
BP神经网络主要用于预测和分类,对于大样本的数据,BP神经网络的预测效果较佳,BP神经网络包括输入层、输出层和隐含层三层,通过划分训练集和测试集可以完成模型的训练和预测,由于其简单的结构,可调整的参数多,训练算法也多,而且可操作性好,BP神经网络获得了非常广泛的应用,但是也存在着一些缺陷,例如学习收敛速度太慢、不能保证收敛到全局最小点、网络结构不易确定。另外,网络结构、初始连接权值和阈值的选择对网络训练的影响很大,但是又无法准确获得,针对这些特点可以采用遗传算法或粒子群算法等对神经网络进行优化。
一、pso+bp预测2022年勇士和凯尔特人夺冠情况
1.1、数据准备
训练集的输入数据和输出数据,如下一共36*14的数据,前面18行是勇士队的训练数据,其中前13列是输入,最后一列是输出。后面的18行是凯尔特人的训练数据,其中前13列是输入,最后一列是输出.
14列数据,一共13个输入指标和1个输出指标。
输入指标:
1.季后赛球队场均投篮命中率 2.季后赛球队场均3分命中率
3.季后赛球队场均罚篮命中率 4.季后赛球队场均得分
5.季后赛球队场均篮板 6.季后赛球队场均助攻
7.季后赛球队场均抢断 8.季后赛球队场均盖帽
9.季后赛球队场均进攻篮板率 10.季后赛球队场均防守篮板率
11.季后赛球队场均失误率 12.球星数量
13.去年是否进入总决赛
输出指标:是否夺冠
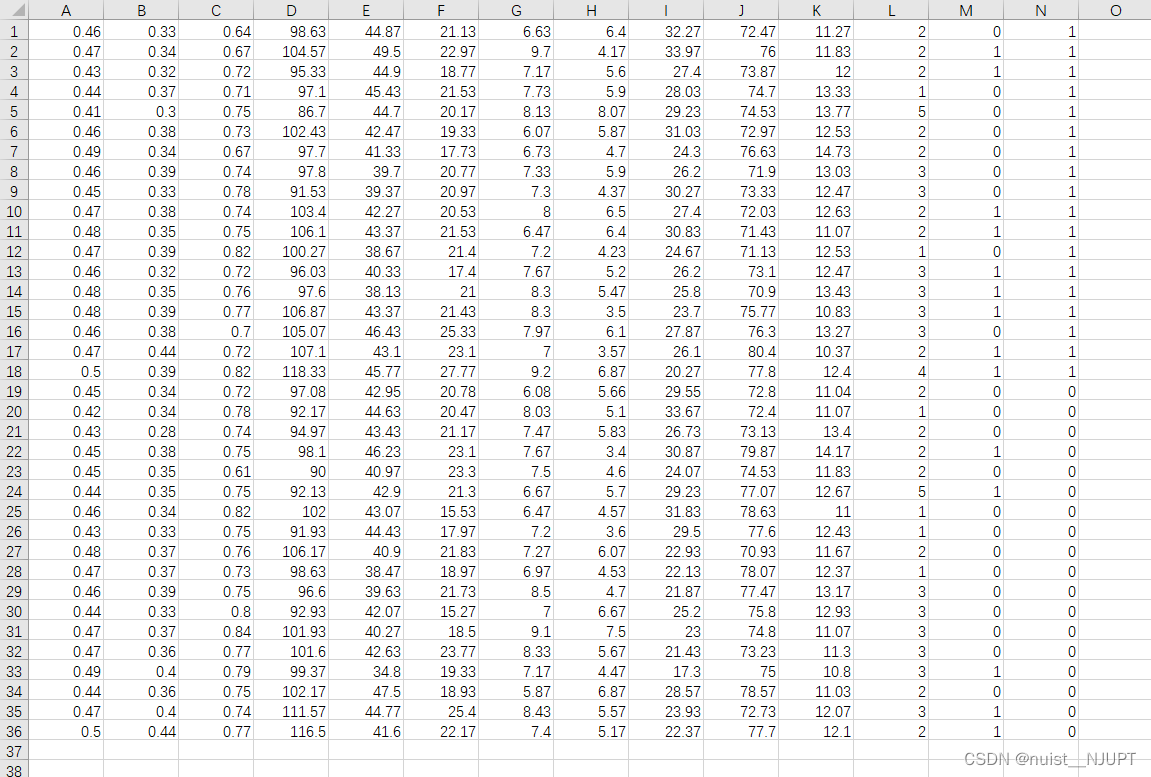
下面8*14的数据分别是勇士和凯尔特人的测试数据,前4行勇士,后四行凯尔特人。

下面2*13的数据是今年勇士和凯尔特人的季后赛数据,用于预测今年的夺冠情况。

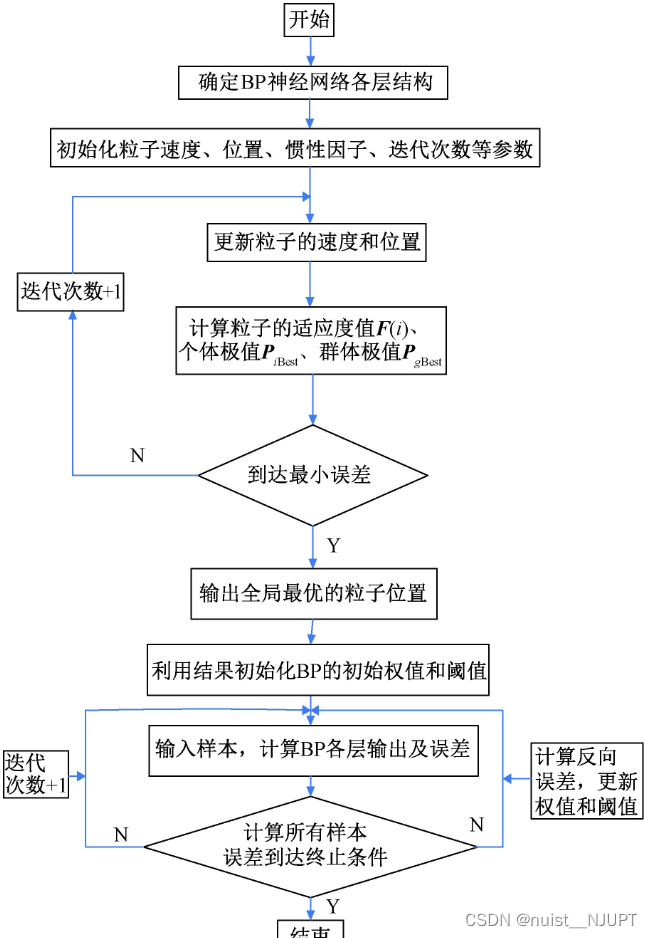
1.2、粒子群优化BP神经网络流程图
我们看一下粒子群优化BP神经网路的流程图,本质上就是用粒子群算法确定BP神经网络初始的权值和阈值,适应度函数(目标函数)是BP神经网络的预测的误差,根据适应度函数,粒子群算法寻找最优的位置,进而去初始化最优的BP权值和阈值。
1.3、BP神经网络和粒子群参数设置
假设我们构建的Bp神经网络为3层网络,则Bp神经网络中需要优化的参数实际上包含4部分:输入层到隐含层的权值、隐层神经元阈值、隐含层到输出层的权值、输出层阈值。

对于粒子群的目标函数的选取,即适应度函数,我们使用BP神经网络的误差范数来衡量,在当前权值和阈值下,Bp神经网络的预测性能怎么样,这里我们使用误差范数n o r m ( T s i m − T t e s t ) 来表示,范数越小说明预测得越准确,如果范数为0,说明预测得完全准确。
对于粒子群算法,我们需要不停地更新粒子的速度和位置,选取代入适应度函数内最合适的权值和阈值,具体的速度和位置更新公式如下:

1.4、pso+bp的完整MATLAB代码
PSO+bp的代码如下:
%% 基于PSO的Bp神经网络预测2022赛季NBA总冠军
clc;
clear;
tic
close all;
%% 加载神经网络的训练样本 测试样本每列一个样本 输入P 输出T
load('basket.mat')%加载数据
P = trains(:,1:end-1) ;%训练集输入
T = trains(:,end) ;%训练集输出
P_test = tests(:,1:end-1) ;%测试集输入
T_test = tests(:,end) ;%测试集输出
cur_season = pred ;%待预测的数据,今年NBA季后赛数据,第1行为勇士队数据,第2行为凯尔特人队数据
inputnum=size(P,2); %输入层神经元个数
hiddennum=2*inputnum+1; %初始隐层神经元个数
outputnum=size(T,2); %输出层神经元个数
w1num=inputnum*hiddennum; %输入层到隐层的权值个数
w2num=outputnum*hiddennum; %隐层到输出层的权值个数
N=w1num+hiddennum+w2num+outputnum; %待优化的变量的个数
%% 定义粒子群优化算法参数
nVar=N; %变量数目
VarSize=[1,nVar]; %变量矩阵大小
VarMin=-0.5; %变量取值下限
VarMax=0.5; %变量取值上限
MaxIt=200; %最大迭代次数
nPop=40; %种群数目
w=1; %惯性权重
wdamp=0.99; %惯性重量降低系数
c1=1.5; %个体学习系数
c2=2.0; %群体学习系数
VelMax=0.1*(VarMax-VarMin); %速度上限
VelMin=-VelMax; %速度下限
%% 初始化
empty_particle.Position=[];
empty_particle.Cost=[];
empty_particle.Velocity=[];
empty_particle.Best.Position=[];
empty_particle.Best.Cost=[];
particle=repmat(empty_particle,nPop,1);
GlobalBest.Cost=inf;
for i=1:nPop
%初始化位置
particle(i).Position=unifrnd(VarMin,VarMax,VarSize);
%初始化速度
particle(i).Velocity=zeros(VarSize);
%个体评价
particle(i).Cost=BpFunction(particle(i).Position,P,T,hiddennum,P_test,T_test);
%更新个体最优
particle(i).Best.Position=particle(i).Position;
particle(i).Best.Cost=particle(i).Cost;
%更新群体最优
if particle(i).Best.Cost<GlobalBest.Cost
GlobalBest=particle(i).Best;
end
end
BestCost=zeros(MaxIt,1);
%% 主循环
for it=1:MaxIt
for i=1:nPop
%更新速度
particle(i).Velocity = w*particle(i).Velocity ...
+c1*rand(VarSize).*(particle(i).Best.Position-particle(i).Position) ...
+c2*rand(VarSize).*(GlobalBest.Position-particle(i).Position);
%对超出范围的速度进行调整
particle(i).Velocity = max(particle(i).Velocity,VelMin);
particle(i).Velocity = min(particle(i).Velocity,VelMax);
%更新位置
particle(i).Position = particle(i).Position + particle(i).Velocity;
%对超出位置范围的速度进行调整
IsOutside=(particle(i).Position<VarMin | particle(i).Position>VarMax);
particle(i).Velocity(IsOutside)=-particle(i).Velocity(IsOutside);
%对超出范围的位置进行调整
particle(i).Position = max(particle(i).Position,VarMin);
particle(i).Position = min(particle(i).Position,VarMax);
%种群评估
particle(i).Cost=BpFunction(particle(i).Position,P,T,hiddennum,P_test,T_test);
%更新个体最优
if particle(i).Cost<particle(i).Best.Cost
particle(i).Best.Position=particle(i).Position;
particle(i).Best.Cost=particle(i).Cost;
%更新群体最优
if particle(i).Best.Cost<GlobalBest.Cost
GlobalBest=particle(i).Best;
end
end
end
BestCost(it)=GlobalBest.Cost;
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCost(it))]);
w=w*wdamp;
end
BestSol=GlobalBest;
%% Results
figure;
%plot(BestCost,'LineWidth',2);
semilogy(BestCost,'LineWidth',2);
xlabel('迭代次数')
ylabel('误差的变化')
title('进化过程')
grid on;
fprintf(['最优初始权值和阈值:\n=',num2str(BestSol.Position),'\n最小误差=',num2str(BestSol.Cost),'\n'])
%% 预测今年总冠军概率
cur_test=zeros(size(cur_season,1),1);
[~,bestCur_sim]=BpFunction(BestSol.Position,P,T,hiddennum,cur_season,cur_test);
prob=softmax(bestCur_sim);
disp(['勇士队获得2022年NBA总冠军概率为',num2str(prob(1))]);
disp(['凯尔特人队获得2022年NBA总冠军概率为',num2str(prob(2))]);
toc
BP的函数如下,用于计算误差范数,更新权值和阈值:
%% 输入
% x:一个个体的初始权值和阈值
% P:训练样本输入
% T:训练样本输出
% hiddennum:隐含层神经元数
% P_test:测试样本输入
% T_test:测试样本期望输出
%% 输出
% err:预测样本的预测误差的范数
function [err,T_sim]=BpFunction(x,P,T,hiddennum,P_test,T_test)
inputnum=size(P,2); %输入层神经元个数
outputnum=size(T,2); %输出层神经元个数
%% 数据归一化
[p_train,ps_train]=mapminmax(P',0,1);
p_test=mapminmax('apply',P_test',ps_train);
[t_train,ps_output]=mapminmax(T',0,1);
%% 开始构建BP网络
net=newff(p_train,t_train,hiddennum); %隐含层为hiddennum个神经元
%设定参数网络参数
net.trainParam.epochs=1000;
net.trainParam.goal=1e-3;
net.trainParam.lr=0.01;
net.trainParam.showwindow=false; %高版MATLAB使用 不显示图形框
%% BP神经网络初始权值和阈值
w1num=inputnum*hiddennum; %输入层到隐层的权值个数
w2num=outputnum*hiddennum; %隐含层到输出层的权值个数
W1=x(1:w1num); %初始输入层到隐含层的权值
B1=x(w1num+1:w1num+hiddennum); %隐层神经元阈值
W2=x(w1num+hiddennum+1:w1num+hiddennum+w2num); %隐含层到输出层的权值
B2=x(w1num+hiddennum+w2num+1:w1num+hiddennum+w2num+outputnum); %输出层阈值
net.iw{1,1}=reshape(W1,hiddennum,inputnum); %为神经网络的输入层到隐含层权值赋值
net.lw{2,1}=reshape(W2,outputnum,hiddennum); %为神经网络的隐含层到输出层权值赋值
net.b{1}=reshape(B1,hiddennum,1); %为神经网络的隐层神经元阈值赋值
net.b{2}=reshape(B2,outputnum,1); %为神经网络的输出层阈值赋值
%% 开始训练
net = train(net,p_train,t_train);
%% 测试网络
t_sim = sim(net,p_test);
T_sim1 = mapminmax('reverse',t_sim,ps_output); %反归一化
T_sim=T_sim1';
err=norm(T_sim-T_test); %预测结果与测试结果差的范数,范数越小说明预测得越准确,如果范数为0,说明预测得完全准确
index0= T_sim<0; %找到预测值小于0的索引
index1= T_sim>1; %找到预测值小于1的索引
penalty=1000*abs(sum(T_sim(index0)))+1000*sum(T_sim(index1)-1); %预测值小于0或大于1会有惩罚
err=err+penalty; %总误差
end
1.5、预测结果
通过预测结果可以发现整体来说随着迭代次数的增加,误差不断减少,最终预测出的结果是5-5开,不过勇气夺冠的概率稍微大于凯尔特人。


另外可以对上述代码进行优化,准确的说是对粒子群进行优化,使其在迭代次数内找到相对最好的值,上述用到是线性递减,我们这里用了自适应递减权重+收缩因子法,代码如下,其实优化的效果不明显。
%% 基于PSO的Bp神经网络预测2022赛季NBA总冠军
clc;
clear;
tic
close all;
%% 加载神经网络的训练样本 测试样本每列一个样本 输入P 输出T
load('basket.mat')%加载数据
P = trains(:,1:end-1) ;%训练集输入
T = trains(:,end) ;%训练集输出
P_test = tests(:,1:end-1) ;%测试集输入
T_test = tests(:,end) ;%测试集输出
cur_season = pred ;%待预测的数据,今年NBA季后赛数据,第1行为勇士队数据,第2行为凯尔特人队数据
inputnum=size(P,2); %输入层神经元个数
hiddennum=2*inputnum+1; %初始隐层神经元个数
outputnum=size(T,2); %输出层神经元个数
w1num=inputnum*hiddennum; %输入层到隐层的权值个数
w2num=outputnum*hiddennum; %隐层到输出层的权值个数
N=w1num+hiddennum+w2num+outputnum; %待优化的变量的个数
%% 定义粒子群优化算法参数
nVar=N; %变量数目
VarSize=[1,nVar]; %变量矩阵大小
VarMin=-0.5; %变量取值下限
VarMax=0.5; %变量取值上限
MaxIt=200; %最大迭代次数
nPop=40; %种群数目
w=0.9; %惯性权重
%wdamp=0.99; %惯性重量降低系数
c1=2.05; %个体学习系数
c2=2.05; %群体学习系数
VelMax=0.1*(VarMax-VarMin); %速度上限
VelMin=-VelMax; %速度下限
w_max = 0.9 ;
w_min = 0.4 ;
C = c1+c2;
fai = 2/abs((2-C-sqrt(C^2-4*C))); % 收缩因子
%% 初始化
empty_particle.Position=[];
empty_particle.Cost=[];
empty_particle.Velocity=[];
empty_particle.Best.Position=[];
empty_particle.Best.Cost=[];
particle=repmat(empty_particle,nPop,1);
GlobalBest.Cost=inf;
for i=1:nPop
%初始化位置
particle(i).Position=unifrnd(VarMin,VarMax,VarSize);
%初始化速度
particle(i).Velocity=zeros(VarSize);
%个体评价
particle(i).Cost=BpFunction(particle(i).Position,P,T,hiddennum,P_test,T_test);
%更新个体最优
particle(i).Best.Position=particle(i).Position;
particle(i).Best.Cost=particle(i).Cost;
%更新群体最优
if particle(i).Best.Cost<GlobalBest.Cost
GlobalBest=particle(i).Best;
end
end
BestCost=zeros(MaxIt,1);
%% 主循环
for it=1:MaxIt
for i=1:nPop
%更新速度
particle(i).Velocity = fai * (w*particle(i).Velocity ...
+c1*rand(VarSize).*(particle(i).Best.Position-particle(i).Position) ...
+c2*rand(VarSize).*(GlobalBest.Position-particle(i).Position));
%对超出范围的速度进行调整
particle(i).Velocity = max(particle(i).Velocity,VelMin);
particle(i).Velocity = min(particle(i).Velocity,VelMax);
%更新位置
particle(i).Position = particle(i).Position + particle(i).Velocity;
%对超出位置范围的速度进行调整
IsOutside=(particle(i).Position<VarMin | particle(i).Position>VarMax);
particle(i).Velocity(IsOutside)=-particle(i).Velocity(IsOutside);
%对超出范围的位置进行调整
particle(i).Position = max(particle(i).Position,VarMin);
particle(i).Position = min(particle(i).Position,VarMax);
%种群评估
particle(i).Cost=BpFunction(particle(i).Position,P,T,hiddennum,P_test,T_test);
%更新个体最优
if particle(i).Cost<particle(i).Best.Cost
particle(i).Best.Position=particle(i).Position;
particle(i).Best.Cost=particle(i).Cost;
%更新群体最优
if particle(i).Best.Cost<GlobalBest.Cost
GlobalBest=particle(i).Best;
end
end
end
BestCost(it)=GlobalBest.Cost;
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCost(it))]);
%自适应权重
f_i=particle(i).Cost; % 取出第i个粒子的适应度
s = 0 ;
f_min = particle(1).Best.Cost ;
for k = 1 : nPop
if f_min > particle(i).Best.Cost
fmin = particle(i).Best.Cost ;
s = s + particle(i).Best.Cost ;
end
end
f_avg = s/nPop; % 计算此时适应度的平均值
if f_i <= f_avg
if f_avg ~= f_min % 如果分母为0,我们就干脆令w=w_min
w = w_min + (w_max - w_min)*(f_i - f_min)/(f_avg - f_min);
else
w = w_min;
end
else
w = w_max;
end
%w=w*wdamp;
end
BestSol=GlobalBest;
%% Results
figure;
%plot(BestCost,'LineWidth',2);
semilogy(BestCost,'LineWidth',2);
xlabel('迭代次数')
ylabel('误差的变化')
title('进化过程')
grid on;
fprintf(['最优初始权值和阈值:\n=',num2str(BestSol.Position),'\n最小误差=',num2str(BestSol.Cost),'\n'])
%% 预测今年总冠军概率
cur_test=zeros(size(cur_season,1),1);
[~,bestCur_sim]=BpFunction(BestSol.Position,P,T,hiddennum,cur_season,cur_test);
prob=softmax(bestCur_sim);
disp(['勇士队获得2022年NBA总冠军概率为',num2str(prob(1))]);
disp(['凯尔特人队获得2022年NBA总冠军概率为',num2str(prob(2))]);
toc
1.6、小结
对于粒子群+bp的算法还有很多需要优化的,特别是对于粒子群的优化方法有很多,比如对权重系数w和学习因子c的优化等,这次主要是讲了一个思想,就是粒子群全局寻优去初始化bp神经网络的初始权值阈值,提高预测准确率。
版权归原作者 nuist__NJUPT 所有, 如有侵权,请联系我们删除。