
1. java安装
1 下载Java的jre包(jdk-8u301-windows-x64.exe),exe安装即可。
2 安装到D:\软件\java目录下(安装上级目录尽量不能有空格)。安装目录可以自己调整。按提示可以不安装jre环境,java目录下有jre目录。

3 安装完成后,电脑右键—属性—高级属性—高级—环境变量。

4 添加JAVA_HOME的环境变量,定义java安装路径变量,便于以后引用。
变量名:JAVA_HOME
变量值:D:\软件\java(自己自安装路径)

5 增加PATH环境变量,设置永久Path变量,运行java命令式,可以省去写java多的完整安装路径。
变量名:path
变量值:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;

6 命令行提示符验证

2. 安装eclipse
解压eclipse安装包

双击运行eclipse.exe启动程序。

若系统中只有一个java版本,eclipse会默认直接引用系统java。也可以通过以下方式方式进行查看对应版本信息。


3. 解压hadoop
自己电脑安装hadoop是为了从eclipse上连接服务端集群(Run on hadoop),不使用本地集群,因此hadoop工具解压之后,我们不作任何操作。
将工具hadoop-2.7.7.tar解压至java同目录下即可。

新增hadoop路径写入环境变量。
变量名:HADOOP_HOME
变量值:D:\软件\hadoop-2.7.7

更新Path环境变量
变量名:path
变量值:%HADOOP_HOME%\bin;

cmd验证Hadoop,有相关参数提示表示安装成功。

下载地址:
mirrors / cdarlint / winutils · GitCodewinutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows 🚀 Github 镜像仓库 🚀 源项目地址 https://gitcode.net/mirrors/cdarlint/winutils?utm_source=csdn_github_accelerator
Windows系统下安装hadoop,对比mac和linux下安装,还需要多进行如下一步,将hadoop.dll和winutils.exe拷贝到 C:\Windows\System32。
同时也可以将winutils.exe,hadoop.dll拷贝一份至Hadoop安装包的bin目录下。
> Windows本地运行mr程序时(不提交到yarn,运行在jvm靠线程执行),hadoop.dll防止报nativeio异常、winutils.exe没有的话报空指针异常。

4. 安装eclipse上hadoop插件
将插件hadoop-eclipse-plugin-2.7.7.jar(插件和版本有关),放置eclipse路径下的plugins(插件目录)下,也可以放在dropins目录下(也是管理插件的文件)。
插件提供对应的附加功能。

重新开启eclipse,依次点击Windows->Preferences,可以看到已经有了Hadoop
Map/Reduce,设置hadoop对应的安装⽬录(以实际路径为准)

**5.**开启相关属性和视图
打开Windows->Perspective->Open Perspective-> Other 中的Map/Reduce,在此perspective下进⾏hadoop程序开发。


打开Windows->Show View->Other -> MapReduce Tools中的Map/Reduce Locations,添加Hadoop视图。

至此,相关工具及插件安装完成,同时相关配置已经打开。
**6.**创建项目,连接hadoop集群并运行程序
1)项目命名标准
1、 项目名全部小写
2、 包名全部小写
3、 类名首字母大写,如果类名由多个单词组成,每个单词的首字母都要大写。
4、 变量名、方法名首字母小写,如果名称由多个单词组成,每个单词的首字母都要大写。
2)hosts文件添加映射
操作系统(Windows)中添加主机映射。

添加如下配置:

同时虚拟主机(hadoop主机)上hosts文件也需要添加主机名(使用内容IP)。

3)开启Hadoop集群确保集群无问题
格式化集群并开启集群
格式化:hadoop namenode -format
启动集群:start-all.sh
方式一:查看集群进程
# 命令
jps

方式二:查看Hadoop HDFS UI界面(注意记得关闭iptables防火墙)

方式三:查看集群状态
# 命令
hdfs dfsadmin -report

4)创建项目
创建一个MapReduce项目,依次点击File-New-Project…

也可以通过便捷方式直接创建项目,选择”Map/Reduce Project”。

命名项目名称WordCount

创建好项目之后,依次创建包名和类文件。

然后就可以编写程序进行操作了。此时代码是对Hadoop HDFS上的数据进行分析,同时结果也会保存在HDFS上。对于HDFS上的数据,可以借助之前的Map/Reduce Locations (Hadoop 视图)直接进行可视化展示。
创建项目之后,可以在左侧查看DFS Localtions,它会同步显示HDFS下的文件,下面先创建一个localtion连接hadoop集群。
右键选择New Hadoop location…新建hadoop连接。

创建之后,可以在左侧工具栏查看,此时eclipse连接虚拟机hadoop时显示HDFS下文件内容。

同时也可以虚拟机终端中查看文件信息:hdfs dfs -ls /

HDFS上创建文件夹,并上传数据。

刷新DFS Localtions,可以看到数据已经上传。

5)编写程序进行wordcount
添加自己包和java类



 文件名后的java自动生成。
文件名后的java自动生成。
程序1:WordCountMapper.java
package com.qingjiao.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* Map阶段的业务逻辑需写在自定义的map()方法中
* MapTask会对每一行输入数据调用一次我们自定义的map()方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//(1)将MapTask传给我们的一行文本内容先转换成String
String line = value.toString();
//(2)根据空格将这一行切分成单词
String[] words = line.split(" ");
//(3)将单词输出为<单词,1>
for (String word : words) {
//将单词作为key,将次数1作为value,以便后续的数据分发,可以根据单词分发,将相同单词分发到同一个ReduceTask中
context.write(new Text(word), new IntWritable(1));
}
}
}
程序2:WordCountReducer.java
package com.qingjiao.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 首先,和前面一样,Reducer类也有输入和输出,输入就是Map阶段的处理结果,输出就是Reduce最后的输出即KEYIN,VALUEIN 对应 Mapper 输出的 KEYOUT,VALUEOUT
* KEYOUT,VALUEOUT是自定义Reduce逻辑处理结果的输出数据类型(KEYOUT:单词 VALUEOUT:总次数)
*
* ReduceTask在调我们写的reduce方法,ReduceTask应该收到了前一阶段(Map阶段)中所有MapTask输出的数据中的一部分
* (数据的key.hashcode%ReduceTask数==本ReduceTask号),所以ReduceTask的输入类型必须和MapTask的输出类型一样
*
* ReduceTask将这些收到kv数据拿来处理时,是这样调用我们的reduce方法的: 先将自己收到的所有的kv对按照k分组(根据k是否相同)
* 将某一组kv中的第一个kv中的k传给reduce方法的key变量,把这一组kv中所有的v用一个迭代器传给reduce方法的变量values
*
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* <Deer,1><Deer,1><Deer,1><Deer,1><Deer,1>
* <Car,1><Car,1><Car,1><Car,1>
* 框架在Map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,values{}>,调用一次reduce()方法
* <Deer,{1,1,1,1,1,1.....}>
* 入参key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//做每个单词的结果汇总
int sum = 0;
for (IntWritable v : values) {
sum += v.get();
}
//写出最后的结果
context.write(key, new IntWritable(sum));
}
}
程序3:WordCount.java
package com.qingjiao.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
/**
* 该MR程序运行的入口,相当于yarn集群(分配运算资源)的客户端,需要在此封装MR程序的相关运行参数,指定jar包,最后提交给yarn
*
* 其中用一个Job类对象来管理程序运行时所需要的很多参数: 比如,指定哪个类作为map阶段的业务逻辑类,哪个类作为reduce阶段的业务逻辑类;
* 指定wordcount job程序的jar包所在路径...以及其他各种需要的参数。
*/
public static void main(String[] args) throws Exception {
// (1)创建配置文件对象
// System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
// conf.set("mapreduce.framework.name", "local");
// 设置客户端访问datanode使用hostname来进行访问
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("fs.defaultFS", "hdfs://master:9000");
// (2)新建一个 job 任务
Job job = Job.getInstance(conf);
// (3)将 job 所用到的那些类(class)文件,打成jar包 (打成jar包在集群运行必须写)
job.setJarByClass(WordCount.class);
// (4)指定 mapper 类和 reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// (5)指定 MapTask 的输出key-value类型(可以省略)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// (6)指定 ReduceTask 的输出key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// (7)指定该 mapreduce 程序数据的输入和输出路径
Path inPath=new Path("/input/");
Path outpath=new Path("/output/");
// 获取 fs 对象
FileSystem fs=FileSystem.get(conf);
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileInputFormat.setInputPaths(job,inPath);
FileOutputFormat.setOutputPath(job, outpath);
// (8)最后给YARN来运行,等着集群运行完成返回反馈信息,客户端退出
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
}
}

6)配置⽂件log4j.properties
打印出在linux下hadoop的⽇志信息,便于差错,进⾏代码修改,在项⽬的src⽬录下,新建⼀个⽂件new->other->general->file,命名为“log4j.properties”即可。
log4j.rootLogger=INFO, <ins>stdout</ins>
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
7)运行程序查看结果
运行程序,主程序文件中右键,选择Run As --Run on Hadoop。

程序正确运行,控制栏进行日志打印。
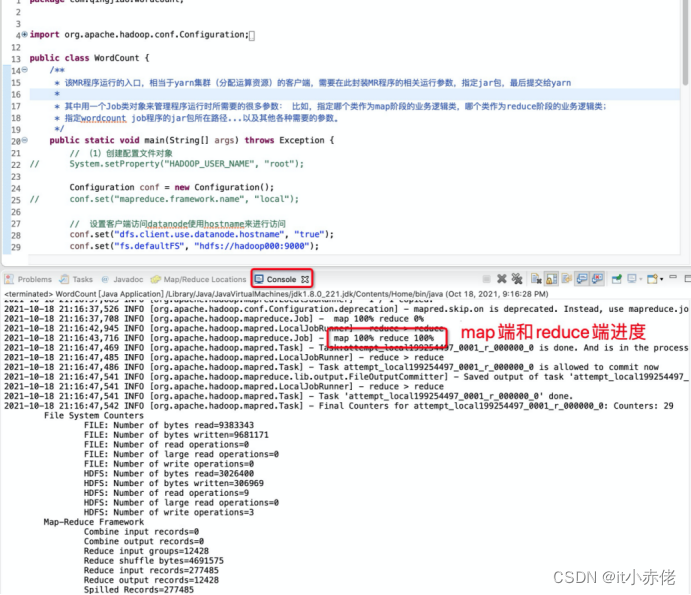
视图中查看分析结果。


8)运行时报错
报错1:
"D:\软件\hadoop-2.7.7\bin\winutils.exe": CreateProcess error=1392, 文件或目录损坏且无法读取。
解决方法:
下载对应版本winutils.exe文件放在D:\软件\hadoop-2.7.7\bin目录下
报错2:
org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRI
解决方法:
如果是Windows用户,在hdfs namenode所在机器添加新用户,用户名为执行操作的Windows用户名,然后将此用户添加到supergroup用户组。
adduser Administrator
groupadd supergroup
usermod -a -G supergroup Administrator
报错3:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Wi
解决方法:
下载对应版本hadoop.dll文件放在D:\软件\hadoop-2.7.7\bin目录下
版权归原作者 it小赤佬 所有, 如有侵权,请联系我们删除。