
深度学习模型调参笔记
train loss 下降,val loss下降,说明网络仍在学习; 奈斯,继续训练
train loss 下降,val loss上升,说明网络开始过拟合了;赶紧停止,然后数据增强、正则
train loss 不变,val loss不变,说明学习遇到瓶颈;调小学习率或批量数目
train loss 不变,val loss下降,说明数据集100%有问题;检查数据集标注有没有问题
train loss 上升,val loss上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
loss震荡?
轻微震荡一般是正常的,在一定范围内,一般来说 Batch Size 越大,其确定的下降方向越准,引起训练震荡越小,如果震荡十分剧烈,那估计是Batch Size设置的太小了吧
欠拟合
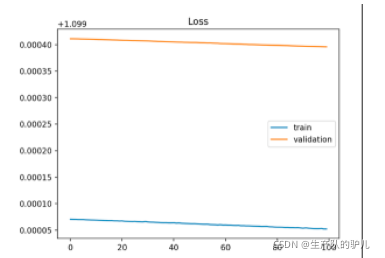
模型对训练集的学习能力不够
train loss下降的非常平缓,以至于似乎并没有下降,这说明模型根本没从数据中学到东西。

training loss还在继续下降,这说明还有学习空间,模型还没来得及学就结束了。
欠拟合原因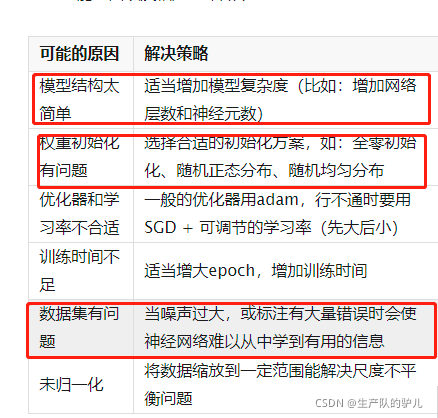
过拟合
模型学过头了,以至于把一些噪声和随机波动也学进来了。
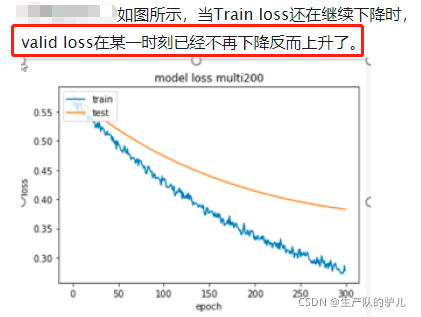

完美拟合
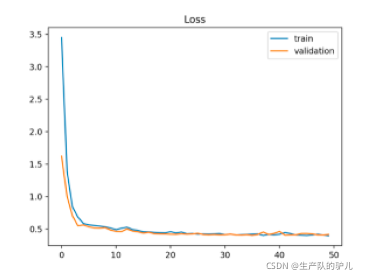
loss曲线可视化
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train','validation'], loc='upper left')
plt.show()
神经网络优化算法的发展
SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam
SGD:没有用到二阶动量,因此学习率是恒定的(实际使用过程中,会采用学习率衰减策略);
AdaGrad:学习率不断递减,最终收敛到0,模型也得以收敛。
Adam:二阶动量是固定时间窗口内的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得学习率可能时大时小,不是单调变化,这就可能在训练后期引起学习率的震荡,导致模型无法收敛。
Adam 和 SGD 对比 建议:
前期用Adam,享受Adam快速收敛的优势;后期用SGD,慢慢寻找最优解。
dam等自适应学习率算法:对于稀疏数据具有优势,且收敛速度很快;
SGD:虽然收敛速度不及Adam快,但是精调参数的SGD往往能取得更好的最终结果;
对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
激活函数
激励函数相当于一个过滤器或激励器,它把特有的信息或特征激活。
常见的激活函数包括softplus、sigmoid、relu、softmax、elu、tanh等。
隐藏层:
对于隐藏层,使用relu、tanh、softplus等 非线性关系
分类问题:
使用sigmoid(值越小越接近于0,值越大越接近于1)、softmax函数
对每个类求概率,最后以最大的概率作为结果;
回归问题:
使用线性函数(linear function)
版权归原作者 生产队的驴儿 所有, 如有侵权,请联系我们删除。