
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
TF-IDF 算法
前言
提示:这里可以添加本文要记录的大概内容:
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
提示:以下是本篇文章正文内容,下面案例可供参考
一、TF-IDF 是什么?
TF-IDF 全称为 term frequency–inverse document frequency
算法分为两部分: 词频(TF) 和 逆文档频率(IDF)
1词频(TF) = 某个词在文章中的出现次数 / 文章总词数
2逆文档频率(IDF) = log( 文章总数 / (包含该词的文章数+1))
分成两部分理解的话就是,一个词的词频越高说明它越重要,逆文档频率越高说明它越普遍,越普遍则代表性越差。所以,词频与最终的权重呈正比,逆文档频率与最终的权重呈反比。
在使用 TF-IDF 算法之前,需要先对文本进行预处理,如分词、去除停用词。在运算之前,需要先统计每篇文章中的每个词语出现的次数。
含义理解:
就将下面三张图,用代码表示出来

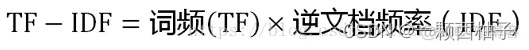
二、算法步骤
1.统计每一篇文档中词的出现次数
docList 是一个列表,包含整份数据(包含多篇文章)的信息;其中,列表的元素是字典类型,即列表包含多个字典元素,其中字典的结构为 词语:出现次数 ,所以,每个列表储存着一篇文章中词语出现次数的信息
defcountWord(doc):2'''
3 依次对所有文章进行统计,统计每篇文章中每个词的出现次数
4 doc: list 列表中一个元素为一篇文章的文本数据,str类型,空格间隔,含换行符
5 '''6 docList =[]7for item in doc:8 wordDic ={}9 wordList = item.strip().split()#将字符串转换成列表,一个元素一个词10for word in wordList:11 wordDic[word]= wordDic.setdefault(word,0)+112 docList.append(wordDic)13return docList
2.计算词频(TF)
词频(TF) = 某个词在文章中的出现次数 / 文章总词数
1例如:
2文章一:‘图书’: 34, ‘评论’: 12, ‘重视’: 2
3文章二:‘评论’: 7, ‘活动’: 4, ‘出版’: 5
4文章三:‘导致’: 2, ‘图书’: 12, ‘评论’: 9
5
6则 词频(TF) 为:
7文章一:‘图书’: 34/(34+12+2), ‘评论’: 12/(34+12+2), ‘重视’: 2/(34+12+2)
8文章二:‘评论’: 7/(7+4+5), ‘活动’: 4/(7+4+5), ‘出版’: 5/(7+4+5)
9文章三:‘导致’: 2/(2+12+9), ‘图书’: 12/(2+12+9), ‘评论’: 9/(2+12+9)
1def computeTF(wordDic):2'''
3 计算一篇文章中每个词的词频
4 wordDic: dict 为 docList 的元素
5 '''6#计算 total7 total =sum(wordDic.values())8#计算词频9 tfDic ={}10for word, value in wordDic.items():11 tfDic[word]= value / total
1213return tfDic
14 TF =[]#所有文章的词频15for wordDic in docList:
TF.append(computeTF(wordDic))
3.计算逆文档频率(IDF)
计算逆文档频率(IDF)
例如:
2文章一:‘图书’: 34, ‘评论’: 12, ‘重视’: 2
3文章二:‘评论’: 7, ‘活动’: 4, ‘出版’: 5
4文章三:‘导致’: 2, ‘图书’: 12, ‘评论’: 9
5
6则 逆文档频率(IDF) 为:
7’图书’: log(3/(2+1)), ‘评论’: log(3/(3+1)), ‘重视’: log(3/(1+1)), ‘活动’: log(3/(1+1)), ‘出版’: log(3/(1+1)), ‘导致’: log(3/(1+1))
8
9针对 ‘评论’: log(3/(3+1)) 这个数据:
10分子 3 是一共有三篇文章;分母 3 是其中有三篇文章包含了词语 ‘评论’;分母 1 是防止分母为 0 的一种做法,如果能保证分母不为 0,此处不加一也无妨。
defcomputeIDF(docList):2'''
3 计算每个词的逆文档频率
4 docList: list
5 '''6#计算 total7 total =len(docList)8#计算逆文档频率9 idfDic ={}10for wordDic in docList:11for word, value in wordDic.items():12if value >0:13 idfDic[word]= idfDic.setdefault(word,0)+114for word, value in idfDic.items():15 idfDic[word]= math.log(total/value+1)#要先引入 math 库1617return idfDic
4.计算TF-IDF
TF-IDF = 词频(TF) * 逆文档频率(IDF)
对于每篇文章,将文章中的每个词对应的词频和逆文档频率相乘,结果就是 TF-IDF 的值
TF_IDF =[]for i in TF:
s =[]for j in i.keys():if j in IDF.keys():
s.append({j:i[j]*IDF[j]})
TF_IDF.append(s)
TF_IDF
总结
相关参考链接:
TF-IDF算法介绍及实现
TF-IDF算法详解
百度百科——tf-idf
版权归原作者 一颗西柚子 所有, 如有侵权,请联系我们删除。