片进行相乘,两个注意力都用到了,他的点在于图像的去噪,将图像分离,去噪,融合,再分离,再融合。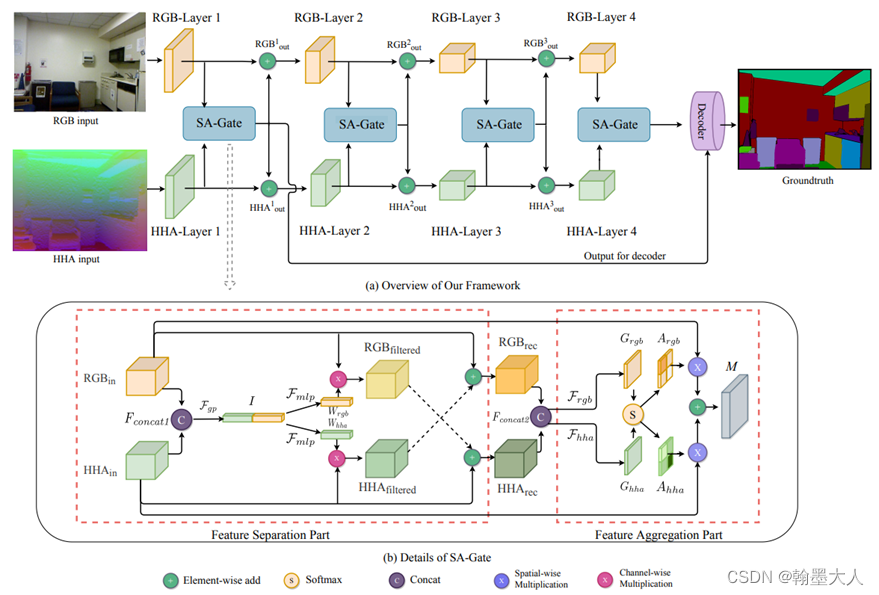
6:在ESANet中应用了SENet中的Sequeeze-and-Excitation模块,将RGB和Depth分别进行
Sequeeze-and-Excitation,经过通道注意力,会学到应该关注于那些通道,相当于某些通道乘了一个大的权重,然后再与深度进行融合。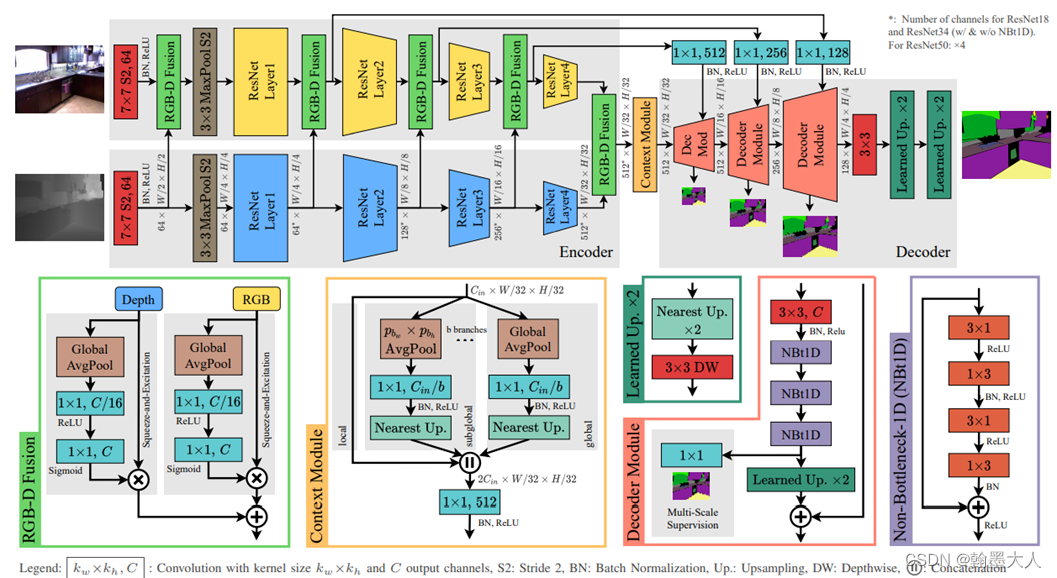
6:除了应用SENet中即插即用的模块,CANet还应用了非局部注意力来融合RGB和Depth。这个方法在DANet的创新点上进行创新。
DANet: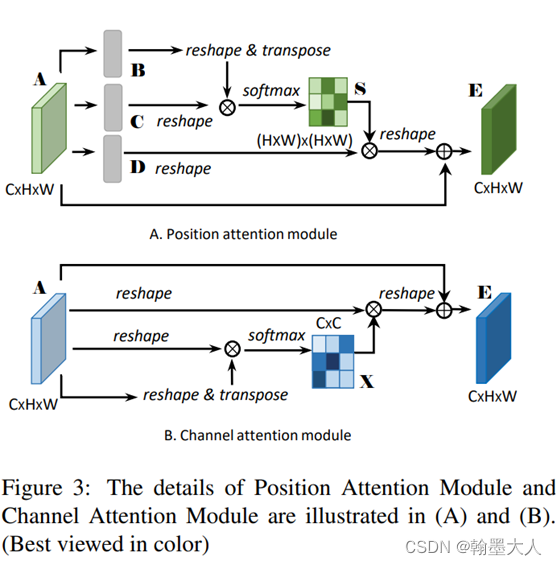
CANet: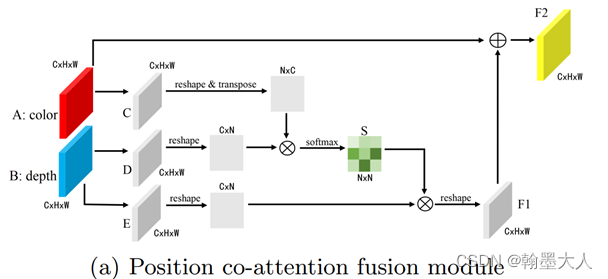
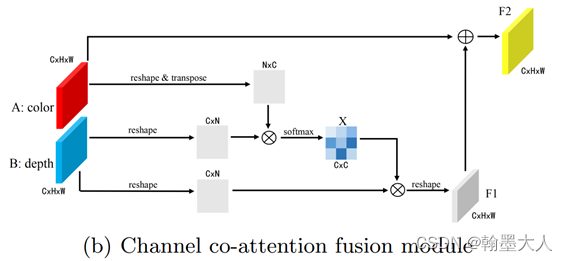
CANet意图很清晰,通过RGB和Depth进行非局部注意力,得到的权重乘以Depth,然后和RGB进行融合,分别在空间上和通道上进行注意力融合,得到的结果再进行1x1卷积和纹理融合,可以说融合的很充分了。
随便揣测一下,这些操作都像是非局部注意力和深度可分离卷积的变形,非局部注意力,通过两个modality进行注意力得到的权重乘以原来的图片,深度可分离卷积,通过卷积核来聚合多个通道的信息,在经过1x1卷积来进行空间的遍历。
综上这是目前看到的RGB和Depth融合策略,以后看到了再补充。
-------------------------------------------------------补充-----------------------------------------------------------------------------------------------------
7:最近读了一篇CMX,是nyu数据集上排名第一的方法,包含了深度与RGB融合方法: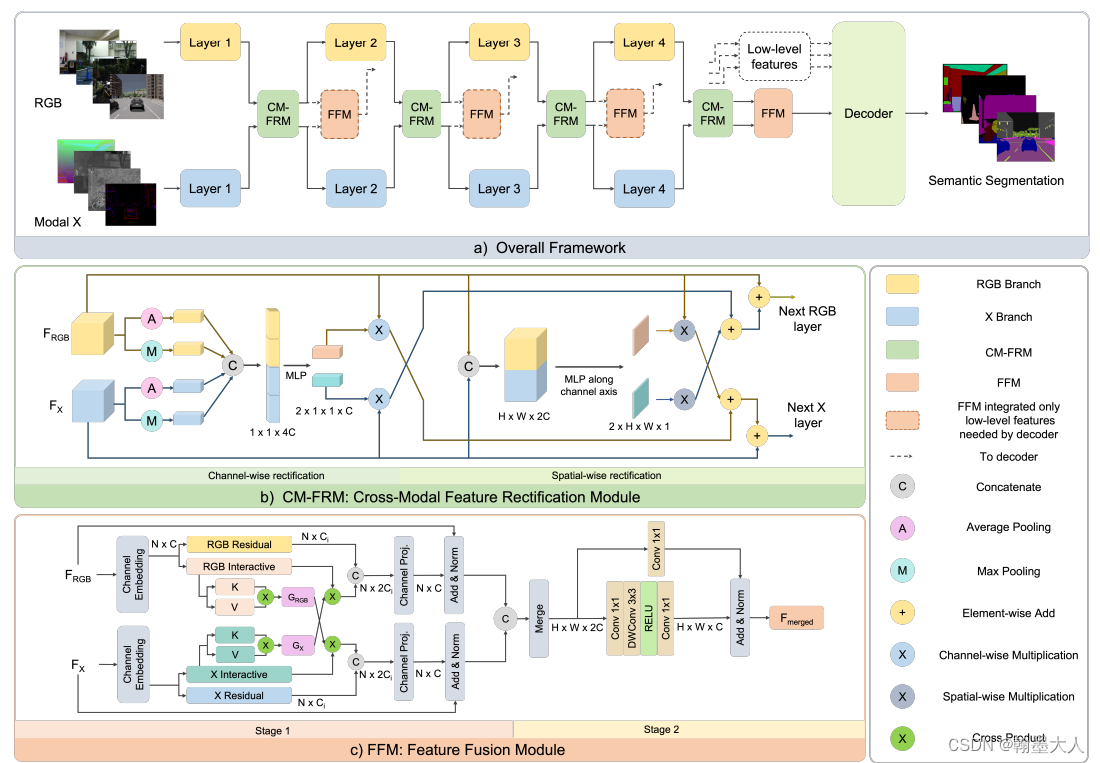
其中FRM模块与SA-Gate的方法十分类似,都是通过进行特征图校准来去噪,CMX通过逐通道校准和逐空间校准,最后生成两个输出,SA-Gate则是通过通道的压缩和聚合来实现的,不过本质上也是注意力。
除此以外CMX还是用了Transformer来进行特征的交互和融合,最后再通过一个通道编码得到最终输出。
----------------------------------------------------------------------补充-----------------------------------------------------------------------------------
8:最近读了一篇FRNet,作者受到SA-Gate的启发,提出了一种跨层跨模态的融合策略。主要使用这种top-down结构,通过将高层次语义信息和低层次特征信息进行融合。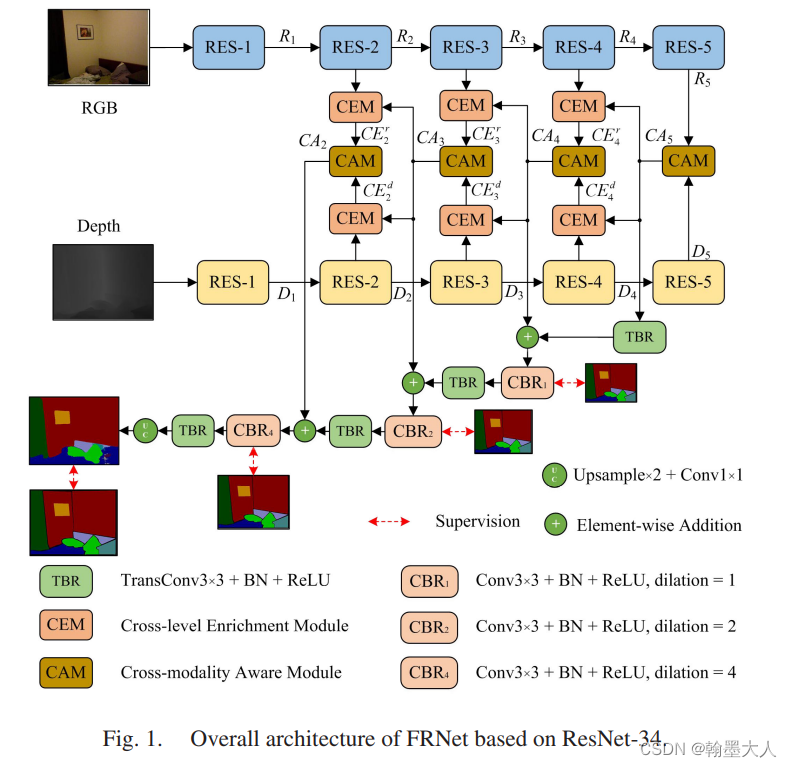
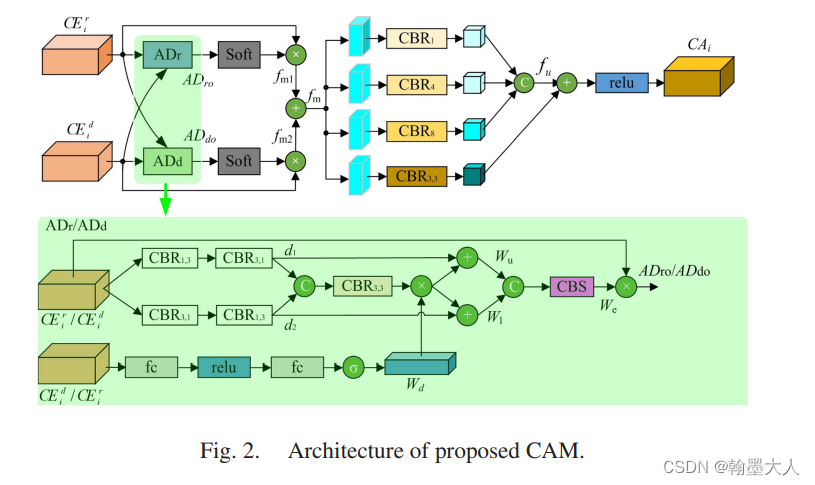
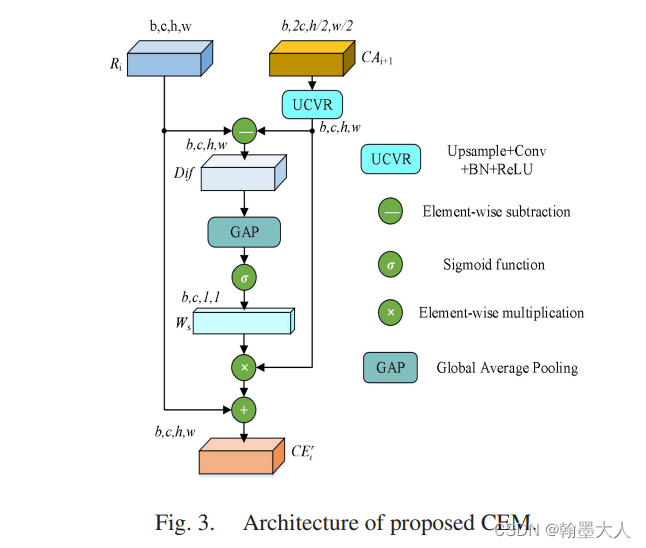
----------------------------------------------------------------------补充-----------------------------------------------------------------------------------
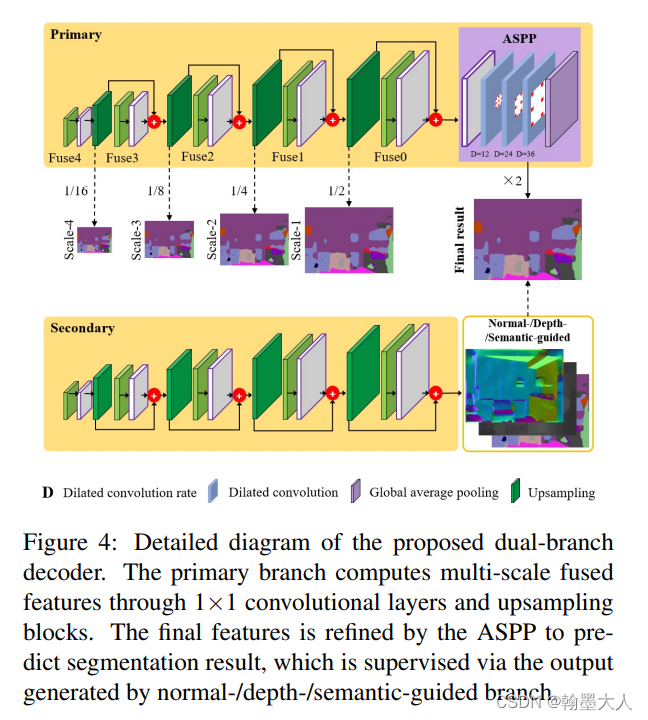
9:这是一篇2022最新的文章,Attention-based Dual Supervised Decoder for RGBD Semantic Segmentation,没有代码。和之前的融合方法有差别,但是差别不大。每一层融合之后不连接,融合方法就是注意力,创新点主要是后面的双分支decoder。在depth分支上采样到最后起到了监督的作用。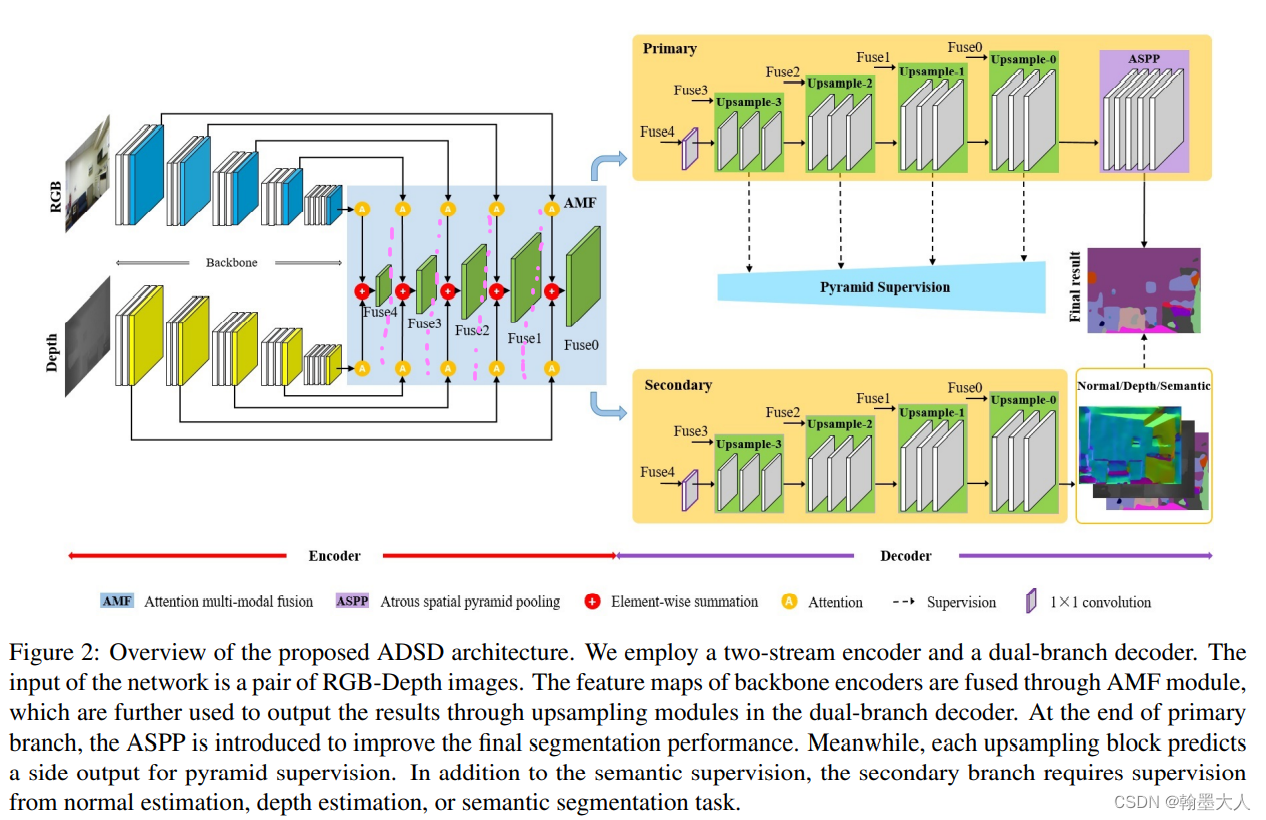
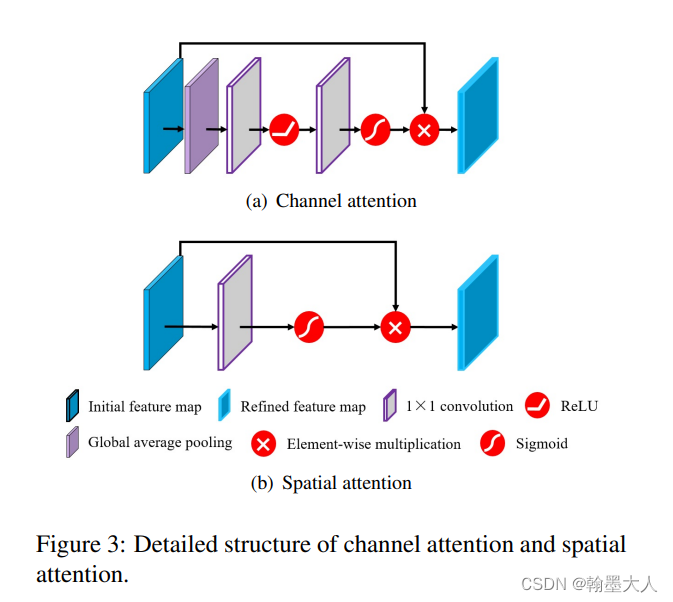
---------------------------------------------------------------补充----------------------------------------------------------------------------------
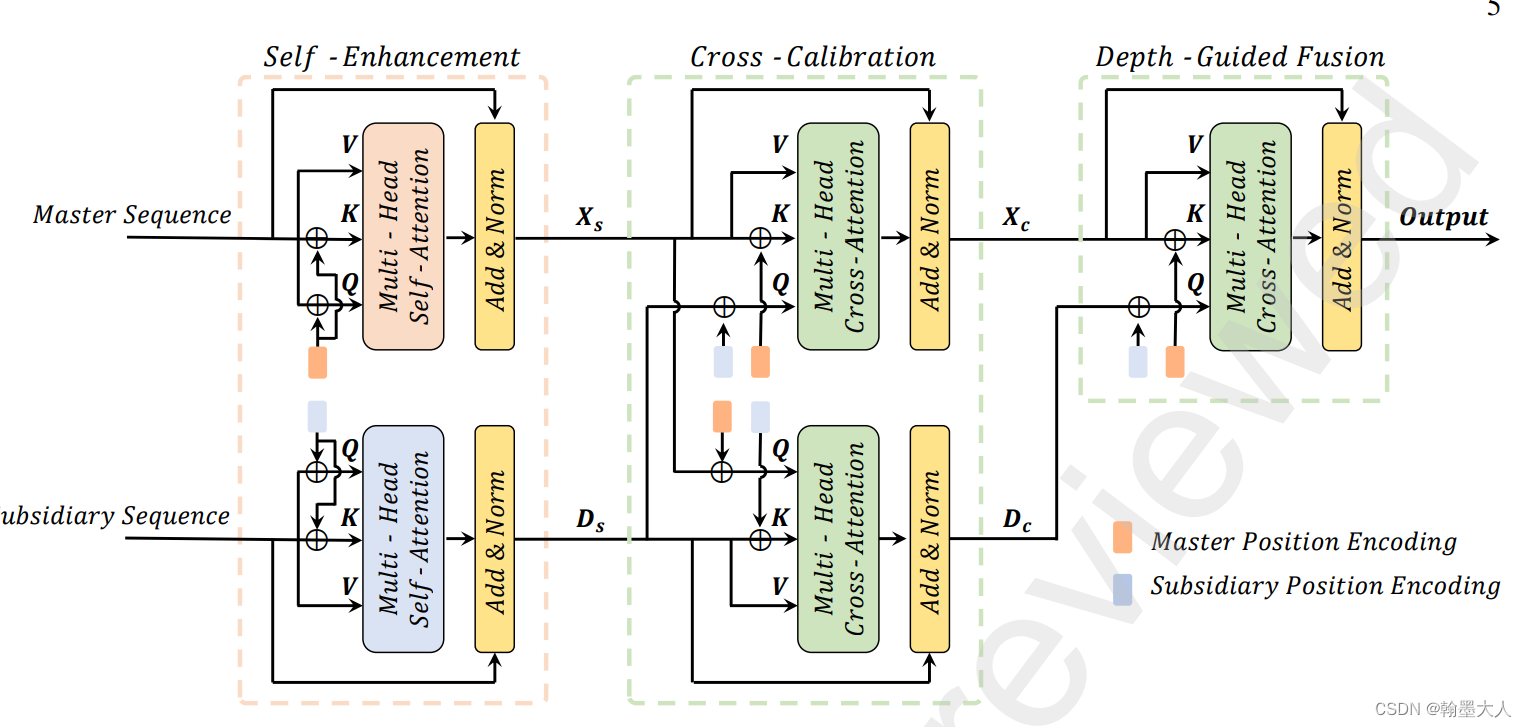
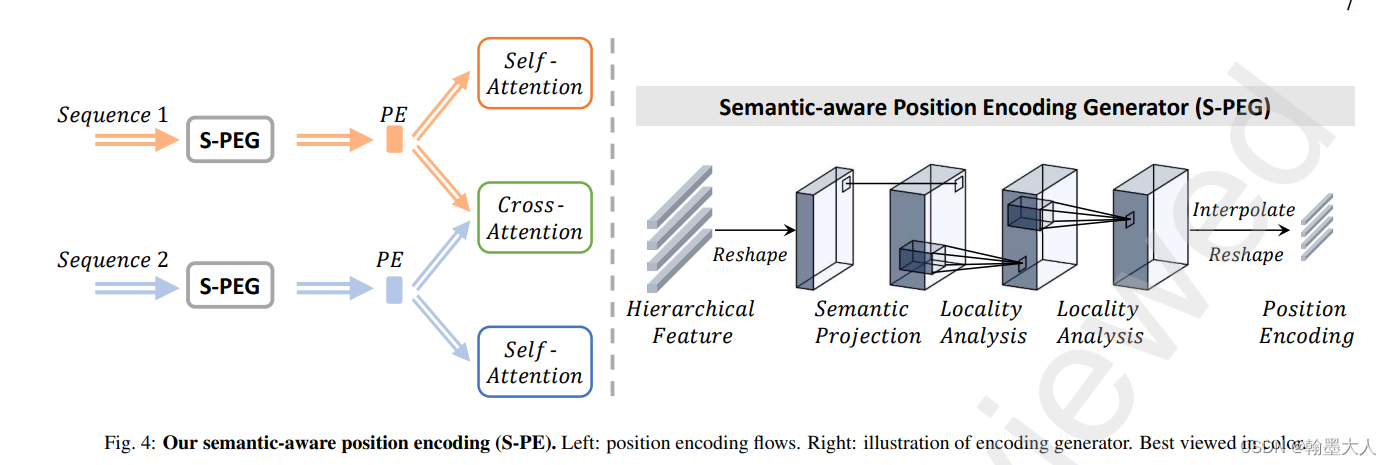
10:TransD-Fusion**:transformer用于RGB-D融合来进行语义分割,在两个分支encoder的尾部进行融合。通过自注意力,交叉注意力,深度引导三步进行融合。在NYU上的miou达到了55.5。其中融合的部位和CANet一样,融合的方法在CMX也使用到了,交叉的transformer注意力。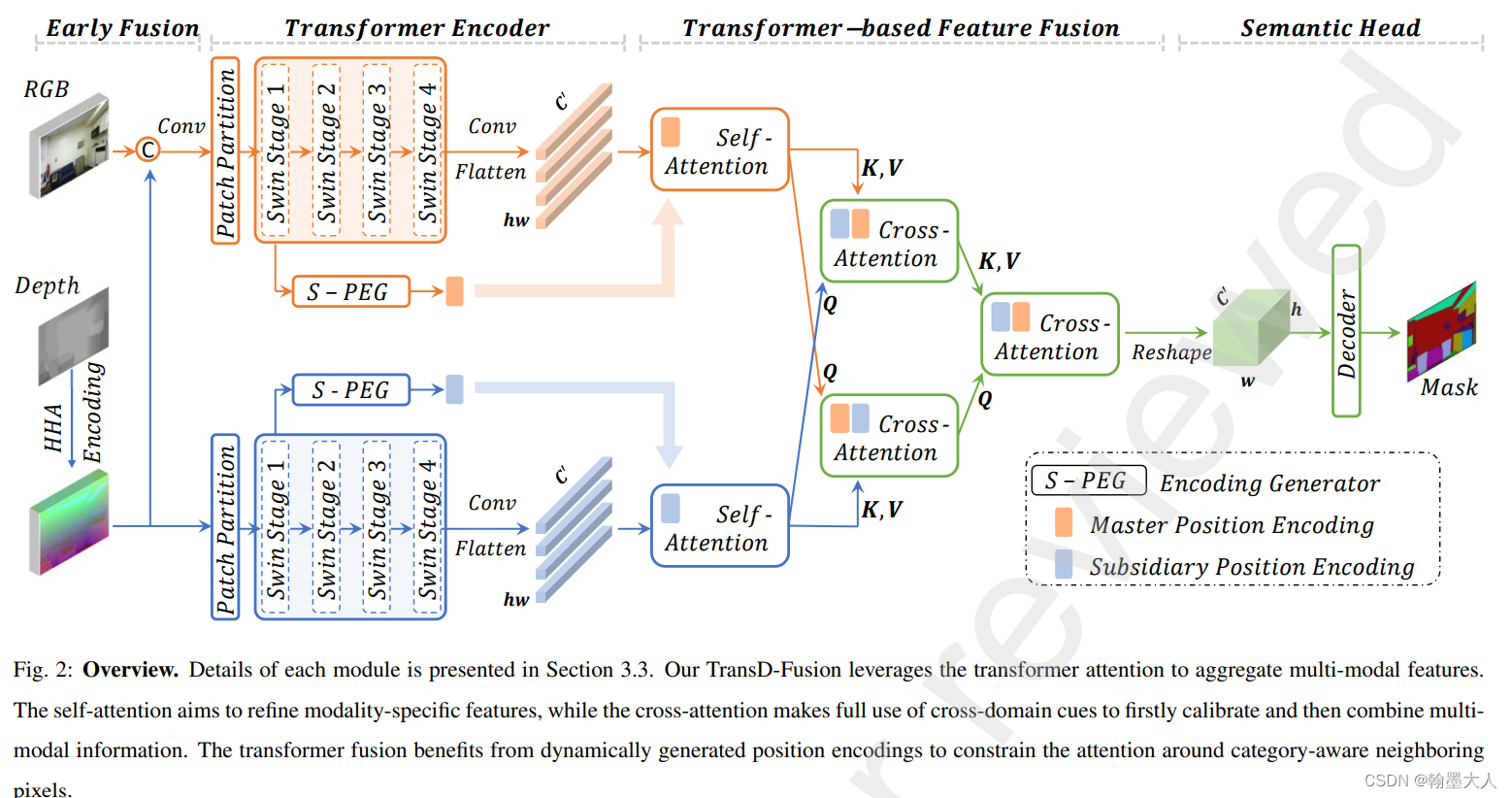
11:在看TransD-Fusion文章的时候,他引用了一篇文章PGDENet: Progressive Guided Fusion and Depth Enhancement Network for RGB-D Indoor Scene Parsing也是RGB-D融合的,我就进去看了一下架构图,和之前的FRNet几乎一样,模型很像,就不仔细看了。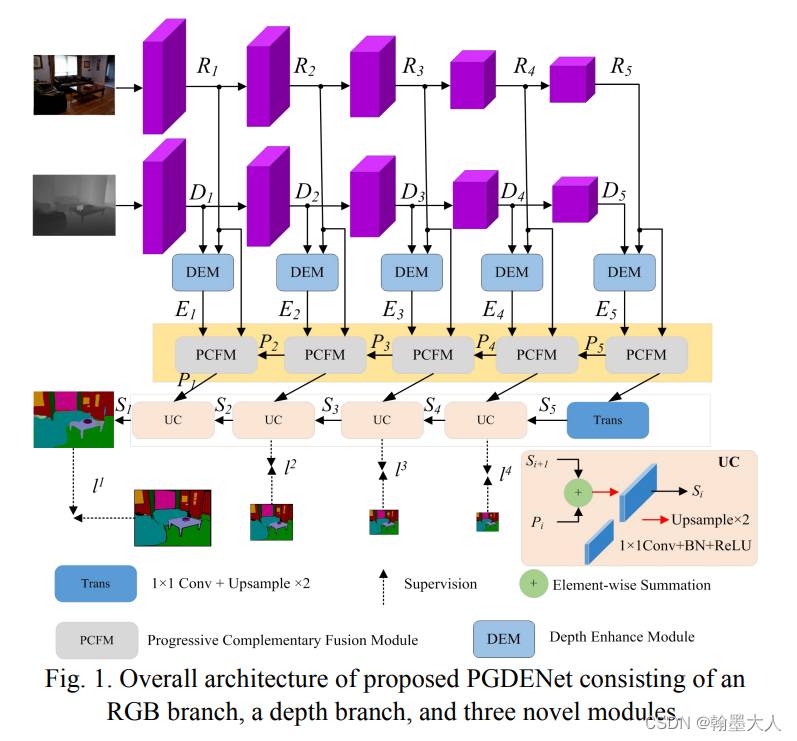
主要看一下PCFM模块和DEM模块: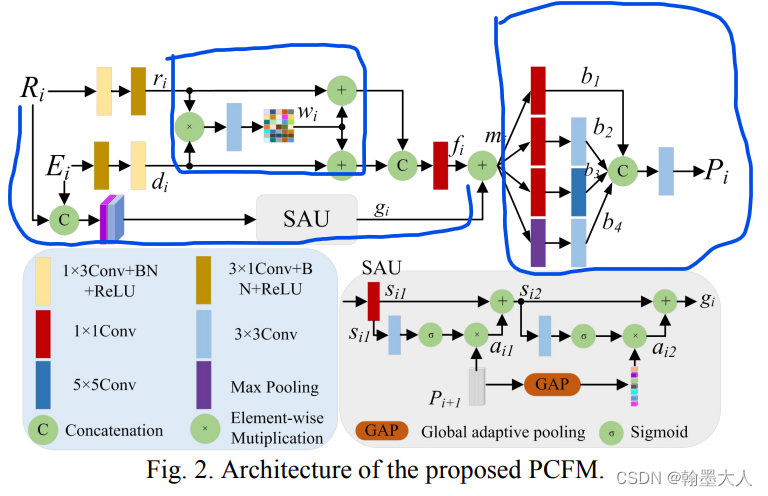
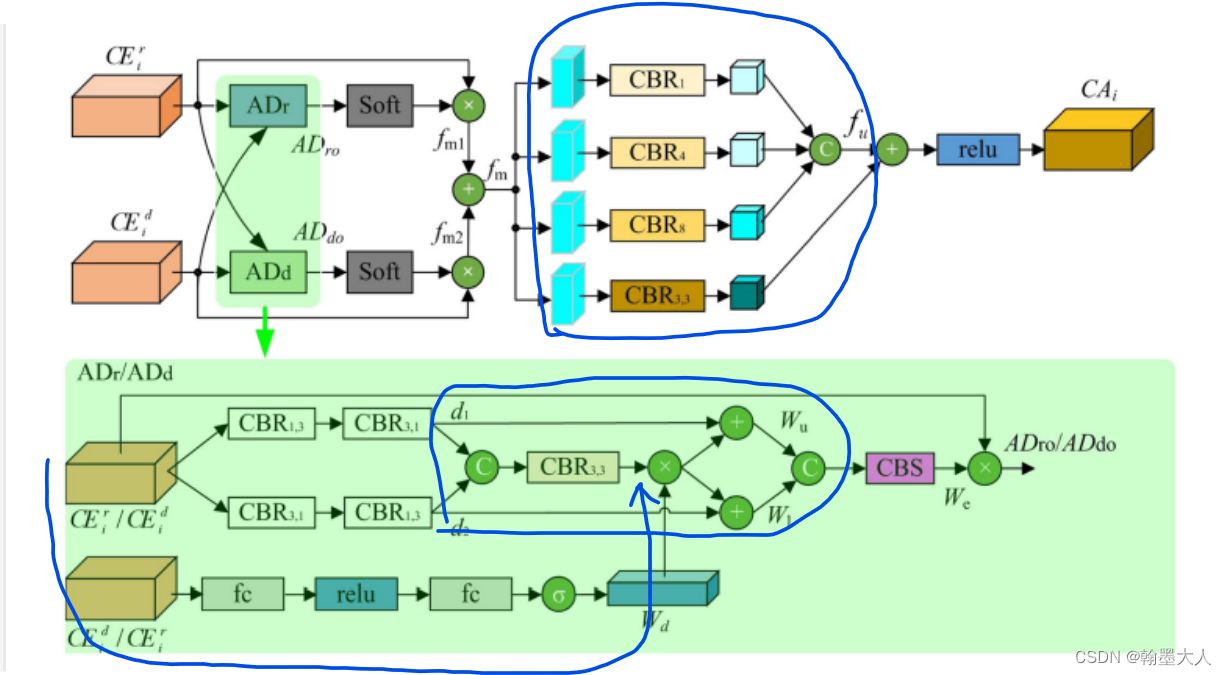
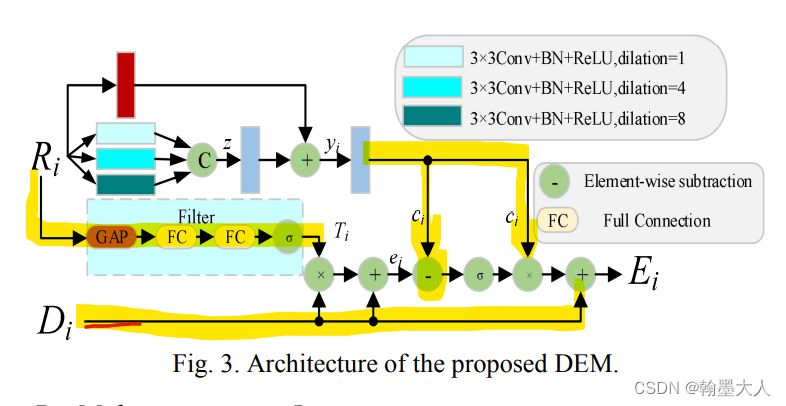
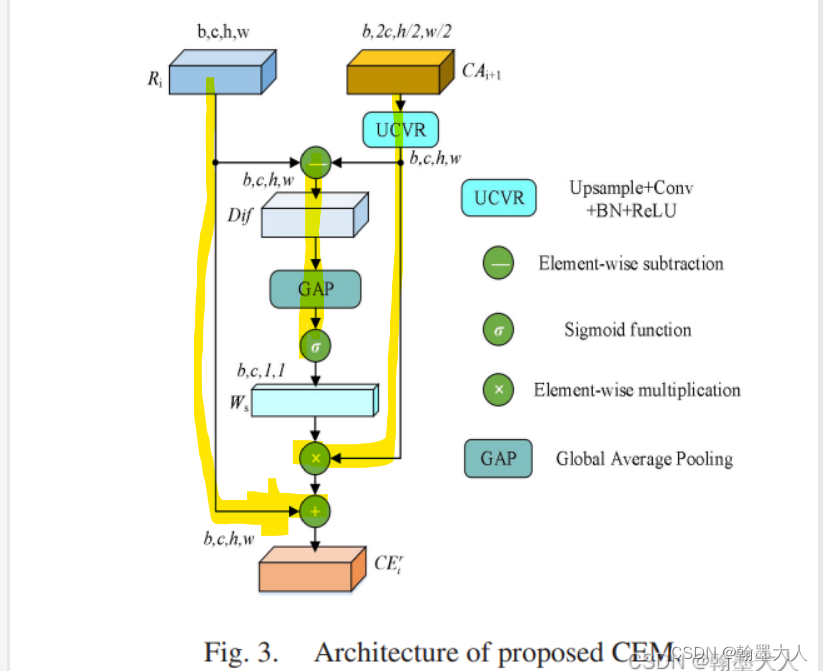
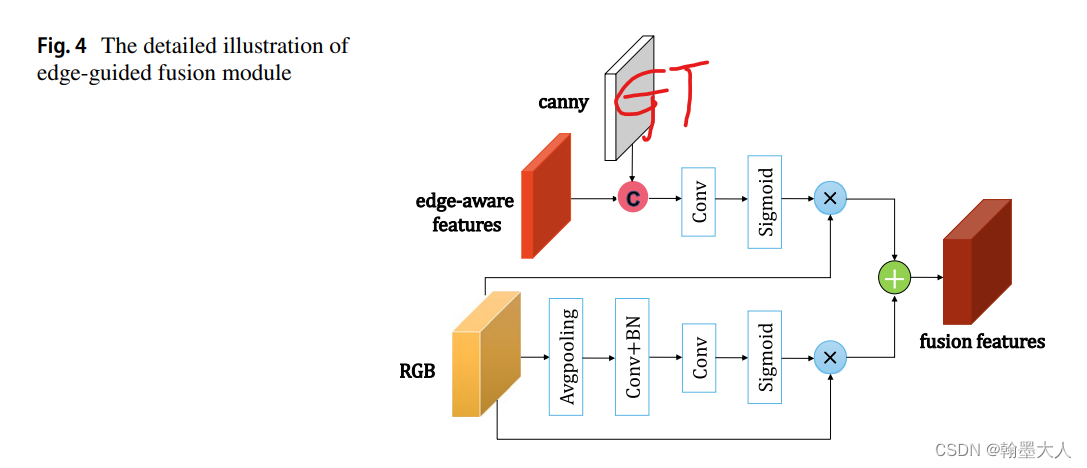
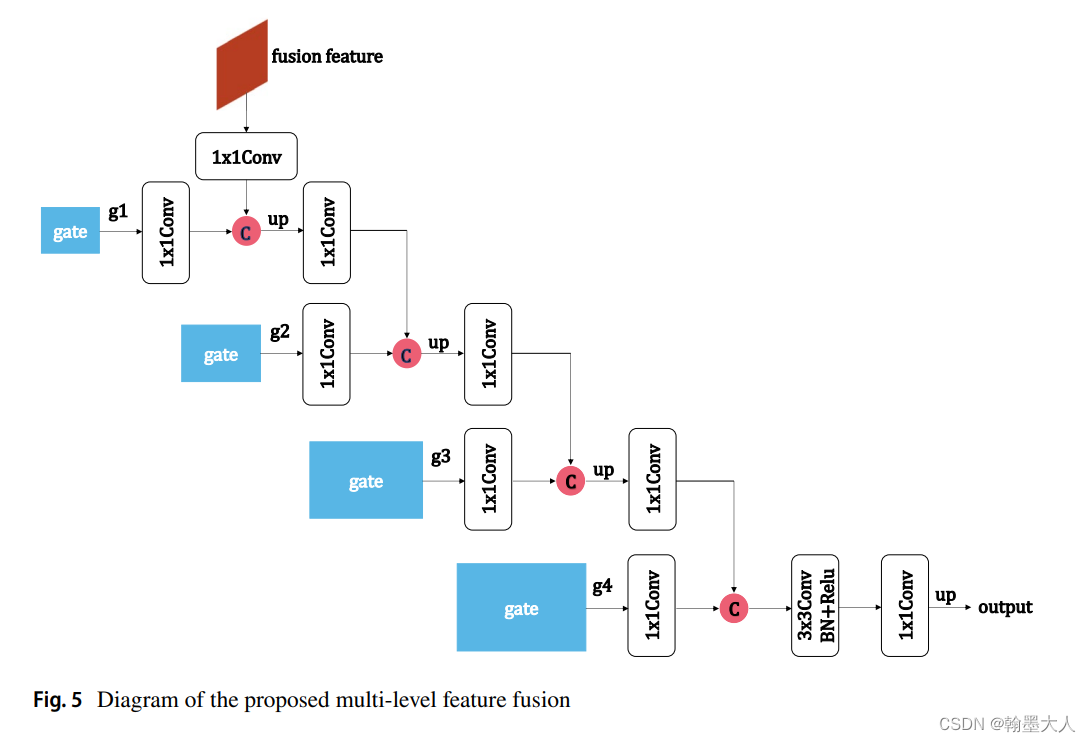
12:RGB‑D Gate‑guided edge distillation for indoor semantic segmentation文章引入了边界引导,RGB和Depth分别处理,其中融合的结果作为一条单独的分支进行传递。在边界特征部分用到了原始GT进行边缘提取的边缘损失。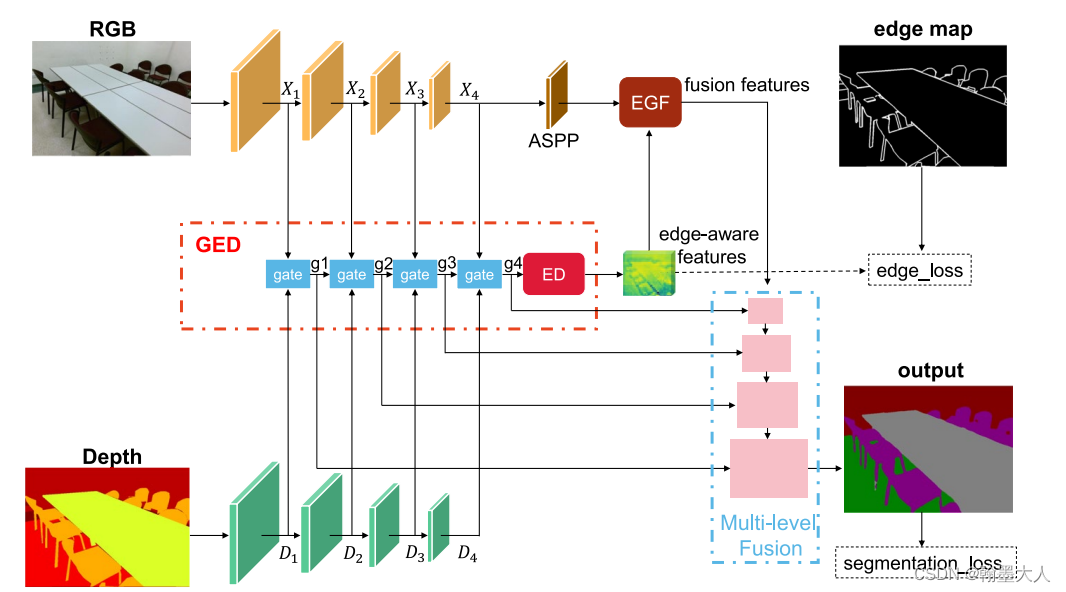
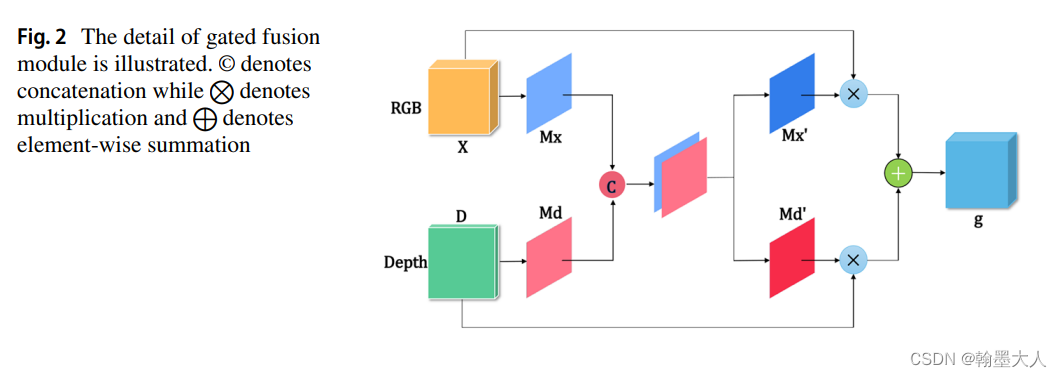
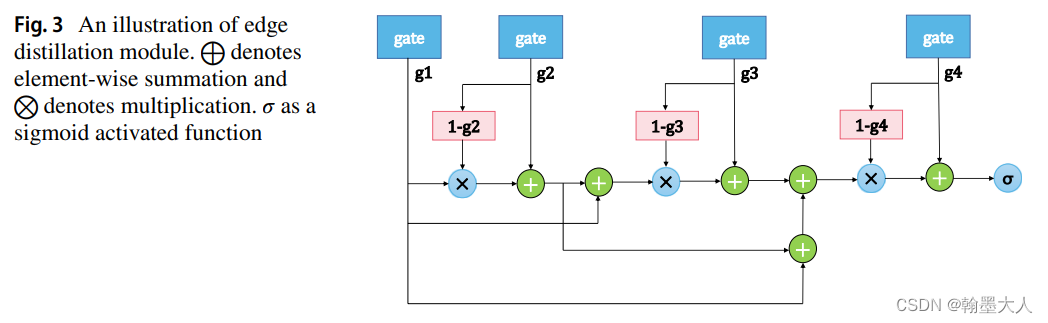
版权归原作者 翰墨大人 所有, 如有侵权,请联系我们删除。