
大家好,我是微学AI,今天给大家带来SpeakGPT的本地实现,在自己的网页部署,可随时随地通过语音进行问答,本项目项目是基于ChatGPT的语音版,我称之为SpeakGPT。
ChatGPT最近大火,其实在去年12月份就想做一期关于ChatGPT的文章。
ChatGPT是美国OpenAI公司研发的功能强大的聊天机器人,他于2022年11月30日发布。ChatGPT是自然语言处理的天花板,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至可以完成论文、文案,代码的编写。
ChatGPT(全称:Chat Generative Pre-trained Transformer),发展于GPT系列,GPT由1代发展到3代,到现在的ChatGPT,ChatGPT的基本原理是基于Transformer的解码器部分来做的,主要是文本生成任务模型。

一、ChatGPT模型训练的步骤:
数据收集:ChatGPT的训练数据通常是从互联网上收集的大量文本数据,如维基百科、新闻文章、小说、论坛帖子等数据,数据量有45TB之多。这些数据需要进行清洗和预处理,例如去除无效字符、标点符号、停用词等。
数据处理:ChatGPT使用的是基于字符级别的模型,因此需要将原始文本数据进行分割,转换成单个字符的形式。同时,还需要对这些字符进行编码,以便于模型处理。
构建模型:ChatGPT模型是基于Transformer架构构建的,它包含多层Transformer编码器和解码器,以及多头注意力机制、残差连接等组件。在构建模型之前,需要确定模型的超参数,例如层数、隐层维度、注意力头数等。
无监督训练:ChatGPT的训练过程是无监督的,采用了基于最大似然估计的语言模型训练方法。训练时,模型根据先前的字符序列来预测下一个字符,然后与实际下一个字符进行比较,并计算预测误差。训练的目标是最小化所有预测误差的累积和。
预训练微调:在完成无监督训练后,ChatGPT还可以通过预训练微调来进一步提高性能。微调的过程是在有标注的任务上进行的,例如文本分类、命名实体识别等。在微调过程中,ChatGPT模型使用预训练好的权重作为初始权重,并通过有监督学习来进一步调整模型参数。
强化学习:除了无监督训练和预训练微调外,ChatGPT还可以通过强化学习来进一步优化模型的性能。在强化学习中,通过人工标注的数据对生成文本进行打分,例如生成四种结果,人工对这四种结果进行排序,排出人类最想要的答案。通过人工打分训练出可以对生成文本进行自动打分的模型。通过打分模型进一步对ChatGPT进行优化。
二、SpeakGPT模型
SpeakGPT是一种基于GPT-3的生成式对话模型,它可以生成自然、流畅的语音对话。与传统的语音对话系统不同,SpeakGPT可以在没有预定义规则和流程的情况下进行对话,并根据用户的输入和上下文信息生成符合语境和语义的回复。
SpeakGPT的工作原理类似于文本对话模型,它使用了GPT-3模型的结构和参数,并基于大量的语音对话数据进行训练和优化。具体而言,SpeakGPT的训练数据包括了大量的语音对话记录,其中包括了各种类型的对话,如电话对话、语音助手对话、实时聊天对话等。这些数据被用于训练SpeakGPT模型,从而使其能够自动学习语音对话的规律和模式。
SpeakGPT的使用方法与其他对话系统类似,用户可以使用语音输入进行对话,并在SpeakGPT的回复中获得自然、流畅的语音输出。
三、SpeakGPT模型代码实现
实现SpeakGPT之前需要获取一个Openai账号,详细可私信,一般小伙伴都可以获取,然后代码中写入OPENAI_API_KEY = '你的API_KEY'。
# coding=utf-8/gbk
import os
import openai
import json
import gradio as gr
import base64
from tts_ws_python3_demo import text2speak
import websocket
import ssl
global latest_data
OPENAI_API_KEY = '你的API_KEY'
def chats(message, history):
history = history or []
message_new = message
if len(history)>0:
if message == history[0][0] or message =='继续':
for hos in history:
message = message + hos[1]
responses = chatgpt(message)
print(responses)
if len(responses)<4:
responses ='\n 已经回答完成!'
history.append((message_new, responses))
context = ''
for tex in history:
texs =tex[1]
texs =texs.replace('\n\n','\n')
context =context+texs
path = text2speak(context)
return path
def chatgpt(prompt):
openai.api_key = OPENAI_API_KEY
response = openai.Completion.create(
model="text-davinci-003",
prompt= prompt,
temperature=0.7,
max_tokens=512,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
res = response["choices"][0]["text"]
res.encode().decode("unicode_escape")
return res
# 清除输入输出
def clear_input():
return ""
if __name__ == '__main__':
with gr.Blocks(title='SpeakGPT', css=".gradio-container #Button {background-color: #03a9f4} #Clear {background-color: #fe3829} #mar {color: #03a9f4} " ) as demo:
with gr.Row():
gr.Markdown("""# SpeakGPT""" )
gr.Markdown("""输入问题, SpeakGPT可以进行回答""")
with gr.Box():
with gr.Row() as row:
with gr.Column():
gpt_text = gr.Textbox(label="问题", lines=2)
gpt_stats = gr.State()
with gr.Row():
gpt_btn = gr.Button("提问", elem_id="Button")
clear = gr.Button("清除", elem_id="Clear")
with gr.Column():
out_Audio = gr.Audio(label="语音",type='filepath')
gpt_btn.click(fn=chats,
inputs=[gpt_text, gpt_stats],
outputs=[out_Audio])
# chatgpt
clear.click(fn=clear_input, inputs=[], outputs=[out_Audio])
demo.launch(share=True,show_api=False)
tts_ws_python3_demo.py代码,这边生成语言采用科大讯飞文本转语言功能,你也可以选择其他方式转换,这里需要填写修改:APPID='你的APPID',APISecret='你的APISecret',APIKey='你的APIKey'
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import os
import time
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
APPID='你的APPID'
APISecret='你的APISecret'
APIKey='你的APIKey'
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, Text):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.Text = Text
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs = {"aue": "raw", "auf": "audio/L16;rate=16000", "vcn": "aisjinger", "tte": "utf8"}
self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-8')), "UTF8")}
#使用小语种须使用以下方式,此处的unicode指的是 utf16小端的编码方式,即"UTF-16LE"”
#self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-16')), "UTF8")}
# 运行
# 生成url
def create_url(self):
url = 'wss://tts-api.xfyun.cn/v2/tts'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
# print('websocket url :', url)
return url
def on_message( ws, message):
try:
message =json.loads(message)
code = message["code"]
sid = message["sid"]
audio = message["data"]["audio"]
audio = base64.b64decode(audio)
status = message["data"]["status"]
#print(message)
if status == 2:
print("ws is closed")
ws.close()
if code != 0:
errMsg = message["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
with open('demo.pcm', 'ab') as f:
f.write(audio)
import wave
# 打开pcm文件
f = open("demo.pcm", 'rb')
# 读取文件
params = f.read()
# 写入wav文件
# 参数
nchannels = 1
sampwidth = 2
framerate = 16000
nframes = len(params)
comptype = "NONE"
compname = "not compressed"
# 写入
wav_file = wave.open("demo.wav", 'w')
wav_file.setparams((nchannels, sampwidth, framerate, nframes, comptype, compname))
wav_file.writeframes(params)
wav_file.close()
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error( ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(self, ws):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws, wsParam):
def run(*args):
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": wsParam.Data,
}
d = json.dumps(d)
print("------>开始发送文本数据")
ws.send(d)
if os.path.exists('demo.pcm'):
os.remove('demo.pcm')
thread.start_new_thread(run,())
def text2speak(text):
wsParam = Ws_Param(APPID=APPID, APISecret=APISecret,
APIKey=APIKey,
Text=text)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = lambda ws: on_open(ws, wsParam)
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
path = 'demo.wav'
return path
if __name__ == "__main__":
# 测试时候在此处正确填写相关信息即可运行
text ="大家好,我是微学AI"
text2speak(text)
运行结果:
电脑端:

手机端:
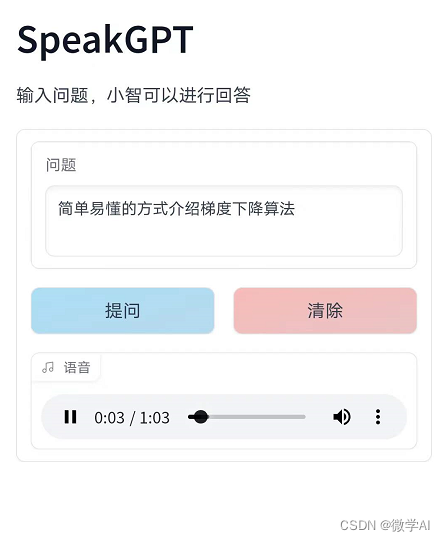
点击语音就可收听,用于旅途中智能问答快速获取信息,成为你的智能背囊,行走的“军师”。
** 往期作品:**
深度学习实战项目
1.深度学习实战1-(keras框架)企业数据分析与预测
2.深度学习实战2-(keras框架)企业信用评级与预测
3.深度学习实战3-文本卷积神经网络(TextCNN)新闻文本分类
4.深度学习实战4-卷积神经网络(DenseNet)数学图形识别+题目模式识别
5.深度学习实战5-卷积神经网络(CNN)中文OCR识别项目
6.深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测
7.深度学习实战7-电商产品评论的情感分析
8.深度学习实战8-生活照片转化漫画照片应用
9.深度学习实战9-文本生成图像-本地电脑实现text2img
10.深度学习实战10-数学公式识别-将图片转换为Latex(img2Latex)
11.深度学习实战11(进阶版)-BERT模型的微调应用-文本分类案例
12.深度学习实战12(进阶版)-利用Dewarp实现文本扭曲矫正
13.深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
14.深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了
15.深度学习实战15(进阶版)-让机器进行阅读理解+你可以变成出题者提问
16.深度学习实战16(进阶版)-虚拟截图识别文字-可以做纸质合同和表格识别
17.深度学习实战17(进阶版)-智能辅助编辑平台系统的搭建与开发案例
18.深度学习实战18(进阶版)-NLP的15项任务大融合系统,可实现市面上你能想到的NLP任务
19.深度学习实战19(进阶版)-ChatGPT的本地实现部署测试,自己的平台就可以实现ChatGPT
...(待更新)
版权归原作者 微学AI 所有, 如有侵权,请联系我们删除。