
Fast R-CNN 算法及训练过程
R-CNN显著提升了目标检测算法的性能,但因为计算过于复杂,耗时很长,所以在实际的应用系统中,大都无法使用。经过分析可知,R-CNN的复杂性主要来自两个方面:一是需要针对大量的候选框分别进行计算;二是特征提取之后的分类器训练和位置回归,是几个独立步骤分别进行的。在训练过程中,提取的特征要先存储在硬盘上,然后训练SVM分类模型,最后训练位置回归模型,而测试过程也是类似的,特征提取之后,需要先进行SVM分类,再回归目标的准确位置,整个过程在计算时间和存储空间上,都需要很大的开销。8.2节介绍的SPP-Net算法解决了前一个问题,通过共享特征图,整幅图像仅须进行一次卷积计算,但特征提取之后的处理仍然是分步骤独立进行的。本节介绍的FastR-CNN算法,针对上述两个问题进行了改进,使得算法速度有了非常显著的提升。以一个较深的网络VGG16为例,FastR-CNN的训练速度是R-CNN的9倍,测试速度是R-CNN的213倍;即使和SPP-Net相比,Fast R-CNN的训练速度和测试速度,也分别有了3倍和10倍的提升。
如图,在测试阶段,**Fast R-CNN将整幅图像和图像上生成的一系列候选框作为输入,通过卷积层和池化层计算得到特征图。对于每个候选框,使用下文将要介绍的ROI池化层,从每个候选框对应的特征图区域提取固定长度的特征向量。固定长度的特征向量经过若干全连接层的计算后,分成两个分支,一个分支通过softmax方法对候选框中的图像进行分类,另一个分支通过回归目标框相对于候选框的偏移量和缩放尺度来预测目标的准确位置。**
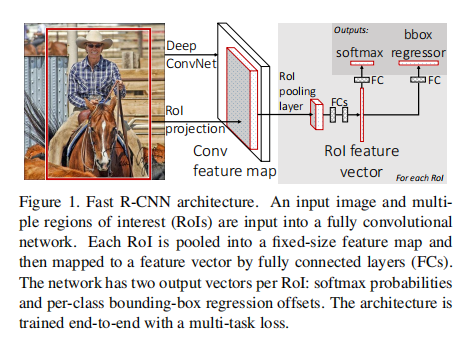
ROI池化层
要使得网络能够适应各种尺寸图像的输入,和SPP-Net类似,在最后一个卷积层之后,也需要加入一步操作,以保证输出的特征图具有固定的尺寸。为了提高算法效率,Fast R:CNN对整幅图像也只做一次卷积运算,所有的候选框共享各个卷积层输出的特征图。对于每个候选框,都可以通过映射关系在最后一个卷积层输出的特征图上找到其对应的感兴趣区域(Region Of Interest,即ROI)。我们在每个ROT区城上划分固定尺寸的均匀网格(比如,划分成7×7的网格),因为网格中每个单元格的宽高和特征图的宽高成正比,所以经过ROL池化层之后输出的特征图就具有了相同的尺寸。在每个单元格内使用最大值池化之后,原来的特征图就被映射成一个较小的固定尺寸的新特征图。
很容易看出,这里介绍的RO1池化层,本质上就是SPP层的一个特例。
模型训练
和R-CNN的训练过程类似,Fast R-CNN的网络模型也使用ImageNet分类数据集进行预训练。除此之外,为了能够实现检测任务,Fast R-CNN需要对原始的分类网络进行结构调整。
第一步,把最后一个池化层替换成上文所述的ROI池化层,网格的行数H和列数W需要与其后第一个全连接层的输入尺度相匹配(例如,对于VGG16,W=H=7)。
第二步,将最后一个全连接层(用于ImageNet的1000个分类),替换成2个并行的全连接层,其中一个全连接层用于分类(k+1个类别,k表示目标类别数,1表示背景),另一个全连接层用于回归目标框的位置。第三步,网络的输入变更为两部分,一部分是图像列表,另一部分是这些图像上的感兴趣区域,即ROI。
SPP-Net算法,在训练调优阶段,SPP层之前的网络参数在实际训练的过程中是不进行更新的。其中一个根本原因就是,如果更新全部参数,计算的代价会非常高。根据SPP-Net算法,一个批次的ROI图像可能来自不同的原始图像,这些图像卷积计算的特征图是无法共享的(但同一张图像卷积计算的特征图是可以共享的)。另外,在SPP层的特征图上,每个点对应原图的感受野都非常大,对于比较深的卷积结构,几乎覆盖了整个原图,使得每次迭代进行前向推理时,都需要分别在多个图像上进行卷积计算,效率十分低。那么,是否有一种方法,既能在训练调优的过程中更新所有的卷积层,又能保证比较高的计算效率呢?正是基于这样的考虑,Fast R-CNN的作者设计了一套独特的训练方法。
Fast R-CNN在训练过程中,假设每次迭代输入ROI图像的个数是R(batch size=R),这R个ROI来自固定数量的N张图像,每张图像包含R/N个ROI,因为同一张图像的各个ROI能共享卷积计算结果,所以可以通过减少N的数量来提升计算效率。不过,如果所有ROI都来自同一个原始图像,各个ROI的相关度会过高,不利于模型收敛,在计算效率和模型收敛效率之间,需要找到一个平衡点。在实际训练的过程中,通常选取N=2,R=128。在训练时,每个批次选取2张图像,每张图像上再分别选取64个ROI作为输入进行计算。通过这样的方式,每次迭代的计算速度大致是分别从128张不同图像上选取ROI计算速度的64倍。
** Fast R-CNN和R-CNN、SPP-Net相比,另一个明显的改进是采用了多任务(multi-task)策略。Fast R-CNN网络有两个并行的输出分支,对于每个ROI,第一个分支计算k个目标类别+1个背景类别的分类概率P=p=(p0,……,pK),这k+1个分类概率一般是通过在全连接层之后计算softmax得到的。第二个输出分支计算候选框归一化的偏移量和缩放尺度,我们把第k个类别对应的归一化的偏移量和缩放尺度记为**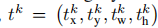 ,对于每个ROI,通过下面的公式计算分类和位置回归的联合损失,
,对于每个ROI,通过下面的公式计算分类和位置回归的联合损失,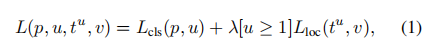
其中分类损失。
其中u表示真实的类别;位置损失表示对于类别u,真实的归一化偏移量及缩放尺度元组
与实际预测的归一化偏移量及缩放尺度元组
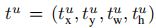 之间的差异,通常可以用两个元组之间的L距离或L,距离来度量。Fast R-CNN的作者使用了一种介于L1距离和L2距离之间的度量方法,具体如下所示:
之间的差异,通常可以用两个元组之间的L距离或L,距离来度量。Fast R-CNN的作者使用了一种介于L1距离和L2距离之间的度量方法,具体如下所示:
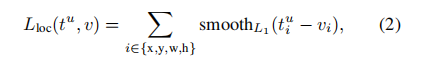
其中:
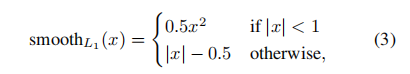
损失函数计算公式(8-9)中的是一个示性函数,当x=true时,[x]=1;当x=false时,[x]=0。因此,当u是目标类别时,u>1的取值为true,[*]=1,损失函数由分类损失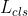和位置损失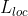两者构成,当u是背景时,u>=1的取值为false,[*]=0,损失函数仅由分类损失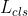构成。损失函数计算公式中的是一个权重因子,用于调节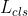和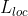的比例,通常情况下取入=1,即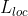和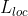按照等比例相加。
在调优训练的过程中,假设进行SGD优化的每个小批次都会使用128个ROI,这些ROI分别来自样本数据集中随机选取的2张图像(实际操作的时候会遍历整个样本集),每张图像上各自选择64个ROI。这64个ROI中,25%是前景目标,75%是背景。划分前景、背景的依据是ROI和真值的交并比(IoU),当IoU 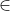 [0.5,1]时,ROI作为前景目标,当IoU 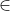 [0.1,0.5)时,ROI作为背景,当IoU<0.1时ROI不参与最开始的训练。训练好一个模型后,使用这些IoU<0.1的ROI进行难例挖掘(hard example mining)以进一步调优训练。在训练的过程中,为了增加样本的多样性,一般会使用50%的概率随机水平翻转图像,以此进行样本扩充。
训练过程中,需要计算ROI池化层的前向传播和后向传播。这里假设一个小批次的所有ROI都来自1张图像(前向传播的过程,对每张图像都是独立处理的,因此N>1的情况类似,可以直接推广过去)。假设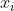是ROI池化层的第i个输入,是ROI池化层对r个RO1进行最大池化后的第j个输出,经过ROI池化层的前向传播,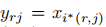,其中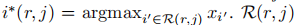表示所有以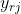为最大池化输出的所有x对应的指标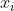的集合。对于反向传播,损失函数相对于ROI层的输入x,偏导数为
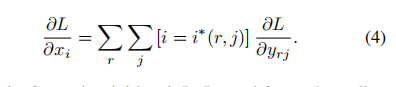
这个公式的意思是,ROI池化层输入变量的导数等于各个ROI经过最大池化后输出变量的导数之和。因为最终的损失等于每个ROI带来的损失之和,所以利用求导公式以及最大池化的反向传播公式,很容易推导出上述结论。
为了适应不同的尺度目标,可以直接基于多尺度样本训练具有多尺度检测能力的模型,也可以在测试的时候,把待测试图像缩放为几个不同尺度,构造图像金字塔,使用模型在金字塔的每一层进行测试,以此提高模型对多尺度目标的检测能力。
测试过程
在基于Fast R-CNN进行测试的时候,首**先通过Selective Search等方法,在原始图像上生成2000个左右的候选框,对于每个候选框,使用训练好的模型进行预测,预测结果为各个类别的分类概率,以及每个分类所对应的包围盒相对于原始候选框位置的偏移量和缩放尺度。待所有的候选框都预测完毕,会得到大量的包围盒,使用前面介绍的非极大值抑制方法对包围盒进行合并,就得到了最终的预测结果。**为了使预测更具有尺度鲁棒性,可以基于原始图像构造不同尺度的图像金字塔,把金字塔的每一层图像分别送入Fast R-CNN进行检测,从而得到对尺度变化更加鲁棒的结果。
版权归原作者 樱花的浪漫 所有, 如有侵权,请联系我们删除。