
ECSSD: Hardware/Data Layout Co-Designed In-Storage-Computing Architecture for Extreme Classification
Li, Siqi, Fengbin Tu, Liu Liu, Jilan Lin, Zheng Wang, Yangwook Kang, Yufei Ding, and Yuan Xie
UCSB, HKUST, RPI, Samsung, Alibaba
https://dl.acm.org/doi/abs/10.1145/3579371.3589093
引言
人工智能领域,分类任务至关重要。分类任务是实现智能化、自动化和个性化的关键步骤,广泛应用于各个领域,提供处理和理解复杂数据的工具和方法。例如,通过学习数据中的模式实现相似模式的识别,在医学诊断中为决策提供信息支持,在推荐系统中理解用户兴趣以提供个性化体验,以及用于检测网络安全威胁和欺诈。
分类层是深度神经网络中做出预测决定的最后一步计算。随着数据量和分类规模的增长,分类任务的执行在整个预测算法的时间开销中约占30%至60%。而且,极限分类任务的参数规模已经高达几百上千GB,超过了CPU或GPU的内存容量。在常规的计算机体系结构下,这些参数需要存储在外部存储设备,计算时再传输到CPU或GPU内存,带来严重的数据搬移瓶颈,降低整个系统性能。
在这一背景下,ISCA 2023的ECSSD提出利用可计算存储架构来解决极限分类任务的性能瓶颈,通过硬件加速器电路与数据布局的深度协同设计,为极限分类提供前所未有的高速、高能效解决方案。ECSSD的出现将推动存储计算技术演进,为科研领域注入新的活力,促进存储与计算的深度融合。
本文将从如下方面解读ECSSD:
- 背景介绍。介绍可计算存储、近内存处理、极限分类的概念。
- 论文解读。****1) 研究动机。概述现有工作存在的关键问题以及作者做这项研究的目标。2) 设计思路和关键技术。总结ECSSD的两个主要设计目标;简要阐述ECSSD的设计和实现。3)****** 评估分析**。展示ECSSD的端到端性能以及和其他架构方案的对比。
- 论文评述。我们对本文进行原创性评述,分析论文呈现方面的亮点和设计上的不足。从新意上看,该论文中规中矩,但它的问题定位清楚,评估测试扎实,写作上处处深思熟虑,值得借鉴学习。
**1. **背景介绍
1.1 可计算存储与近内存处理****
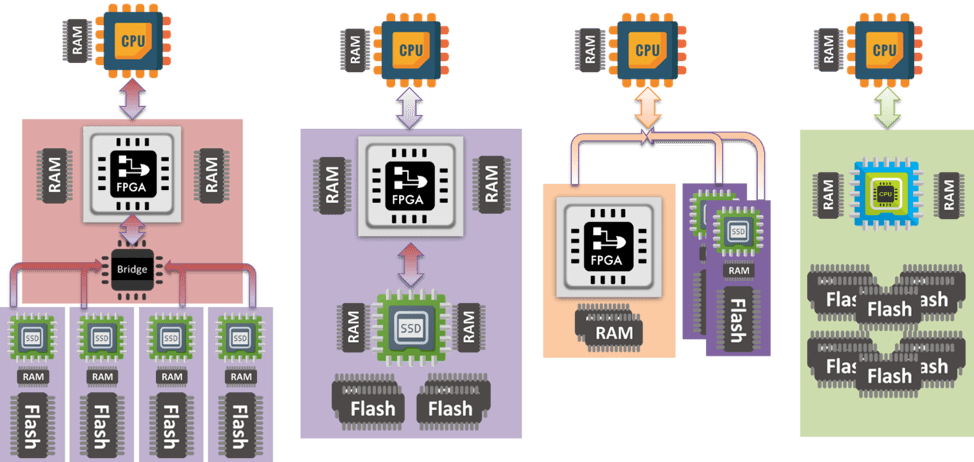
图1:多种可计算存储架构 (source:SNIA) [1]
可计算存储 (Computtaional Storage) 和近内存处理 (Near-Memory Processing) 代表着近数据处理(Near Data Processing)计算机体系结构的两项创新技术。如图1所示,近数据处理是一种整合了计算能力的内存/存储架构,旨在将计算任务下推到数据附近执行,而不是将数据从存储设备搬到CPU。这一架构极大减少了传统存储和计算模块之间的数据传输,提高了系统性能和效率,为大规模数据处理和分析提供了新的可能性。计算和存储融合是一大技术趋势。
1.2 极限分类** (Extreme Classification)**
机器智能领域的新趋势,例如自然语言处理、图像识别和推荐系统,都涉及处理带有大量标签的极限分类问题。这个研究领域的兴起是为了处理诸如人脸识别、零售产品识别以及图像和视频标注等多类别和多标签问题。相较于传统的排名和推荐技术,极限分类在机器学习和计算机视觉应用中的显著进步,主要归功于建立标签间结构关系、开发亚线性时间算法和创造适应性损失函数等创新措施。这些无偏的损失函数在预测稀有标签时提供了额外的奖励,使得极限分类技术在全球范围内的热门产品中得到了广泛应用。极限分类的应用实例包括网页标签系统、电商平台推荐系统、社交媒体图像和视频标签系统、自然语言处理任务和医疗诊断模型等。
2. ECSSD** 论文解读**
**2.1 **研究动机
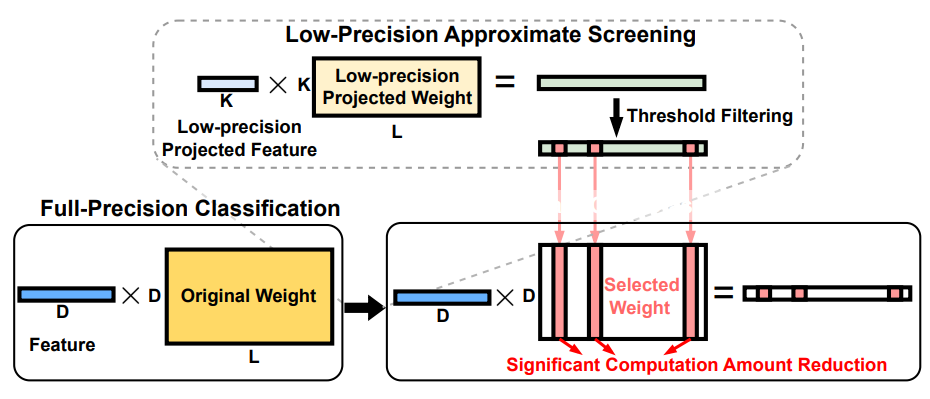
图2:极限分类的近似筛选算法
现有工作存在的关键问题:无法满足的大内存需求会导致极限分类系统产生性能瓶颈。尽管近内存处理(NMP)技术有解决内存限制的潜力,但其逻辑计算能力的有限性阻碍了其在极限分类问题的应用。ENMC方案 [2] 提出了一种有效的近似方法,只计算对模型预测有用的分类,以解决NMP在处理极限分类时的内存限制问题。通过引入图2所示近似筛选算法,该方案平衡了分类精度和计算效率,过滤并执行候选分类,大大提高了处理速度。然而,最先进的近内存计算方案也难以满足极限分类的需求,主要存在两个问题:
- 内存容量瓶颈日渐突出,难以满足飞速增长的分类任务规模。
- 能耗和硬件成本高昂。
有希望的新方案:可计算存储的兴起为处理极限分类问题提供了新的硬件机会:高性能海量存储空间 + 盘内近数据处理架构
**2.2 **设计思路和关键技术
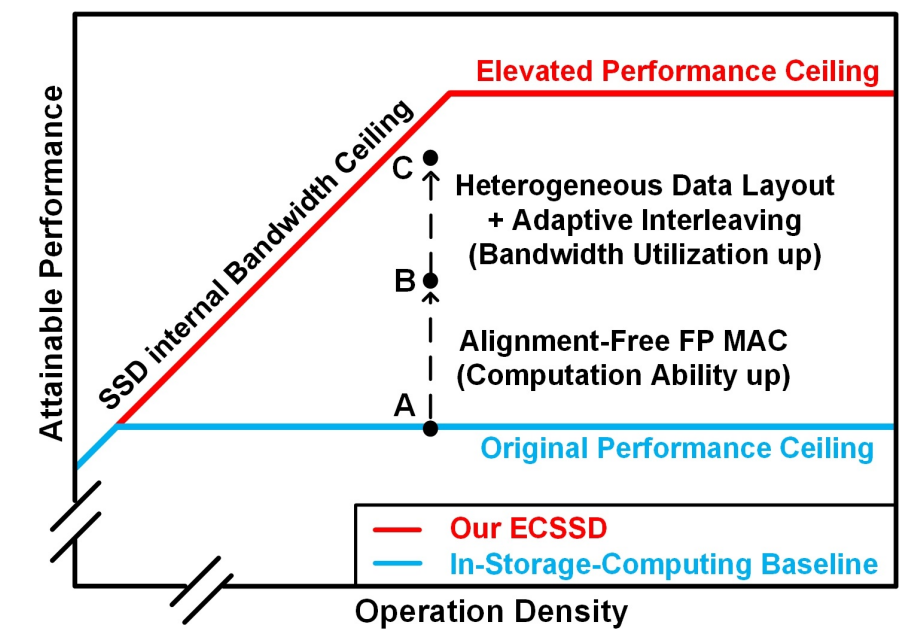
图3:ECSSD设计 vs. 存储内计算基线设计
由于SSD 中可添加的计算能力受到增加逻辑电路面积(Area Size)预算的限制,为了达到高效的盘内极限分类,ECSSD需要解决两个问题:1)如何提高有限区域的计算能力;2)如何充分利用SSD内部的DRAM和闪存带宽。
首先,ECSSD对目标问题做了一个合理约束,即在SSD内增加硬件加速器应当满足一定的芯片面积限制****,具体为不超过SSD主控中嵌入式处理器的面积。理由是:第一,具备通用性,无论哪种SSD设计、产品、及工艺,SSD内都包含主控芯片,适合作为参照物;第二,SSD嵌入式处理器由于需要处理多种复杂任务因此具有较复杂的逻辑电路,而加速器通常是为单类应用设计,其面积不应超过嵌入式处理器面积。图3展示了ECSSD设计和可计算存储基线设计之间的区别。
通过架构与电路设计提高单位电路面积的算力:在架构与电路设计方面,ECSSD在数据缓冲区附近定制了加速器,负责低精度筛选和候选过滤。ECSSD的设计特点包括免对齐的浮点MAC电路和异构数据布局。
优化浮点MAC电路。SSD中额外逻辑电路的面积预算有限,因此优化浮点MAC(乘法累加)电路对于提高性能至关重要。原始的浮点MAC电路包含大量开销的对齐相关组件。因此,ECSSD提出了一种免对齐方法,实现向量级别的对齐,并消除了对齐相关组件的需求。预对齐操作在主机中实施,主机功能更强大,能够高效处理这个操作。ECSSD引入了一种补偿浮点数据格式(CFP32),以确保计算精度,且无需额外的存储或传输负担。免对齐的浮点MAC电路提高了计算能力,并匹配了SSD的高内部带宽,从而克服了计算受限的问题。
整数和浮点权重向量分开存储。32位浮点权重向量的传输工作负载远大于4位整数权重向量。在NAND闪存通道中均匀存储这两种类型的权重数据会导致数据传输干扰。异构数据布局设计将4位整数权重向量存储在DRAM中,而将32位浮点权重向量存储在NAND闪存通道中。这种设计消除了数据传输干扰,同时利用了通道级带宽和额外的DRAM带宽。ECSSD可以工作在两种模式下:SSD模式,类似于传统的SSD产品;和加速器模式,其中插入的加速器加速极限分类应用。
通过智能的数据布局实现SSD闪存通道的负载均衡:基于学习的自适应交错框架,揭示了顺序存储和均匀交错方法的局限性,并引入了基于学习的自适应交错框架来解决数据访问不平衡的问题。
顺序存储无法实现闪存通道负载均衡。由于矩阵运算是 tile-by-tile的,顺序存储权重矩阵会导致一个tile存在一个闪存通道,权重矩阵的读写都无法充分浪费通道带宽资源。
均匀交错也无法实现闪存通道负载均衡。****考虑以均匀(uniform)方式将32位权重向量交错到闪存通道中。然而,由于候选过滤流程,均匀交错下的通道负载仍不均衡,这限制了SSD聚合带宽利用率。假设SSD有8个通道,可以将No.1 ∼ No.8 权重向量交织到No.1 ∼ No.8闪存通道中,然后将No.9 ∼ No.16 32位权重向量交织到No.1 ∼ No.8中闪存通道等。与顺序存储相比,现在8个闪存通道可以并行工作进行数据访问,并且提高了总通道级带宽利用率。然而,由于候选过滤的结果是离散的,统一交织方法下的闪存通道访问模式并不平衡。在大多数情况下,某些通道比其他通道包含更多的候选权重向量,导致通道负载仍然不均衡。
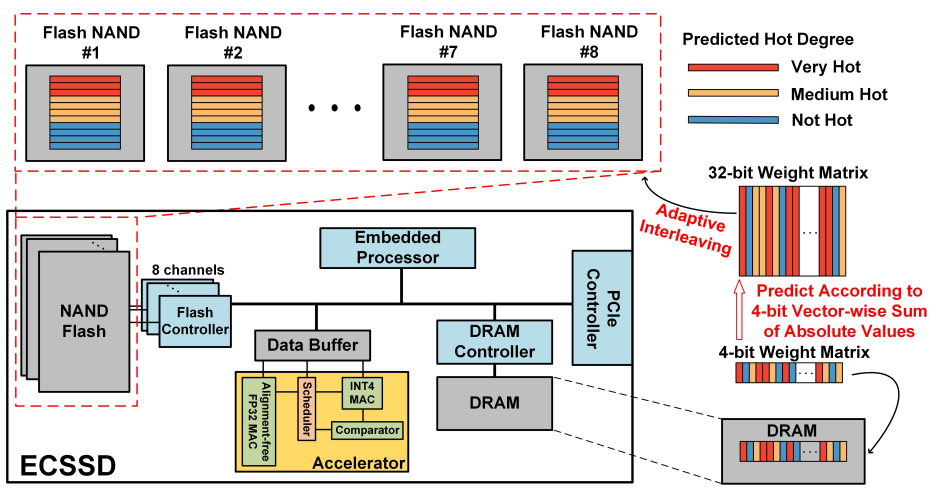
图4:自适应的Tile交错布局
基于学习的自适应交错。如图4所示,ECSSD提出了基于学习的自适应交织框架,利用投影的 4 位权重向量的信息来预测相应的 32 位权重向量的热度,通过权重向量的热度来均衡ECSSD中每个闪存通道的数据访问工作负载。每个闪存通道的工作负载通过根据其微调的热度将所有权重向量交错到8个闪存通道中而使得近乎相同。通过这样做,可以均衡闪存通道的负载,显著减少总的数据访问延时。
2.3** ECSSD**** 评估结果**
本文对所提出的架构的评估十分全面,包括与最先进的基准架构包括GenStore和SmartSSD的性能比较。评估结果显示性能显着提升,与基准架构相比,所提出的架构实现了 3.24-49.87 倍的性能提升。该论文还提供了基于学习的自适应交织方法的详细评估结果,显示出与其他存储策略相比更平衡的数据访问模式和改进的性能。
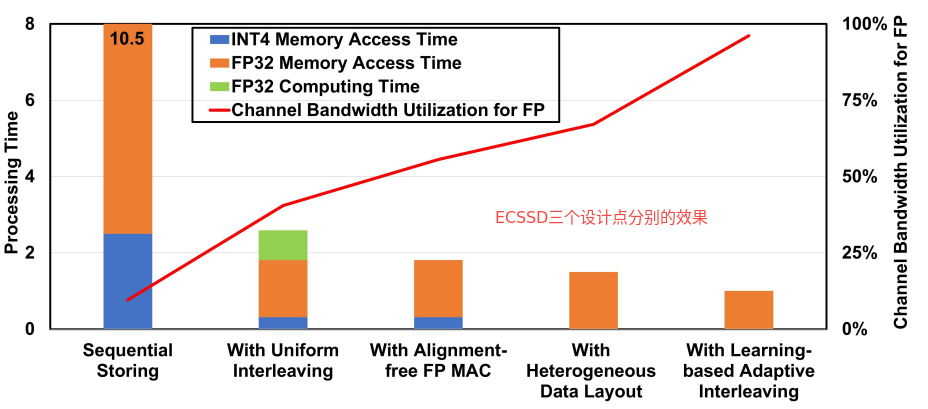
图5:ECSSD的端到端性能
如图5所示,ECSSD所提出的技术逐步提高了端到端性能,与起始基线相比,速度提高了 10.5 倍。
- 均匀交织将通道带宽利用率提高到 44.31%,从而实现 4.06 倍的加速。
- 免对齐 FP Mac 电路通过内存访问时间隐藏浮点计算时间。
- 异构数据布局设计将4位和32位数据传输分开,将通道带宽利用率提高到67.6%。
- 基于学习的自适应交织将浮点数据传输的通道带宽利用率提高到 94.7%。
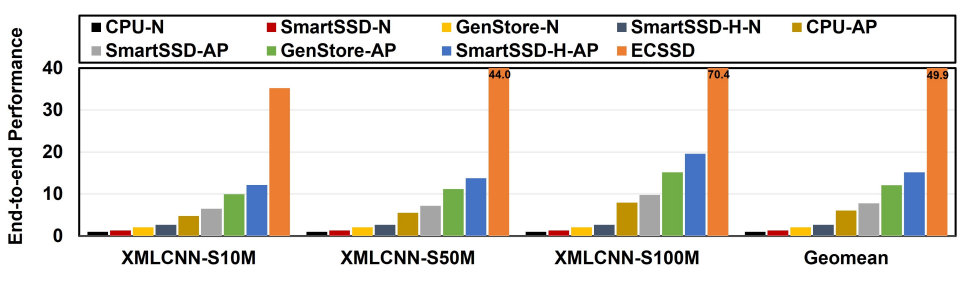
图6:ECSSD与其他架构的比较
如图6所示,ECSSD(极限分类固态硬盘)与各种基准进行了比较,包括基于 CPU、类似 GenStore 和基于 SmartSSD 的架构。ECSSD 的性能优于所有基准,实现了从 3.24 倍到 49.87 倍的显着性能改进。ECSSD相对于其他架构的优势来自于采用近似筛选算法、免对齐MAC电路的优越性能以及更好的带宽利用率等因素。
评估部分还讨论了 ECSSD 的可扩展性,16GB DRAM 容量是平衡硬件成本和最大分类规模的最佳选择。对于较大的分类问题,提出了一种横向扩展方法,可以并行使用多个 ECSSD 来执行,从而能够在不超出服务器内存容量的情况下处理更大的类别大小。
与高端 NVIDIA RTX 3090 GPU相比,其24GB内存远不足以存下极限分类层的参数,而且它的能耗是ECSSD的32倍以上;如果采用多个GPU构成集群,虽然能够满足内存容量需求,但能耗会超出ECSSD的500倍以上。
3.** 论文评述**
3.1** 清晰的问题呈现**
本文从近内存计算架构难以应对日益增长的极限分类数据集问题切入,分析了内存计算方案和近似筛选算法的局限性。接着,文章讨论了可计算存储CSD的硬件优势,如更大的高性能存储空间和盘内计算架构,同时也指出了盘内计算方案的限制,包括空间和面积预算有限,以及浮点MAC电路技术无法匹配SSD的高内部带宽,这可能导致带宽资源浪费。针对这些问题,作者提出了设计方案,并首次提出为SSD内硬件加速器设置芯片面积约束,这将有助于深化对可计算存储技术边界的理解,并为如何配置和调度计算和存储带宽资源等问题提供了启示。
3.2** 扎实的测试评估**
论文的测试评估执行得非常充分。不仅仅提供了各个设计点在总体效果上的贡献,还跟现有的SmartSSD等可计算存储方案进行了对比,并且和GPU方案以及ENMC近内存架构方案也进行了对比。扎实全面的评估也暴露了一个问题,就是并没有太多非常有洞见的观察和结论。
3.3** 处处深思熟虑**
本文是ENMC研究的延续,尽管在概念创新和架构贡献方面较为有限,但其深度和细致度仍然值得赞赏。文章从优化数据布局的角度,讨论了如何将权重数据放在DRAM和闪存中以及如何均衡地在不同闪存通道中写入权重数据。同时,也为盘内加速器的芯片面积约束提出了解决方案,并探讨了如何在芯片面积约束下实现高性能的MAC。总的来说,文章问题定义清晰,逻辑严密完整,关键点均有数据或分析支持,处处深思熟虑,写作层面具有很高的参考价值。
结语
ECSSD是作者MICRO'21近内存计算工作ENMC [2] 的姊妹篇。时至2023,可计算存储已经不是新概念。所以严格来讲,ECSSD实在谈不上是一篇很有新意的文章,但是笔者对这篇文章的作者充满敬佩。从写作的层面,这篇文章的问题呈现十分出色,测试评估全面扎实,全文处处深思熟虑,足以弥补概念创新性不足以及设计上的平凡,让人难以拒绝。面积和功耗是可计算存储设备面临的现实问题。在技术层面,ECSSD讨论了在SSD内部集成加速器的域面积(Area Size)和功耗问题,给出了实践建议,并进行了评估,让人印象深刻。ECSSD在文章类型上和ASPLOS‘22的GenStore [3] 非常类似,ECSSD面积功耗的讨论很可能是受GenStore启发。从存储架构的角度,GenStore的设计更加丰富,复杂度要高很多。
以架构顶会来要求,ECSSD中规中矩。它恰恰代表了大部分优秀科研人员的大部分工作,毕竟惊天地泣鬼神的文章不可多得。研究项目的立意有限怎么办呢?可以学一下ECSSD,把问题交代清楚,评估测试做扎实,处处深思熟虑。
参考文献
[1] Bryon Moyer, "Moving Data And Computing Closer Together", https://semiengineering.com/moving-data-and-computing-closer-together/
[2] Liu, Liu, Jilan Lin, Zheng Qu, Yufei Ding, and Yuan Xie. "Enmc: Extreme near-memory classification via approximate screening." In MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, pp. 1309-1322. 2021.
[3] Nika Mansouri Ghiasi, Jisung Park, Harun Mustafa, Jeremie Kim, Ataberk Olgun, Arvid Gollwitzer, Damla Senol Cali, Can Firtina, Haiyu Mao, Nour Almadhoun Alserr, Rachata Ausavarungnirun, Nandita Vijaykumar, Mohammed Alser, and Onur Mutlu. 2022. GenStore: a high-performance in-storage processing system for genome sequence analysis. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '22).
版权归原作者 存储前沿技术评论 所有, 如有侵权,请联系我们删除。