
本文总计 2700 字,预计阅读需要 10-15分钟
本文将介绍如何在 Python 和 Scala 中 使用 Spark NLP 库训练超过 100 多种语言的模型,结果准确率超过 90%。 还有会介绍 Spark NLP 中的管道是如何创建和使用的,最后还会提到一些有用的资源。
数据采集
要开始任何机器学习项目,我们首先需要数据。对于这项任务我收集了超过 100 万行各种语言的文本:
我们只使用其中的 4 万行,就可以在这100 多种语言中达到 91% 的准确率。
我使用了 Pandas(用于数据收集和操作的 Python 模块)来收集和合并数据。数据超过一百万并且有些不平衡,因此我将数据平衡为 50-50 个标签分布。
Spark NLP
Spark NLP 是 NLP 领域中使用最广泛和创新的工具之一。它在各种任务中支持 100 多种语言,并且易于使用、可扩展,并且始终提供最先进的技术。它在 NER、POS、标记化、句子相似性等各种任务中拥有超过 4000 个模型,还包括了一些高级函数,如关系提取、断言状态、去标识化等。它是由 John Snow Labs 构建的,如果你们有使用过他,推荐你试一试。
安装 Spark NLP
Python作为机器学习的标准语言已经是公认的事实了,但是Spark NLP 还支持 Java 和 Python,并且可以在本文的最后找到 Scala 版本。为了简单起见我们就以python介绍他的功能。
安装后我们可以导入所需的包。
import sparknlpspark = sparknlp.start()from sparknlp.base import *from sparknlp.annotator import *from pyspark.ml import Pipelineimport pandas as pd
在哪里训练模型?
如果在PC上训练一个模型来预测 100 多种语言模型肯定是不可能,所以使用云服务器是最好的选择。
aws,gcp都是可以选择的,甚至是 Databricks( Spark 的商业化公司),它最近刚刚筹集了 16 亿美元!本篇文章将使用Databricks进行训练。
加载数据
下一步是加载实际数据,我将其分为训练和测试部分,并将其上传到 Github 以方便访问。
!wget https://raw.githubusercontent.com/ahmedlone127/Multilingual_Sentiment/master/Data/Sentiment_Test.csv!wget https://raw.githubusercontent.com/ahmedlone127/Multilingual_Sentiment/master/Data/Sentiment_Train.csvimport pandas as pd df = pd.read_csv("Sentiment_Train.csv")train_df = spark.createDataFrame(df)df = pd.read_csv("Sentiment_Test.csv")df = df.iloc[:7000]test_df = spark.createDataFrame(df)train_df.show()
结果如下:

一些工具函数
Spark NLP 提供了日志功能但是我们还需要定义一些函数来从日志中获取准确性和损失的图表。
import matplotlib.pyplot as pltdef loss_plot(log_path) :withopen(log_path, "r", encoding="utf-8") as f :lines = f.readlines()loss = [line.split()[6] for line inlinesif line.startswith("Epoch") and line.split()[6] != "size:"] epoch = [] losses = []for x, y in enumerate(loss, 1): epoch.append(x) losses.append(float(y)) plt.subplots(1,1, figsize=(8,8)) plt.ylabel('Loss') plt.xlabel('Epochs') plt.title('Loss Plot') plt.plot(epoch[::-1], losses[::-1]) plt.show()
def acc_plot(log_path):withopen(log_path, "r", encoding="utf-8") as f :lines = f.readlines()loss = [line.split()[9] for line inlinesif line.startswith("Epoch") and line.split()[6] != "size:"]
epoch = [] losses = []for x, y in enumerate(loss, 1): epoch.append(x) losses.append(float(y)) plt.subplots(1,1, figsize=(8,8)) plt.ylabel('Accuracy') plt.xlabel('Epochs') plt.title('Accuracy Plot') plt.plot(epoch[::-1], losses[::-1]) plt.show()
用 Bert 训练模型
下一步是构建管道。在 Spark-NLP 中,我们将功能块放在一起来构建成管道来执行复杂的功能,例如从非结构化医疗数据中提取有用信息。
这个管道非常简单,管道的第一部分是 DocumentAssembler,它被广泛使用并将文本转换为 Spark NLP 使用的格式。接下来是嵌入,它将我们的文本映射到模型可以处理的句子向量中。这里会尝试不同的嵌入,看看哪个能产生最好的结果。我第一次尝试使用通过 100 多种语言训练的通用句子编码器,管道的最后一部分是 ClassifierDlApproach,它是一种用于分类模型的算法。
from pyspark.ml import Pipelinefrom sparknlp.annotator import *from sparknlp.common import *from sparknlp.base import *
document = DocumentAssembler()\ .setInputCol("text")\ .setOutputCol("document")sent_embeddings = BertSentenceEmbeddings.pretrained("sent_bert_use_cmlm_multi_base_br", "xx") \ .setInputCols("document") \ .setOutputCol("sentence_embeddings")classifierDl = ClassifierDLApproach()\ .setInputCols(["sentence_embeddings"])\ .setOutputCol("class")\ .setLabelColumn("y")\ .setMaxEpochs(125)\ .setLr(0.0007) \ .setEnableOutputLogs(True)\ .setOutputLogsPath('/Classifier_logs_Bert')
pipeline = Pipeline( stages = [document, sent_embeddings, classifierDl ])
让我们继续训练模型。
mutli_lingual_model = pipeline.fit(train_df)
日志文件将被保存在Databricks DFBS系统中,我们可以使用下面的命令将它们复制到本地会话中,并获取所有日志文件地址:
dbutils.fs.cp("/Classifier_logs_Bert",'file:/Classifier_logs_Bert/'True)import oslog_files = os.listdir("/Classifier_logs_Bert")
然后读取文件:
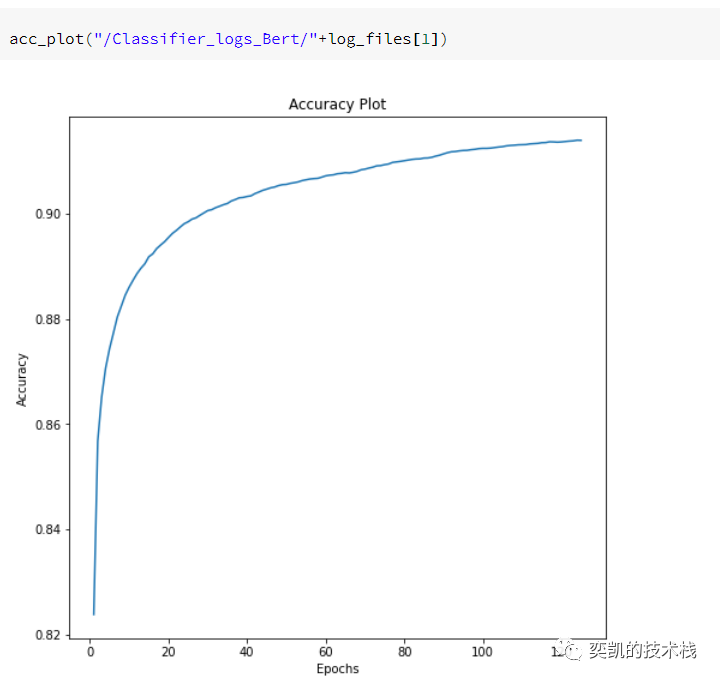
可视化准确率
损失
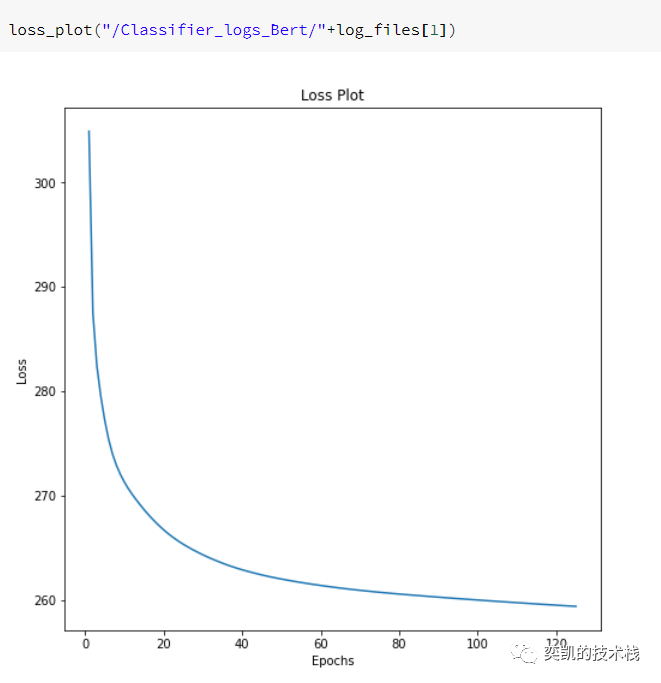
看起来很好!让我们看看它在测试数据上的表现
我们必须把它转换成一个pandas的df
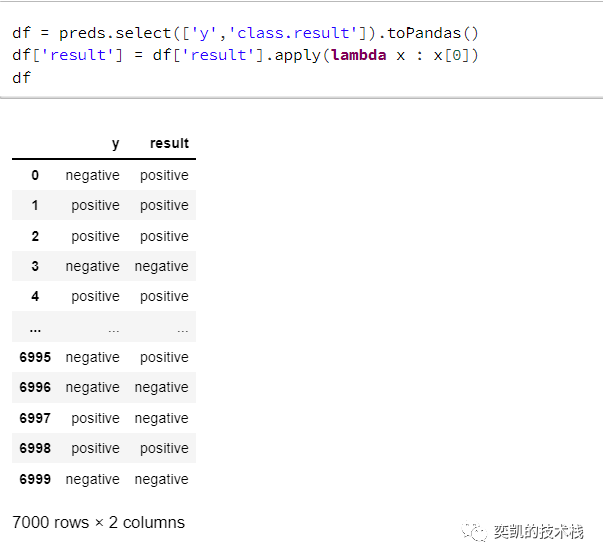
现在让我们用Sklearn来看看Bert的表现
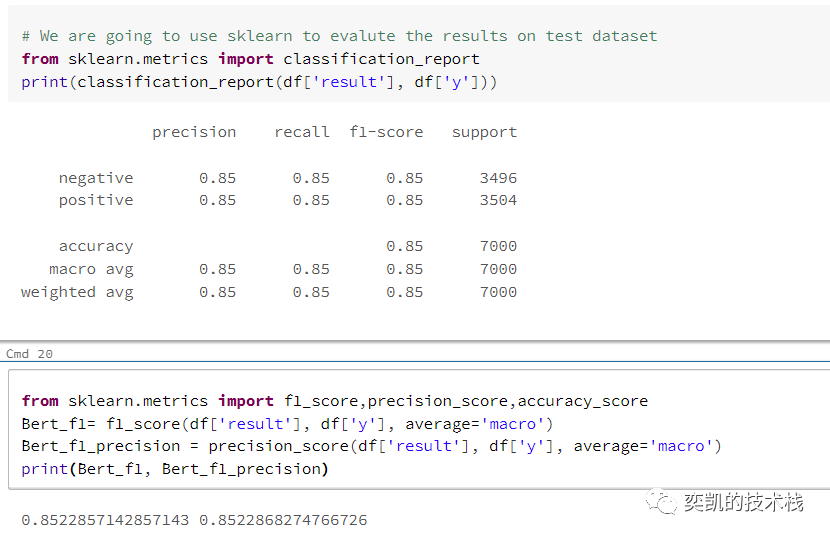
我们在没有进行任何超参数的微调并且只使用了整个数据集的4%,这个表现还是可以接受的。
DistilBert进行知识蒸馏
我们的下一步我们在管道中加入DistilBert进行知识蒸馏
from pyspark.ml import Pipelinefrom sparknlp.annotator import *from sparknlp.common import *from sparknlp.base import *
document = DocumentAssembler()\ .setInputCol("text")\ .setOutputCol("document")embeddings = DistilBertEmbeddings.pretrained("distilbert_base_multilingual_cased", "xx") \ .setInputCols("document", "token") \ .setOutputCol("embeddings")tokenizer = Tokenizer() \ .setInputCols(["document"]) \ .setOutputCol("token")classifierDl = ClassifierDLApproach()\ .setInputCols(["sentence_embeddings"])\ .setOutputCol("class")\ .setLabelColumn("y")\ .setMaxEpochs(125)\ .setLr(0.0007) \ .setEnableOutputLogs(True)\ .setOutputLogsPath('/Classifier_logs_DistilBERT')embeddingsSentence = SentenceEmbeddings() \ .setInputCols(["document", "embeddings"]) \ .setOutputCol("sentence_embeddings") \ .setPoolingStrategy("AVERAGE")pipeline = Pipeline( stages = [ document, tokenizer, embeddings , embeddingsSentence, classifierDl ])
继续训练模型,看看效果
mutli_lingual_model_Distil_Bert = pipeline.fit(train_df)
还是需要复制文件:
dbutils.fs.cp("/Classifier_logs_DistilBERT", 'file:/Classifier_logs_DistilBERT/',True)
import os
log_files = os.listdir("/Classifier_logs_DistilBERT")
读取日志文件看看效果吧
可视化指标
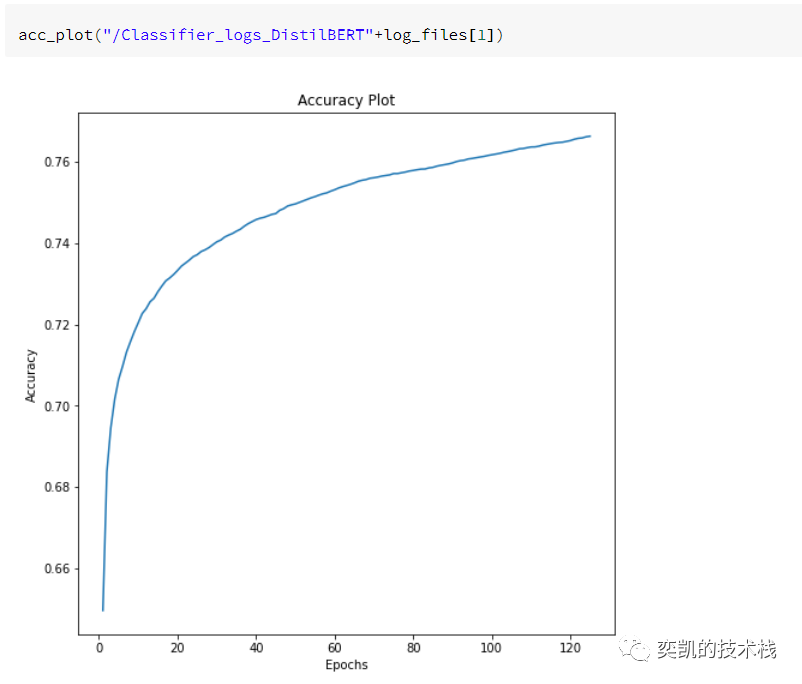
损失:
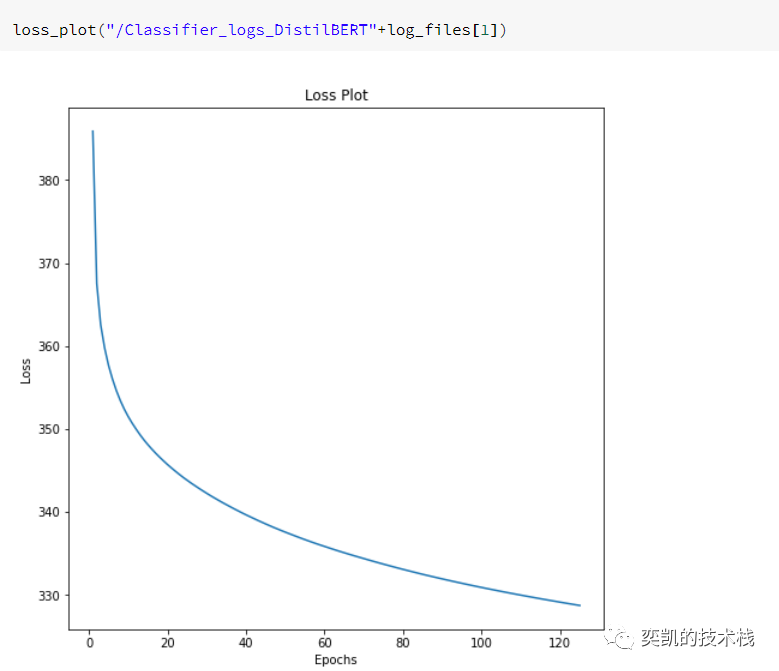
看起来不错的!让我们看看它在测试数据上的表现
还是需要转换成pandas并使用sklearn查看效果
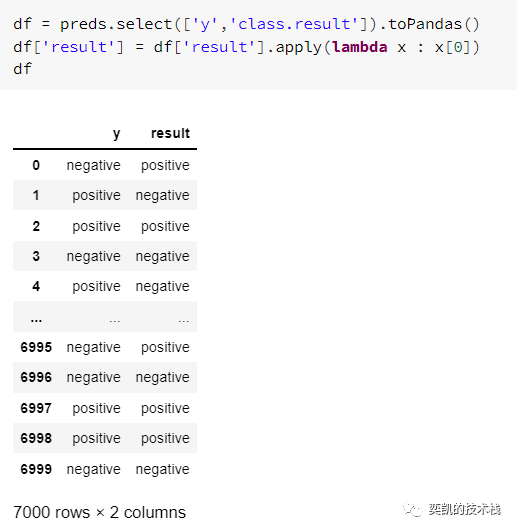
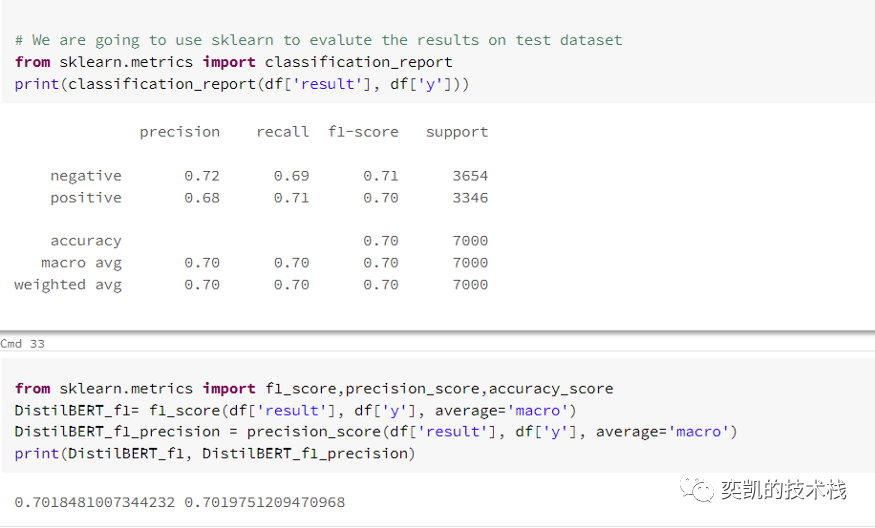
注:这里表现不好其实是因为还没有完全拟合,通过曲线我们可以看到,准确率和损失都可以再继续训练。
Xlm-Roberta模型
我们的下一个嵌入是XLM-Roberta。
from pyspark.ml import Pipelinefrom sparknlp.annotator import *from sparknlp.common import *from sparknlp.base import *
document = DocumentAssembler()\ .setInputCol("text")\ .setOutputCol("document")sent_embeddings = XlmRoBertaSentenceEmbeddings.pretrained("sent_xlm_roberta_base", "xx") \ .setInputCols("document") \ .setOutputCol("sentence_embeddings")classifierDl = ClassifierDLApproach()\ .setInputCols(["sentence_embeddings"])\ .setOutputCol("class")\ .setLabelColumn("y")\ .setMaxEpochs(125)\ .setLr(0.0007) \ .setEnableOutputLogs(True)\ .setOutputLogsPath('/Classifier_logs_XLM_Roberta')pipeline = Pipeline( stages = [document, sent_embeddings, classifierDl ])
除了嵌入以外,其他都不需要修改,为了省略,这里我们直接看结果
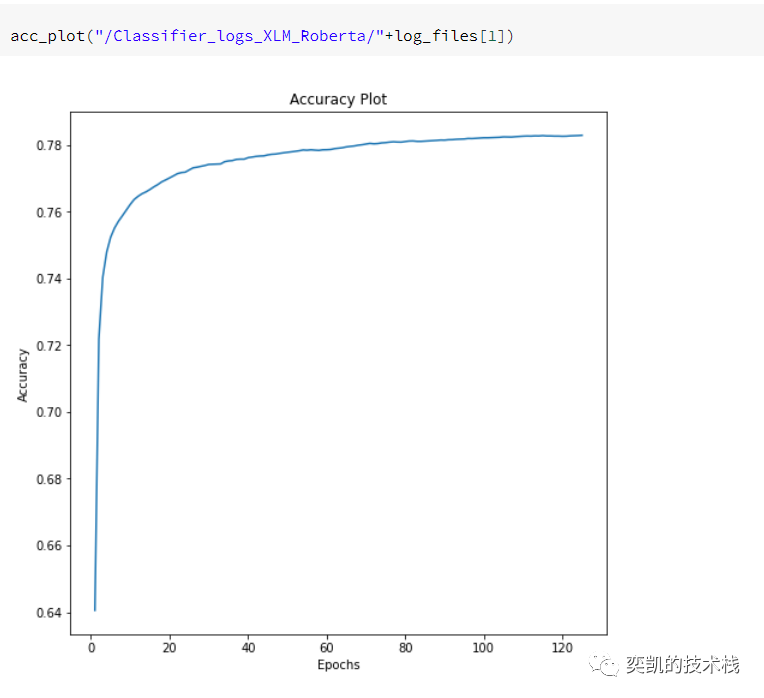
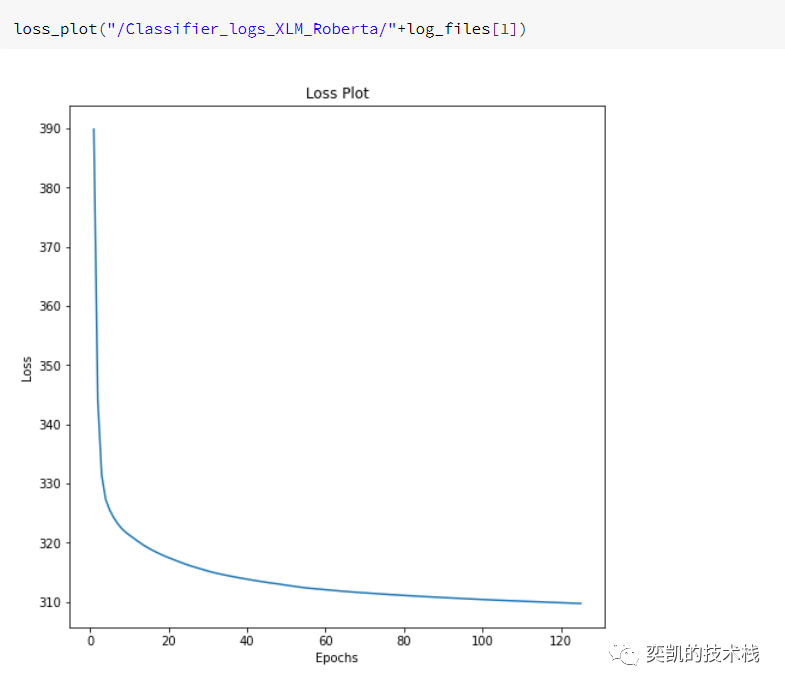
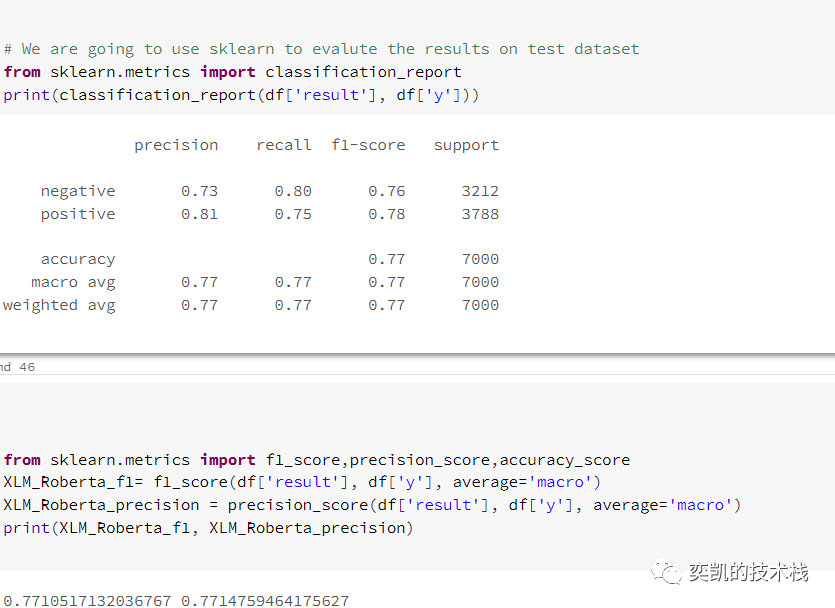
性能对比
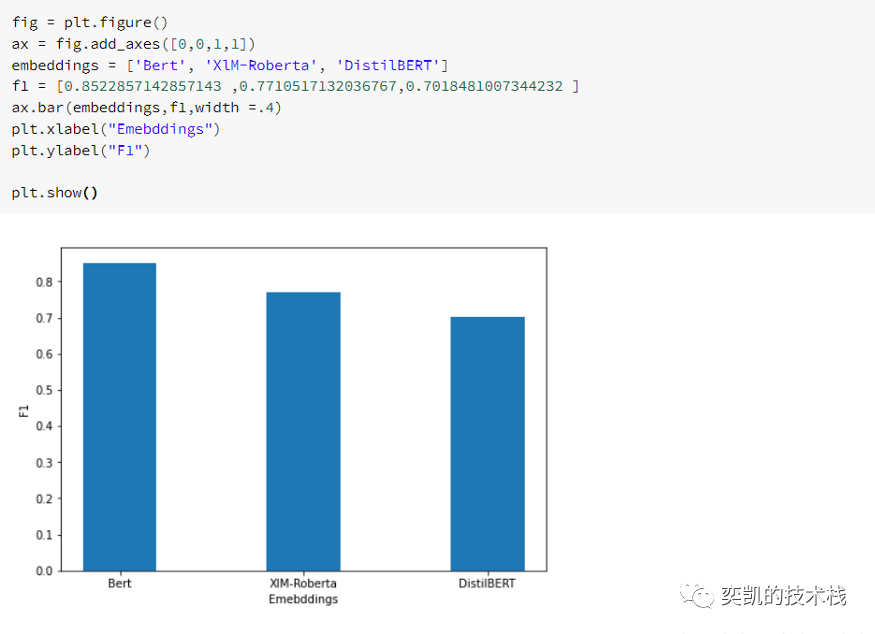
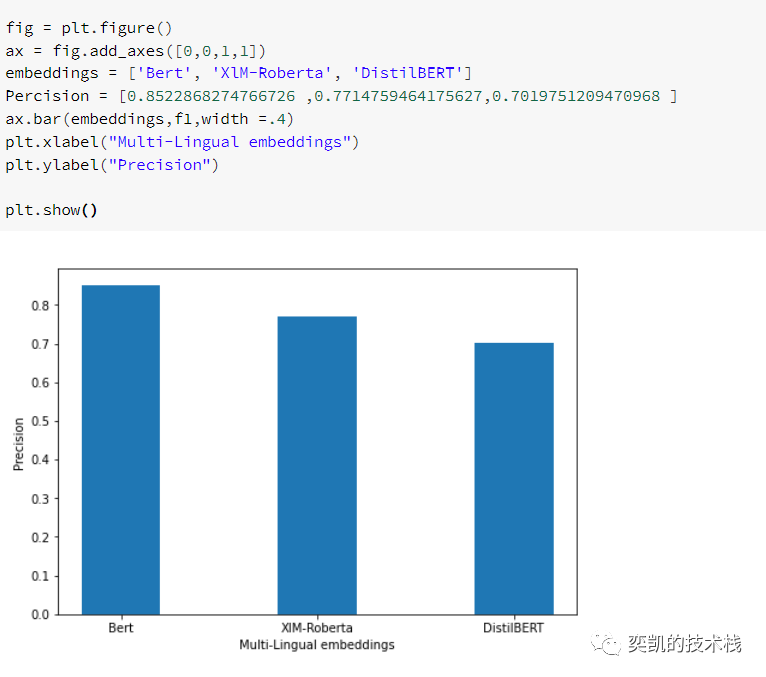
依然是bert最好。
保存和加载模型
训练完成后可以保存模型
mutli_lingual_model.stages[-1].write().overwrite().save('/content/tmp_multi_classifierDL_model')
在其他的地方也可以对保存的模型进行加载。
from pyspark.ml import Pipelinefrom sparknlp.annotator import *from sparknlp.common import *from sparknlp.base import *from pyspark.sql import SparkSession
document = DocumentAssembler()\ .setInputCol("text")\ .setOutputCol("document")sent_embeddings = BertSentenceEmbeddings.pretrained("sent_bert_use_cmlm_multi_base_br", "xx") \ .setInputCols("document") \ .setOutputCol("sentence_embeddings")classifierDl = ClassifierDLModel.load('/content/tmp_multi_classifierDL_model')\ .setInputCols(["sentence_embeddings"])\ .setOutputCol("class")pipeline = Pipeline( stages = [document, sent_embeddings, classifierDl ])empty_df = spark.createDataFrame([['']]).toDF('text')mutli_lingual_model = pipeline.fit(empty_df)
mutli_lingual_model = LightPipeline(mutli_lingual_model)
在推理时可以使用LightPipeline,因为推理预测的时候数据量都比较的少,但在大数据训练方面,常规管道的表现要比它好。
用一些例句进行模型测试
在重新加载模型之后,我们将用一些例句来测试它
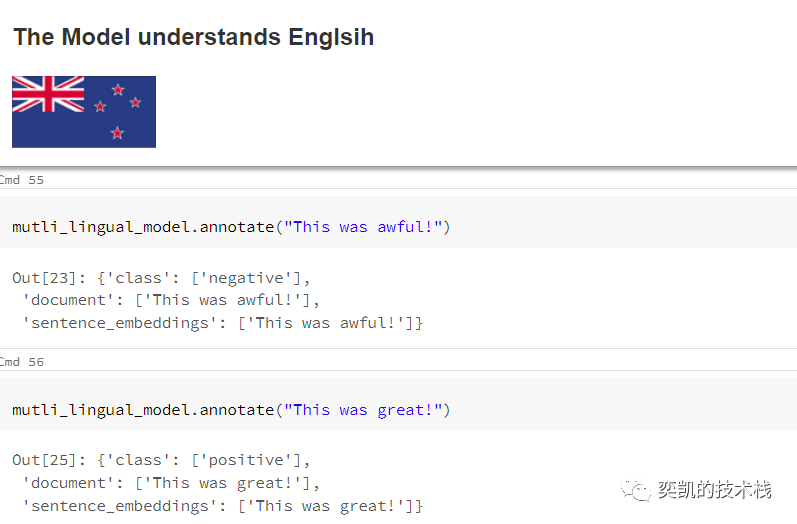
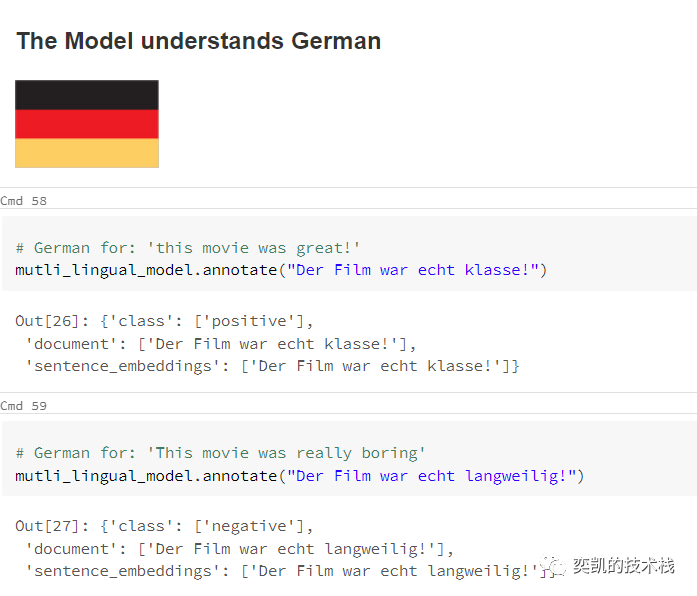
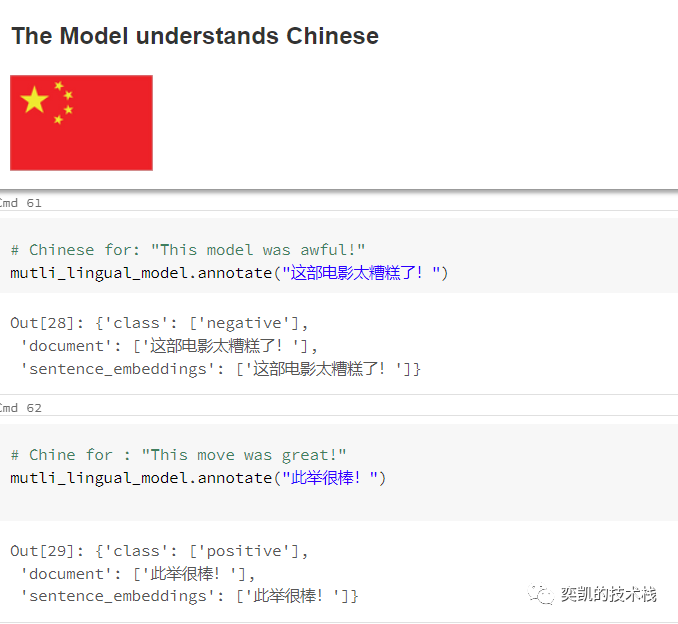
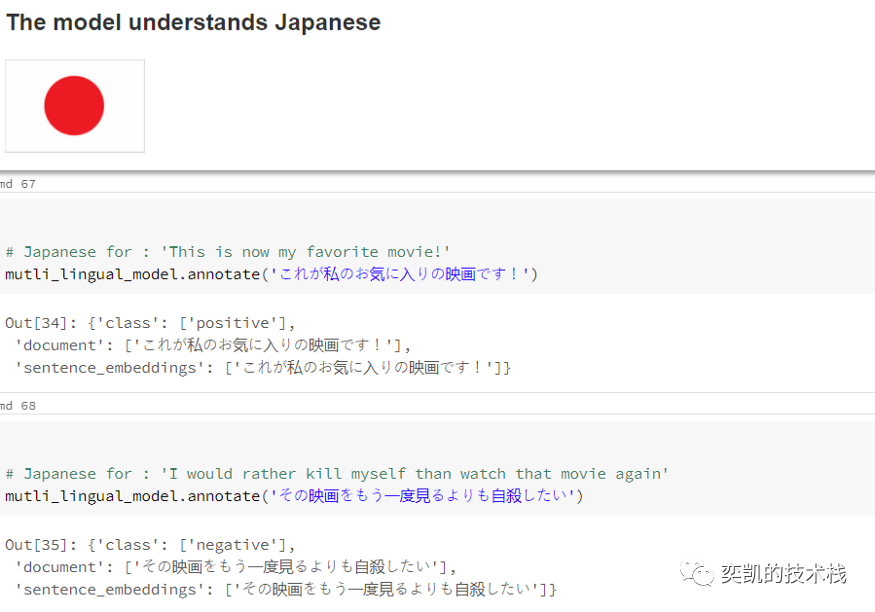
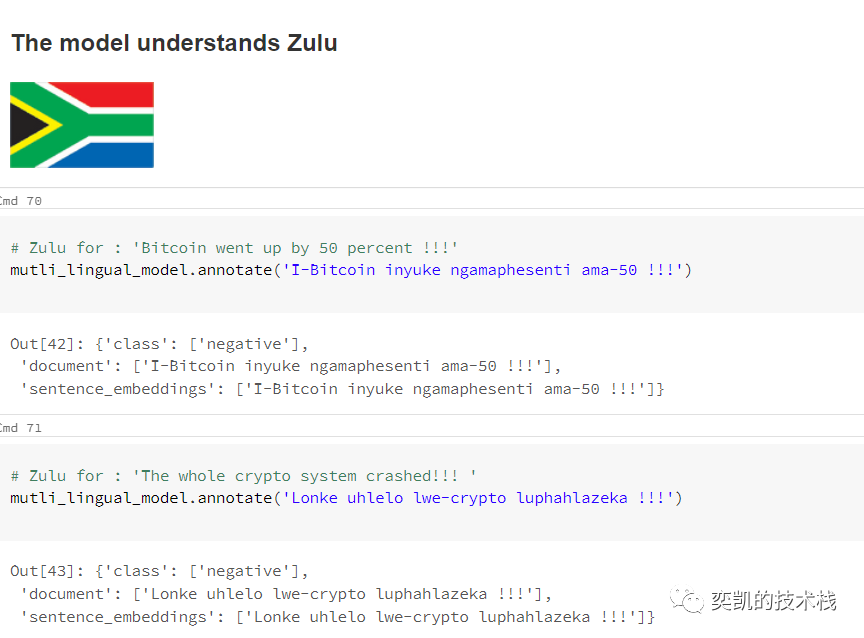
效果还不错。
最后如果你想看Scala的代码,看看这个链接吧:
spark NLP :https://www.johnsnowlabs.com/spark-nlp
作者github:https://github.com/ahmedlone127/