
❤写在前面
❤博客主页:努力的小鳴人
❤系列专栏:JavaSE超详总结😋
❤欢迎小伙伴们,点赞👍关注🔎收藏🍔一起学习!
❤如有错误的地方,还请小伙伴们指正!🌹
对于【10章Java集合】几张脑图带你进入Java集合的头脑风暴🔥 的拓展分析
文章标题
一、基础知识
- Set接口:存储无序、不可重复的数据
HashSet:主要实现类,线程不安全,可以存储null值LinkedHashSet:是HashSet的子类,遍历内部的数据时,可以按照添加的顺序遍历TreeSet:可以按照添加的对象指定属性,进行排序
二、HashSet
基于JDK 1.8 分析
- 定义
publicclassHashSet<E>extendsAbstractSet<E>implementsSet<E>,Cloneable,java.io.Serializable
HashSet继承AbstractSet类,实现Set、Cloneable、Serializable接口
- 基本属性
privatetransientHashMap<E,Object> map;//定义一个Object对象作为HashMap的valueprivatestaticfinalObject PRESENT =newObject();
HashSet中数据是存放在HashMap中,HashSet基于HashMap,对数据的访问基本用HashMap的方法,另外存入Set中的数据本身是无序的,维护访问顺序没有意义
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/publicHashSet(){
map =newHashMap<>();}
HashSet是可克隆对象和进行序列化
,其内部的数据存储区通过一个transient修饰的HashMap维护,调用了HashMap的构造函数完成。主要的参数是基础容量为16个单位,加载因子是0.75
- 方法
publicintsize(){return map.size();}publicbooleanisEmpty(){return map.isEmpty();}publicbooleancontains(Object o){return map.containsKey(o);}publicbooleanadd(E e){return map.put(e, PRESENT)==null;}publicVput(K key,V value){returnputVal(hash(key), key, value,false,true);}/**
* Returns an iterator over the elements in this set. The elements
* are returned in no particular order.
*
* @return an Iterator over the elements in this set
* @see ConcurrentModificationException
*/publicIterator<E>iterator(){return map.keySet().iterator();}
contains()判断某个元素是否存在于HashSet()中,存在返回true,否则返回false,底层调用containsKey判断HashMap的key值是否为空
底层调用HashMap的keySet返回所有的key,反映了HashSet中的所有元素都是保存在HashMap的key中,value则是使用的PRESENT对象,该对象为static final
publicObjectclone(){try{HashSet<E> newSet =(HashSet<E>)super.clone();
newSet.map =(HashMap<E,Object>) map.clone();return newSet;}catch(CloneNotSupportedException e){thrownewInternalError();}}
clone返回此 HashSet 实例的浅表副本,并没有复制这些元素
🔥put方法
finalVputVal(int hash,K key,V value,boolean onlyIfAbsent,boolean evict){Node<K,V>[] tab;Node<K,V> p;int n, i;//确认初始化if((tab = table)==null||(n = tab.length)==0)
n =(tab =resize()).length;//如果桶为空,直接插入新元素,也就是entryif((p = tab[i =(n -1)& hash])==null)
tab[i]=newNode(hash, key, value,null);else{Node<K,V> e;K k;//如果冲突,分为三种情况//key相等时让旧entry等于新entry即可if(p.hash == hash &&((k = p.key)== key ||(key !=null&& key.equals(k))))
e = p;//红黑树情况elseif(p instanceofTreeNode)
e =((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else{//如果key不相等,则连成链表for(int binCount =0;;++binCount){if((e = p.next)==null){
p.next =newNode(hash, key, value,null);if(binCount >= TREEIFY_THRESHOLD -1)// -1 for 1sttreeifyBin(tab, hash);break;}if(e.hash == hash &&((k = e.key)== key ||(key !=null&& key.equals(k))))break;
p = e;}}if(e !=null){// existing mapping for keyV oldValue = e.value;if(!onlyIfAbsent || oldValue ==null)
e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if(++size > threshold)resize();afterNodeInsertion(evict);returnnull;}
hashset不允许重复的元素加入,因为只要key的equals方法判断为true时会发生value的替换,即当两个hashcode相同但key不相等的entry插入时,仍然会连成一个链表,长度超过8时依然会和hashmap一样扩展成红黑树,当add方法发生冲突时,如果key相同,则替换value,如果key不同,则连成链表
🔥小结
- HashSet有以下特点●不能保证元素的排列顺序,顺序有可能发生变化 ●不是同步的 ●集合元素可以是null,但只能放入一个null
- 当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置
HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等
🎁注:如果要把一个对象放入HashSet中,重写该对象对应类equals方法,也应该重写其hashCode()方法:其规则是如果两个对象通过equals方法比较返回true时,其hashCode也应该相同。另对象中用作equals比较标准的属性,都应用来计算 hashCode的值
三、LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺序保存的,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素
构造函数
//Constructor - 1publicLinkedHashSet(int initialCapacity,float loadFactor){super(initialCapacity, loadFactor,true);//Calling super class constructor}//Constructor - 2publicLinkedHashSet(int initialCapacity){super(initialCapacity,.75f,true);//Calling super class constructor}//Constructor - 3publicLinkedHashSet(){super(16,.75f,true);//Calling super class constructor}//Constructor - 4publicLinkedHashSet(Collection<?extendsE> c){super(Math.max(2*c.size(),11),.75f,true);//Calling super class constructoraddAll(c);}
四个构造函数调用的是同一个父类构造函数,该构造函数是一个包内私有构造函数,它只能被LinkedHashSet使用,该构造函数需要初始容量,负载因子和 boolean类型的哑值等参数,这个哑参数只是用来区别这个构造函数与HashSet的其他拥有初始容量和负载因子参数的构造函数
🎁注:哑值:没有什么用处的参数,作为标记
🔥小结
- LinkedHashSet直接继承自HashSet,能够维护基础的有序性,LinkedHashSet并没有自己的方法,所有方法都继承自它的父类HashSet,因此对LinkedHashSet的所有操作方式就像对HashSet操作一样,唯一的不同是内部使用不同的对象去存储元素。在HashSet中,插入的元素是被当做HashMap的键来保存的,而在LinkedHashSet中被看作是LinkedHashMap的键 换句话说LinkedHashSet继承自HashSet,源码更少、更简单, 唯一的区别是LinkedHashSet内部使用的是LinkHashMap
- 特点:●有序,按照插入顺序 ●不是同步的 ●集合元素可以是null,但只能放入一个null ●没有set和get方法 只能通过迭代器取值
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet
四、TreeSet
- 定义TreeSet与TreeMap实现类似
TreeMap是一个有序的二叉树,TreeSet同样也是一个有序的二叉树,它的作用是提供有序的Set集合。TreeSet继承自AbstractSet,实现了Set接口、Cloneable和Serializable、NavigableSet接口。其内部主要是通过一个NavigableMap的map维护数据存储
publicclassTreeSet<E>extendsAbstractSet<E>implementsNavigableSet<E>,Cloneable,java.io.Serializable
- 构造方法
//默认构造方法publicTreeSet(){this(newTreeMap<E,Object>());}//构造包含指定 collection 元素的新 TreeSet,按照其元素的自然顺序进行排序。publicTreeSet(Comparator<?superE> comparator){this(newTreeMap<>(comparator));}//构造新的空 TreeSet,根据指定比较器进行排序。publicTreeSet(Collection<?extendsE> c){this();addAll(c);}//构造与指定有序 set 具有相同映射关系和相同排序的新 TreeSetpublicTreeSet(SortedSet<E> s){this(s.comparator());addAll(s);}TreeSet(NavigableMap<E,Object> m){this.m = m;}
🔥主要方法
1.add:将指定的元素添加到此 set
publicbooleanadd(E e){return m.put(e, PRESENT)==null;}publicVput(K key,V value){Entry<K,V> t = root;if(t ==null){//空树时,判断节点是否为空compare(key, key);// type (and possibly null) check
root =newEntry<>(key, value,null);
size =1;
modCount++;returnnull;}int cmp;Entry<K,V> parent;// split comparator and comparable pathsComparator<?superK> cpr = comparator;//非空树,根据传入比较器进行节点的插入位置查找if(cpr !=null){do{
parent = t;//节点比根节点小,则找左子树,否则找右子树
cmp = cpr.compare(key, t.key);if(cmp <0)
t = t.left;elseif(cmp >0)
t = t.right;//如果key的比较返回值相等,直接更新值(一般compareto相等时equals方法也相等)elsereturn t.setValue(value);}while(t !=null);}else{//如果没有传入比较器,则按照自然排序if(key ==null)thrownewNullPointerException();@SuppressWarnings("unchecked")Comparable<?superK> k =(Comparable<?superK>) key;do{
parent = t;
cmp = k.compareTo(t.key);if(cmp <0)
t = t.left;elseif(cmp >0)
t = t.right;elsereturn t.setValue(value);}while(t !=null);}//查找的节点为空,直接插入,默认为红节点Entry<K,V> e =newEntry<>(key, value, parent);if(cmp <0)
parent.left = e;else
parent.right = e;//插入后进行红黑树调整fixAfterInsertion(e);
size++;
modCount++;returnnull;}
- get:获取元素
publicVget(Object key){Entry<K,V> p =getEntry(key);return(p==null?null: p.value);}
与put的流程类似,只把插入换成了查找
- ceiling:返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回 null
太多了直接上脑图: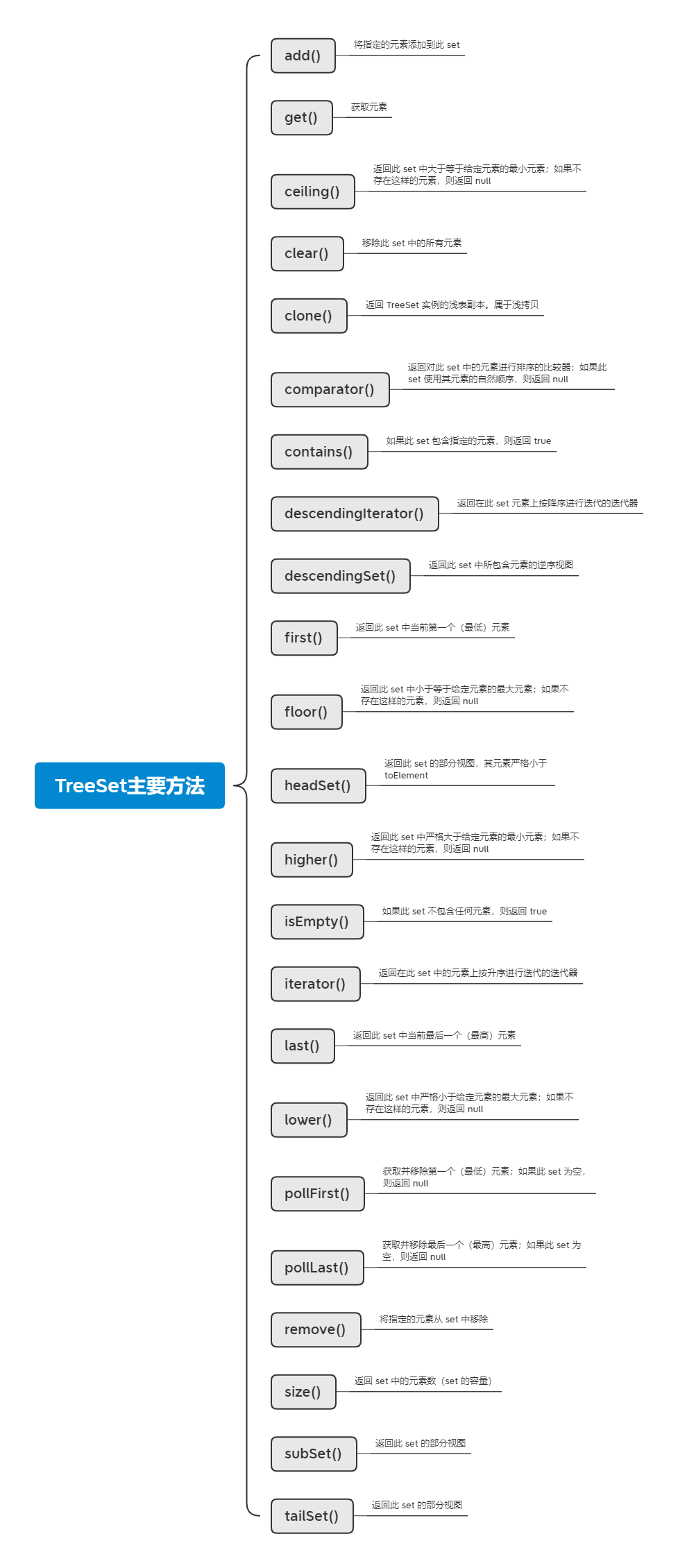
🔥自然排序与定制排序
TreeSet支持两种排序方式,自然排序 和 定制排序
强烈推荐传送门🎁 >>> 【附章3Java比较器】的两个排序你知道吗?
🔥小结
- TreeSet内部是通过TreeMap构造出来的
- 特点:●有序,按照比较器排序,并非按照插入顺序 ●不是同步的 ●集合元素可以是null,但只能放入一个null ●没有set和get方法 只能通过迭代器取值
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态
🎁总结:HashSet、LinkedHashSet和TreeSet,三者其内部都是基于Map来实现的。TreeSet和LinkedHashSet分别使用了TreeMap和LinkedHashMap来控制访问数据的有序性。都属于Set的范畴,都是没有重复元素的集合。基于HashMap和TreeMap,也都是非线程安全的
👌 作者算是一名Java初学者,文章如有错误,欢迎评论私信指正,一起学习~~
😊如果文章对小伙伴们来说有用的话,点赞👍关注🔎收藏🍔就是我的最大动力!
🚩不积跬步,无以至千里,书接下回,欢迎再见🌹
版权归原作者 努力的小鳴人 所有, 如有侵权,请联系我们删除。