
理论基础知识可以看我之前的博客:
1、python之Numpy知识点详细总结
2、python最最最重要的数据分析工具之pandas
3、pandas之表连接与高级查询
也可以进入我的专栏:欢迎订阅哦,持续更新
python数据分析
文章目录
废话不多说了,直接开始吧!
# 导入库import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
import warnings
from datetime import datetime
plt.style.use('ggplot')# 画图风格为ggplot 美化
plt.rcParams['font.sans-serif']=['SimHei']# 设置中文字体为黑体,解决图形中不显示中文的问题
plt.rcParams['axes.unicode_minus']=False# 正常显示负号
warnings.filterwarnings("ignore")# 忽略警告
一、数据预处理
数据预处理分为:数据缺失值处理、数据重复值处理、数据异常值处理
1.0、数据格式转化
df = pd.read_csv('data.csv',sep=',',index_col=0)# 读取数据 分割符',' 将第一列作为索引列
df.columns =['订单时间','订单id','产品id','产品种类id','种类','品牌','价钱','用户id','年龄','性别','地区']# 修改列名
df.head(2)
订单时间 订单id 产品id 产品种类id 种类 品牌 价钱 用户id 年龄 性别 地区
02020-04-2411:50:39 UTC 229435993205453698615159662235090899062.268105e+18 electronics.tablet samsung 162.011.515916e+1824.0 女 海南
12020-04-2411:50:39 UTC 229435993205453698615159662235090899062.268105e+18 electronics.tablet samsung 162.011.515916e+1824.0 女 海南
# 修改字段格式
df['订单id']= df['订单id'].astype('object')
df['产品id']= df['产品id'].astype('object')
df['产品种类id']= df['产品种类id'].astype('object')
df['用户id']= df['用户id'].astype('object')
df['年龄']= df['年龄'].astype('int')
df['订单时间']= df['订单时间'].astype('datetime64')
df.info()<class'pandas.core.frame.DataFrame'>
Int64Index:564169 entries,0 to 2633520
Data columns (total 11 columns):# Column Non-Null Count Dtype ----------------------------0 订单时间 564169 non-null datetime64[ns]1 订单id564169 non-null object2 产品id564169 non-null object3 产品种类id564169 non-null object4 种类 434799 non-null object5 品牌 536945 non-null object6 价钱 564169 non-null float64
7 用户id564169 non-null object8 年龄 564169 non-null int32
9 性别 564169 non-null object10 地区 564169 non-null object
dtypes: datetime64[ns](1), float64(1), int32(1),object(8)
memory usage:49.5+ MB
1.1、数据缺失值处理
- 是否删除需要根据数据的重要性判断,如果用不到的字段有缺失,可以将这一列进行删除;如果字段比较重要且缺失值在20%以内也可以删除,若缺失值过多,最好不要删除否则可能会影响结果分析,我们可以看看是否可以通过原数据(的均值、众数等)进行补全;
# 从上面的结果可以知道:总数据有564169条,种类列缺失十万条数据,不能删除;品牌列缺失4万条数据,可以删除# 缺失较多的用M替补
df['种类']= df['种类'].fillna('M')# 缺失较少的直接删除不影响结果
df = df[df['品牌'].notnull()]
df.info()<class'pandas.core.frame.DataFrame'>
Int64Index:536945 entries,0 to 2633520
Data columns (total 11 columns):# Column Non-Null Count Dtype ----------------------------0 订单时间 536945 non-null datetime64[ns]1 订单id536945 non-null object2 产品id536945 non-null object3 产品种类id536945 non-null object4 种类 536945 non-null object5 品牌 536945 non-null object6 价钱 536945 non-null float64
7 用户id536945 non-null object8 年龄 536945 non-null int32
9 性别 536945 non-null object10 地区 536945 non-null object
dtypes: datetime64[ns](1), float64(1), int32(1),object(8)
memory usage:47.1+ MB
1.2、数据重复值处理
- 数据不同,处理重复值的方法也不同,有些可以直接删除重复值,而有些则不能;例如在这里,存在634个重复值,由于是订单信息,可能用户购买了多份产品,后台统计订单时将其分成n条数据了,这个时候我们就不能删除了,否则影响销量结果统计。
df.duplicated().sum()#是否存在重复值 634# 存在重复值,但是换个角度去想,这些重复值就是同笔订单下了多个数量的订单
1.3、数据异常值处理
df['订单时间'].dt.year.value_counts()202053569919701246
Name: 订单时间, dtype: int64
# 存在1970年的数据,原因可能是下单了但未付款,最终导致下单失败;也有可能只是数据错误。通过查看1970年的数据,发现日期仅有一个时刻的数据,因此可以确定数据出现错误,直接删除。
df = df[df['订单时间'].dt.year!=1970]
df.describe().T
count mean std min25%50%75%max
价钱 535699.0214.647845305.9821100.024.9899.51289.3311574.05
年龄 535699.033.17542110.12785816.024.0033.0042.0050.00# 价钱的3/4位数和max差距有点打,我们可以看一下价钱>10000的是什么产品
df[df['价钱']>10000]
订单时间 订单id 产品id 产品种类id 种类 品牌 价钱 用户id 年龄 性别 地区
16279812020-07-0311:59:01235328850900077791822739483053166430782.26811e+18 electronics.video.tv lg 11574.051.51592e+1834 男 北京
22709992020-09-1606:46:10238844098113448448415159662235208012802.3745e+18 electronics.video.tv samsung 10416.641.51592e+1834 男 上海
# 产品种类属于电子产品且属于video类,品牌为三星和lg属于高端产品 说明价钱并不异常 不需要处理
df.reset_index(drop=True,inplace=True)# 重置索引并替换原数据
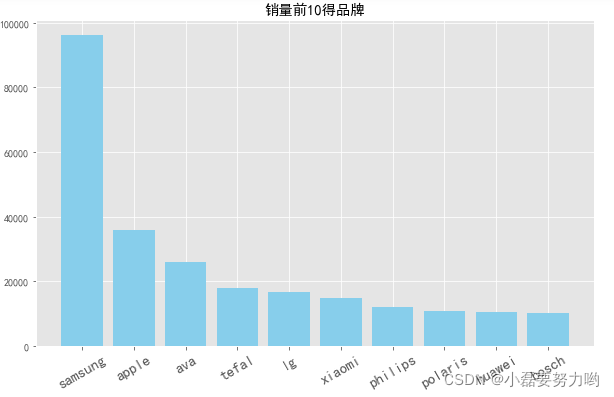
二、销量前十的品牌
brand_cnt = df.groupby('品牌')['订单id'].count().sort_values(ascending=False)
plt.figure(figsize=(10,6))
plt.bar(np.arange(10),brand_cnt[0:10],color='skyblue')
plt.title('销量前10得品牌')
plt.xticks(np.arange(10),brand_cnt[0:10].index,size=15,rotation=30)
plt.show()
三、用户画像分析
3.0、什么是用户画像呢
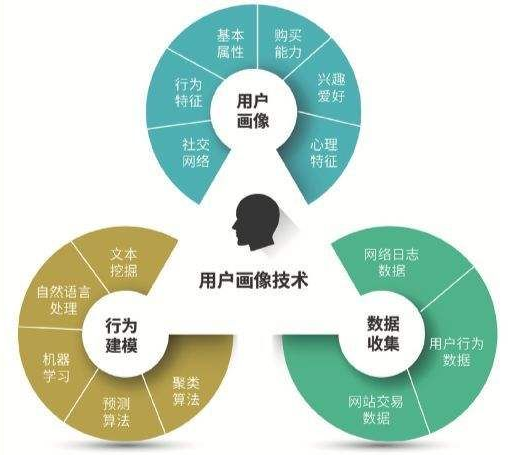
- 用户画像指真实用户的虚拟代表,是建立在一系列属性数据之上的目标用户模型。说白了就是个人标签。用户画像的内容不固定,需根据行业和产品的不同所关注的用户特征也不同。对于大部分互联网公司,用户画像都会包含用户基本属性和用户行为特征。有了这些特征,我们进而挖掘产品或app等的用户特征,了解使用app或产品的使用与购物的人群,进而可以精准化营销产品,带来更多的利益。
- 人口基本属性主要指用户本身特征:包含年龄、性别、所在省份和城市、教育程度、行业职业等。
- 用户行为特征主要包含活跃度、忠诚度等指标,电商行业(淘宝、pdd等)购物时会有浏览、收藏、加入购物车等,从而也可以计算转化率等信息,这些也属于用于行为分析的范畴。
3.1、地区、年龄和性别分布
# 1、地区分布,按地区分布对用户计数 nunique() 去重后计数
df_area = df.groupby('地区')['用户id'].nunique().sort_values(ascending=False)
df_area
地区
广东 21382
上海 16031
北京 15928
江苏 5561
海南 5449
四川 5445
浙江 5370
湖北 5355
重庆 5342
天津 5337
湖南 5330
Name: 用户id, dtype: int64
# 2、性别分布:对性别分组,对人数计数
df_sex = df.groupby('性别')['用户id'].nunique().sort_values(ascending=False)
df_sex
性别
男 47628
女 47235
Name: 用户id, dtype: int64
# 3、年龄段分布:将年龄切分为若干段后,再对用户进行计数
box =[10,20,30,40,50,60]
df['年龄段']= pd.cut(df['年龄'],bins=box,right=False)# 分箱
df_age = df.groupby('年龄段')['用户id'].nunique().sort_values(ascending=False)
df_age
年龄段
[20,30)27596[30,40)27451[40,50)27308[10,20)10917[50,60)2724
Name: 用户id, dtype: int64
# 4、可视化地区分布、性别分布及年龄段分布
fig = plt.figure(figsize=(12,8),facecolor='#E6E6FA')# 设置画布大小和背景颜色# 第一个子图:性别分布
ax1 = fig.add_subplot(221)
patch,l_text,p_text = ax1.pie(df_sex.values,labels=df_sex.index,colors=['b','r'],autopct='%.2f%%')for i,j inzip(l_text,p_text):# 设置标签文字大小 l_text外面的文字标签 p_text里面的百分数
i.set_size(15)
j.set_size(15)
ax1.set_title('性别分布')# 子图标题# 第二个子图:年龄分布
ax2 = fig.add_subplot(222)
patch,l_text,p_text = ax2.pie(df_age.values,labels=df_age.index,autopct='%.2f%%',colors=['skyblue','SpringGreen','DarkTurquoise','Gold','#FF4500'])for i,j inzip(l_text,p_text):
i.set_size(12)
j.set_size(12)
ax2.set_title('年龄分布')# 第三个子图 :地区分布柱状图
ax3 = fig.add_subplot(212)# 212将原来的2行2列图变为2行1列图 212 2行1列中的第二幅图
ax3.bar(df_area.index,df_area.values)for i,j inenumerate(df_area.values):# 标签位置与显示
plt.text(i-0.3,j+40,j)
ax3.set_title('地区分布')
ax3.set_ylabel('人数(人)')# 采用ggplot风格时,会显示网格线和灰色背景# 不显示网格线
plt.grid(False)# 子图的背景色透明
ax3.patch.set_alpha(0)# 上和右边框不可见
ax3.spines['top'].set_visible(False)
ax3.spines['right'].set_visible(False)
plt.show()
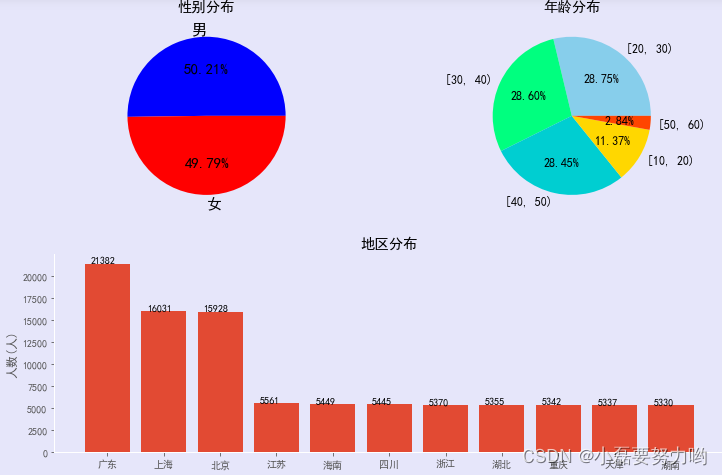
- 从图中可以看出: - 年龄分布:男女比列差不多,男性比例稍高一点点。- 年龄分布:较多的群体是20岁到50岁的用户群体,说明这些产品深受年轻人和青年人信赖。因此,厂商可以多多研发年轻化的产品。- 地区分布:广东省高居第一位、其次上海市和北京市,说明北上广的用户消费的居多,消费水平也高,而且北上广还是一线城市。 其余的省份消费人数才是北上广的1/3,消费人数较少。
3.2、各年龄段的下单数量及消费金额
df_age_money = pd.DataFrame(df.groupby('年龄段')['价钱'].sum())
df_age_num = pd.DataFrame(df.groupby('年龄段')['订单id'].nunique())
age_money_num = df_age_money.merge(df_age_num,left_index=True,right_index=True)
age_money_num.columns =['总消费金额','订单数量']
age_money_num['平均每单价钱']= age_money_num['总消费金额']/age_money_num['订单数量']
age_money_num
总消费金额 订单数量 平均每单价钱
年龄段
[10,20)1.237316e+0741846295.683236# 各年龄段的平均消费水平还是差不太多的[20,30)3.336561e+07112086297.678664[30,40)3.211958e+07108307296.560528[40,50)3.391897e+07115426293.859046[50,60)3.209309e+0611077289.727280# 可视化
fig = plt.figure(figsize=(15,5))
ax1 = fig.add_subplot(111)
ax1.bar(np.arange(len(age_money_num)),age_money_num['总消费金额'],color='red',width=0.2)for i, j inenumerate(age_money_num['总消费金额']):
plt.text(i, j,'%s'%round((j/1e7),2))
ax1.set_ylabel('总消费金额(千万)')
ax2 = ax1.twinx()# 共用x轴
ax2.bar(np.arange(len(age_money_num))+0.2,age_money_num['订单数量'],color='skyblue',width=0.2)for i, j inenumerate(age_money_num['订单数量']):
plt.text(i+0.2, j,'%s'%round((j/1e4),2))
ax2.grid(False)
ax2.set_ylabel('订单数量(万)')
plt.xticks(np.arange(len(age_money_num))+0.1,age_money_num.index)
plt.yticks(np.arange(0,130000,20000),np.arange(0,13,2))
plt.show()
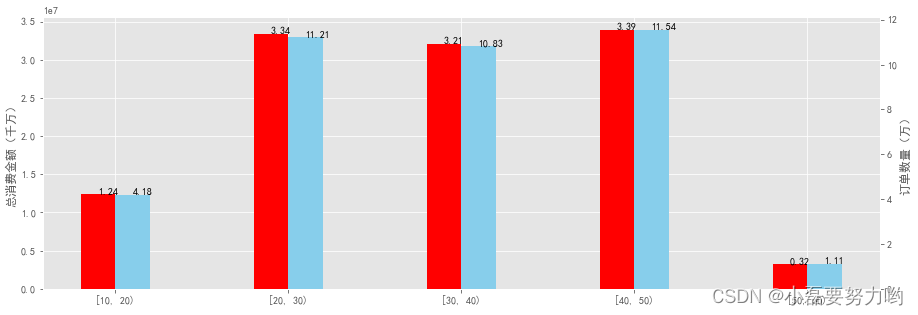
- 可以看出:无论是消费金额还是订单数量,20—50岁的用户始终是消费的重要群体。
3.3、男性女性的消费金额及下单数量
df_sex_money = pd.DataFrame(df.groupby('性别')['价钱'].sum())
df_sex_num = pd.DataFrame(df.groupby('性别')['订单id'].nunique())
sex_money_num = df_sex_money.merge(df_sex_num,left_index=True,right_index=True)
sex_money_num.columns =['总消费金额','订单数量']
sex_money_num['平均每单价钱']= sex_money_num['总消费金额']/sex_money_num['订单数量']
sex_money_num
总消费金额 订单数量 平均每单价钱
性别
女 5.710846e+07192394296.830757
男 5.787818e+07196348294.773460# 从性别上看,男性的总消费金额比较高,但是男性的平均消费水平较女性低,说明女生个人消费比男生高一点。
四、二八定律
- 二八定律也称帕累托法则,即20%的人口掌握了80%的社会财富。这个结论对大多数国家的社会财富分配情况都成立。因此,该法则又被称为80/20法则。例如:当一家公司发现自己80%的利润来自于20%的顾客时,公司就该着重注意这20%的顾客,不能让他们流失掉。这样做,不但比把注意力平均分散给所有的顾客更容易,也更值得。再者,如果公司发现80%的利润来自于20%的产品,那么这家公司应该全力来销售那些高利润的产品。
user_pay = pd.DataFrame(df.groupby('用户id')['价钱'].sum().sort_values(ascending=False)).reset_index()
user_pay['累计消费金额']= user_pay['价钱'].cumsum()
user_pay['累计百分比%']=round(user_pay['累计消费金额']/ np.max(user_pay['累计消费金额'])*100,2)
user_pay
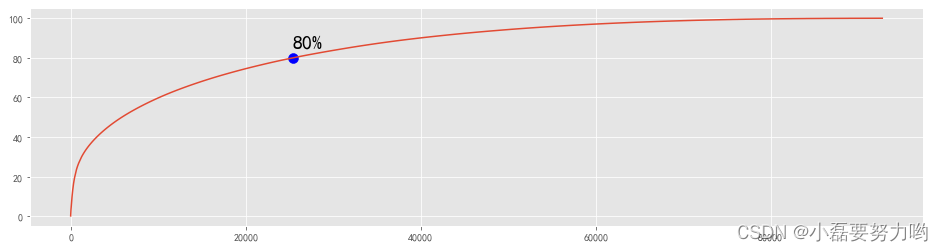
用户id 价钱 累计消费金额 累计百分比%01515915625512422912160604.071.606041e+050.1411515915625513695488158277.373.188814e+050.2821515915625512377088149967.064.688485e+050.4131515915625513577472135672.846.045213e+050.5341515915625514597888133945.887.384672e+050.64# 累计金额第一次出现80%
sy = user_pay[user_pay['累计百分比%']==80].index[0]# 索引
plt.figure(figsize=(16,4))
plt.plot(np.arange(len(user_pay)),user_pay['累计百分比%'])
plt.text(sy,85,'80%',size=20)
plt.scatter(sy,80,marker='o',c='blue',s=100)
plt.show()print(sy)# 25384 累计金额占比第一次出现80% 的索引print(round(sy/len(user_pay)*100,2))# 27.36 提供了80%的消费金额的人数/总人数# 说明27.36%的人提供了80%的消费金额 符合二八定律 应该着重注意这27%的用户,收入来源主要是这些用户。
五、用户分层:RFM模型
- RFM模型是通过客户的最近一次购买距今天数、购买的总体频率以及花了多少钱3个维度来描述该客户价值状况的客户分类模型,这3个维度分别表示为: - 最近一次消费距离现在的时间 (Recency):顾客的最近一次购物时间越近,购物越积极- 某段时间内消费频率次数 (Frequency):顾客的消费频次越高,对商家的忠诚度就越高- 某段时间内消费金额 (Monetary):顾客的消费金额越高即消费能力越强,对商家贡献度越高
- 这3个维度可以根据实际业务来确定,比如针对社交类产品,最近一次活跃距离现在的时间比最近一次消费距离现在的时间更适合。
RFM得分标准(根据公司情况自定义)
r值分段得分f值分段得分m值分段得分60天未购买5购买1次1100元以下160—120天未购买4购买2次2100—200元2120—180天未购买3购买3次3200—500元3180—240天未购买2购买4次4500—1000元4240天以上未购买1购买5次以上51000元以上5
- 但最好R、F、M都仅有两值(0或1),所以还要根据第一次得分的平均值分为0或1。得到最终得用户的R值、F值、M值,接下来把他们放入分类器中,汇总如下:
用户类别划分
RFMRFM用户分类111111重要价值客户101101重要发展客户011011重要保持客户001001重要挽留客户110110一般价值客户100100一般发展客户010010一般保持客户000000一般挽留客户
- 最好可根据用户分层对用户进行精准营销。
df2 = df[['用户id','订单时间','价钱','订单id']]
df2['订单日期']= pd.to_datetime(df['订单时间'].dt.strftime('%Y-%m-%d'))
df2.drop_duplicates(inplace=True)# 假设以2020-11-30为基准 计算用户每次购物距离11-30多少天
df2['距今天数']=(pd.to_datetime('2020-11-30')- df2['订单日期']).dt.days
# 用户最近一次购物距离11-30多少天 距今天数最小的就是最近一次购物
r = pd.DataFrame(df2.groupby('用户id')['距今天数'].min())# 计算每个用户的消费金额
m = pd.DataFrame(df2.groupby('用户id')['价钱'].sum())# 计算 每个用户的消费频次
f = pd.DataFrame(df2.groupby('用户id')['订单时间'].nunique())
rfm = pd.concat([r,f,m],axis=1).reset_index()
rfm.columns =['用户id','r','f','m']
rfm['用户id']= rfm['用户id'].astype('object')
rfm.head(4)
用户id r f m
015159156254399518721441416.641151591562544003840033256.43215159156254400517121446054.373151591562544009984022164790.99
rfm.describe().T
count mean std min25%50%75%max
r 92755.0107.58921954.5268799.070.00110.00136.00330.00
f 92755.04.18650217.5661061.01.002.003.00632.00
m 92755.01228.3567844080.8319840.0145.81451.371133.98159999.66# r:距离现在最远的是330天没有购物了,最近的是9天前# f:购物频次最低的是1次,最高的是632次了,平均一天购物两次# m:购物最小总金额0,可能是只购买了1次且是免费产品, 最大总金额159999元
# 根据RFM标准创建函数defuser_r(x):if x <=60:return5elif60<x<=120:return4elif120<x<=180:return3elif180<x<=240:return2else:return1defuser_f(x):if x ==1:return1elif x ==2:return2elif x ==3:return3elif x ==4:return4else:return5defuser_m(x):if x <=100:return1elif100<x<=200:return2elif200<x<=500:return3elif500<x<=1000:return4else:return5
# 按照RFM得分标准应用函数
rfm['r']= rfm['r'].apply(user_r)
rfm['f']= rfm['f'].apply(user_f)
rfm['m']= rfm['m'].apply(user_m)# 要将得分转化为0-1格式,若得分>均值返回1,否则返回0
rfm['r']= rfm['r'].apply(lambda x:'1'if x>=np.mean(rfm['r'])else'0')
rfm['f']= rfm['f'].apply(lambda x:'1'if x>=np.mean(rfm['f'])else'0')
rfm['m']= rfm['m'].apply(lambda x:'1'if x>=np.mean(rfm['m'])else'0')# 直接相加 这也是前面为什么返回字符串'1'和'0';若是返回数字,默认直接做加法运算
rfm['RFM']= rfm['r']+ rfm['f']+ rfm['m']
rfm.head(2)
用户id r f m RFM
0151591562543995187200000011515915625440038400100100
defRFM(j):if j =='111':return'重要价值客户'elif j =='101':return'重要发展客户'elif j =='011':return'重要保持客户'elif j =='001':return'重要挽留客户'elif j =='110':return'一般价值客户'elif j =='100':return'一般发展客户'elif j =='010':return'一般保持客户'elif j =='000':return'一般挽留客户'
rfm['用户类型']= rfm['RFM'].apply(lambda x : RFM(x))
rfm.head(2)
用户id r f m RFM 用户类型
01515915625439951872000000 一般挽留客户
11515915625440038400100100 一般发展客户
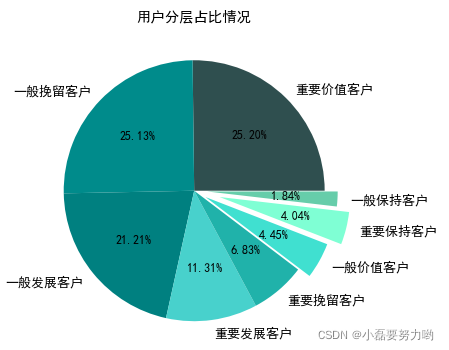
user_RFM = rfm.groupby('用户类型')['用户id'].nunique().sort_values(ascending=False)
user_RFM
用户类型
重要价值客户 23371
一般挽留客户 23306
一般发展客户 19673
重要发展客户 10486
重要挽留客户 6336
一般价值客户 4125
重要保持客户 3751
一般保持客户 1707
Name: 用户id, dtype: int64
# 自定义颜色
colors =['#2F4F4F','#008B8B','#008080','#48D1CC','#20B2AA','#40E0D0','#7FFFD4','#66CDAA']
plt.figure(figsize=(10,6))
patch,l_text,p_text = plt.pie(user_RFM.values # 值,autopct='%.2f%%'# 显示两位百分数,labels=user_RFM.index # 标签,labeldistance=1.1# 标签距离圆心距离,colors=colors # 颜色,explode=[0,0,0,0,0,0.1,0.2,0.1])# 扇形突出位置for i,j inzip(l_text,p_text):# 设置标签及百分数字体大小
i.set_size(13)
j.set_size(12)
plt.title('用户分层占比情况')
plt.show()
本文转载自: https://blog.csdn.net/m0_69435474/article/details/124397214
版权归原作者 小磊要努力哟 所有, 如有侵权,请联系我们删除。
版权归原作者 小磊要努力哟 所有, 如有侵权,请联系我们删除。