
目录
数据层解决方案
**
这里还是要说,涉及到的技术并没有做很详细的讲解,以整合为主,但是足够会基本使用和了解了。某个单一的技术更详细的知识还是要找具体的课程学习
**
内置的数据源
springboot如果我们不指定使用什么数据源(连接池),则默认使用springboot内嵌的hikariCP数据源,当然,若要使用数据源,则数据源相关的配置也必须配置上
springboot内嵌有三种数据源供我们选择使用
1.hikariCP
2.Tomcat提供的DataSource
3.Commons DBCP
数据源的配置
无论是内嵌的数据源还是我们自己选的比如druid数据源,他们的配置都大同小异,比如: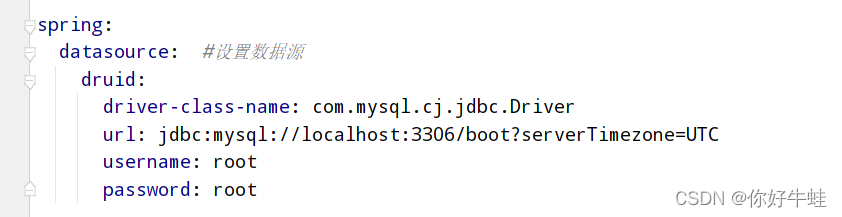
如果只这样配置:则默认使用hikariCP数据源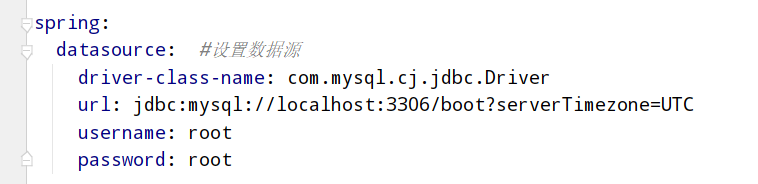
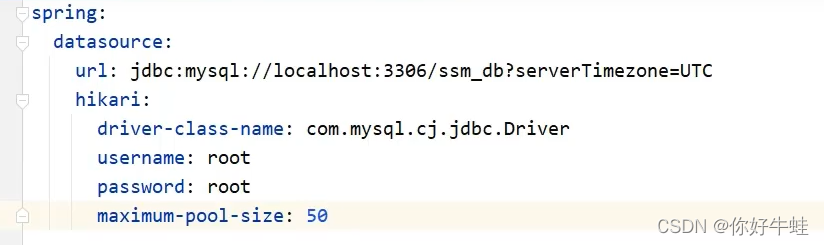
但是需要对hikariCP数据源进一步配置,则需要下面这样配置,和配置一般的数据源有点类似,但是,配置hikariCP需要注意一点,**他的url得写在hikari同一级,不然会报错,
这里注意
**
jdbcTemplate
JdbcTemplate是Spring对原始JDBC封装之后提供的一个操作数据库的工具类,是跟mybatis同一类的技术,操作数据库,实现持久化。
我们可以借助JdbcTemplate来完成所有数据库操作,比如:增删改查等
使用jdbcTemplate
使用jdbcTemplate需要先有dataSource对象,即数据源对象,即先配置好数据源(springboot项目启动的时候会根据配置产生对应的数据源对象)
然后:
- 需要导入对应的依赖 即jdbc的starter

- 自动装配上jdbcTemplate的对象
 导入这个starter,从底层来说就等于有了jdbc启动器(starter),boot会自动加载,被spring容器管理,所以可以自动装配
导入这个starter,从底层来说就等于有了jdbc启动器(starter),boot会自动加载,被spring容器管理,所以可以自动装配 - 使用 这里模拟一个查询操作
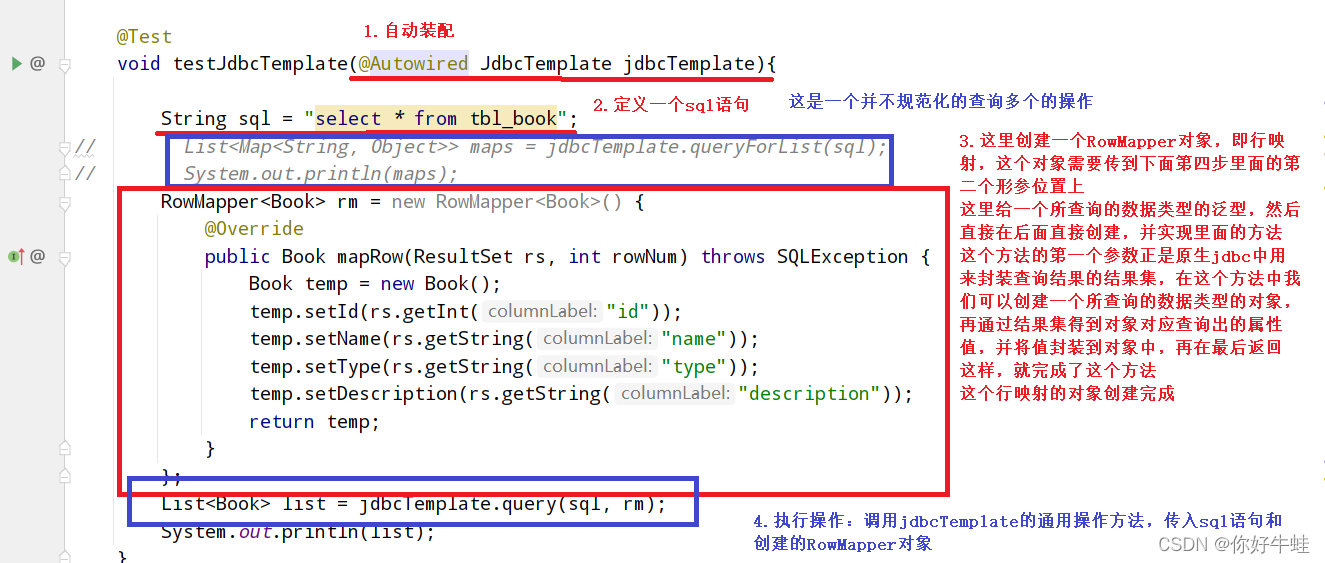
内置的数据库
springboot内置了三款数据库。
1.H2
2.HSQL
3.Derby
这些数据库都很小巧,是内嵌的,是内存级别的数据库,用来搞测试非常方便,所以这三款数据库多用于测试
三种,他们模式都差不多,所以以H2为例子
H2数据库
使用还是那几步
1.导入依赖包
2.做配置
3.使用
- 导入jar包
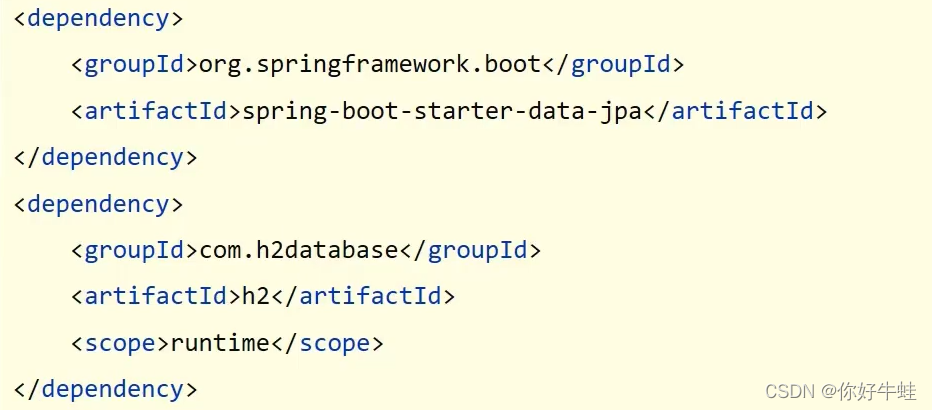
- 做配置和连接控制台

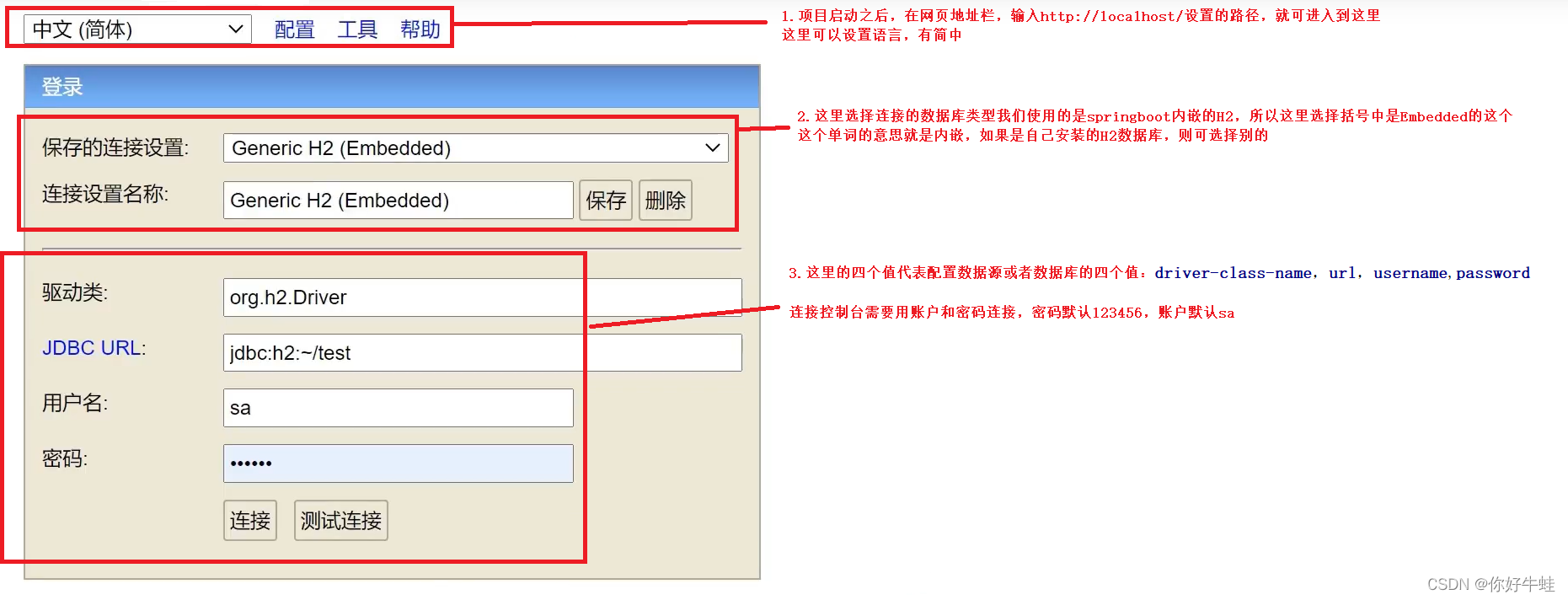 进入之后,根据提供的功能操作即可 第一次进入可能会报错,原因是springboot无对应的初始化数据,所以需要第一次也需要做一点配置,把上面连接界面的四个值告诉给springboot 可以在配置数据源的时候告诉springboot,第一次启动之后,这个就不需要了,注释掉也没问题
进入之后,根据提供的功能操作即可 第一次进入可能会报错,原因是springboot无对应的初始化数据,所以需要第一次也需要做一点配置,把上面连接界面的四个值告诉给springboot 可以在配置数据源的时候告诉springboot,第一次启动之后,这个就不需要了,注释掉也没问题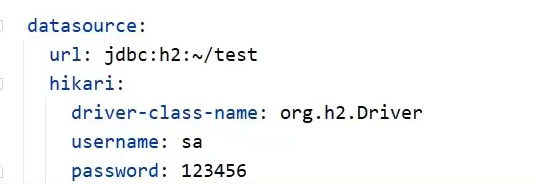
- 使用 直接使用即可,和mysql没啥区别,也是sql语句
NoSQL解决方案
这里学习整合三个常用的
1.Redis
2.Mongodb
3.ES
Redis
Redis是一款key-value存储结构的内存级NoSQL数据库
支持多种数据存储格式
支持持久化
支持集群
官方只提供linux版的Redis,windows版的由windows研发组维护这里以windows版本作为实例,整合springboot部分跟linux一样,这里以整合为主,并不是讲redis的,redis的知识后续再记录
安装和启动服务和可能出现的一个小BUG
windows版下载地址
https://github.com/microsoftarchive/redis/releases/tag/win-3.2.100
,这个地址进不去的话需要魔法,因为是在github上的
选择msi的话,则是安装包,只用于学习的话,安装全部下一步即可,自己选择安装路径
目录下是这样的: 里面的三个需要注意一下
使用redis前需要先启动服务,即上面的redis-service,可以在cmd中如下操作,或者直接在文件中双击对应的可执行程序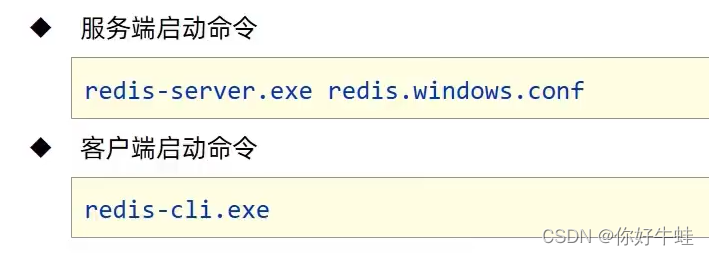
若出现这样的启动失败
这是windows版redis的小BUG,则可以这样解决:
一般是是安装包出现这样的问题,如果这样则先打开客户端,然后执行下面的命令,然后在启动服务就可以了
redis基础操作:
springboot整合redis
整合也就那三步,1.导依赖包 2.做配置 3.使用
- 导包

- 做配置 主要这几项:
 这里是本机上的,只用配一个host和port,或者只一个url,但是其实啥配置也不用做,因为host和port有默认值
这里是本机上的,只用配一个host和port,或者只一个url,但是其实啥配置也不用做,因为host和port有默认值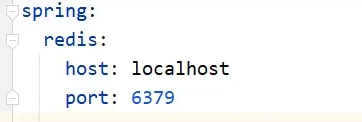
- 使用

 如果使用redisTemplate,传入的是对象,则在客户端访问,则会返回一串类似这样的东西:
如果使用redisTemplate,传入的是对象,则在客户端访问,则会返回一串类似这样的东西:"\xac\xed\x00\x05t\x00\x06747976",用上面说的StringRedisTemplate就能解决这个问题
切换springboot操作redis客户端的实现技术(jedis或lettuce)
lettcus与jedis区别:
jedis连接Redis服务器是直连模式,当多线程模式下使用jedis会存在线程安全问题,解决方案可以通过配置连接池使每个连接专用,这样整体性能就大受影响。
lettuce基于Netty框架进行与Redis服务器连接,底层设计中采用StatefulRedisConnection。StatefulRedisConnection自身是线程安全的,可以保障并发访问安全问题,所以一个连接可以被多线程复用。当然lettcus也支持多连接实例一起工作。
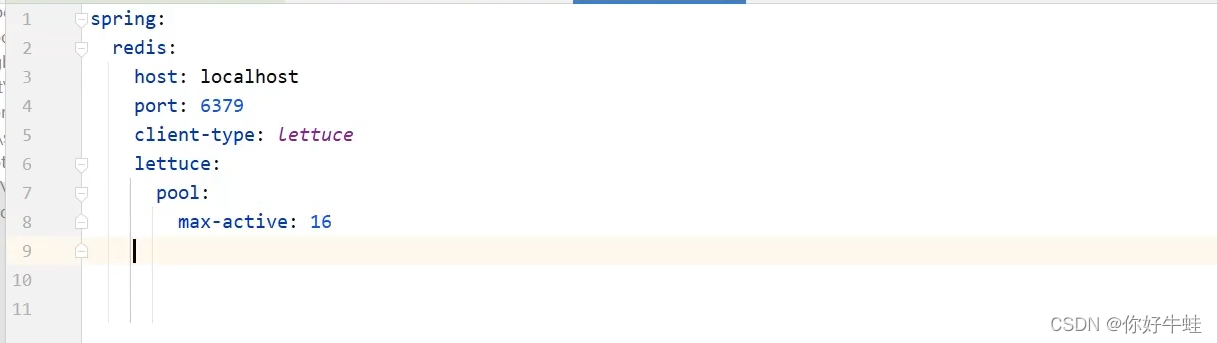
- 导入依赖包
 这玩意版本号也由springboot管控了
这玩意版本号也由springboot管控了 - 做配置 client-type用于设置使用什么技术,如下图 下面可以配置更详细的配置
- 直接使用,没啥区别,直接跟前面的一样使用即可
MongoDB
**
MongoDB的基本知识这里确实没写啥东西,因为我也不太会,但是整合部分的知识倒是没问题。MongoDB的使用可以找更详细的课程
**
MongoDB是一个开源、高性能、无模式的文档型数据库。NoSQL数据库产品中的一种,是最像关系型数据库的非关系型数据库
MongoDB多用于存储变动较快的数据
不常变动的一般用关系型数据库
安装和初始化
官网下载好像得注册账号,忘记之前咋下载的了,这里把我的安装包分享一下:
链接:链接:https://pan.baidu.com/s/1rrKB0UfbOwPWsBAbG-zJ4A 提取码:duay
版本是5.0.6
bin文件夹下
这里mongo.exe就是启动客户端的可执行程序
安装后之后,第一次使用需要初始化 启动服务也是这个命令
默认端口:27017
启动客户端,双击mongo.exe就行
安装mongodb的可视化工具Robo 3T
依然是之前保存的资源:
链接:链接:https://pan.baidu.com/s/1UjjsVokjYMEoTHBQF0AN8A 提取码:ynt2
版本是1.4.4
如果连接不上mongodb,那很可能是和mongobd的版本不符,但是我这俩版本不冲突
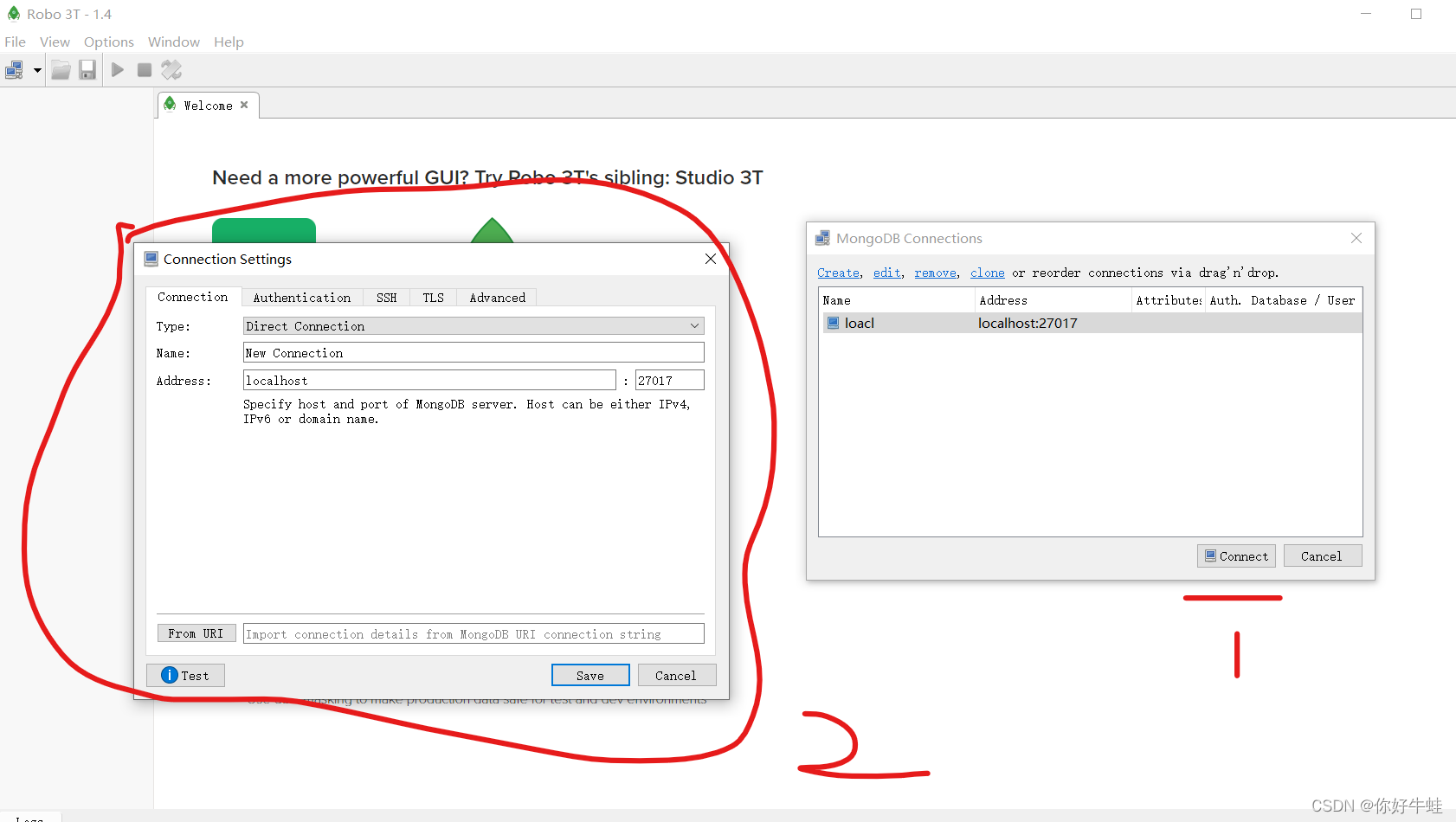
进来之后就这弔样,先连接,我这里已经连接过了,所以有记录
mongodb的详细使用可以参考对应的教程
整合
- 导入依赖包 NoSQL相关的包基本都是spring-boot-starter-data-*

- 做配置

- 使用
 下面这个是查找
下面这个是查找
整合第三方技术
**
这里还是要说,涉及到的技术并没有做很详细的讲解,以整合为主,但是足够会基本使用和了解了。某个单一的技术更详细的知识还是要找具体的课程学习
**
整合无非就那三步,导包,配置,使用
这里记录几个常用的
1.缓存 2.发邮件 3.消息队列
缓存
缓存是一种种介于数据永久存储介质与数据应用之间的数据临时存储介质
使用缓存可以有效的减少低速数据读取过程的次数(例如磁盘IO),提高系统性能
在软件中,因为两者对接而出现的一些问题,加一层能解决其中大部分的问题
缓存就是这样,若程序频繁访问数据库,则会极大的影响程序整体的性能
缓存就是在这两者之间加一层,缓存把常用的数据存储到内存中,然后程序去缓存中访问数据,这样就避免程序频繁访问数据库
缓存的作用不止是可以减低速数据读取过程的次数,还可以用于记录程序运行期间产生的一些无需进入数据库的数据,比如验证码
Spring提供的缓存技术除了提供默认的缓存方案,还可以对其他缓存技术进行整合,统接口,方便援存技术的开发与管理,有这么一些:
Generic
JCache
Ehcache
Hazelcast
Infinispan
Couchbase
Redis
Caffenine
Simple (默认)
还有一个技术memcache也挺常用,但是boot并未给整合,我们需要手动整合
这里记一下几个常用的缓存技术
1.Redis 2.Memcached 3.Ehcache
注意几点:
- springboot已经整合过的技术,下面关于这些技术的配置都是在spring级别下,比如redis,Simple,Ehcache,但是springboot并未整合memcache,他的配置后续到这部分了再讲
- 因为下面整合不同的缓存技术所使用的的例子都是一个业务,为了防止使用一个技术的时候和上一个技术相冲突,当从一项缓存技术切换到另一种缓存技术,则和上一种缓存技术相关的而且和当前切换到的缓存技术无关的部分需要注释掉
手动实现一个简单的缓存机制
随便搞一搞的话很简单
如果是验证码,则先获取验证码,然后存入Map,比对的时候从Map中取,这样这个数据就是只存在内存中的
springboot中默认的使用的缓存
springboot提供了自己默认的缓存技术
springboot中的缓存默认使用Simple
可以导入对应的依赖包后直接使用即可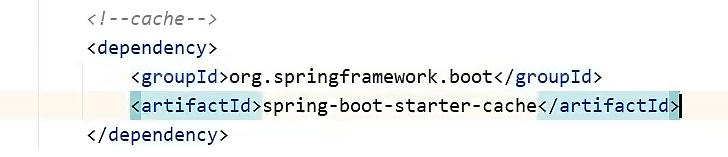
然后三步:
启用缓存
设置进入缓存的数据
设置读取缓存的数据
实现一个简单的验证码业务
实验一个用缓存存储验证码的业务,作为后续用不同缓存技术的模板,这里先使用默认的Simple作为缓存技术
需求
输入手机号获取验证码,组织文档以短信形式发送给用户(页面模拟)
输入手机号和验证码验证结果
需求分析
提供controller, 传入手机号,业务层通过手机号计算出独有的6位验证码数据,存入缓存后返回此数据
提供controller, 传入手机号与验证码,业务层通过手机号从缓存中读取验证码与输入验证码进行比对,返回比对结果
service层: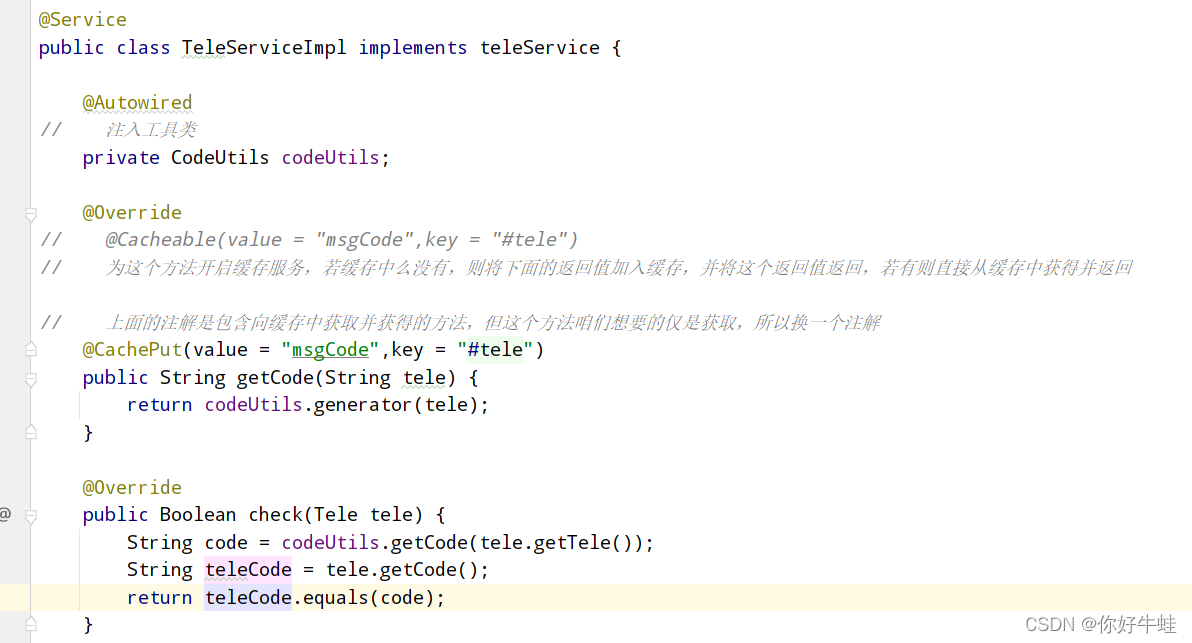
对应产生验证码,和获取验证码的类,这里有一点很重要,需要注意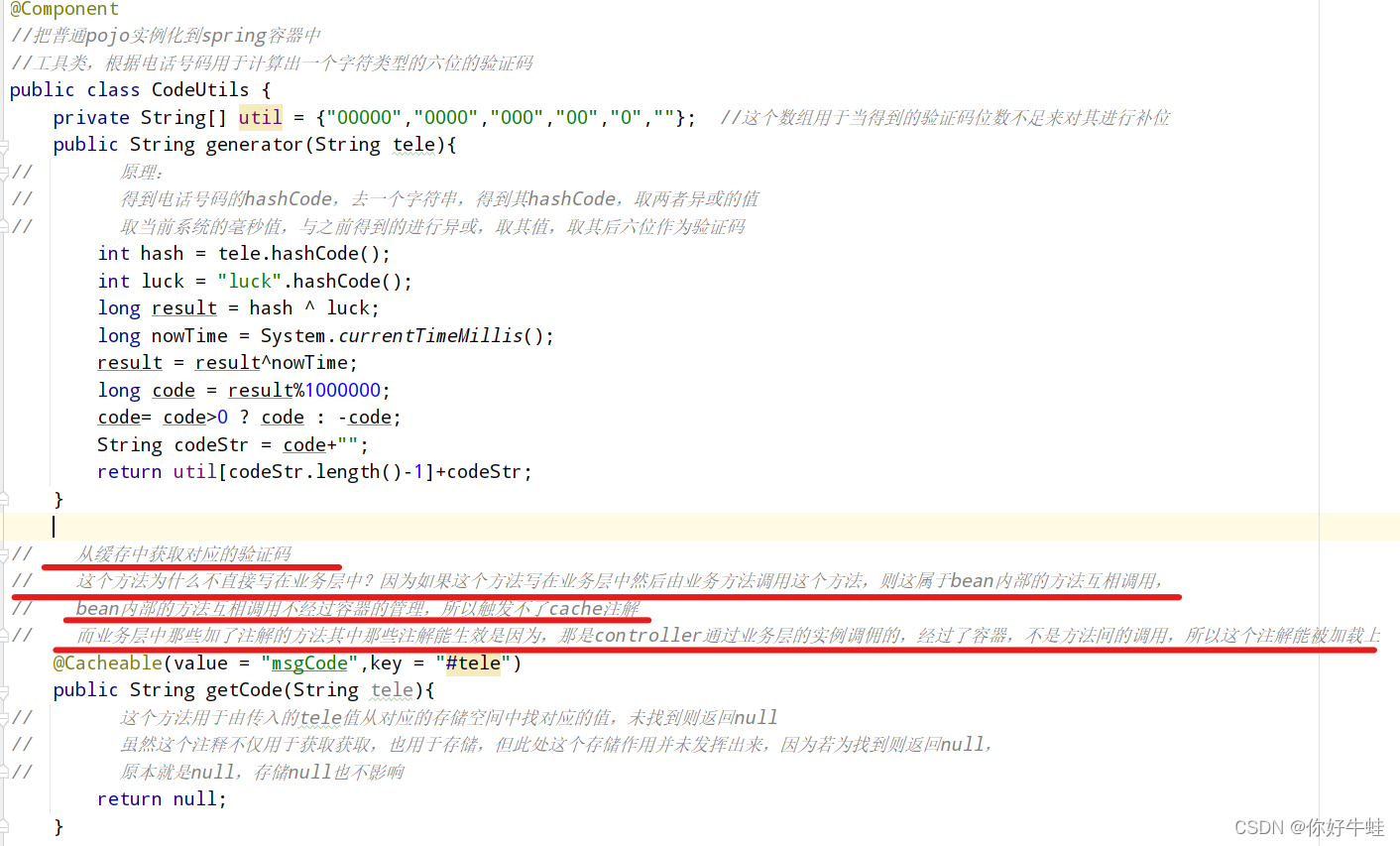
切换为Ehcache
三步
- 导入依赖包

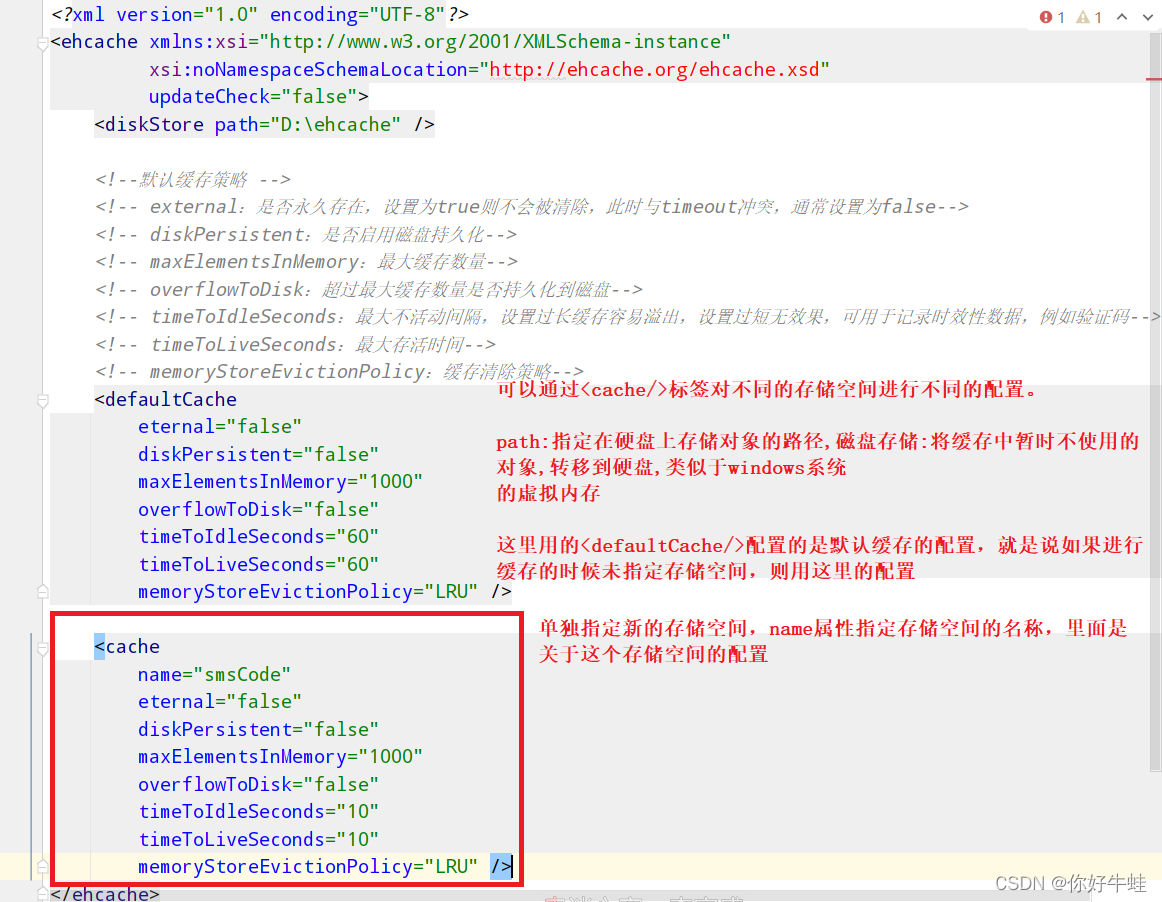
- 做配置 Ehcache是spring体系外的技术,而且他有自己的配置,所以使用他的话,需要再搞一个属于他的配置文件。并放在resources路径下。
 上面的配置文件也需要在配置中指定一下
上面的配置文件也需要在配置中指定一下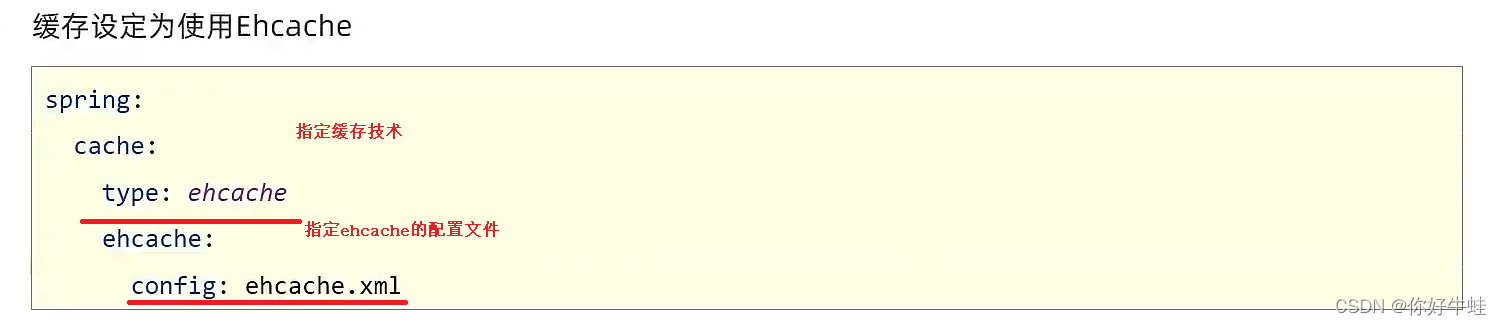
- 使用 其实使用起来和前面的simple一模一样,这就是springboot的精妙之处,他给这些提供了一个统一的接口,我们直接调用即可。如果想换不同的实现,我们可以直接选择这些接口的实现就行了,不用变更使用方法
配置文件内容
<?xml version="1.0" encoding="UTF-8"?><ehcachexmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"updateCheck="false"><diskStorepath="D:\ehcache"/><!--默认缓存策略 --><!-- external:是否永久存在,设置为true则不会被清除,此时与timeout冲突,通常设置为false--><!-- diskPersistent:是否启用磁盘持久化--><!-- maxElementsInMemory:最大缓存数量--><!-- overflowToDisk:超过最大缓存数量是否持久化到磁盘--><!-- timeToIdleSeconds:最大不活动间隔,设置过长缓存容易溢出,设置过短无效果,可用于记录时效性数据,例如验证码--><!-- timeToLiveSeconds:最大存活时间--><!-- memoryStoreEvictionPolicy:缓存清除策略--><defaultCacheeternal="false"diskPersistent="false"maxElementsInMemory="1000"overflowToDisk="false"timeToIdleSeconds="60"timeToLiveSeconds="60"memoryStoreEvictionPolicy="LRU"/><cachename="smsCode"eternal="false"diskPersistent="false"maxElementsInMemory="1000"overflowToDisk="false"timeToIdleSeconds="10"timeToLiveSeconds="10"memoryStoreEvictionPolicy="LRU"/></ehcache>
切换为redis
三步:
- 导入依赖包并启动redis服务

- 做配置下面这其中的注释比较重要

- 使用 前面已经说过了,springboot给这些提供了一个统一的接口,我们直接调用即可。如果想换不同的实现,我们可以直接选择这些接口的实现就行了,不用变更使用方法,就是说,使用方法跟之前一样,啥都不用该,就上面配置改一下,就等于换成了redis来实现缓存
切换为memcached
SpringBoot未提供对memcached的整合,所以这里也是相当于记录了如何整合springboot未整合的技术的模板
没有本地或者远程的服务的话,我们需要先在自己本机上下载对应的服务:地址
https://www.runoob.com/memcached/window-install-memcached.html
然后以管理员身份进入cmd,再进入memcached安装目录,执行安装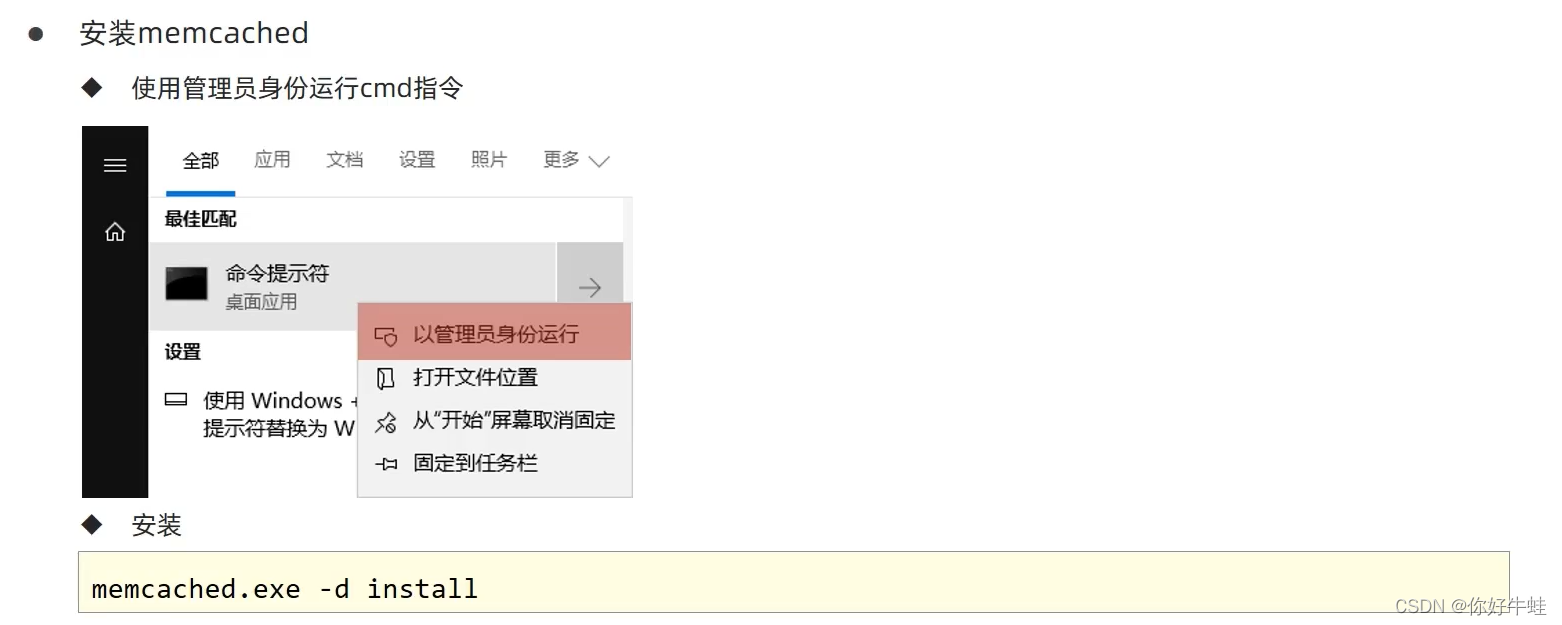
启动和停止服务的命令: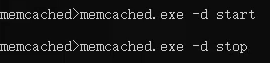
都需要在memcached安装目录下执行
服务有了,使用这个服务我们需要选择客户端
啥意思呢?就像redis,他的bin目录下有redis-service(服务端),redis-cli(客户端)
就是说redis提供了客户端,所以不需要我们特意去找客户端,但是memcached没有提供,所以需要我们去选择使用
memcached客户端选择
Memcached Client for Java:最早期客户端,稳定可靠,用户群广
SpyMemcached: 效率更高
Xmemcached:并发处理更好
我们选择Xmemcached
但是SpringBoot未提供对memcached的整合,需要使用硬编码方式实现客户端初始化管理
其实还是那三步,但是在配置上差别稍微大一点:
- 导入客户端的依赖包 即Xmemcached
 看这里带着版本号呢,因为springboot没给整合
看这里带着版本号呢,因为springboot没给整合 - 做配置 因为pringboot没给整合,咱们在boot里这样整合,写一个配置类,然后在将所需的配置信息写在yml配置文件中,然后在封装到配置类的实体中,然后在需要使用配置信息的地方通过这个实体来获取即可,这就是我们自定义的配置信息,将其封装到对象中的操作 具体学习yml可以看这里:
https://blog.csdn.net/qq_45821251/article/details/123188505?spm=1001.2014.3001.5501#yml_75(哈哈,这个也是我的笔记) 配置类: 这里用到了lombok lombok相关的看这里
配置类: 这里用到了lombok lombok相关的看这里https://blog.csdn.net/qq_45821251/article/details/123188505?spm=1001.2014.3001.5501#lombok_206(哈哈,还是我那篇笔记中的) 然后加载配置,得抛出异常 这里也是获取操作memcache客户端的对象,就像操作redis有redisTemplate一样,操作memcache有memcachedClient,通过这个类的实例来操作memcache客户端。就下面加了@Bean的那个方法,用来获取和配置memcachedClient的实例
然后加载配置,得抛出异常 这里也是获取操作memcache客户端的对象,就像操作redis有redisTemplate一样,操作memcache有memcachedClient,通过这个类的实例来操作memcache客户端。就下面加了@Bean的那个方法,用来获取和配置memcachedClient的实例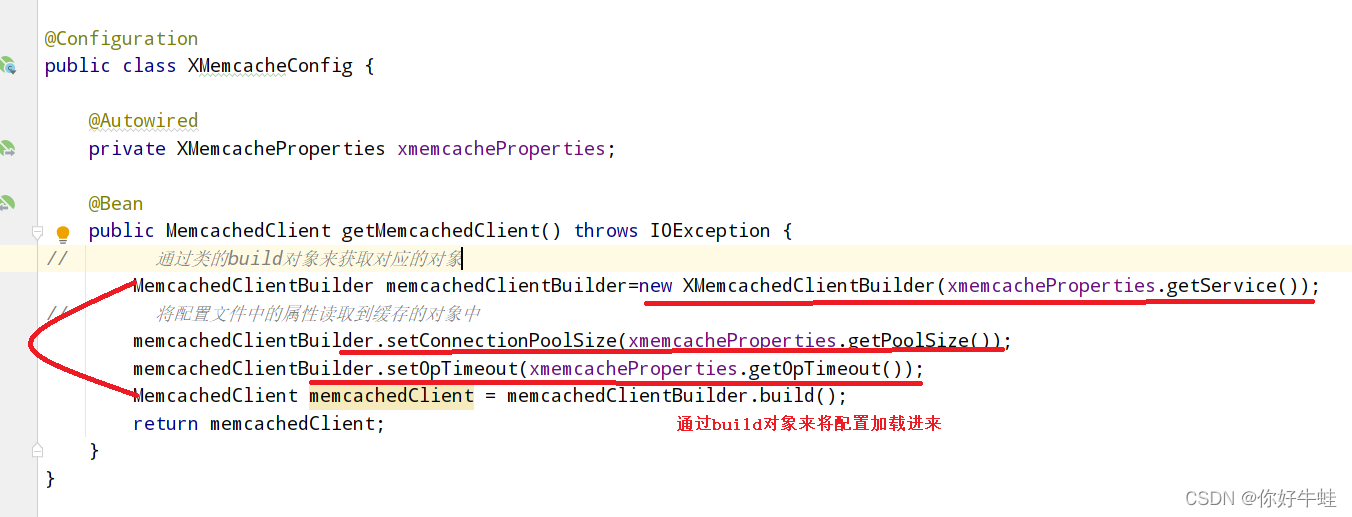
- 使用 就是换一种缓存的实现方式,业务还是跟前面一样。 这里,第二个@Autowired那里,就是将上面获取的memcachedClient的对象注入进来

定时任务
企业开发中,总不免有些需要定时执行的任务,比如年度报表,缓存统计报告…
java提供的定时任务制作
java提供了一些api用于执行定时任务
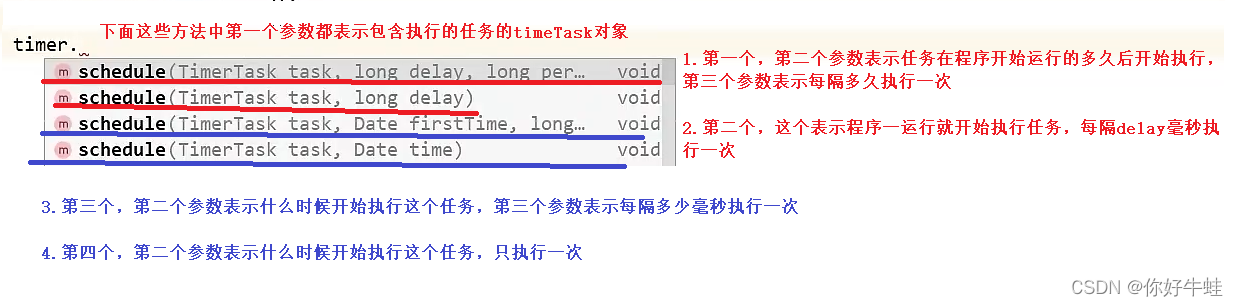
使用quartz
Quartz是市面上比较流行的定时任务技术
Quartz将定时任务拆分又加了一些设定
quartz中有这么一些相关的概念
相关概念
工作 (Job) :用于定义具体执行的工作
工作明细 (JobDetail) :用于描述定时工作相关的信息
触发器 (Trigger) :用于描述触发工作的规则,通常使用cron表达式定义调度规则
调度器 (Scheduler) :描述了工作明细与触发器的对应关系
使用这个技术也是三步
- 导入依赖包

- 做配置 他需要的配置比较多,跟后面要讲的task比真的很繁杂 这里要做的工作就是实现这三个部分,工作明细 触发器 调度器 工作明细指定工作,然后触发器绑定工作明细,然后调度器描述触发器和工作明细的关系 就上面这东西,一听就知道很麻烦 先看看工作部分,即要执行的任务,这里有一个执行的任务: 这个任务要使用quartz的话,需要继承QuartzJobBean,并实现对应的方法,执行的任务就写在这个方法里面 这个方法提供了一个工作执行的上下文对象,即那个参数,通过这个上下文对象可以拿到很多具体的信息 注意这个类并没有定义为一个spring的bean,不需要
 实现:工作明细指定工作,然后触发器绑定工作明细,然后调度器描述触发器和工作明细的关系 用配置类完成这样的配置
实现:工作明细指定工作,然后触发器绑定工作明细,然后调度器描述触发器和工作明细的关系 用配置类完成这样的配置 cron表达式一点基础知识看下面的目录
cron表达式一点基础知识看下面的目录 - 使用 哈哈哈,这里的使用其实和上面配置都融到一起了,上面已经完成所有工作了,直接运行即可
cron表达式一点基础知识
(“a b c d e f”)
一般有六项,从左到右分别代表,a:秒,b:分,c:时,d:日,e:月,f:星期几
他们的值设置为
*
则表示任意,如
"5 * * * * *"
表示任意分钟的5秒执行
一般d和f不会同时设定一个具体的值,比如不能这样设置
"0 * * 1 * Monday"
这谁能确定1号就是星期1呢?所以一般是若一个设置为具体的值,则另一个需要设置为
?
表示根据另一个值进行匹配,如
"0 * * 1 * ?"
根据前面日子匹配星期
每一项有可以设定各种的值,如
"0/5 * * * * ?"
表示每隔5s执行一次
"0 5/5 * * * ?"
表示从每小时的第五分钟开始运行,每隔5分钟运行一次
"0,5,8,56 * * * * ?"
表示每分钟的0秒、5秒、8秒、56秒执行
更详细的可以去学习一下,网上一大堆,cron表达式生成器也一搜一大堆
使用task
由上面几个步骤,就知道这个quartz多让人难受了
还好,springboot给整了个简单方便的
只需简单的两步就能实现简单的定时任务
- 在项目中开启定时任务的功能在容器能扫描到的地方加上这个注解
@EnableScheduling按照规范,我们一般加载启动类上,表示开启定时任务的功能
- 在需要执行定时的任务上加上注解
@Scheduled(cron = "")cron的值是cron表达式,作用就是设置执行时间和频度等,这个类需要被标注为bean,交由spring管控
只这两步,就完成了定时任务
更详细的设定,可以通过配置文件来搞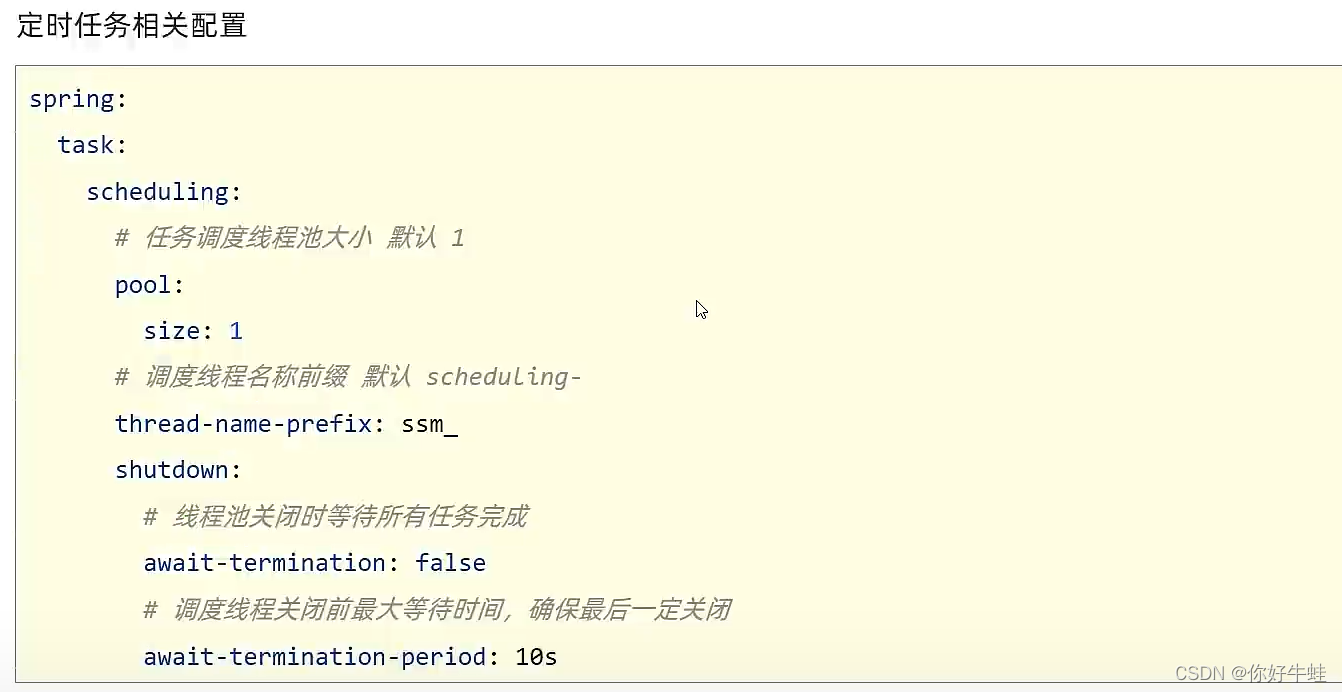
整合JavaMail(发邮件)
关于收发电子邮件有三个协议
SMTP (Simple Mail Transfer Protocol) :简单邮件传输协议,用于发送电子邮件的传输协议
POP3 ( Post Office Protocol - Version 3) :用于接收电子邮件的标准协议
IMAP ( Internet Mail Access Protocol) :互联网消息协议,是POP3的替代协议
POP3协议因为同步问题,被IMAP替代了
发送简单邮件
三步
- 导入依赖包

- 配置 配置需要补充这几项
 username就是我们的邮箱账户host是为了区别邮件供应商,比如使用QQ邮箱,则host为smtp.qq.com,前缀smtp表示smtp协议。password并不是邮箱账户的密码,是一个授权码,可以说是一个密码令牌,密码通行证 获取方式:
username就是我们的邮箱账户host是为了区别邮件供应商,比如使用QQ邮箱,则host为smtp.qq.com,前缀smtp表示smtp协议。password并不是邮箱账户的密码,是一个授权码,可以说是一个密码令牌,密码通行证 获取方式: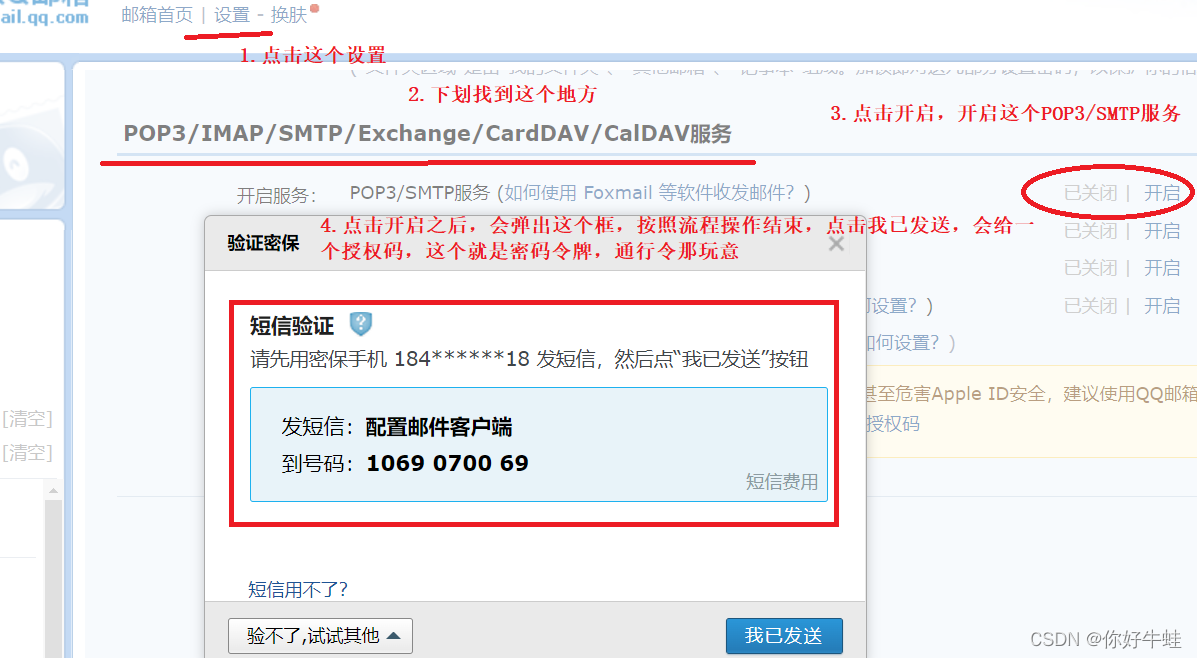 就类似于下面这样的:
就类似于下面这样的: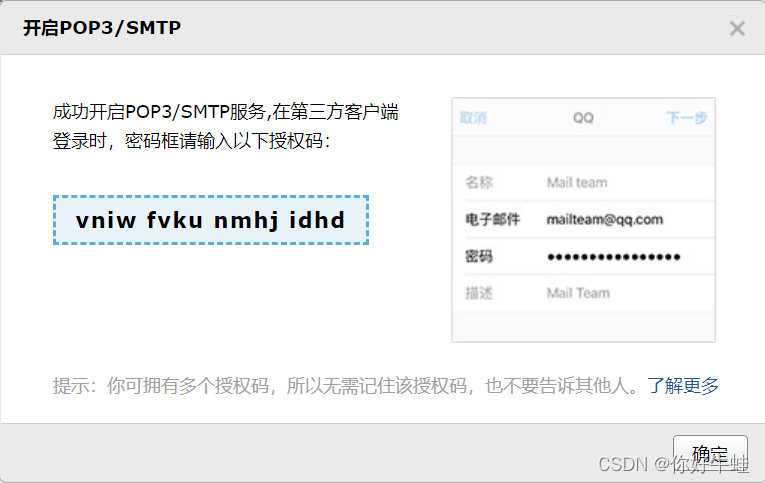
- 使用 使用其实就是操作客户端,前面的整合技术中的操作原理也是操作客户端 具体的解释都在注释里了,实在不想再编辑一下图片了
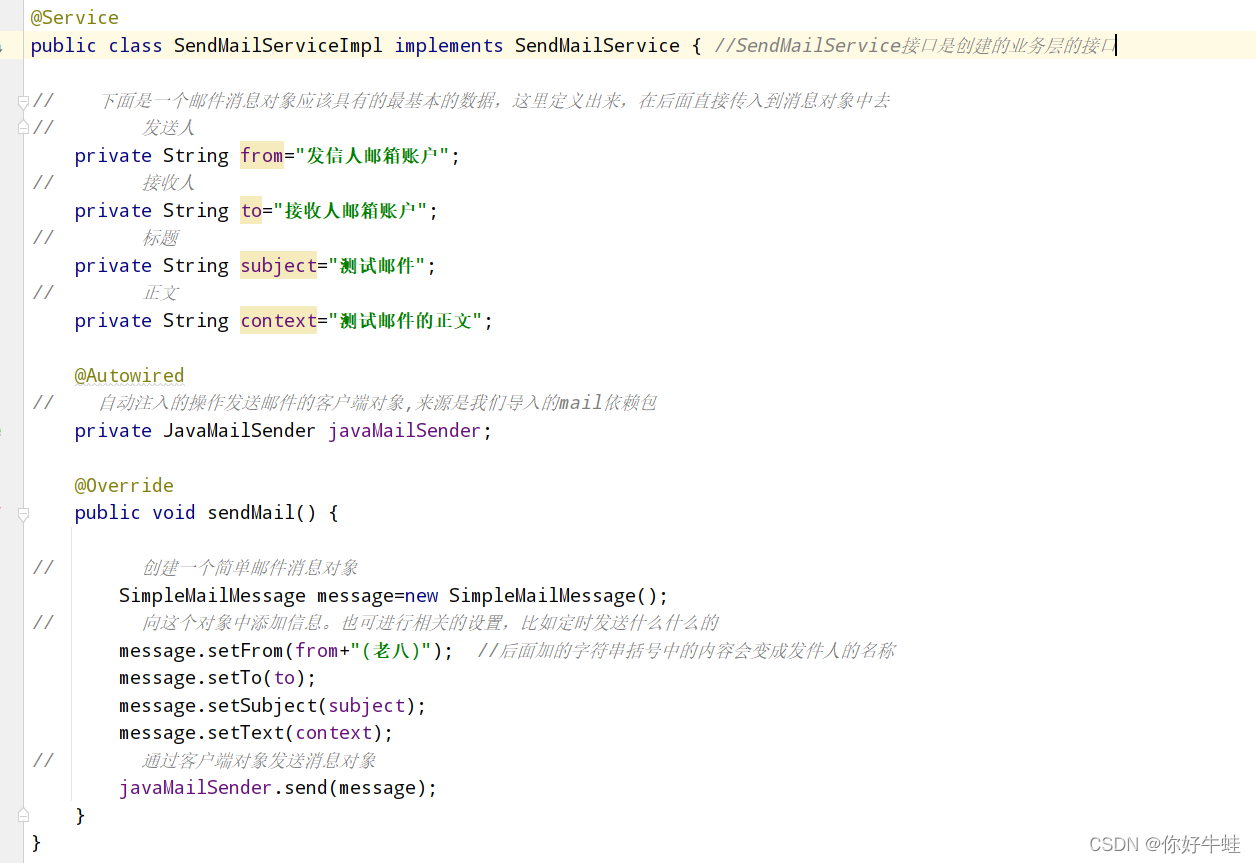 上面定义的几个字符串类型的数据就对应着这里的这几项:
上面定义的几个字符串类型的数据就对应着这里的这几项: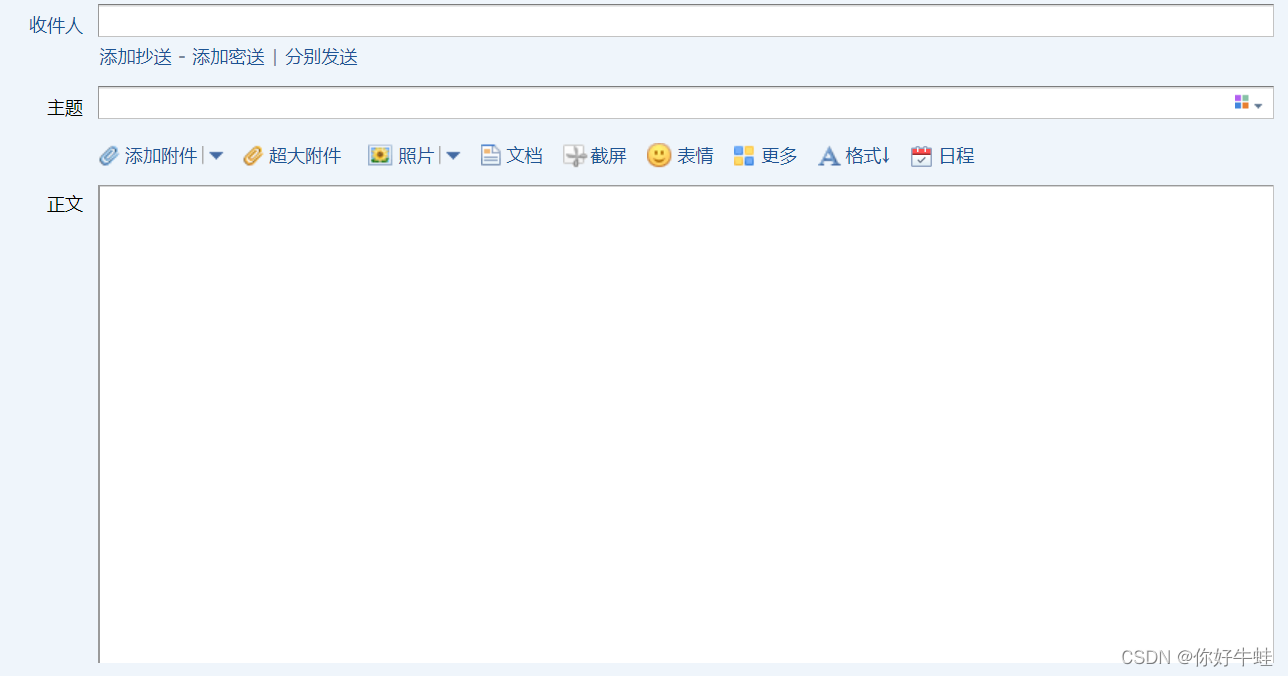 运行程序执行效果:
运行程序执行效果:
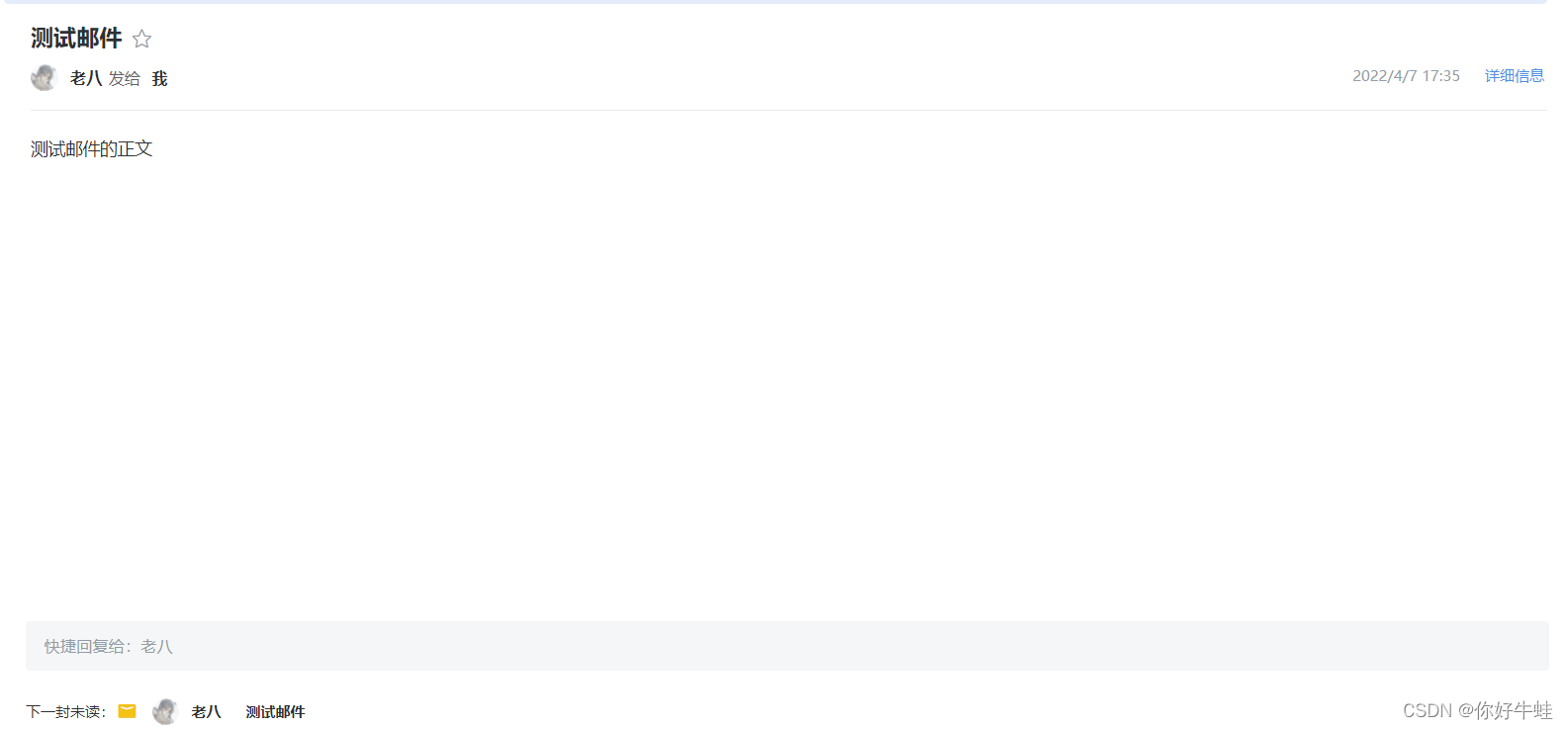
这就实现了简单邮件的发送
下面是可以包含链接,图片,文件等等信息的邮件发送
发送多部件邮件
多部件邮件其实就是邮件中能够包含多个部件的邮件
比如包含附件的邮件,甚至能够通过html格式解析邮件正文
发送这样的邮件的步骤和发送简单邮件的步骤一样
只是更换消息对象,和设置数据信息的方式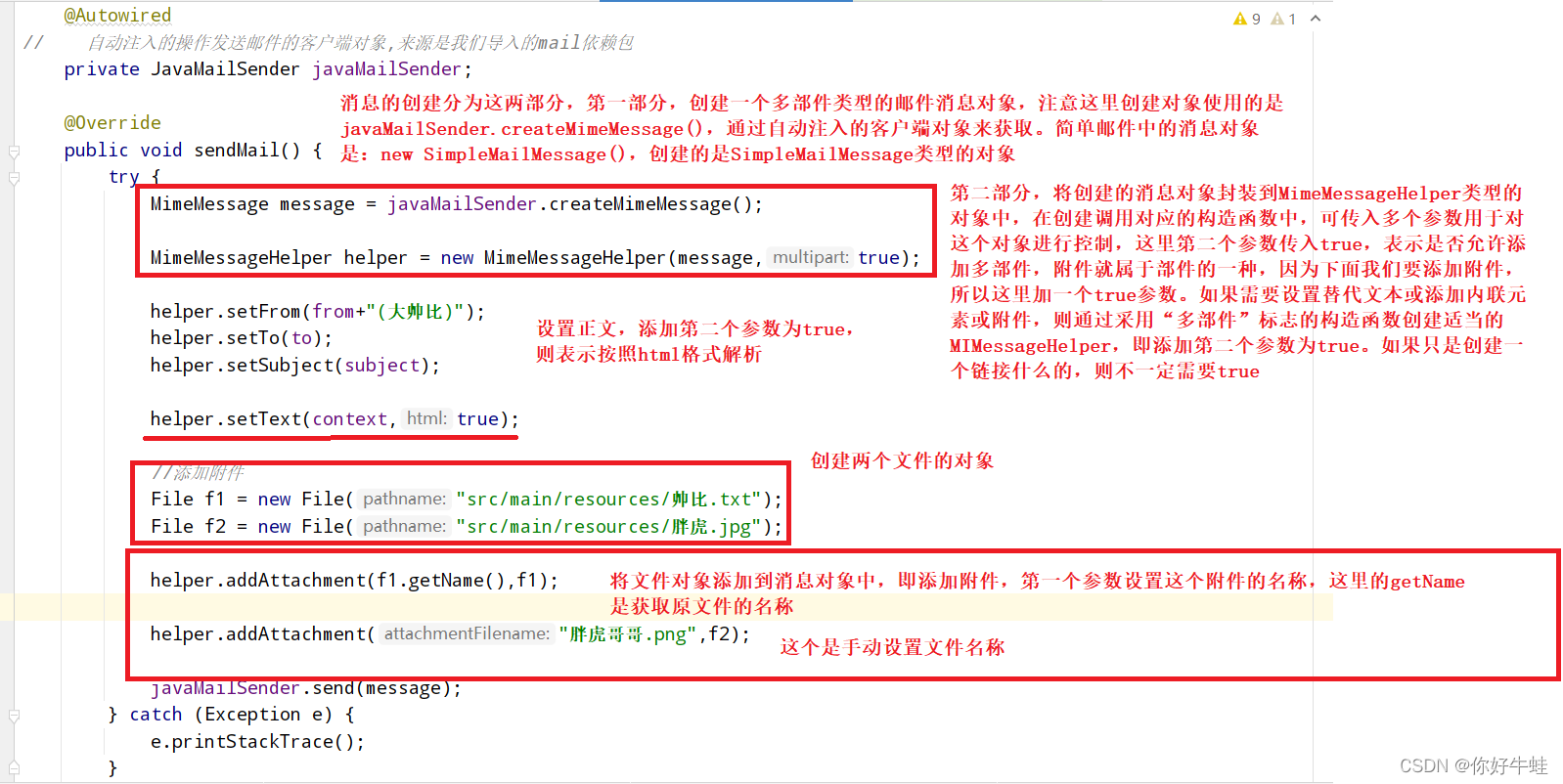
如果,要在正文中嵌入图片
如果图片是在网络上,则直接使用"",然后用开启html解析即可
如果是本地的图片,则需要换一个把戏
如下:这是如果图片是在本地的情况下
实现内嵌图片是靠下面标注出来的地方,注意下面标注出来的地方,在后面讲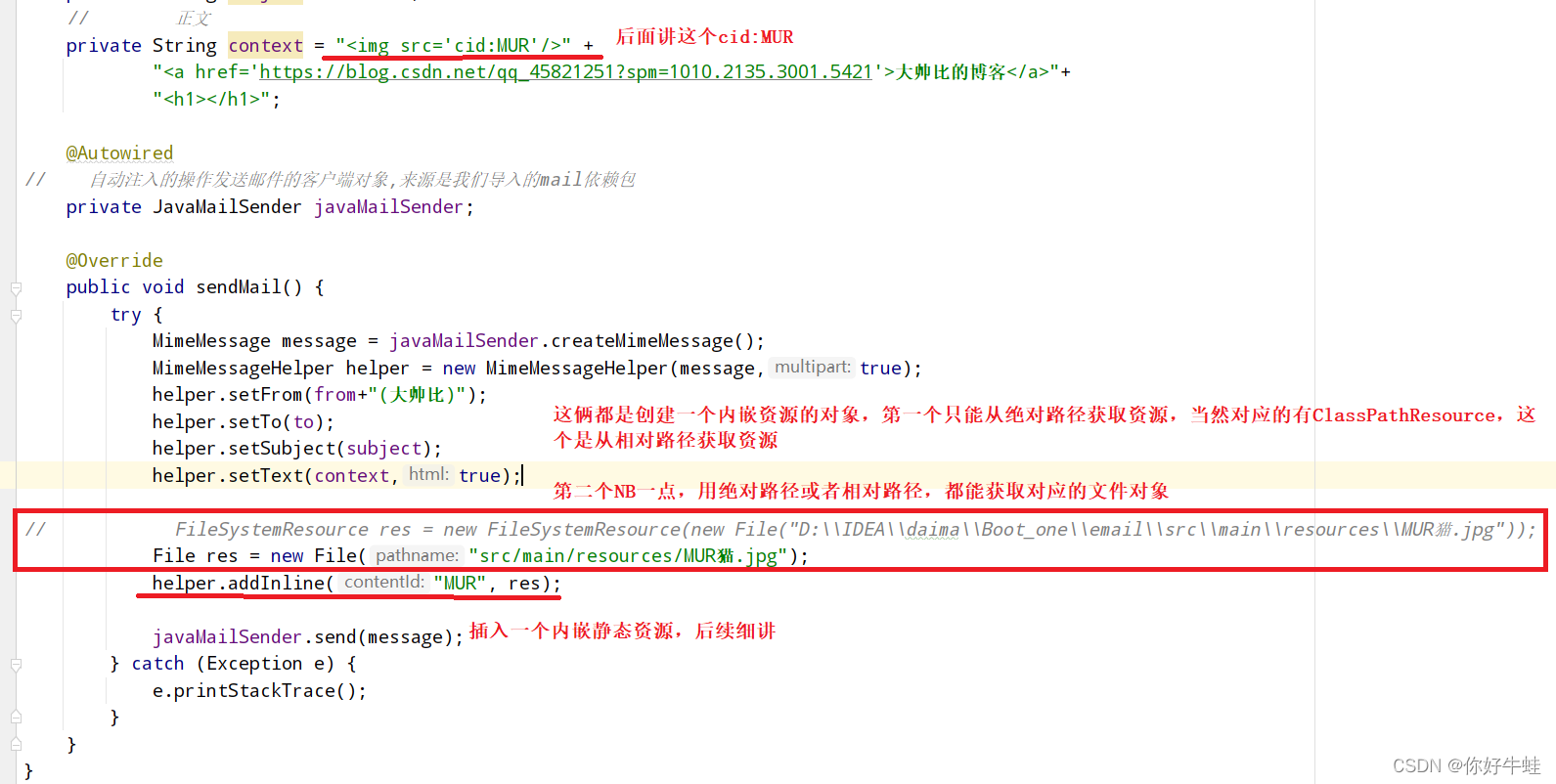
- src=“cid:MUR” ?cid: 全称是Content-ID Content-ID头字段用于为"multipart/related" 组合消息中的内嵌资源指定一个唯一标识号,在HTML格式的正文中可以使用这个唯-标识号来引用该内嵌资源。例如,假设将一个表示内嵌图片的MIME消息的Content-ID头字段设置为如下形式: Content-ID:MUR 那么,在HTML正文中就需要使用如下HTML语句来引用该图片资源:
注意,在引用Content-ID头字段标识的内嵌资源时,要在资源的唯一标识号前面加上"cid:" ,以说明要采用唯一标识号对资源进行引用。 在此处作用通俗点将就是作一个占位符,表示这里应该是一个标识号是MUR的内嵌资源
- File和FileSystemResourc ? 作用:创建一个内嵌资源,具体可以看上图中的文字说明
- helper.addInline ? helper.addInline(内嵌资源标识符,内嵌资源的对象),用于为当前的消息对象添加一个内嵌资源,更形象点将,更应该叫做向指定地点位置插入一个内嵌资源。即将内嵌资源的对象(参数二)插入到内嵌资源标识符(参数一)所在的地方,跟上面
src="cid:MUR"相对应 为什么这样说,可以看一下官方文档:注意下面警告那一部分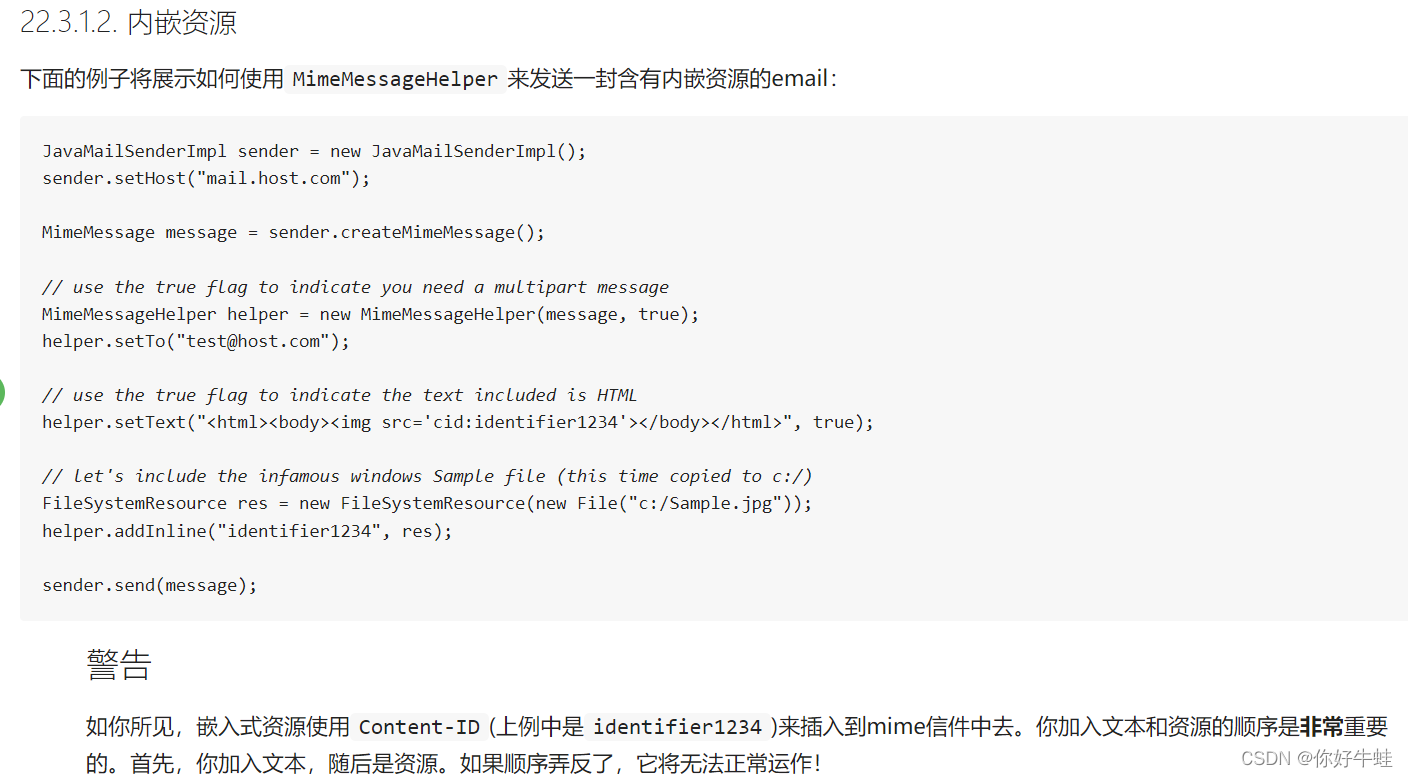
其实这里的原理:
看一下官方的这段话:
Multipart email允许添加附件和内嵌资源(inline resources)。内嵌资源可能是你在信件中希望使用的图像或样式表,但是又不想把它们作为附件。
就是说,这里潜入的内嵌资源也是附件,即也是多部件的一个部件,通过上面的操作,可以将这个附件不按照附件的形式来展示,而是通过内嵌的形式,潜入到邮件正文中
注意重要的一点:在下面这个地方,依然要增加第二个参数,并为其设置为true,因为这个内嵌的资源也是多部件的一种
看一下结果:
没啥意思,就想告诉大家,我是大帅比
中间件之消息队列
**
这里还是要说,涉及到的技术并没有做很详细的讲解,以整合为主,但是足够会基本使用和了解了。某个单一的技术更详细的知识还是要找具体的课程学习
**
- 什么是中间件? 我也不是很明白,就是你好像知道,但是描述不出来,这说明了解的还是太少 百度百科: 中间件是一类连接软件组件和应用的计算机软件,它包括一组服务。以便于运行在一台或多台机器上的多个软件通过网络进行交互。该技术所提供的互操作性,推动了一致分布式体系架构的演进,该架构通常用于支持并简化那些复杂的分布式应用程序,它包括web服务器、事务监控器和消息队列软件。 IT界有句俗话说,所有问题都可以通过增加一层来解决。 中间件也是加一层,在两个服务之中加一层 比如redis,中间件的一种,他就是在程序和数据库之间加一层,当然redis不仅仅能用于存储数据库信息。再比如RabbitMQ,消息队列,就是在消息的发送方和接收方之间加一层,提高了极大的效率。 就这么回事
- 什么是消息? 百度百科: “消息”是在两台计算机间传送的数据单位。消息可以非常简单,例如只包含文本字符串;也可以更复杂,可能包含嵌入对象。 很了然了,就是数据单位 消息有发送方和接收方 我们称为生产者和消费者 消息有同步消息和异步消息 同步消息: 生产者向消费者发送消息,只有得到消费者的回应后,生产者才会进行下一步的操作,这样的称为同步消息 异步消息: 生产者向消费者发送消息,无需得到消费者的回应,生产者即可进行下一步的操作,这样的称为异步消息
- 什么是消息队列? 百度百科: “消息队列”是在消息的传输过程中保存消息的容器。
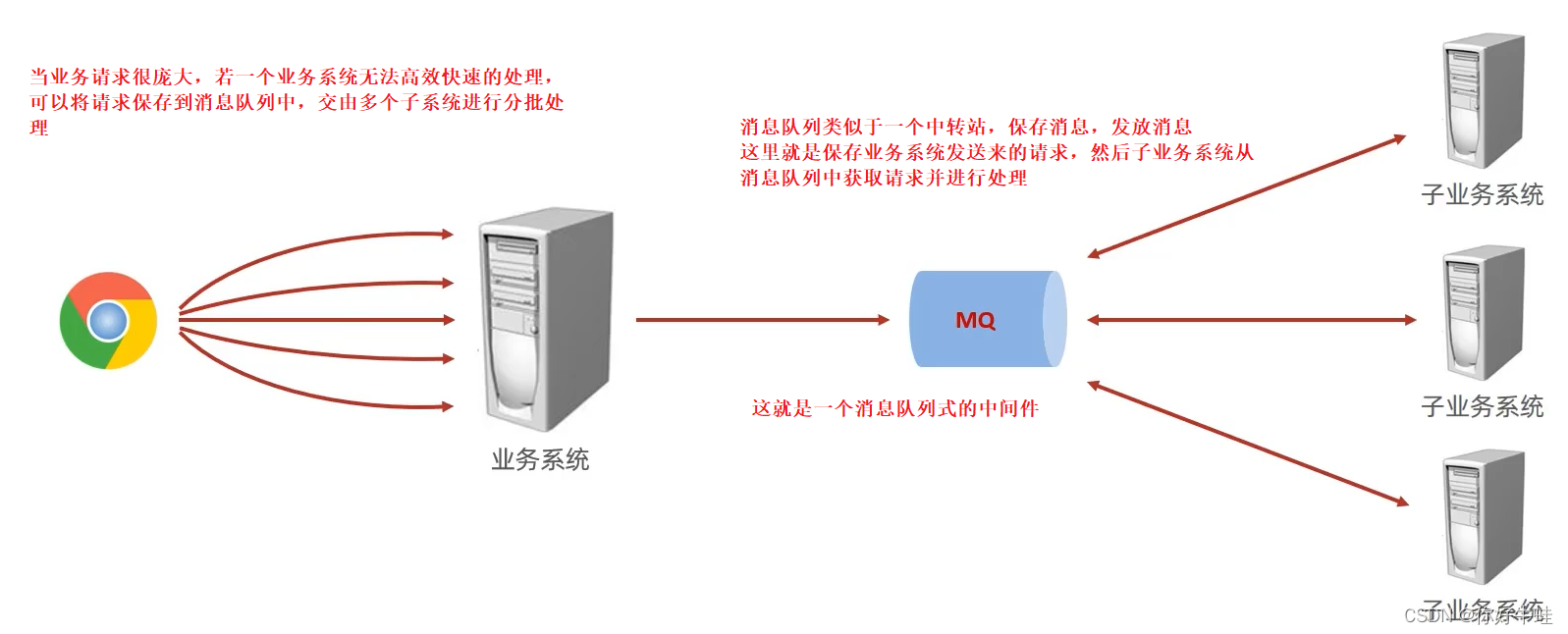 同步消息对我们的意义不是很大,消息队列的高并发靠的是异步消息 相关产品有RabbitMQ,ActiveMQ,RocketMQ… …
同步消息对我们的意义不是很大,消息队列的高并发靠的是异步消息 相关产品有RabbitMQ,ActiveMQ,RocketMQ… … - 企业级应用中广泛使用的三种异步消息传递技术: JMS AMQP MQTT 这三组对应了又有若干个实现技术,比如消息队列中现在常用的 RabbitMQ,ActiveMQ,RocketMQ… …JMS: JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的API,绝大多数MOM提供商都对JMS提供支持。
 AMQP: JMS出来的要比AMQP早,JMS是一个规范,类似于JDBC,而且JMS定义的一些接口仅适用于Java平台,并不适用于其他语言,所以在这个基础上人们提出了一个协议
AMQP: JMS出来的要比AMQP早,JMS是一个规范,类似于JDBC,而且JMS定义的一些接口仅适用于Java平台,并不适用于其他语言,所以在这个基础上人们提出了一个协议 他将所有的消息种类规范为字节单位,主要就是靠这个实现跨平台的。消息模型注意direct和topic两个模型 百度百科: AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。他兼容JMS AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。这使得实现了AMQP的provider天然性就是跨平台的。AQMP可以用http来进行类比,不关心实现的语言,只要大家都按照相应的数据格式去发送报文请求,不同语言的client均可以和不同语言的server链接。 AMQP跟JMS的关系可以类比于炒菜:AMQP规范了炒菜动作,JMS规范了放啥原料,炒菜动作都差不多,放啥原料要根据炒啥菜来放MQTT 用于物联网
他将所有的消息种类规范为字节单位,主要就是靠这个实现跨平台的。消息模型注意direct和topic两个模型 百度百科: AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。他兼容JMS AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。这使得实现了AMQP的provider天然性就是跨平台的。AQMP可以用http来进行类比,不关心实现的语言,只要大家都按照相应的数据格式去发送报文请求,不同语言的client均可以和不同语言的server链接。 AMQP跟JMS的关系可以类比于炒菜:AMQP规范了炒菜动作,JMS规范了放啥原料,炒菜动作都差不多,放啥原料要根据炒啥菜来放MQTT 用于物联网
常用实现消息队列的技术有四个:
RabbitMQ
ActiveMQ
RocketMQ
Kafka:一种高吞吐量的分布式发布订阅消息系统,提供实时消息功能,可以实现消息队列的功能,但主要不使用用于做消息队列
这里记录两个常用的消息队列的整合
RabbitMQ
ActiveMQ
实现一个业务
先实现一个简单的业务,基于这个业务用于后续整合消息队列
业务功能:模仿订单处理其中的发短信功能(并不是真正的发短信)
两个类,一个表示类用于调用处理具体业务的具体实现(实际应该是这样做,这里是模拟,就意思意思一下),这里模拟的是发送短信,所以至少应该有一个实现具体发送短信的类吧,这里第二个类就是这个作用,当然就是具体意思意思,也不是真正的发送短信
调用处理具体业务的类:
一个实现具体发送短信业务的类: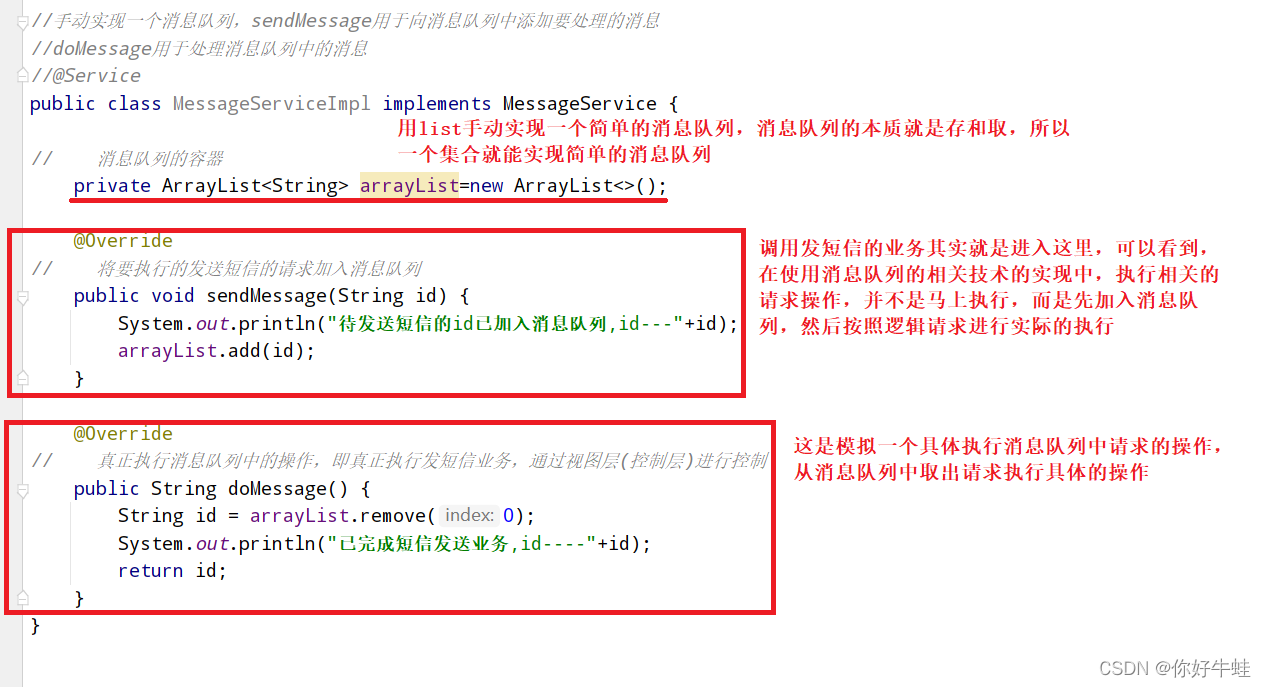
按照开发流程,进行具体的发短信业务的类是消费消息,也应该对应一个视图层,不然里面的具体的发短信业务的那个方法无法调用
两个视图层:

切换为ActiveMQ
Apache ActiveMQ是Apache软件基金会所研发的开放源代码消息中间件;由于ActiveMQ是一个纯Java程序,因此只需要操作系统支持Java虚拟机,ActiveMQ便可执行。
市场使用量也很大
ActiveMQ的安装和启动
下载地址:
https://activemq.apache.org/activemq-5016004-release
这个是5.16.4版本,5.17即往上需要jdk 11+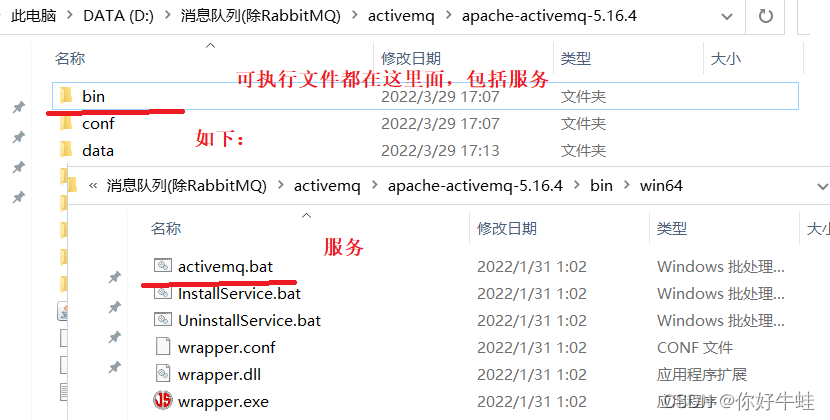
启动服务需要三个端口:5672,61613,1883,启动失败可以看看是哪个端口被占用:
比如这里,我启动active服务失败了,往下找到第一个报错的地方,可以看到是说5672的端口被占用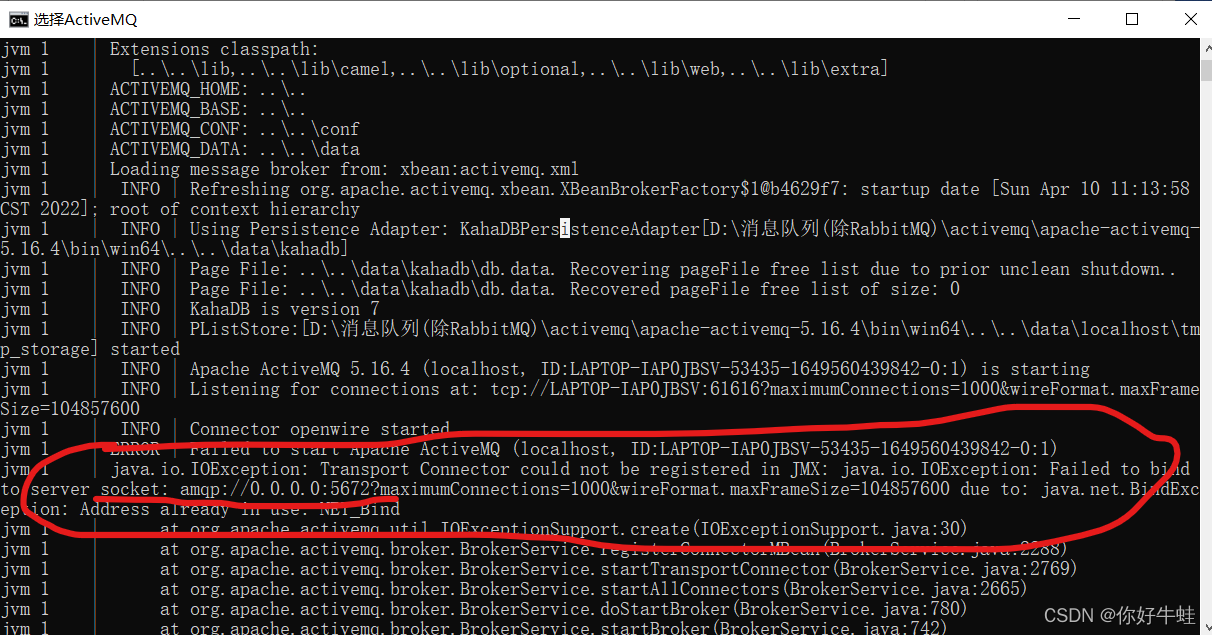
然后我们可以查找当前这个端口是被什么玩意给占了,把相关进程关了就行,一般我们能手动关闭的进程都是不重要的,不要担心因为手动关闭进程而导致电脑系统崩掉
根据端口关闭进程的方法后面再记录(往下找就能找到),这里直接接着上面写
这里就是因为我安装了RabbitMQ所需要的erlang语言,他的后台进程会占用5672端口,把它关闭了服务就能启动
启动服务
启动服务就是启动bin下的
activemq.bat
直接点击或在cmd执行都可
这个样子:可以看到最下面,给了一个地址,这个是activeMQ给我们提供一个web端的控制台的地址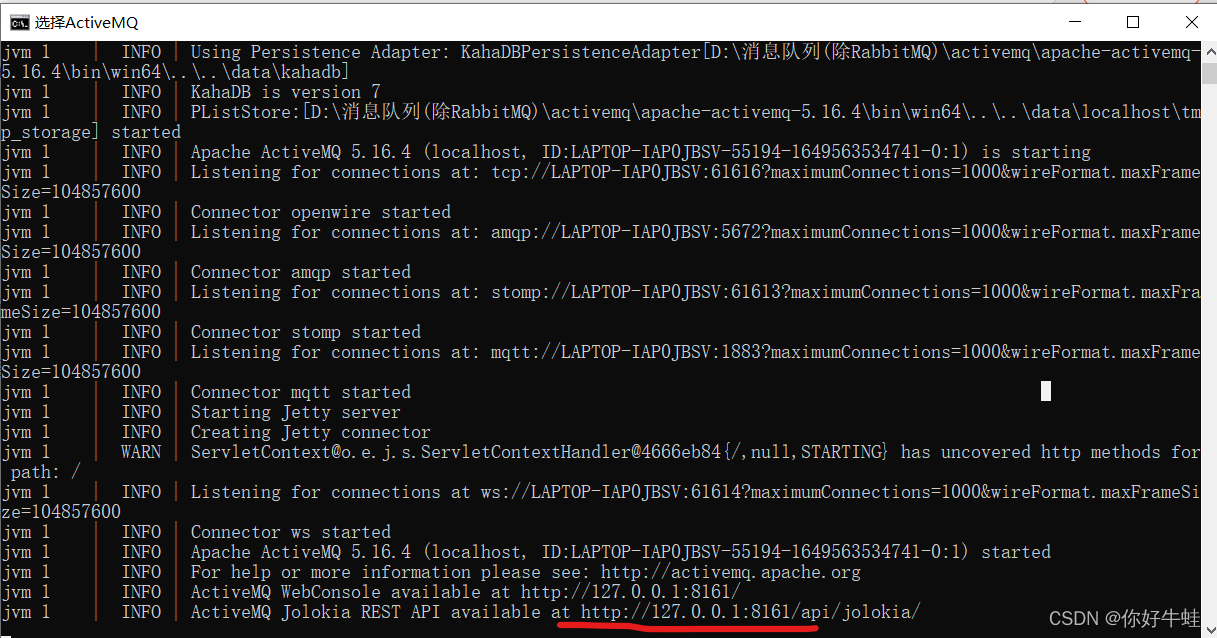
进入这个地址,会问你要密码和账户,初始默认都是admin,然后进入后这样: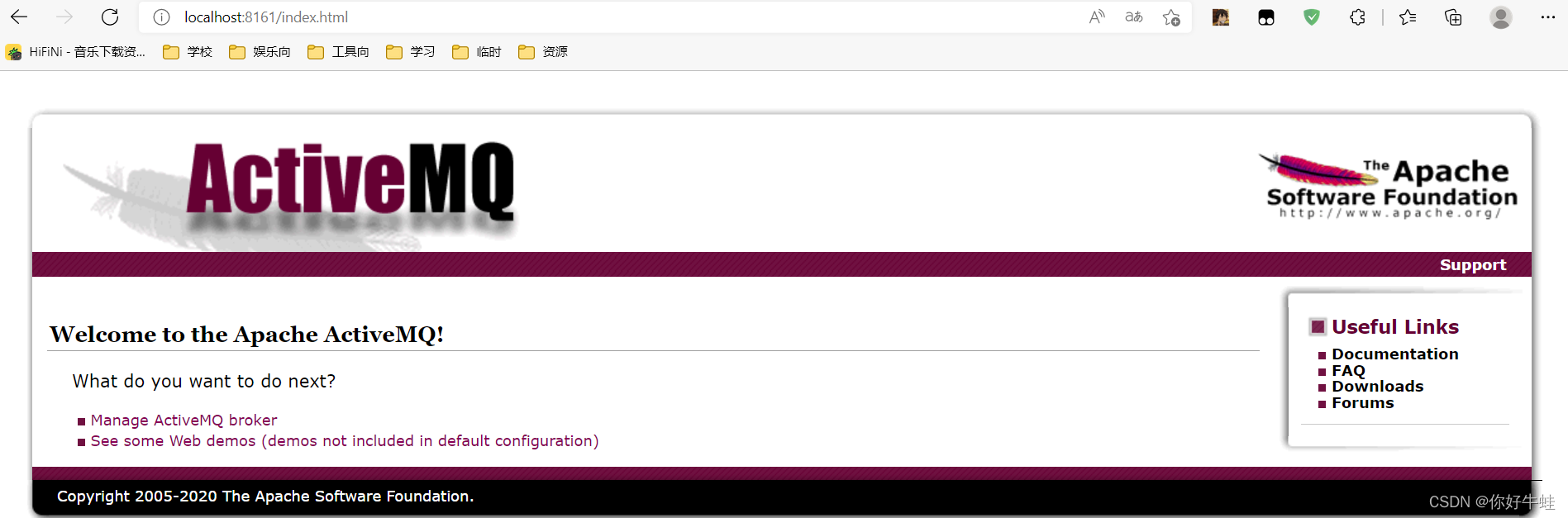
点击那个
Manage ActiveMQ broker
就能进入如下这样的相关的管理界面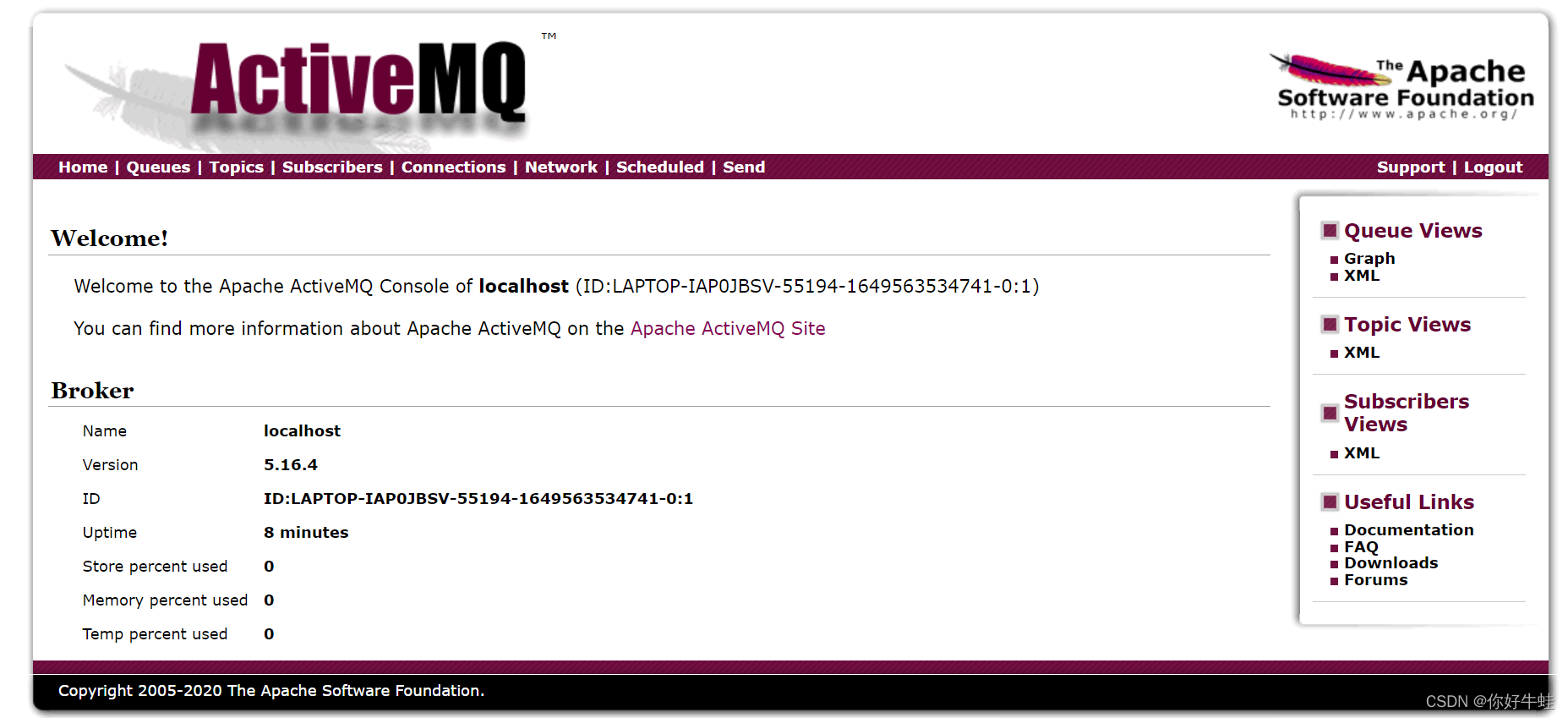
windows下根据端口,关闭相关进程
分为两步:
- 查看端口被什么进程占用 在cmd下,这个命令用于查看占用对应端口号的进程信息
netstat -ano | findstr 端口号显示的结果中每个值的含义: 1:协议 2:本地地址 3:外部地址 4:状态 5:PID 我们需要的只是最后面的PID值 根据PID值查看对应的进程信息:
我们需要的只是最后面的PID值 根据PID值查看对应的进程信息:tasklist|findstr PID值
- 关闭相关进程 有两种方法 第一是还在cmd下执行关闭命令:
taskkill -PID PID值 -F这个权限不够高,可能无法生效 或者直接根据PID值在任务管理器中找到对应的进程,进行手动关闭: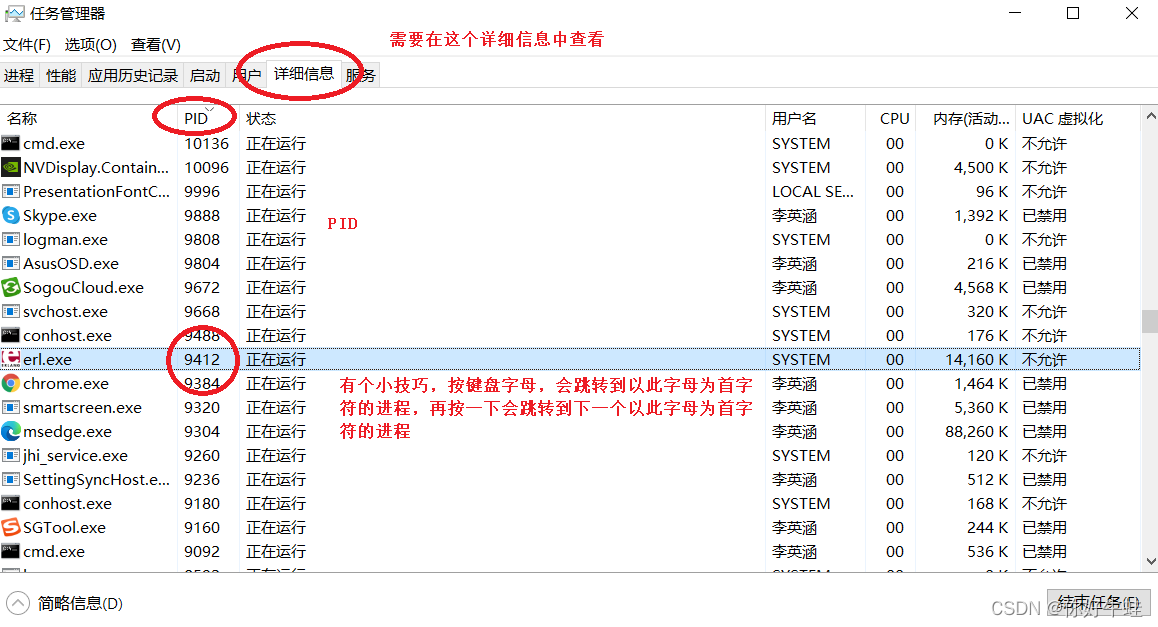 这里建议,在详细信息中找到对应的进程信息后,在这里找到这个进程进行关闭
这里建议,在详细信息中找到对应的进程信息后,在这里找到这个进程进行关闭
业务更换为activeMQ实现
三步
- 导入坐标

- 做配置 设置所连接的消息队列的地址
 本机的话,格式是:
本机的话,格式是: tcp://localhost:服务的端口号tcp是tcp协议,localhost表示本机的地址,后面的端口号是ActiveMQ服务所使用的端口号 - 使用接口操作
 当向消息队列中存放消息的时候,需要为当前要发送的消息指定一个存储地址,因为消息队列也是一个大的容器,每次存放的消息应该分类划分进行存储,所以要在消息队列中指定一个位置,不然会报错 设置一个默认的存储路径:
当向消息队列中存放消息的时候,需要为当前要发送的消息指定一个存储地址,因为消息队列也是一个大的容器,每次存放的消息应该分类划分进行存储,所以要在消息队列中指定一个位置,不然会报错 设置一个默认的存储路径: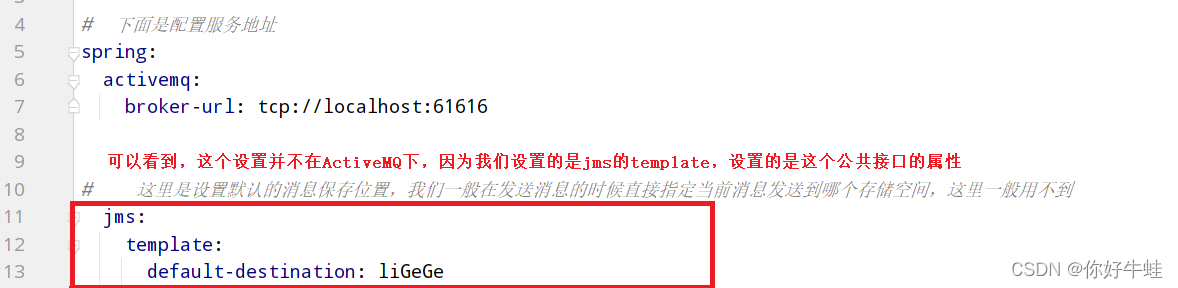 然后通过postman测试:
然后通过postman测试: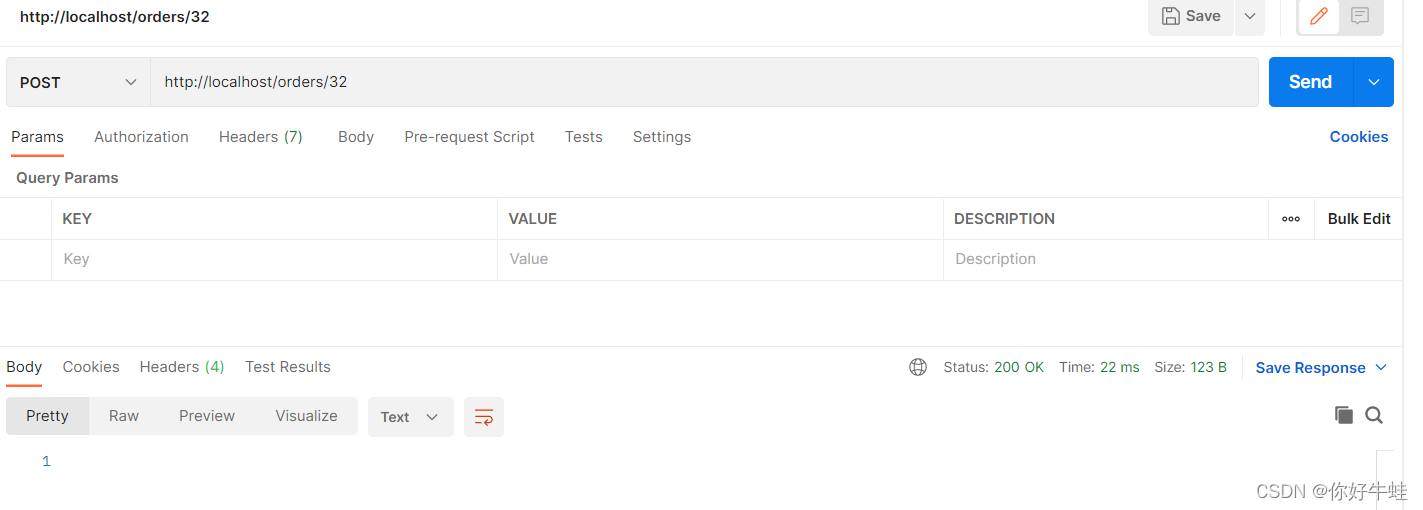 测试结果如下:
测试结果如下: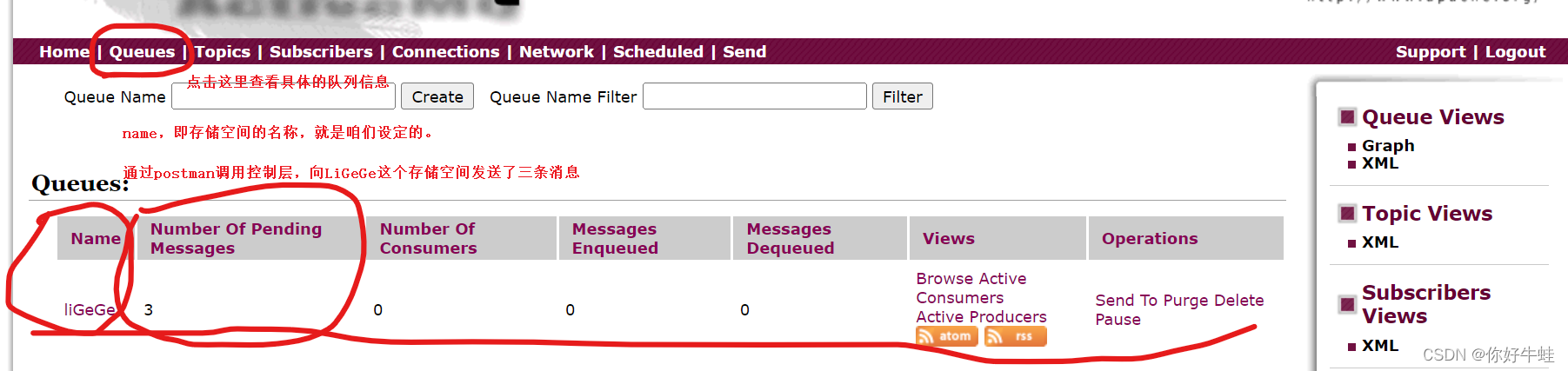 消费消息: 通过postman通过设定的msgs路径进行调用:
消费消息: 通过postman通过设定的msgs路径进行调用: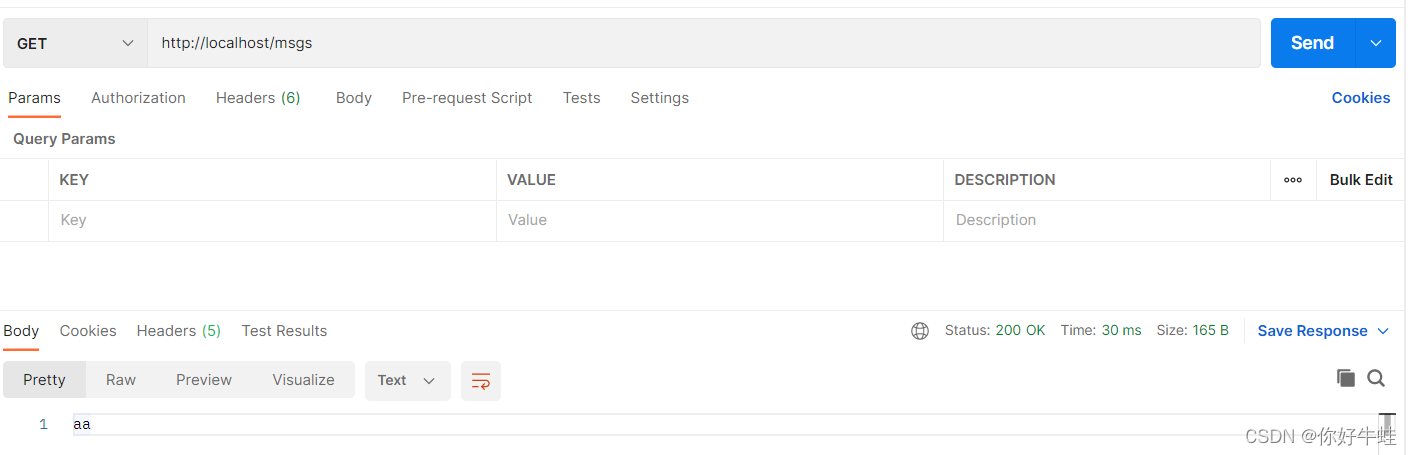 这里,会从头取出第一个消息进行处理 但是,这里的存储空间的设定确实不妥,我们一般应该这样搞:
这里,会从头取出第一个消息进行处理 但是,这里的存储空间的设定确实不妥,我们一般应该这样搞: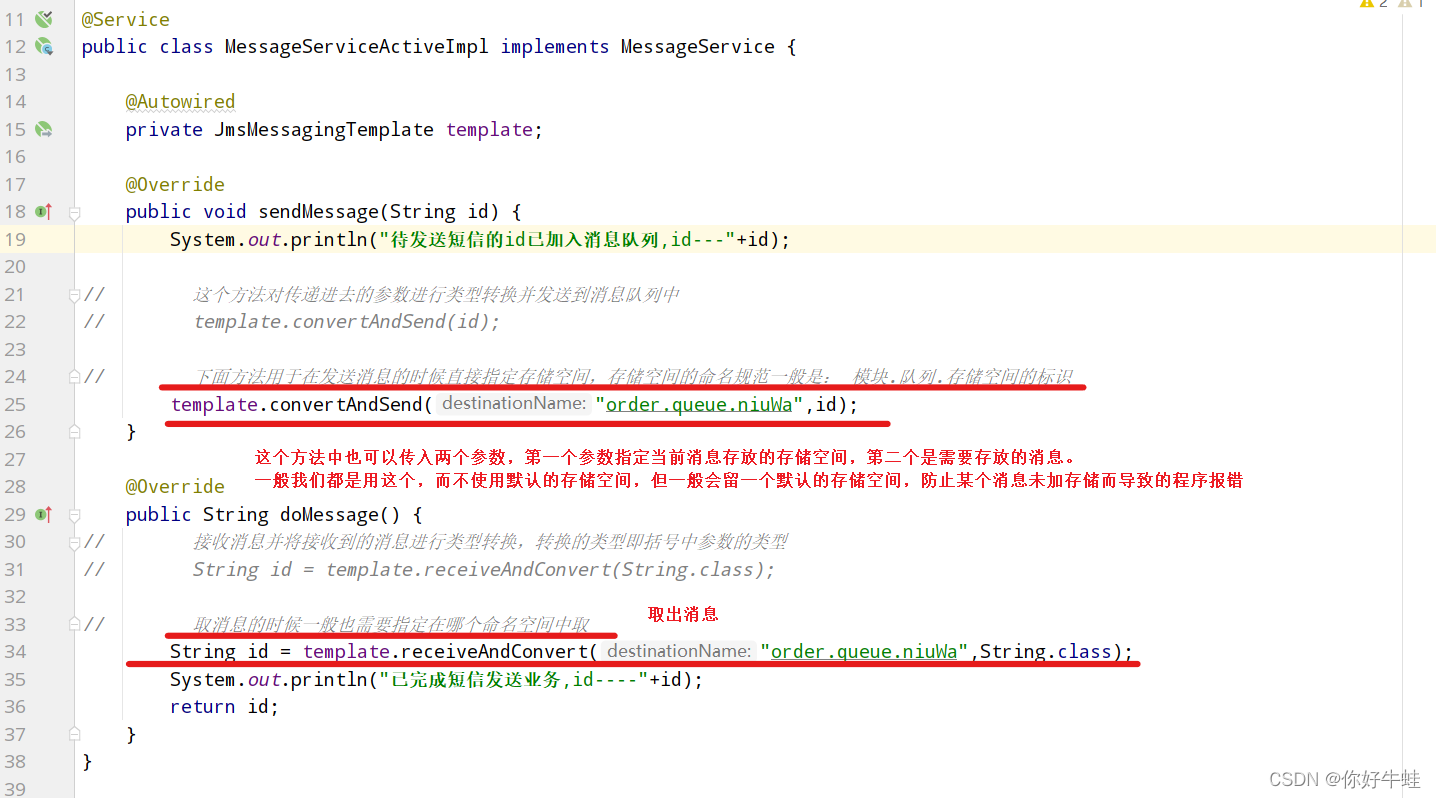
但是,在实际开发中,我们很少搞这种点一下才进行消费消息队列中的消息,我们一般都是消息过来,马上就消费
MQ中提供了一套这样的解决方案,设置一个监听器,来监听消息队列中对应的存储空间
一旦有消息,立即消费,就是说,原存储空间中有的,这里也会一个一个全给消费了
这里还有一个配置,比较重要
JMS规定的消息模型有俩,点对点和发布订阅模型
设置当前所使用的的消息模型,如下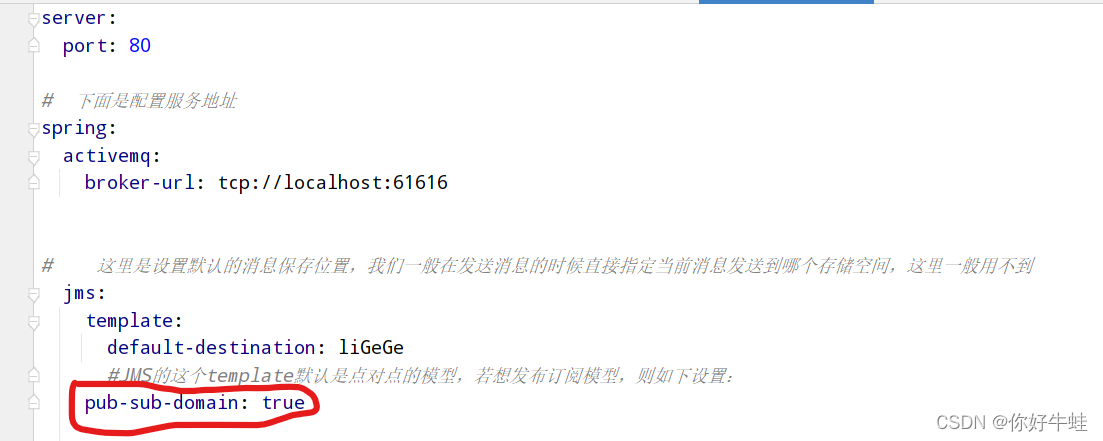
设置成功后,发布的消息会显示在Topics里面,而不会显示在Queues里面了,如下: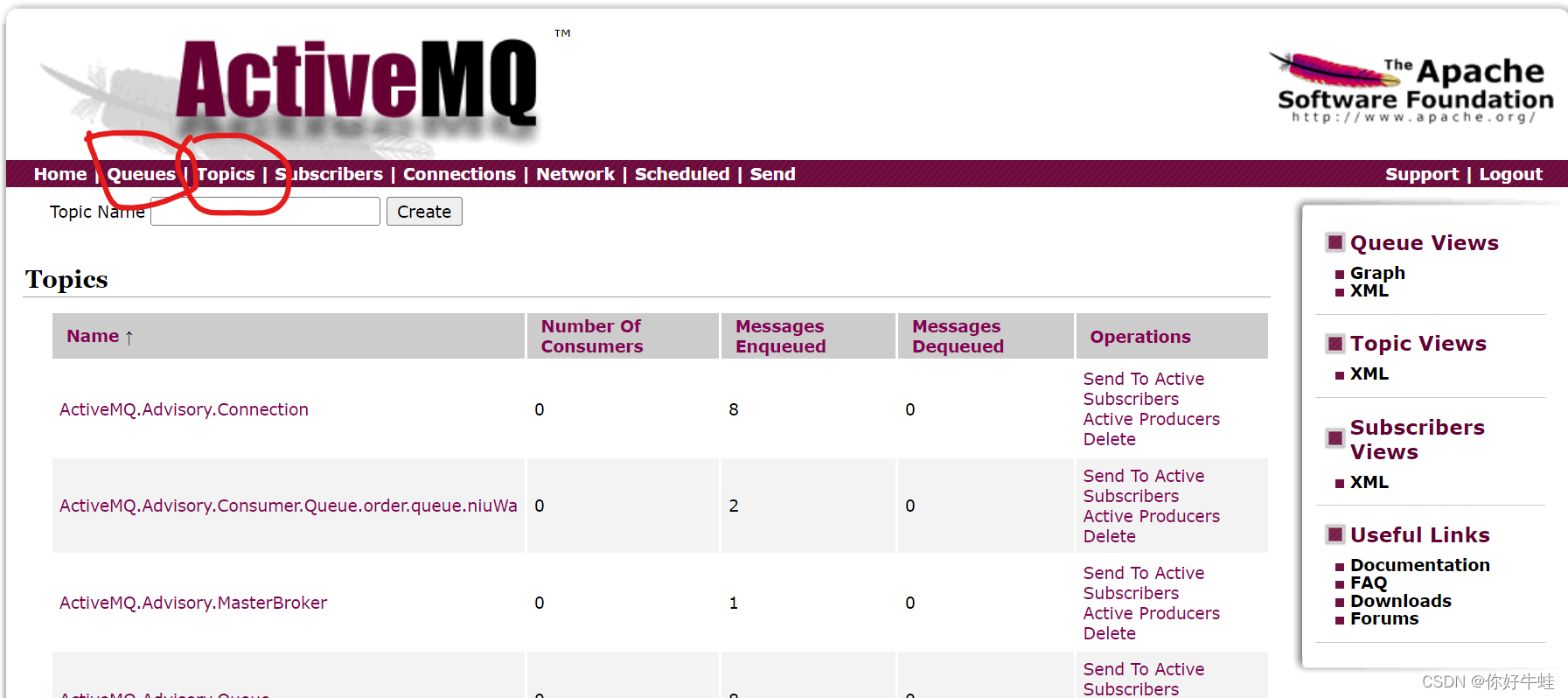
**
后续相关点对点和发布订阅在后面再说
**
更换使用RabbitMQ
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器由以高性能、健壮以及可伸缩性出名的 Erlang 写成。
运行它需要erlang环境,就是说我们需要先安装erlang并配置,然后才能再安装使用RabbitMQ
安装并启动RabbitMQ
安装RabbitMQ需要先安装erlang
安装erlang
我用的是24.3.2
下载地址:
https://www.erlang.org/patches/otp-24.3.2
别乱下载版本,不同版本的RabbitMQ对不同的erlang版本不一定支持
挂魔法进行下载的话会快一点,但是这个文件挺大,挺消耗流量,而且不挂魔法还不一定能下
既然这样,分享一下,我的云链接。这个是安装包形式的,安装只需点击下一步即可,自己选安装路径,需要注意的是目录要没有空格和中文字符
链接:https://pan.baidu.com/s/1sIk308-KooBgwXvjBY_r_w 提取码:13ql
安装完重启一下电脑
然后需要配置环境变量:
大家学Java的,知道咋配吧?
windows+R,输入sysdm.cpl回车,可快速进入系统属性
选择高级,进入环境变量: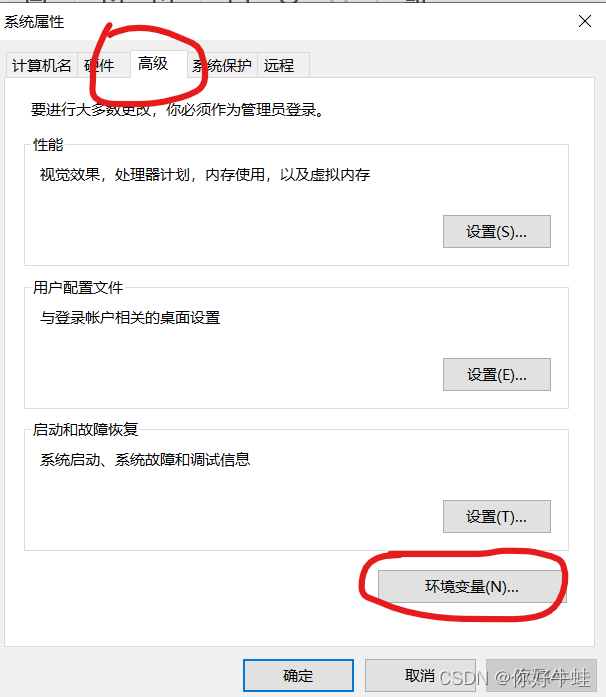
然后根据需要,在系统变量或者用户变量中新建一个:变量名是ERLANG_HOME,变量值指向erlang安装路径,如下: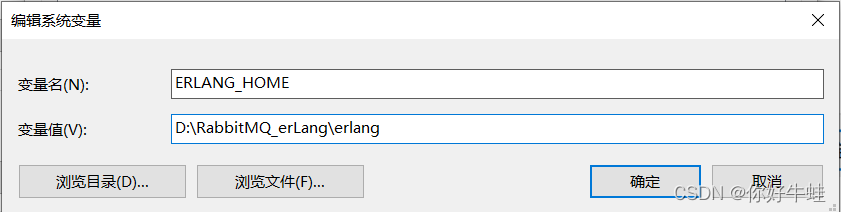
上面的东西放哪,就找到哪里的对应的path,点击编辑,把上面的东西加进去,如下,需要指向bin目录
然后都点击确定,直到退出即可。
有一点需要知道,上面保存之后,在当前cmd窗口中并不会生效,要想生效,重新打开cmd窗口即可
安装过程中可能会出现这个: 不影响,等待安装完成即可
安装并启动RabbitMQ
上面erlang搞好后,就可以安装rabbitMQ了,如果没搞好,RabbitMQ甚至不让你安装
下载路径:
https://www.rabbitmq.com/news.html#2022-03-23T14:00:00+00:00
不挂魔法依然不一定能进去
所以来吧,我的分享一下:
链接:https://pan.baidu.com/s/1i9RWzixpORfVNhVgT08x2A 提取码:pxbk
版本3.9.14,和上面erlang版本兼容
安装就点击下一步就行,主要自己选择安装路径。需要注意的是目录要没有空格和中文字符
RabbitMQ的目录: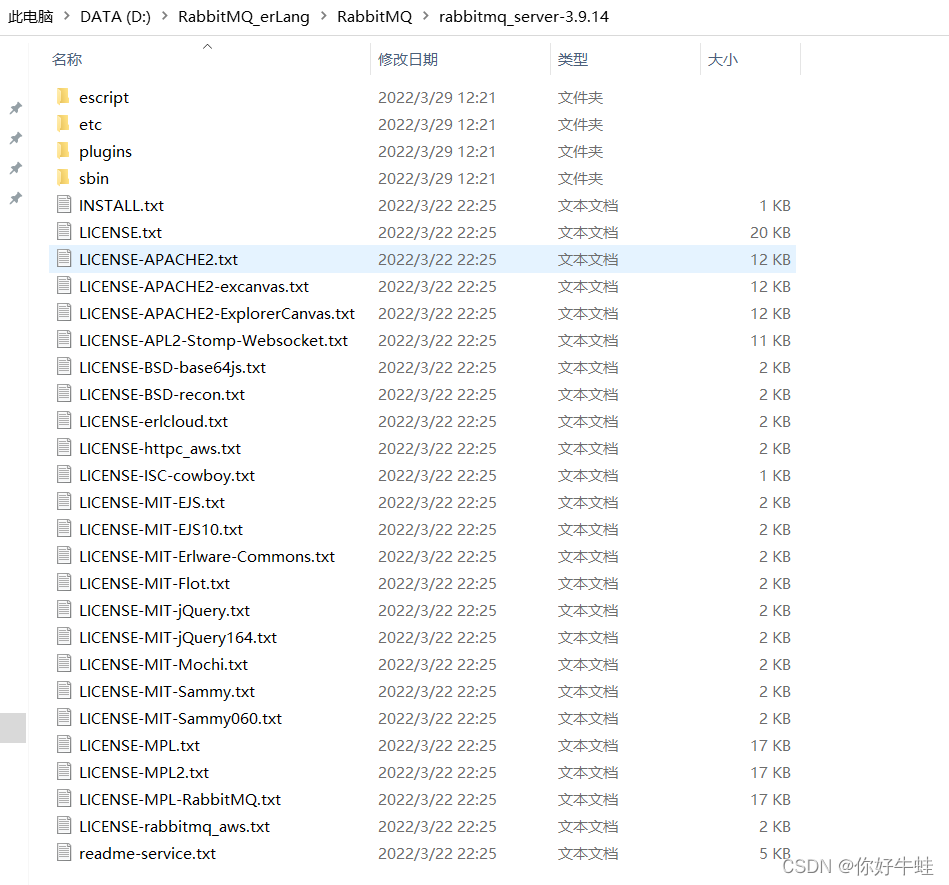
这里他喜欢搞特殊化,把可执行文件放在了sbin下了:
接下来,我们就能启动使用rabbitMQ的服务了
启动服务:
以管理云身份运行cmd,在RabbitMQ安装目录下的sbin目录下执行这个命令:
rabbitmq-service.bat start
刚安装好后,可能会出现下面这种情况下,这是因为RabbtMQ服务已经启动了,RabbitMQ刚安装好后,会默认启动RabbitMQ服务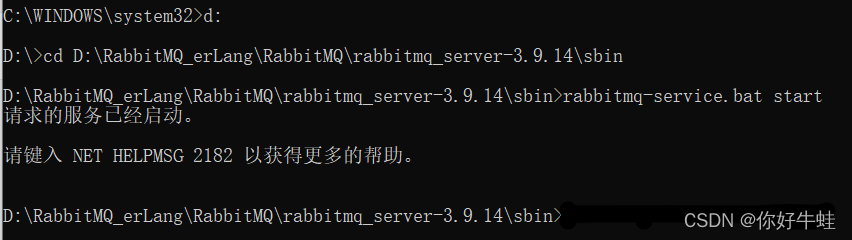
停止这个服务的命令:
rabbitmq-service.bat stop
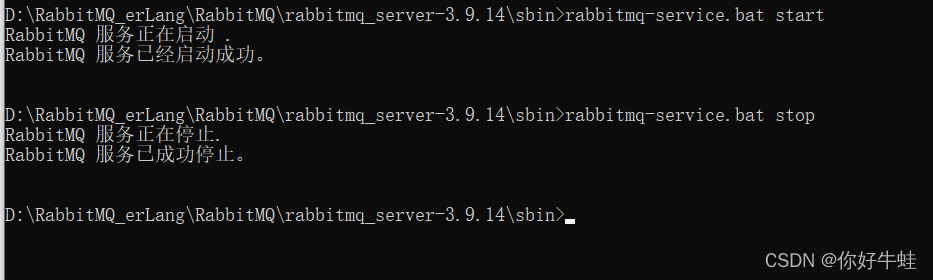
再启动:
跟ActiveMQ一样,RabbitMQ也有一个web端的控制台,但是需要我们手动开启这个插件
需要用到sbin目录下的
rabbitmq-plugins.bat
可执行程序
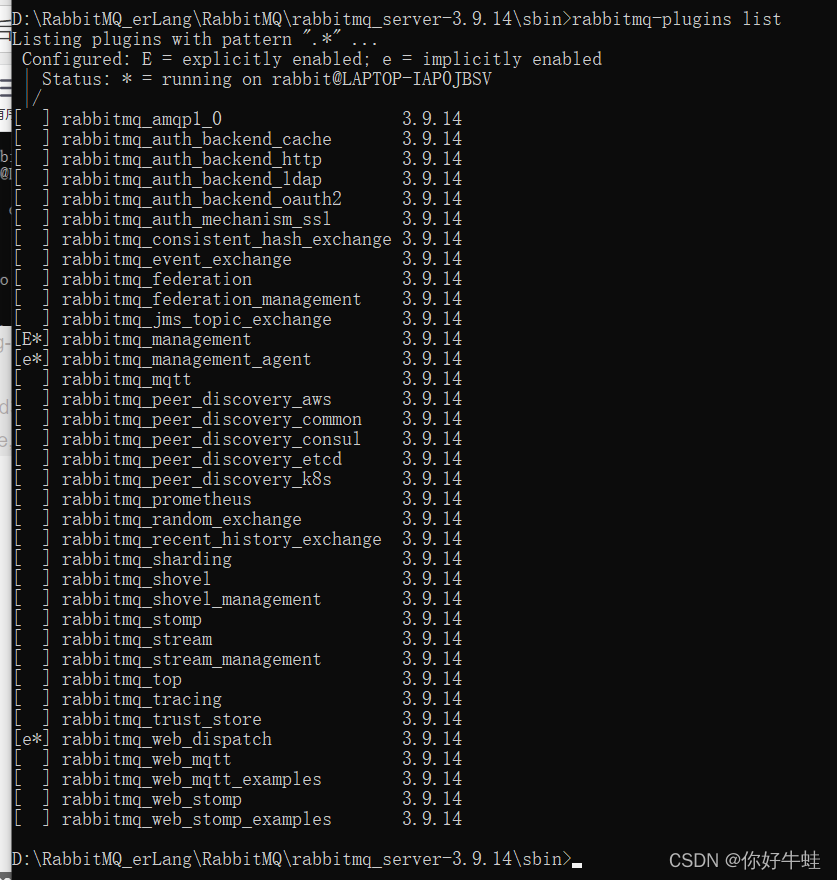
首先,以管理员身份进入cmd,再进入RabbitMQ下的sbin目录,通过这个命令可以查看他携带了哪些插件:
rabbitmq-plugins.bat list
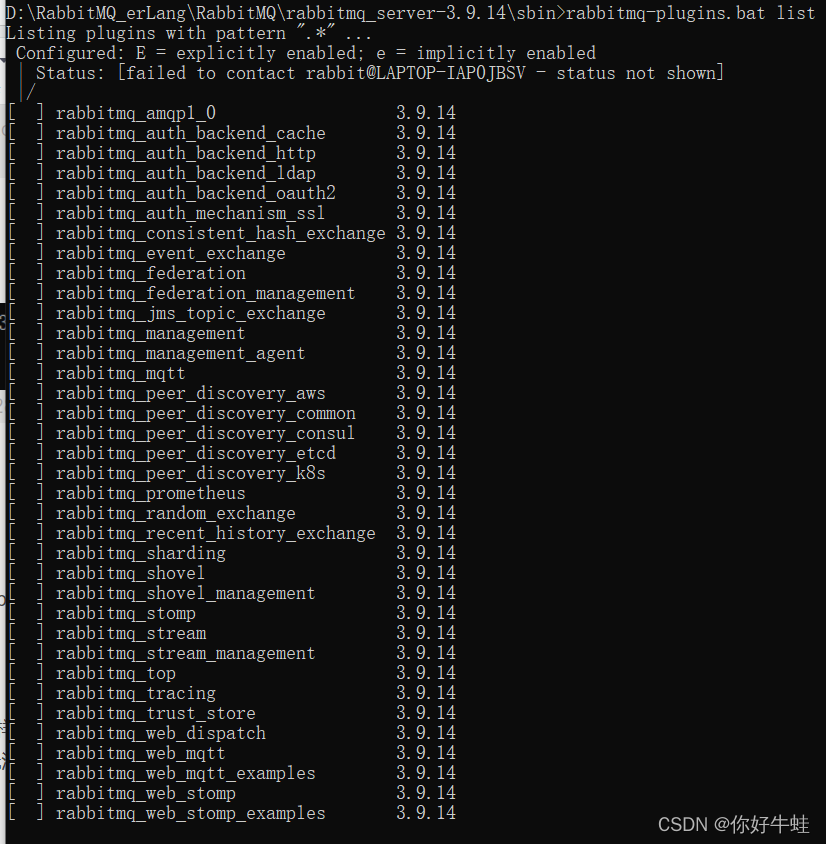
执行这个命令可以开启web端的控制台的插件:注意一件事情,应该在服务运行的情况下执行下面的命令
rabbitmq-plugins.bat enable rabbitmq_management
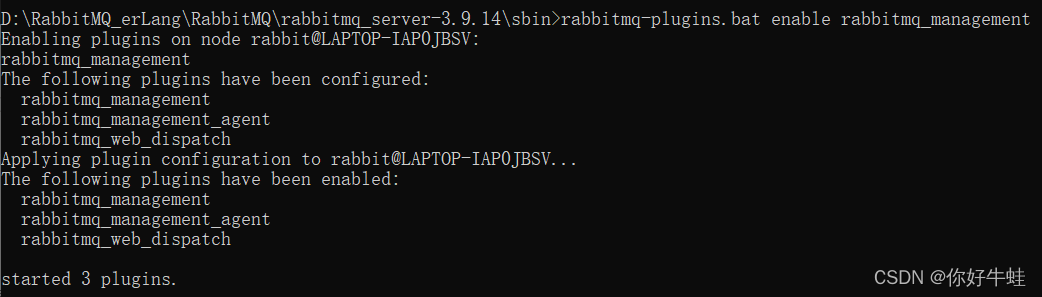
然后再查看:开启这个功能之后,会附带开启这三个插件,即带[e/E*]的,如果不带
*
,则应该是在rabbitMQ服务停止的情况下开启的这个web端控制台插件,此时还无法访问web端控制台,这样的情况只需开启RabbitMQ服务,在这种情况下,再次执行上面开启插件的命令即可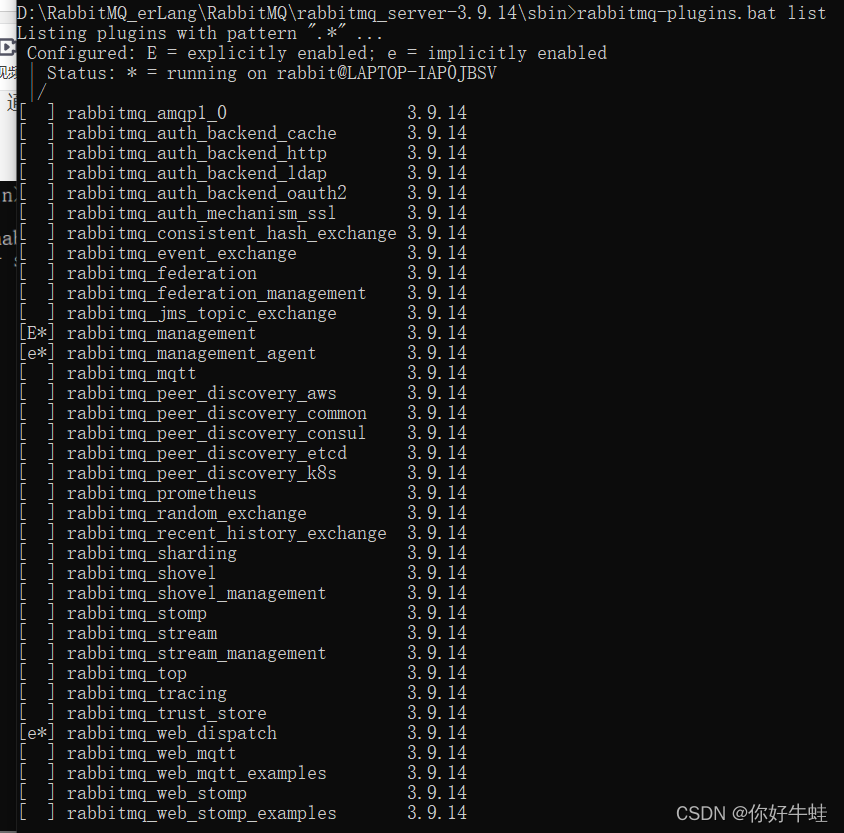
这样就可以访问web端的控制台了
地址:
http://localhost:15672
,进入要账号密码,初始都是guest,然后进入就是这弔样: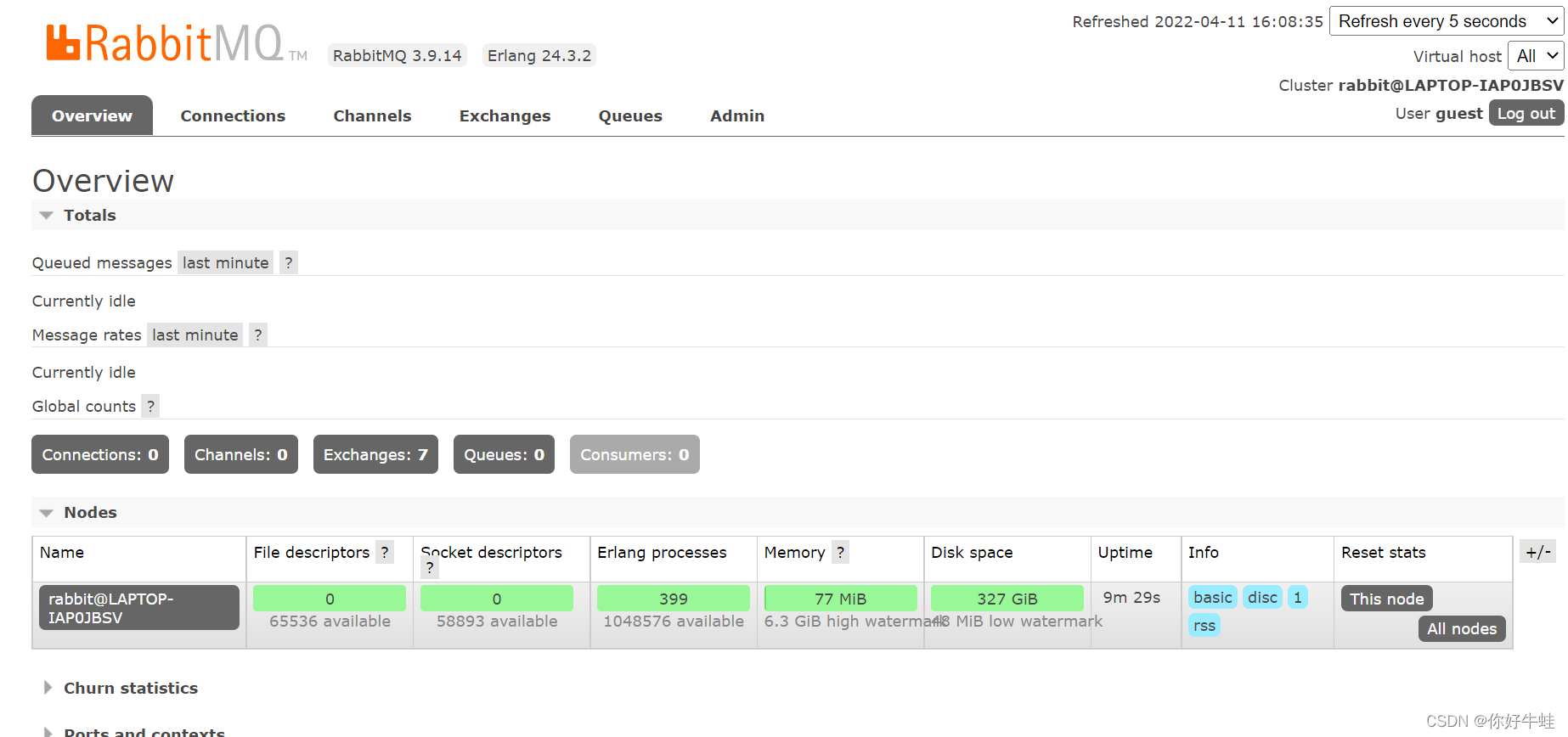
但是!!!这里面蕴含着一个BUG。这个BUG影响的地方很多,但是我们第一次意识到他的存在应该是在开启web端控制台的时候
下面说一说,顺便说一说解决方法:
解决RabbitMQ的一个BUG(重要,可能很多人都遇见过这样的问题)
是否会遇到这个BUG跟自己当前电脑的用户名有关,如果包含中文,或者包含空格,就会遇到这个BUG
在RabbitMQ服务运行的情况下,当在开启web端控制台的步骤那里,执行开启的命令,可能会报下面的错,无法开启。而且,这个BUG会影响到sbin下的某些可执行命令,某些命令出错可能也是因为这个问题。(当时研究这个问题研究了好几天,woc,头都快裂开,后来终于找到问题所在和解决方法)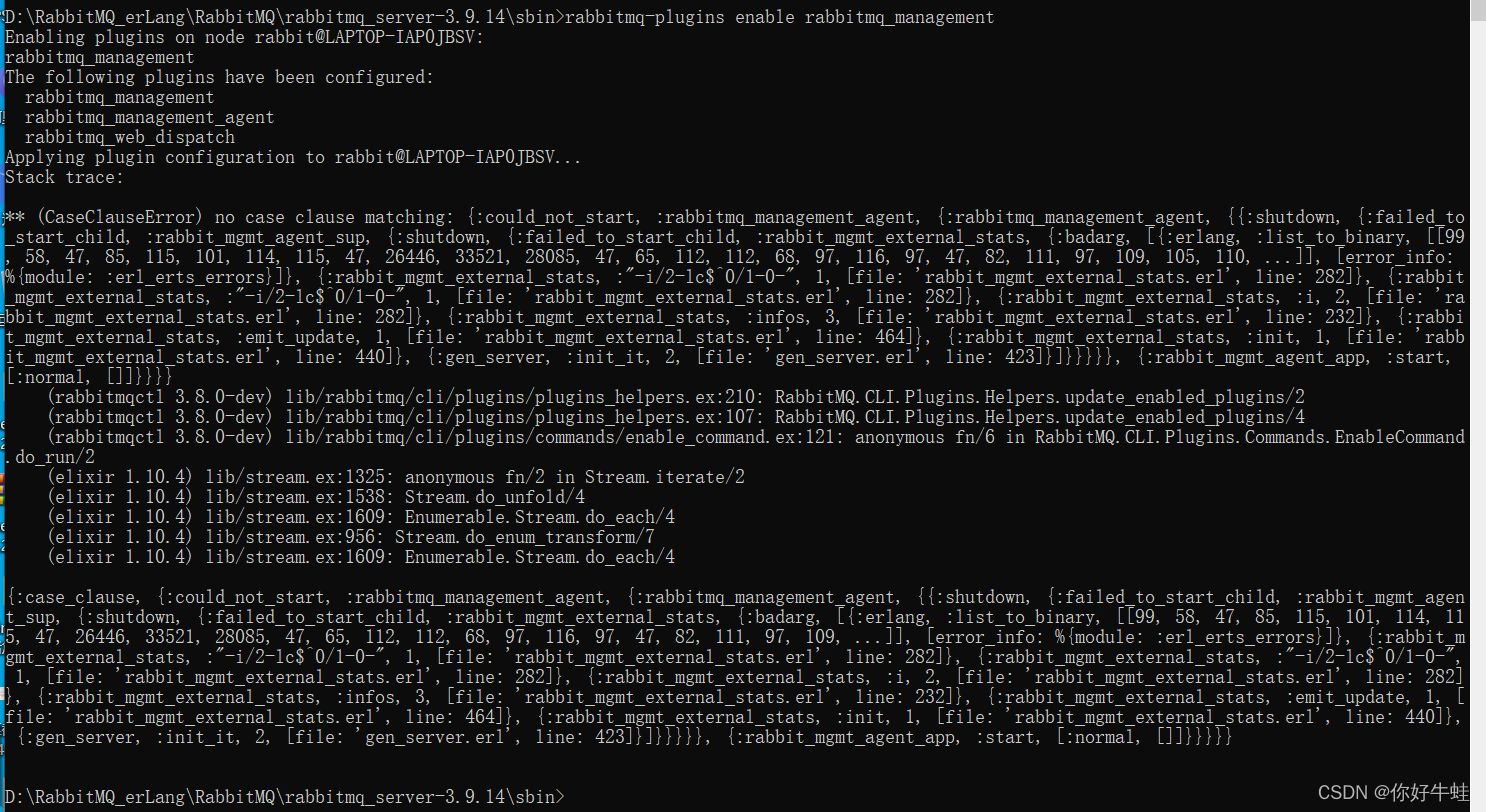
注:如果在没有开启RabbitMQ服务情况下开启这个插件不会报错,但是也无法真正的开启,web端依旧无法访问到
为什么会出现这个BUG?
我们进入
C:\Users\当前用户名所命名的文件夹\AppData\Roaming
这里,可以找到一个这个文件夹:
RabbitMQ默认将日志和数据存储在这个里面,如果这个路径带有中文或空格,则就会导致RabbitMQ读取相关信息出错
解决方法:
第一种,该用户名呗,这种好像最简单,但是我觉得这个蕴含着一些未知的问题,而且我也不想改,咋办?
方法二:
修改RabbitMQ的默认日志和数据存储路径。
步骤如下:
- 先创建一个文件夹,用于存放RabbitMQ的默认日志和数据,路径不能带有中文或空格,建议放在rabbitMQ相关联的地方,这样好找,文件夹名字随意,建议叫data。我放在和rabbitMQ安装路径的同级目录下了:
- 然后:(下面关于在cmd下运行的,cmd都要以管理员身份运行) cmd进入RabbitMQ的sbin目录下: 先这个命令,移除当前的rabbitMQ的服务
rabbitmq-service.bat remove然后设置RabbitMQ的默认日志和数据存储路径。 命令:set RABBITMQ_BASE=D:\RabbitMQ_erLang\RabbitMQ\data(自己创建的文件夹路径,此处是我的data文件夹路径,这个是我设置的新的rabbitmq存放日志和数据的文件夹)然后再次重新安装RabbitMQ服务 命令:rabbitmq-service.bat install如下:
至此,问题解决,此时,我们再启动服务,再开启对应的插件,就不会出问题了: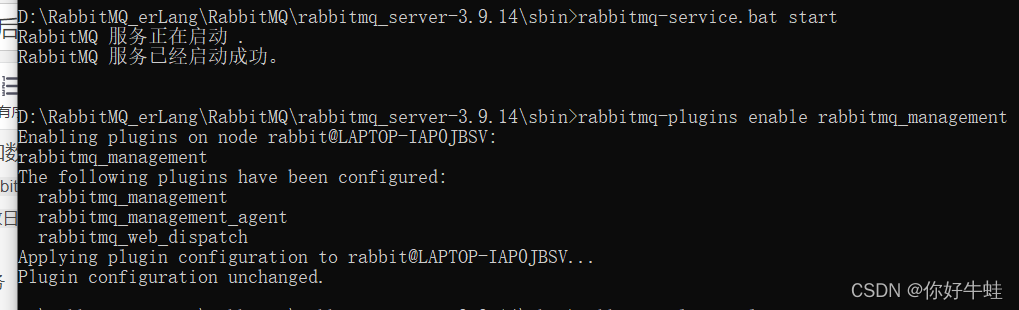
原来RabbitMQ默认的存储日志和数据的文件夹已经没作用了,不想要可以删了
更换使用RabbitMQ
JMS中有两个经典的数据模型:点对点和发布订阅模型
AMQP有五个:标注出来的这俩分别与点对点和发布订阅模型非常相似,比较常用
direct exchange:直连交换机
topic exchange:主题交换机
使用方法
三步
1.导入依赖
导入的是springboot整合的amqp的包,里面包含了rabbit的依赖包
2.配置
3.使用
先开启rabbitMQ的服务
然后再使用
这里我们跳过通过手动点击实现消费消息的业务,只通过监听器来进行消费
首先还是前面那个业务,这里只是换一种消息队列实现方式
这里使用两个常用的消息模型作为展示
记一下这两个模型:
**
这里只是以整合为主,详细的RabbitMQ知识无法兼顾到,可以另外学习
**
direct exchange消息模型
直连交换机
amqp中,通过AmqpTemplate来操作消息队列
通过template.convertAndSend()方法可以向对应的消息队列中传递消息
如下:
template.convertAndSend()方法需要三个参数
第一个代表交换机Bean的字符串,第二个,代表Binding(绑定键)的Bean的字符串,第三个,所需要传入的消息本身
其中,Binding是由交换机和存储消息队列的Bean绑定而成,这些需要从第三方那里获取。按照开发规范,从第三方获取的Bean应该在配置类中获取,所以下面搞一个配置类:
将交换机和Binding(绑定键)传入template.convertAndSend()方法,再传入发送的消息,即可发送到对应的存储空间中
下面是监听消息队列的监听器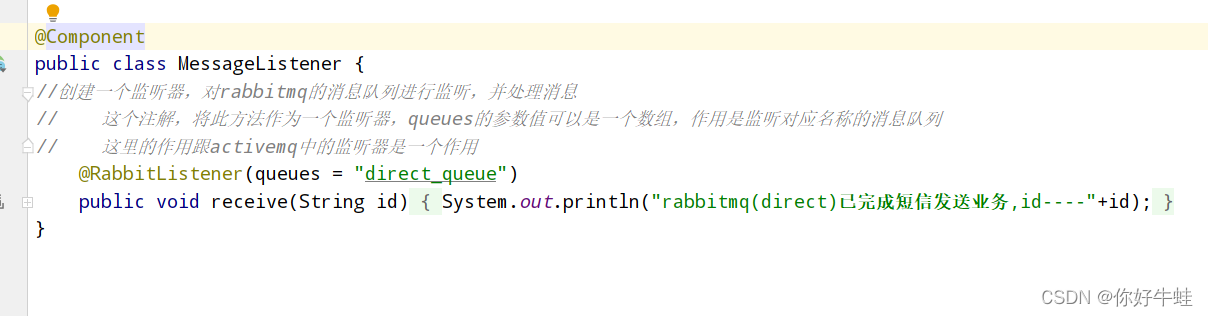
结果: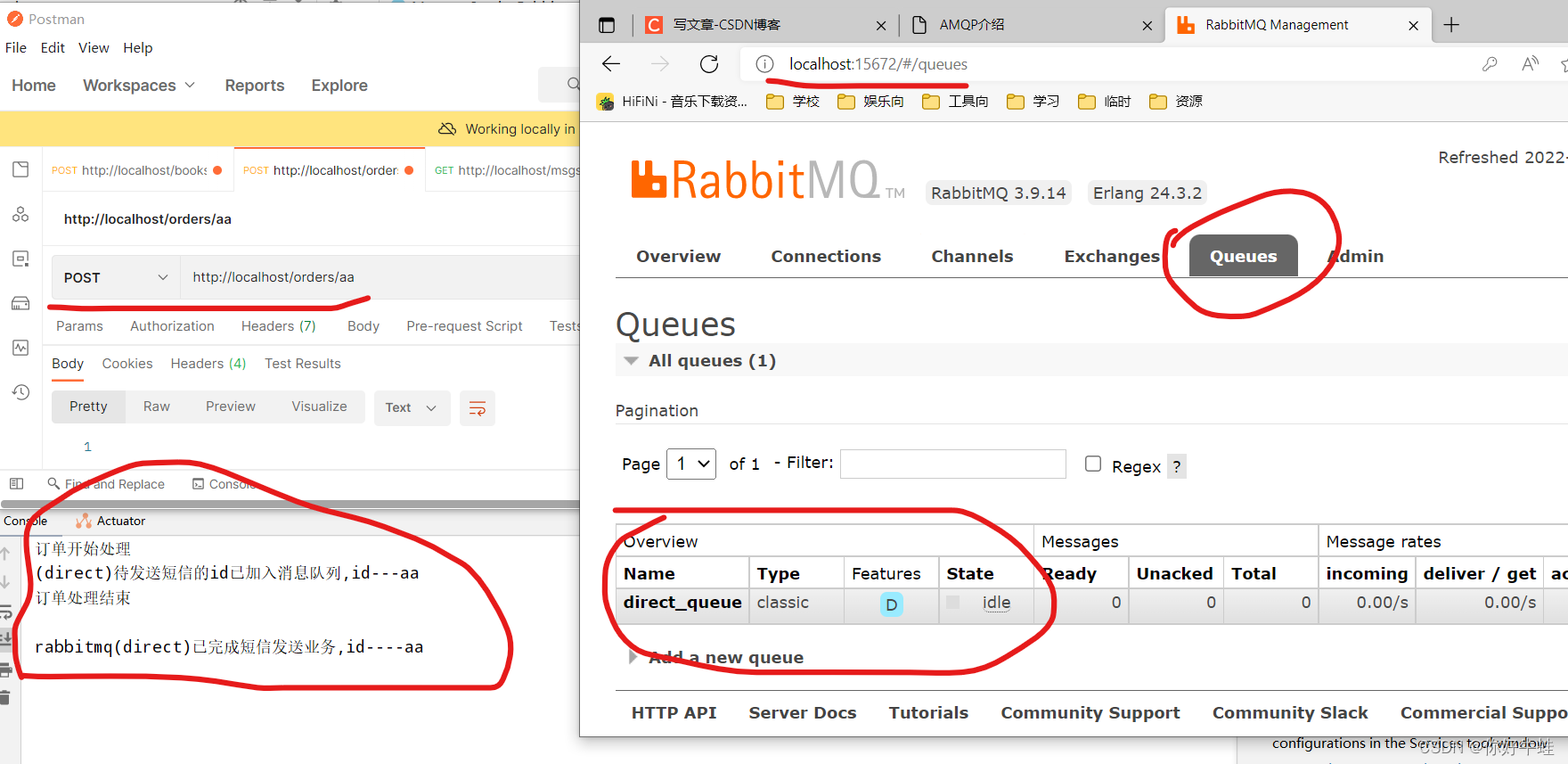
topic exchange消息模型
主题交换机
与直连交换机代码上没有多少区别,但是工作模式差别很大
用主题交换机可以制造出来直连交换机的效果
直连模式使用的交换机是directExchange类型的,他的模式像是JMS中的点对点
主题交换机使用的是topicExchange类型的,他的模式像是JMS中的发布订阅
amqp中,不同消息模型靠不同形式的交换机来设置和区分
topicExchange类型的有这样的特点:
topic类型的交换机增加了".“和”#"的匹配,比Direct类型灵活。
.
表示匹配任意一个单词,
#
表示匹配任意个数的任意单词
这俩字符匹配机制作用:绑定键可以更灵活的接收多个不同的消息,或者多个绑定键可以同时接收一个消息的发送
比如绑定键设置这样的名称:
order.*.id
: 则可以通过
order.任意单词.id
来向这个绑定键发送消息
order.#
: 则可以通过
order.任意单词.任意单词....
来向这个绑定键发送消息
代码没多多少区别:下面是配置类:
定义两个消息队列的对象和一个主题交换机,将消息队列对象和这种类型的交换机进行绑定就能实现
topic exchange
消息模型
然后将这俩消息队列的bean和同一个主题交换机绑定起来,形成两个绑定键,设置对应的匹配规则(标识符)是
order.*.id
和
order.#
。然后我们在发送消息的时候,就能根据这些匹配规则向对应的消息队列中发送消息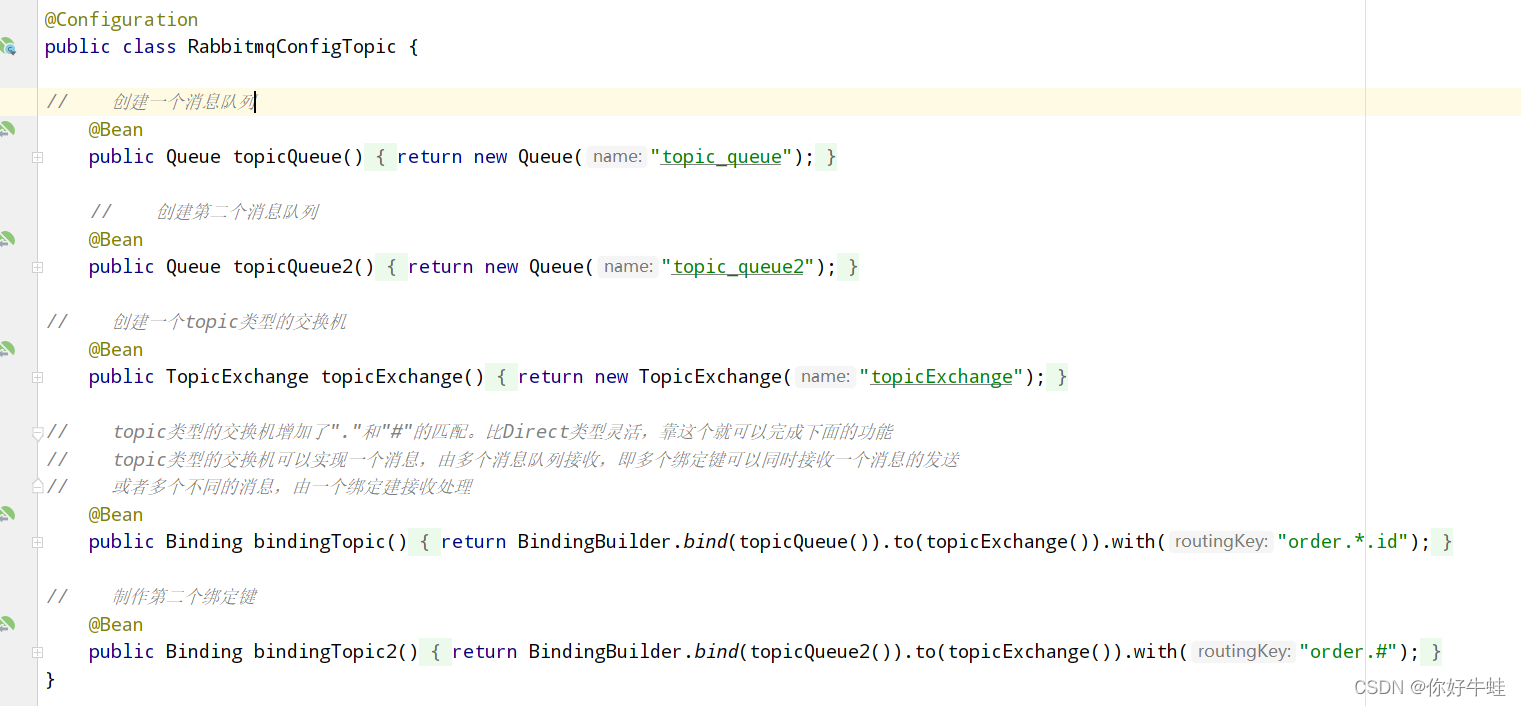
下面是发送:按照匹配机制,这里能把这个消息同时发送给两个消息队列。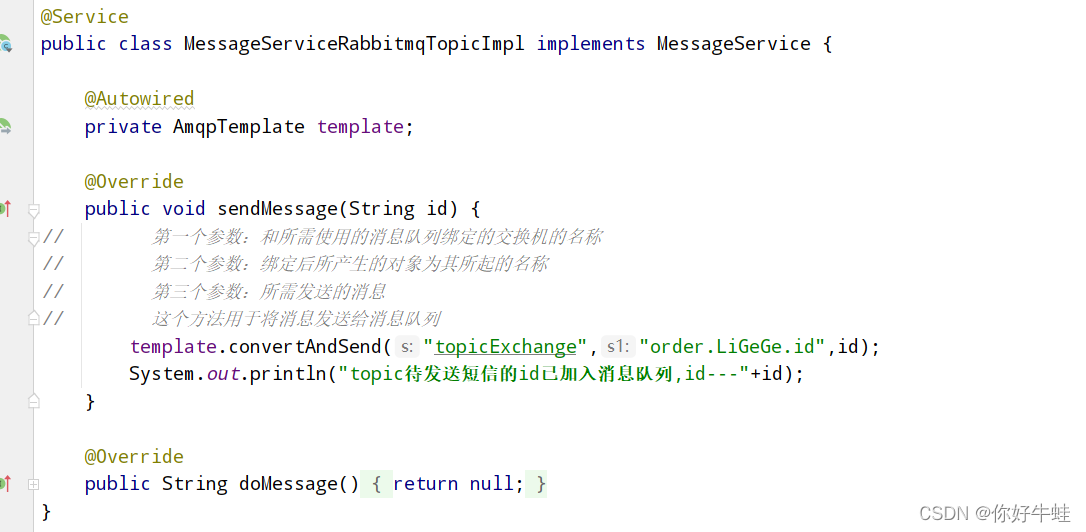
这里我们是直接使用监听器来对消息队列中的消息进行消费,如下,两个监听器,分别监听消息队列
topic_queue
和消息队列
topic_queue2
,这两个消息队列即对应着两个绑定键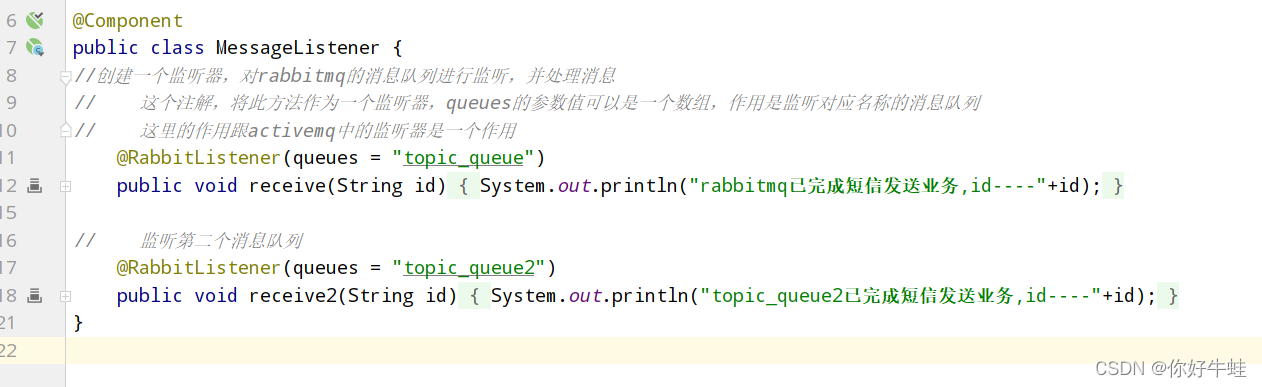
然后通过postman测试: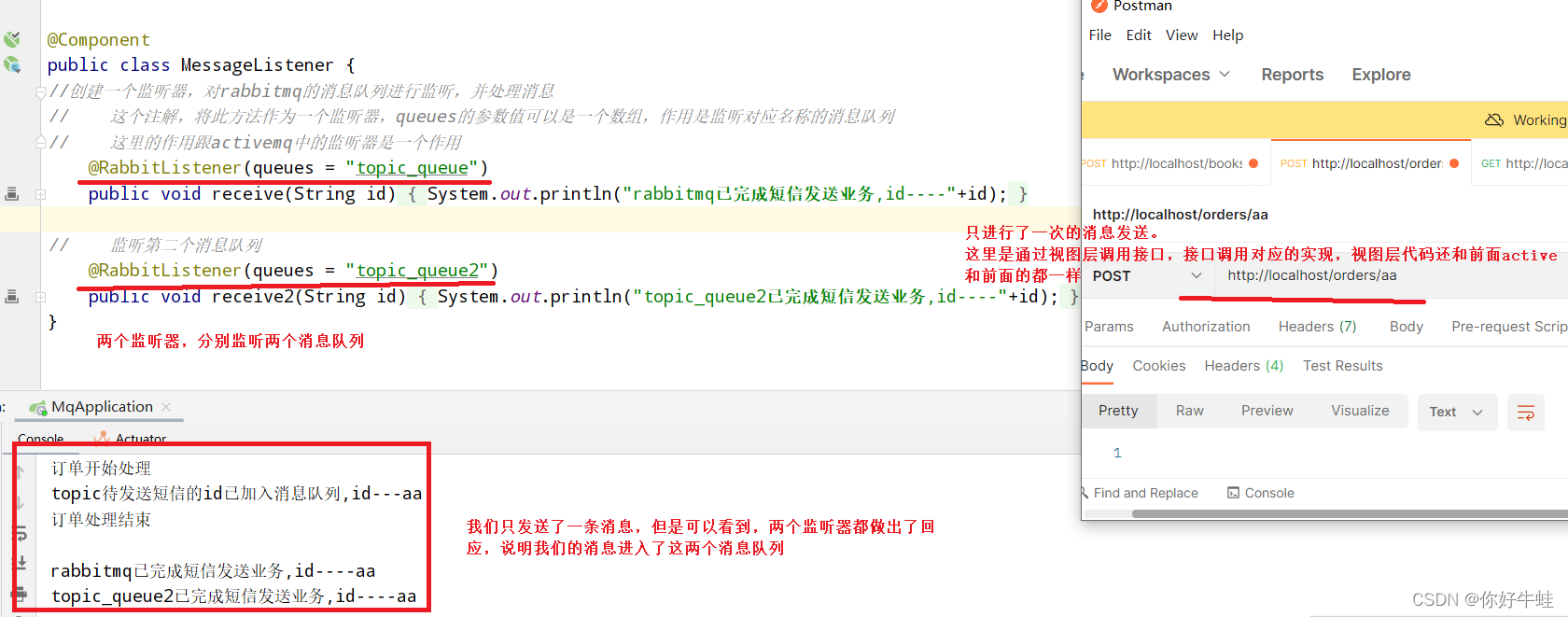
所以还是说:
直连模式使用的交换机是directExchange类型的,他的模式像是JMS中的点对点
主题交换机使用的是topicExchange类型的,他的模式像是JMS中的发布订阅
topicExchange类型的有这样的特点:
topic类型的交换机增加了".“和”#"的匹配,比Direct类型灵活。
.
表示匹配任意一个单词,
#
表示匹配任意个数的任意单词
这俩字符匹配机制作用:绑定键可以更灵活的接收多个不同的消息,或者多个绑定键可以同时接收一个消息的发送
topicExchange交换机可以很轻松的实现directExchange交换机的功能,只要不使用
.
和
#
匹配符即可
尾章
**
这里还是要说,涉及到的技术并没有做很详细的讲解,以整合为主,但是足够会基本使用和了解了。某个单一的技术更详细的知识还是要找具体的课程学习
**
和上一篇 前一段时间学习的springboot+vue的一个小案例,还有中间的几篇笔记,加在一起,关于springboot的东西差不多都有了。
但是还有一点点的东西没做笔记,等之后再记录,先去转战
redis
和项目去了
版权归原作者 你好牛蛙 所有, 如有侵权,请联系我们删除。