
🌈数据结构专栏
- (꒪ꇴ꒪(꒪ꇴ꒪ )🐣,我是Scort
- 🌍博客主页:张小姐的猫~江湖背景🌍
- 快上车🚘,握好方向盘跟我有一起打天下嘞!
- 送给你们一句罗翔老师的话🤔:
- 🔥你迷茫的原因,在于读书太少,而想的太多🔥
- 🙏作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
- 🎉🎉欢迎持续关注!🎉🎉



手把手教会你单链表🔍

🌍一.链表的概念及结构
🏝️1.链表的概念
- 链表是一种
物理存储结构上非连续、非顺序的存储结构。 - 数据元素的
逻辑顺序是通过链表中的指针链接次序实现的 。
🏝️2.链表的结构
逻辑结构是用来描述数据元素之间的逻辑关系,是一个抽象概念,与数据的实际存储无关,独立于计算机存在。物理结构是数据元素及其相互之间的关系在计算机存储器中的存储方式,简而言之物理结构就是实际的物理存储方式。 -
逻辑结构:👇🏻
物理结构:👇🏻

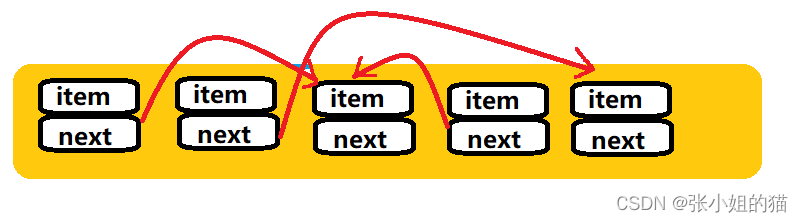
🌟综上:
- 1️⃣链表实际上是由不同的结点
链接而成的【结点是由结构体类型来创建】 - 2️⃣结点是由数据【存放数据】和指针【指向下一个结点的地址】所组成的
- 3️⃣现实中的
结点一般是在堆上申请空间,是按照一定的策略【随机分配】来分配的,两次申请的空间是随机的,可能连续,也可能不连续
🤏简单来说:
链表
并不像顺序表那样按照
下标
去访问
而是通过访问每个节点的
指针域
【储存指向下一个节点的空间地址】,去找到下一个节点。
所以链表就是通过一个个节点的指针的
地址链接
起来,但其中空间的
地址是随机
的,不连续,所以不能像顺序表一样进行连续访问,所以链表的
逻辑结构
和
物理结构
不同
💫但是我们实现的时候是按照
逻辑结构来实现
🌍二.链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8️⃣种链表结构:
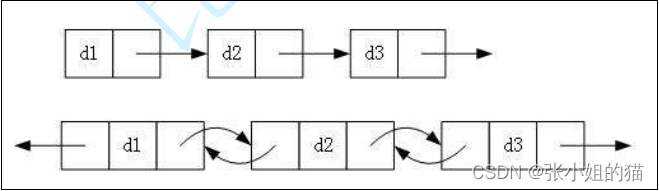
1️⃣ 单向或者双向:👇🏻
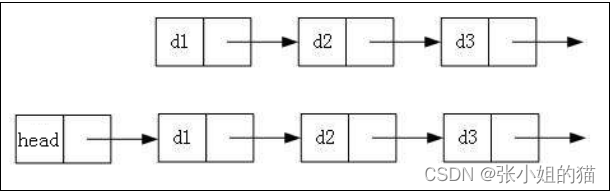
2️⃣带头或者不带头:👇🏻
3️⃣循环或者非循环:👇🏻
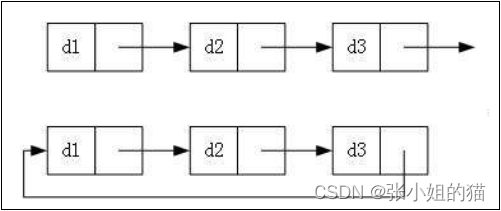
🔥虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:👇🏻
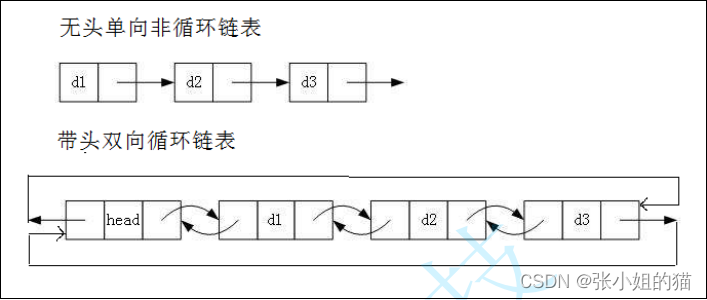
- 无头单向非循环链表:
结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结 构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。- 带头双向循环链表:
结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都 是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带 来很多优势,实现反而简单了,后面我们代码实现了就知道了。
了解了这么多链表的知识,接下来我们就来实现一下吧~👇🏻
🌍三.链表的实现
🛫准备工作
为了简明扼要的分清楚链表的作用,各部分代码分在以下三个不同的项中👇🏻
- Slist.h ---------➡️函数功能的说明
- Slist.c ---------➡️函数功能的实现
- test.c ---------➡️调用函数功能
💍结点: 我们所创建的结点都是从堆区上申请空间的
简单来说➡️: 使用动态开辟在堆区上开辟一个结点的空间
typedefint SLTDataType;typedefstructSListNode{
SLTDataType data;structSListNode* next;}SLTNode;
💍节点的本质是
结构体
,其中包括了
数据域
和
指针域
SLTDataType data是数据域,用来存储数据struct SListNode* next是指针域,存放着指向下一个节点的地址,因此链接成链表
📌我们用
typedef
来重命名,可以很好的简化代码关键词
🏝️1.动态申请一个结点
1️⃣创建新结点的函数声明:
SLTNode*BuySListNode(SLTDataType x);
2️⃣创建新结点函数的实现:
SLTNode*BuySListNode(SLTDataType x){
SLTNode* newnode =(SLTNode*)malloc(sizeof(SLTNode));assert(newnode);
newnode->data = x;
newnode->next =NULL;return newnode;}
🏝️2.单链表的头插
💡说明: 在链表头部链接一个结点,使其变成新结点
➡️思路实现: 在原链表的头链表前,添加新结点,使其变成头结点
❗注意事项:
空链表也可以头插- 注意实现的顺序,不然会找不到后一个结点地址
✨动图解析:
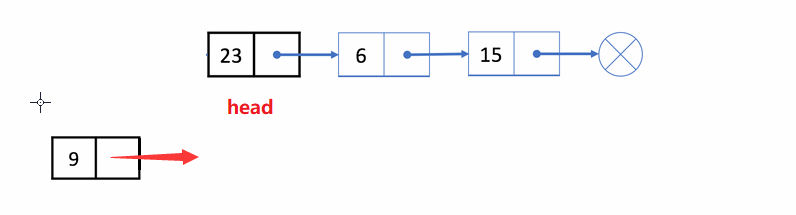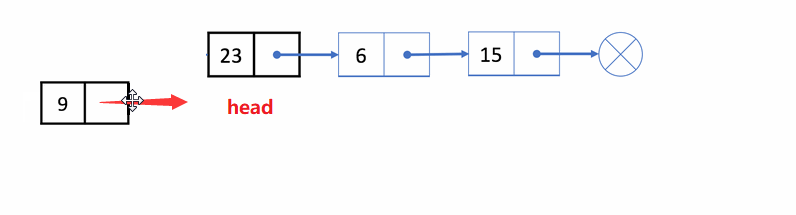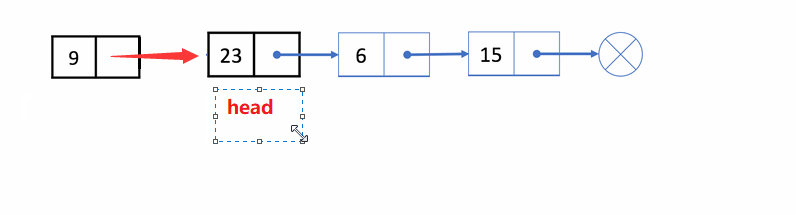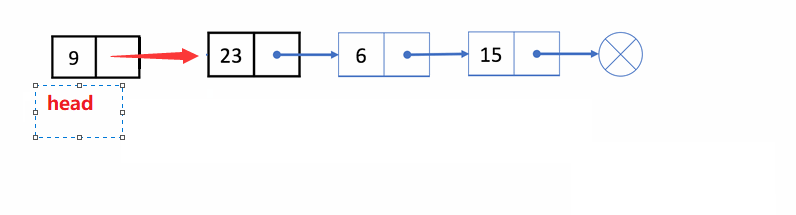
1️⃣单链表的头插的函数声明:
voidSListPushFront(SLTNode** pphead, SLTDataType x);
2️⃣单链表的头插函数的实现:
voidSListPushFront(SLTNode** pphead, SLTDataType x){
SLTNode* newnode =BuySListNode(x);
newnode->next =*pphead;*pphead = newnode;}
🏝️3.单链表尾插
💡说明: 在链表的尾部链接一个新结点
➡️思路实现: 通过访问链表走到链表最后一个结点,将此结点的next指向新的结点
❗注意事项: 当链表为空时,尾插可以理解为头插
✨动图解析:
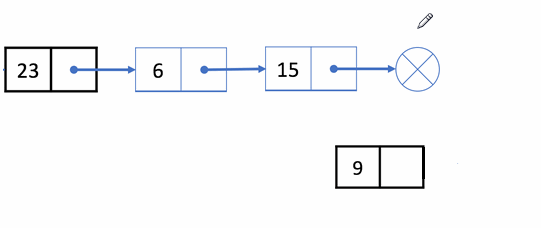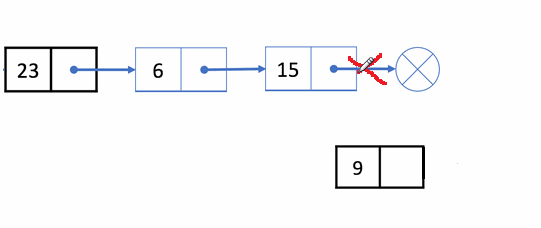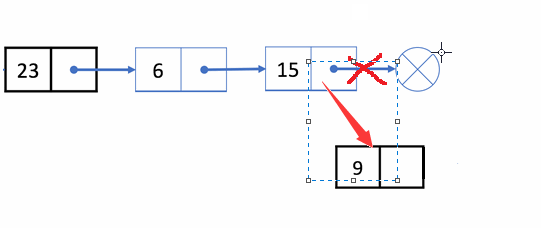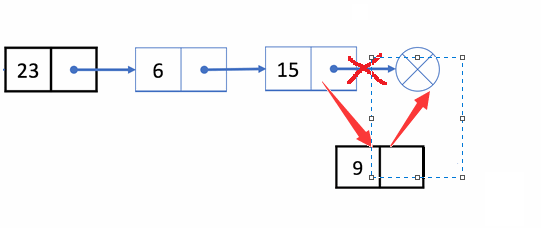
1️⃣单链表尾插的函数声明:
voidSListPushBack(SLTNode** pphead, SLTDataType x);
2️⃣单链表尾插函数的实现:
voidSListPushBack(SLTNode** pphead, SLTDataType x){
SLTNode* newnode =BuySListNode(x);if(*pphead ==NULL){*pphead = newnode;}else{//找尾节点
SLTNode* tail =*pphead;while(tail->next !=NULL){
tail = tail->next;}
tail->next = newnode;}}
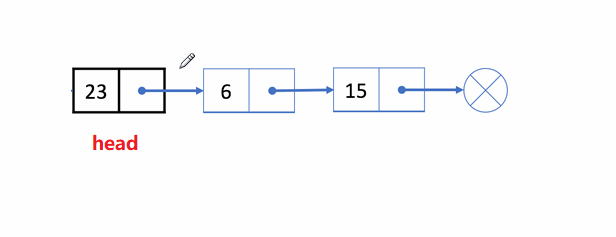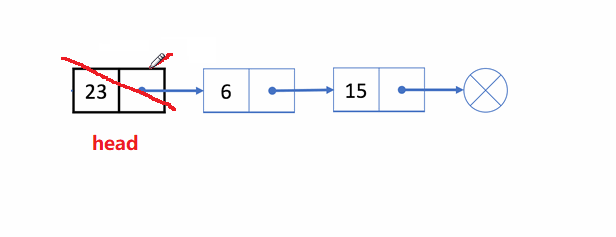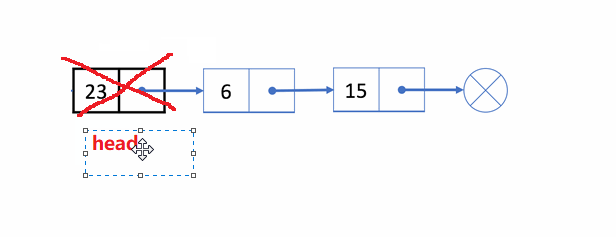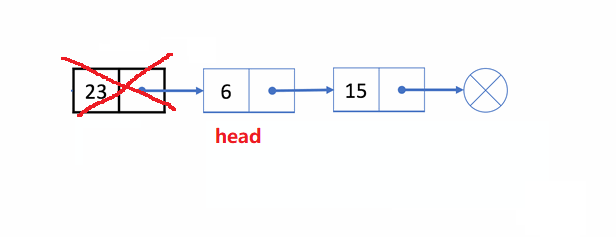
🏝️4.单链表头删
💡说明: 在链表的头部删除第一个结点
➡️思路实现: 先记住第二个结点的位置,释放头结点,让第二个结点变成头结点
❗注意事项:
多情况考虑
- 链表为空
NULL的情况,直接返回,不用删了 - 一个结点
- 两个及以上的结点
✨动图解析:
1️⃣单链表头删的函数声明:
voidSListPopFront(SLTNode** pphead);
2️⃣单链表头删函数的实现:
voidSListPopFront(SListNode** pplist){// 1.空// 2.一个// 3.两个及以上
SListNode* first =*pplist;if(first ==NULL){return;}elseif(first->next ==NULL){free(first);*pplist =NULL;}else{
SListNode* next = first->next;free(first);*pplist = next;}}
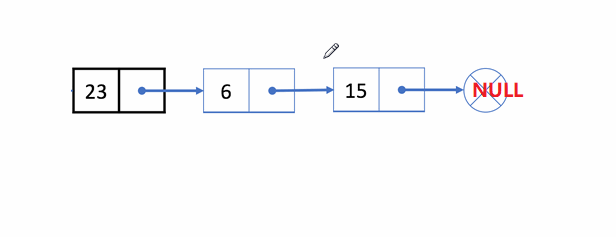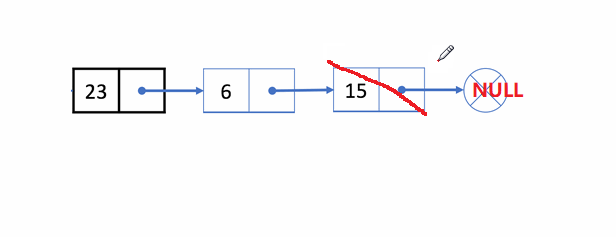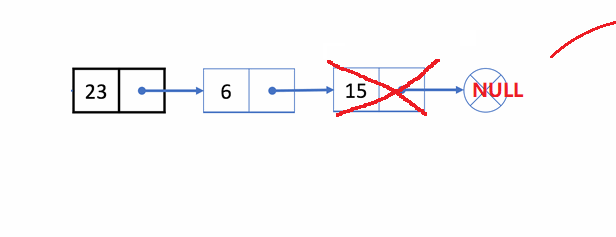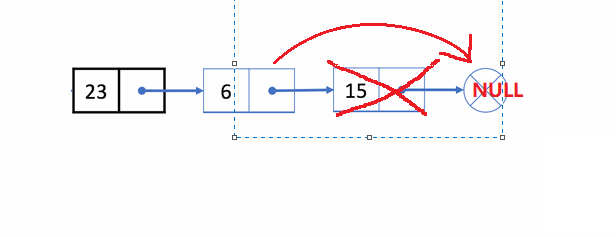
🏝️5.单链表的尾删
💡说明: 在链表的尾部删除最后一个结点
➡️思路实现: 遍历链表,找到并释放最后一个结点,再把倒数第二个结点的next置为
NULL
;
❗注意事项:
- 考虑到
一个结点和多个结点的情况
✨动图解析:
1️⃣单链表尾删的函数声明:
voidSListPopBack(SLTNode** pphead);
2️⃣单链表尾删函数的实现:
voidSListPopBack(SLTNode** pphead){assert(pphead);//1、只有一个节点//2、多个节点if((*pphead)->next==NULL){free(*pphead);*pphead =NULL;}else{//方法一://SLTNode* tail = *pphead;//SLTNode* prevtail = NULL;//while (tail->next != NULL)//{// prevtail = tail;// tail = tail->next;//}//free(tail);//prevtail->next = NULL;//方法2:只定义一个指针
SLTNode* tail =*pphead;while(tail->next->next !=NULL){
tail = tail->next;}free(tail->next);
tail->next =NULL;}}
🏝️6.单链表查找节点
💡说明:找到数据域为x的结点
➡️思路实现: 遍历链表,直到找到我们所需的结点,找到返回
该结点位置
,没有即
返回NULL
1️⃣单链表查找节点的函数声明:
voidSListFind(SLTNode* phead, SLTDataType x);
2️⃣单链表查找节点函数的实现:
voidSListFind(SLTNode* phead, SLTDataType x){
SLTNode* cur = phead;while(cur !=NULL){if(cur->data == x){return cur;}else{
cur = cur->next;}}returnNULL;
🏝️7.在pos位置之后插入x
💡说明: 在对链表的某个结点(pos)后进行插入x结点
❗注意事项:
- 该结点是否存在
- 插入顺序不能乱,不然找不到后一位的地址
✨动图解析:
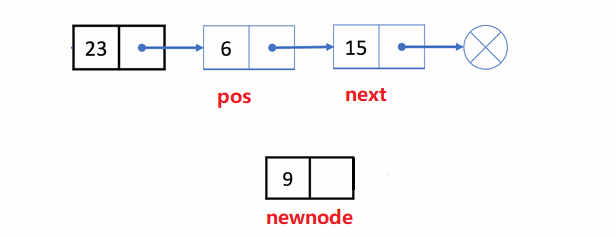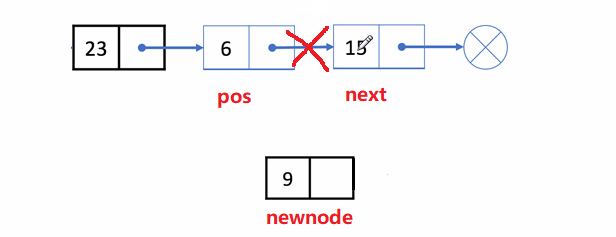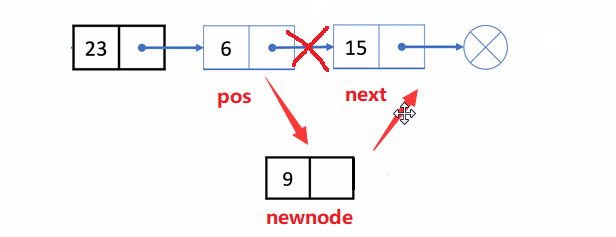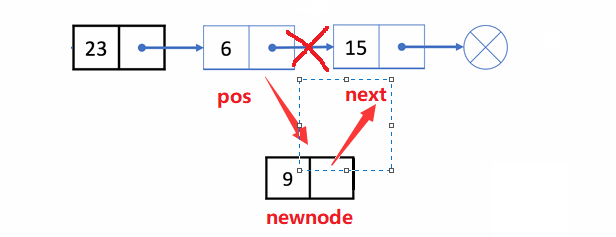
1️⃣在pos位置之后插入x的函数声明:
voidSListInsertAfter(SLTNode* pos, SLTDataType x);
2️⃣在pos位置之后插入x函数的实现:
voidSListInsertAfter(SLTNode* pos, SLTNode** pphead, SLTDataType x){assert(pos);
SLTNode* newnode =BuySListNode(x);
SLTNode* next = pos->next;
pos->next = newnode;
newnode->next = next;//pos newnode next//要考虑顺序//assert(pos);//SLTNode* newnode = BuySListNode(x);//newnode->next = pos->next;//pos->next = newnode;}
🏝️8.删除pos位置之后的值
💡说明: 在链表的尾部删除最后一个结点
➡️思路实现: 遍历链表,找到并释放最后一个结点,再把倒数第二个结点的next置为
NULL
;
❗注意事项:
- 考虑到
一个结点和多个结点的情况
✨动图解析:
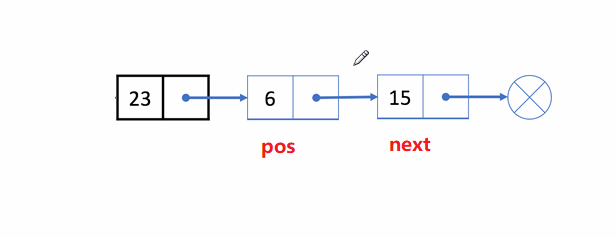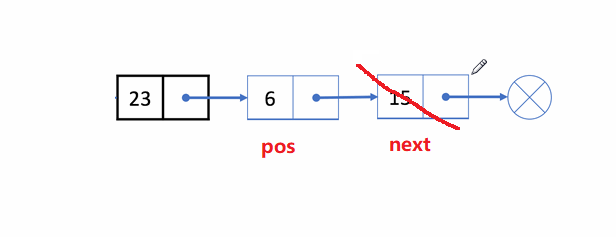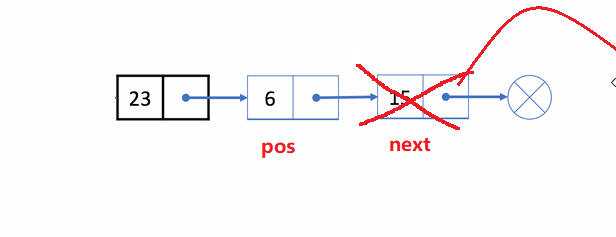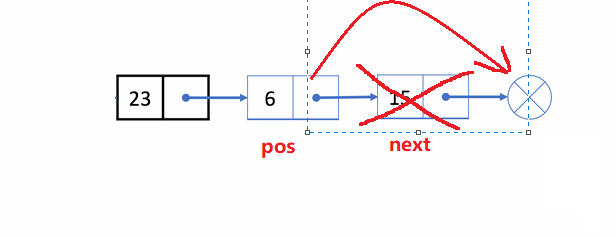
1️⃣删除pos位置之后的值函数声明:
voidSListEraseAfter(SLTNode* pos,SLTDataType x);
2️⃣删除pos位置之后的值函数的实现:
voidSListEraseAfter(SListNode* pos){assert(pos);// pos next nextnext
SListNode* next = pos->next;if(next !=NULL){
SListNode* nextnext = next->next;free(next);
pos->next = nextnext;}}
🏝️9.打印单链表
💡说明:遍历链表逐个打印
1️⃣打印链表的函数声明:
voidSListPrint(SLTNode* plist);
2️⃣打印链表函数的实现:
voidSListPrint(SLTNode* plist){
SLTNode* cur = plist;while(cur !=NULL){printf("%d ", cur->data);
cur = cur->next;}printf("\n");}
🏝️10.销毁单链表
💡说明:遍历单链表后逐一释放
1️⃣打印链表的函数声明:
voidSListDestroy(SListNode** pphead)
2️⃣打印链表函数的实现:
voidSListDestroy(SLTNode** pphead){assert(pphead);
SLTNode* cur =*pphead;while(cur){
SLTNode* next = cur->next;free(cur);
cur = next;}*pphead =NULL;}

🌍四.一级or二级指针接收问题
如果有细心的老铁,会发现上述的函数实现时,上述的形参不仅有
一级指针
,还有不少
二级指针
,为什么会不一样呢?
📌举个例子
voidf1(int* p){*P =1;}voidf2(int** pp){int* px =(int*)malloc(sizeof(int));assert(px);*pp = px;}intmain(){//要改变int,就传int的地址,解引用改变int x =0;f1(&x);printf("%d\n", x);//要改变int*,传int*的地址,解引用改变int* ptr =NULL;f2(&ptr);printf("%d\n", ptr);}
所以我们知道:要改变
int
,就传int的地址,要改变
int*
,传int*的地址
如图💓:
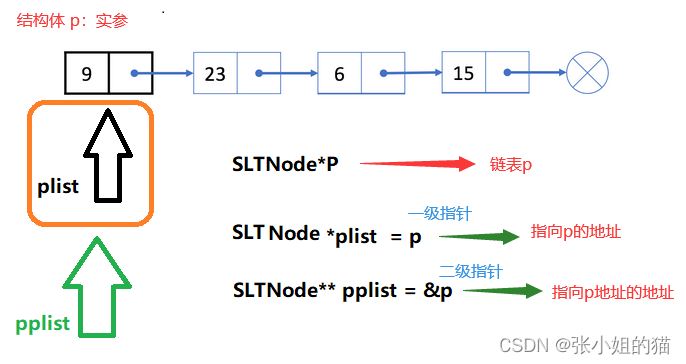
💫同理我们知道:
- ♻️如果用
一级指针接收,则改变的是plist的指向,头结点指针的指向并没有发生改变, - 🍭如果用
二级指针接收,则相当于形参是结构体p这个变量的地址,pplist = &p,*pplist = p,即可改变plist的地址,也就改变了头结点。
📌综上:
- 只要是要修改
头指针所指向的位置,就需要传头指针的地址上来,即二级指针 - 如不改变头指针的,传
一级指针

📢写在最后
能够看完的都是棒棒哒🙌!
这样我们基本就了解了数据结构中"单链表"的的知识啦
接下来我还会继续写关于📚《链表oj面试题》等…
如果有错误❌,欢迎在评论区指正呀✅
🥇想学吗你?我教你啊
🎉觉得博主写的还不错👍的可以一键三连撒🎉

版权归原作者 张小姐的猫 所有, 如有侵权,请联系我们删除。