
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的短文本情感分析
设计思路
一、课题背景与意义
短文本情感分析是自然语言处理领域的一个重要课题,目标是从给定的短文本中识别出情感倾向,如积极、消极或中性。在社交媒体、产品评论和用户反馈等场景中,人们经常表达出对某些事物或事件的情感态度,因此准确地分析短文本情感对于企业和决策者来说具有重要意义。
二、算法理论原理
2.1 文本分类模型
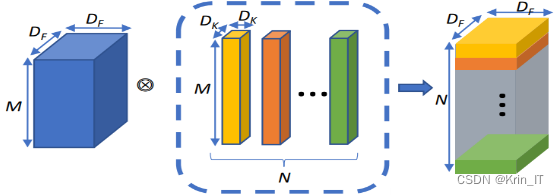
深度学习模型是基于大脑神经网络的运行机制,通过提取数据特征并进行参数调整来进行学习。在文本分类领域,卷积神经网络和双向长短期记忆网络是最常见的基本网络结构。卷积神经网络最初用于图像处理,后来在自然语言处理领域也得到广泛应用。
短文本情感分析是对短小的文本进行情感分类的任务,如判断一段文字是正面的、负面的还是中性的情感表达。TextCNN模型通过其卷积操作和池化操作的特点,能够有效地捕捉短文本中的局部特征和语义信息。TextCNN模型首先将文本转化为词向量表示,然后通过一系列卷积层和池化层对这些词向量进行特征提取。卷积层可以捕捉到不同长度的局部特征,通过多个不同大小的卷积核,可以获得不同尺度的特征表示。而池化层则用于降低特征的维度,保留最重要的特征信息。最后,将提取到的特征输入到全连接层进行分类。
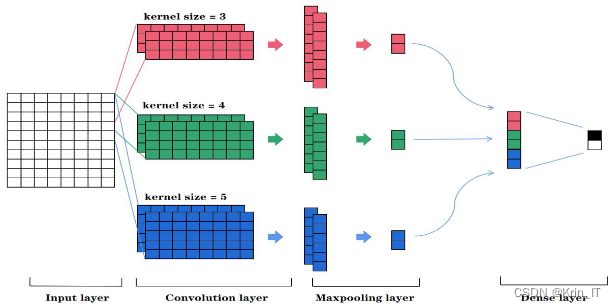
TextCNN模型在短文本情感分析系统中的应用具有以下优势:
- 效果显著:TextCNN能够有效地捕捉短文本中的局部特征和语义信息,对情感分类任务具有较高的准确性和性能。
- 处理速度快:由于卷积操作的并行性,TextCNN模型的训练和推理速度较快,适用于实时或大规模的情感分析应用。
- 模型简洁:TextCNN模型相对于其他深度学习模型来说,结构较为简单,参数较少,易于训练和调优。
- 数据效率高:相比于基于循环神经网络的模型,TextCNN对于短文本情感分析具有更好的数据效率,不容易受到长期依赖问题的影响。
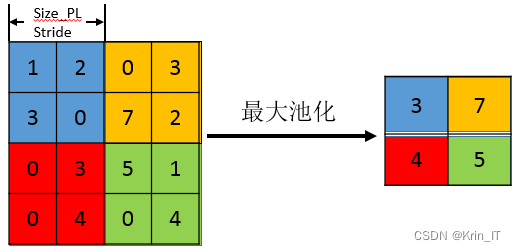
池化操作是一种用于提取特征的重要手段,其核心思想是将目标矩阵或向量分成多个部分,并从中选择最具代表性的特征值。常见的池化方式包括平均池化和最大池化。在一般情况下,平均池化和最大池化并没有明显的优劣之分。然而,在文本情感分析中,通常使用最大池化的方式,因为最大特征能更好地概括整个文本的情感语义。因此,在文本情感分析任务中,最大池化被广泛采用,以提取最重要的特征并进行情感分类。
相关代码示例:
import torch
import torch.nn as nn
class TextCNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_filters, filter_sizes, output_dim):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(1, num_filters, (fs, embedding_dim)) for fs in filter_sizes
])
self.fc = nn.Linear(num_filters * len(filter_sizes), output_dim)
def forward(self, text):
embedded = self.embedding(text) # 将文本转换为词向量表示
embedded = embedded.unsqueeze(1) # 添加channel维度
conved = [nn.functional.relu(conv(embedded)).squeeze(3) for conv in self.convs] # 卷积操作
pooled = [nn.functional.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved] # 池化操作
cat = torch.cat(pooled, dim=1) # 将多个池化结果拼接起来
output = self.fc(cat) # 全连接层
return output
2.2 神经网络
循环神经网络(RNN)是一种能够准确捕捉时间序列数据特征并对其进行建模的模型。对于文本数据来说,RNN也适用,因为文本是典型的时序数据,其中单词的出现顺序对语义和情感倾向具有重要影响。在文本情感分析任务中,RNN模型能够有效地处理文本的时序性。通过学习文本中单词的顺序和上下文关系,RNN能够捕捉到情感表达的细微变化。这意味着即使是一小段文本,如一句话或一段短语,RNN也能够通过分析其中的单词顺序来判断其情感倾向。
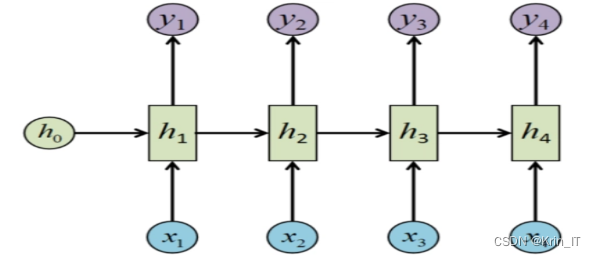
循环神经网络(RNN)适用于处理时序数据,但容易遇到梯度消失和梯度爆炸问题。为解决这一问题,LSTM引入了门控结构,包括遗忘门、更新门和输出门,使其能够有效地捕捉时序数据的特征并学习重要的依赖关系。LSTM通过记忆单元和门控机制,避免了梯度消失和梯度爆炸问题,并能够学习到对当前任务更重要的信息,使其成为处理文本等时序数据的强大模型。
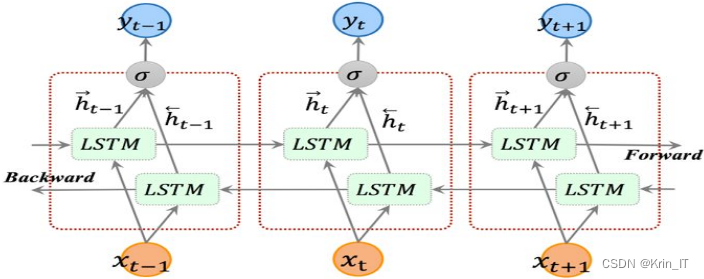
相关代码示例:
import torch
import torch.nn as nn
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0)) # LSTM前向传播
# 取最后一个时间步的输出作为模型的输出
out = self.fc(out[:, -1, :])
return out
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的数据集,我决定自己收集数据并制作一个全新的数据集,用于短文本情感分析的研究。这个数据集包含了各种真实场景下的短文本,涵盖了多个情感类别,包括积极、消极和中性情感。通过自己收集数据,我能够捕捉到真实的情感表达和多样的语境,这将为我的研究提供更准确、可靠的数据样本。我相信这个自制的数据集将为短文本情感分析的研究提供有力的支持,并为该领域的发展做出积极贡献。
3.2 实验环境搭建

3.3 实验及结果分析
本次实验采用批量训练方式,词向量维度为100,批大小为32,初始学习率为0.001,损失函数为二元交叉熵,优化器为Rmsprop。为解决模型输入口大小导致的关键语义屏蔽问题,将输入口大小作为超参数,并通过后续对比实验选择合适的尺寸。同时,探究训练数据比例、TextCNN层中卷积核尺寸的组合以及迭代次数对模型性能的影响。通过控制变量法进行对比实验,选择最优超参数组合,并与其他模型进行性能比较,以提高模型性能和效果。
通过引入ECA双通道模型,可以进一步提升情感分析任务的效果。UNF-ECA模型可能利用了两个通道的信息,例如,可以同时考虑文本的语义信息和上下文信息,从而更准确地捕捉情感表达。相比之下,单通道的复杂模型可能无法充分利用这些多维度的信息,导致性能略有限。
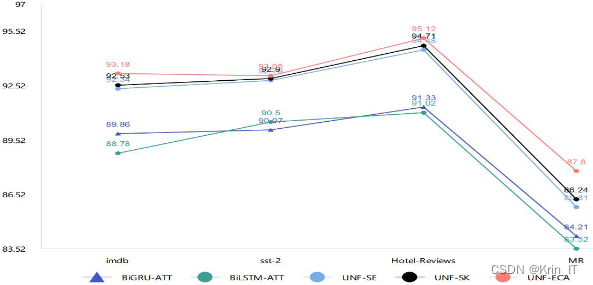
叠加更多的ECA模块可以增加模型对特征图的全面把握能力。ECA模块通过自适应地调整特征图中每个通道的权重,使得模型能够更加准确地捕捉到重要的特征。随着ECA模块的叠加数量增加,模型可以更好地利用多个通道的信息,进一步提高其表达能力和性能。相比于单通道模型,双通道模型具有更低的参数量和模型复杂度,同时能够利用ECA模块对特征图进行全面的把握。这使得双通道模型在处理文本情感分析等任务时能够更好地捕捉到重要的特征和语义信息,从而提高了性能和效果。
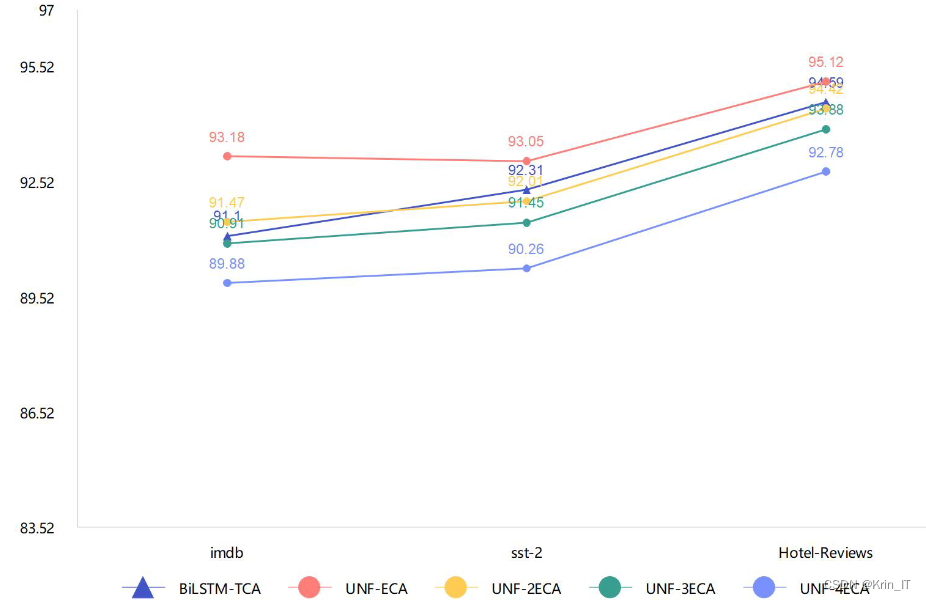
相关代码示例:
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Input, Embedding, Bidirectional, LSTM, Dense, Attention
# 定义模型
def create_model(vocab_size, embedding_dim, max_length):
input_text = Input(shape=(max_length,))
embedding = Embedding(vocab_size, embedding_dim, input_length=max_length)(input_text)
lstm = Bidirectional(LSTM(64, return_sequences=True))(embedding)
attention = Attention()(lstm)
output = Dense(1, activation='sigmoid')(attention)
model = tf.keras.Model(inputs=input_text, outputs=output)
return model
# 数据预处理
def preprocess_data(texts, labels, tokenizer, max_length):
sequences = tokenizer.texts_to_sequences(texts)
padded_sequences = pad_sequences(sequences, maxlen=max_length, padding='post')
labels = np.array(labels)
return padded_sequences, labels
# 训练模型
def train_model(model, X_train, y_train, epochs, batch_size):
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size)
# 测试模型
def test_model(model, X_test, y_test):
loss, accuracy = model.evaluate(X_test, y_test)
print('Test Loss:', loss)
print('Test Accuracy:', accuracy)
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/135584385
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。