
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯**基于知识图谱的垂直领域电影知识查询问答系统**
课题背景和意义
随着互联网技术的普及和电影产业的发展,用户对于电影信息的需求日益增长。然而,现有的电影信息检索系统往往无法满足用户对于深层次、细粒度电影知识的查询需求。基于知识图谱的垂直领域电影知识查询问答系统,结合了知识图谱和自然语言处理技术,为用户提供了一个深入、准确的电影知识查询平台,具有重要的实际应用价值和广阔的发展前景。此课题的研究对于推动知识图谱技术在电影领域的应用,提高电影知识查询的准确性和深度,具有重要意义。
实现技术思路
一、算法理论基础
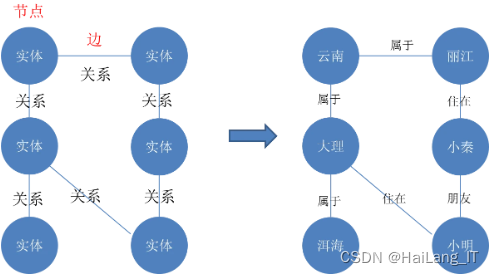
1.1 知识图谱
知识图谱是一种基于语义网络的知识库,它以图形模型的形式系统化地描述现实世界中事物及其相互关系。在这个模型中,节点代表实体,如人、飞机、手机等,边则表示实体之间的关系,如地理位置、雇佣、友谊等。知识图谱由模式层和数据层构成,模式层定义了概念及其关系,而数据层存储了实际存在的实体和它们之间的关系。这种结构使得知识图谱能够高效地组织和检索信息,支持复杂的关系查询和推理,广泛应用于搜索引擎、推荐系统、自然语言处理等领域。
1.2 网络爬虫技术
网络爬虫是一种自动抓取互联网信息的程序或脚本,它们按照特定的爬取规则,从特定的网站URL开始,通过模拟HTTP协议请求获取网页内容,解析页面内容并提取出符合任务要求的信息URL,存储在URL队列中,递归地请求获取页面的数据资源,最后对爬取的数据进行清洗、提取并存储在数据库中。
网络爬虫中,主要采用Python的Scrapy爬虫框架对目标地址资源进行爬取。Scrapy是一个满足用户爬取各种网站数据、使用网页解析器提取目标信息数据的爬虫应用框架,它采用异步框架模式对整体框架网络通信进行异步网络调度,对于大规模的数据爬取,采用异步结构模式加快程序的爬取速度。Scrapy设计了各种程序框架中间件接口,在实际的爬取操作中,根据不同的爬取任务嵌入不同的程序代码,灵活地完成各种爬取需求。
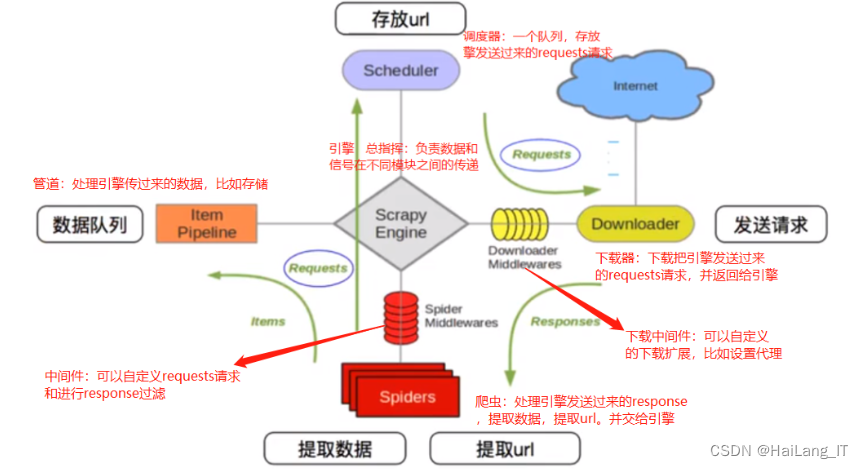
Spiders(爬虫组件)定义了整个网页的爬取逻辑和内容解析规则,负责生成新的请求并解析相应的响应。Engine(引擎)负责整个框架组件的通讯、信号和数据传递等。Scheduler(调度器)主要功能是将引擎发来的网络请求存储在组件队列中,完成一次请求时将请求再次传递给引擎。Downloader(下载器)下载各种爬取的网页,并根据框架的调度将下载的网页传递给Spider。Item Pipeline(项目管道)定义了爬取程序中的数据结构,获取爬取网页的数据,清洗并存储在数据库中。Spider Middlewares(Spider中间件)根据实际开发爬取框架需求,可以在操作引擎和Spider中自定义组件功能。
1.3 文本分类
朴素贝叶斯模型是一种基于贝叶斯定理的概率分类器,它假定特征之间相互独立。在文本分类任务中,模型会根据预先设定的类别,利用所属类别收集的大量文本集合形成文本训练数据集,并通过计算概率来确定文本的类别。朴素贝叶斯算法的主要特点是简单易懂、训练样本效率高,并且在特定的分类问题中效果良好。根据实际的分类任务待判断的类项,依据贝叶斯定理公式计算在任务条件下各个类别的概率,比较不同类别的概率,从而得出分类任务属于哪个类别。
二、 数据集
2.1 数据集
由于网络上没有现有的合适的电影知识数据集,我决定自己去电影网站进行爬取,收集电影信息并制作了一个全新的电影知识数据集。这个数据集包含了各种电影的信息,其中包括电影的导演、演员、评分等。通过现场爬取,我能够捕捉到真实的电影信息和多样的工作环境,这将为我的研究提供更准确、可靠的数据。我相信这个自制的电影知识数据集将为基于知识图谱的垂直领域电影知识查询问答系统研究提供有力的支持,并为该领域的发展做出积极贡献。
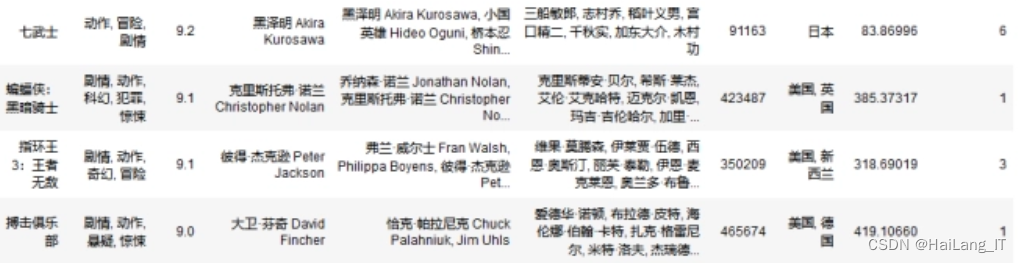
2.2 数据扩充
数据扩充是提高模型鲁棒性和泛化能力的重要手段。在本研究中,我们对收集到的电影知识数据进行了多样化的数据扩充。包括使用文本生成技术生成新的训练样本,如电影的摘要、评论等。这些扩充后的数据能够帮助模型更好地学习和理解电影知识的多样性和复杂性,提高模型在实际应用中的表现力。同时,数据扩充还可以增加模型的泛化能力,使其在面对未见过的数据时仍能保持良好的性能。
三、实验及结果分析
3.1 实验环境搭建
实验软硬件环境包括:服务器硬件要求搭载Intel Xeon E5或更高处理器、至少64GB RAM、1TB SSD存储以及额外的备份存储;网络设备需要高速路由器或交换机和防火墙以确保网络安全稳定;软件环境包括Ubuntu 18.04 LTS或CentOS 7.x等服务器操作系统、Neo4j或OrientDB等图数据库、MySQL或PostgreSQL等关系型数据库、Python编程语言、DjangoWeb应用框架以及PyTorch机器学习框架。此外,还需配备相应的开发工具、监控工具、日志管理工具和自动化部署工具等。
3.2 模型训练
基于知识图谱的垂直领域电影知识查询问答系统,主要是利用知识图谱技术为用户提供电影领域的相关知识查询和问答服务。其技术思路主要包括以下几个方面:
- 数据采集与处理:首先,需要从各种电影数据源(如电影数据库、影评网站、社交媒体等)采集电影相关的数据。然后,对这些数据进行预处理,包括数据清洗、去重、实体识别、关系抽取等,以便后续的知识图谱构建。
- 知识图谱构建:根据采集到的电影数据,构建电影领域的知识图谱。知识图谱主要包括电影实体、电影属性、电影关系等。实体主要包括电影、演员、导演等,属性包括电影的上映时间、评分、类型等,关系包括主演、导演、制片等。
- 查询与问答:用户通过问答系统提出关于电影的问题,系统根据问题内容在知识图谱中进行查询,找到相关的电影信息。查询可以通过关键词匹配、自然语言处理等技术实现。然后,系统将查询结果以问答的形式返回给用户。
- 自然语言理解:为了更好地理解用户提出的问题,需要利用自然语言处理技术对问题进行解析,包括分词、词性标注、命名实体识别等。通过理解用户的意图,帮助系统更准确地在知识图谱中找到相关的信息。
- 答案生成与优化:根据查询结果,系统需要生成合适的答案返回给用户。在这个过程中,可以利用自然语言生成技术(如模板匹配、序列到序列模型等)生成答案。同时,通过对用户反馈的分析,不断优化答案的生成策略,提高问答系统的效果。
相关代码示例:
from neo4j import GraphDatabase
class MovieQuestionAnswerer:
def __init__(self, uri, user, password):
self._driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self._driver.close()
def answer_question(self, question):
query = self.construct_query(question)
with self._driver.session() as session:
result = session.run(query)
return self.process_results(result)
def construct_query(self, question):
query = "MATCH (m:Movie) WHERE m.title = $title RETURN m"
return query
def process_results(self, result):
movie = result.single()
return f"The movie you are looking for is {movie['title']}."
海浪学长项目示例:



最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
本文转载自: https://blog.csdn.net/qq_37340229/article/details/136283070
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。