
1.YOLOv5模型简介
YOLO能实现图像或视频中物体的快速识别,在相同的识别类别范围和识别准确率条件下,YOLO识别速度最快。YOLO有多种模型,其中最新的为V5,V5的特点是速度更快,识别准确率更高,权重文件更小,可以搭载在配置更低的移动设备上。
本次测试采用V5模型,对各种场景下的车辆类型进行批量检测,对检测结果进行分析,重点是道路车辆类别能否得到正确识别,以探讨YOLOv5模型应用于车辆检测的可行性。
2.测试环境搭建
2.1下载源码
本次测试采用的是YOLOv5官网提供的最新pytorch框架下的源码,下载完成后将其解压到一个不带中文字符的文件夹下。打开源码文件夹中的requirement.txt文件夹,可以查看YOLOv5运行所需要的环境配置,其中最重要的是Pytorch和torchvision的安装与配置,最新版本的YOLOv5所需要的Pytorch版本要高于1.7.0。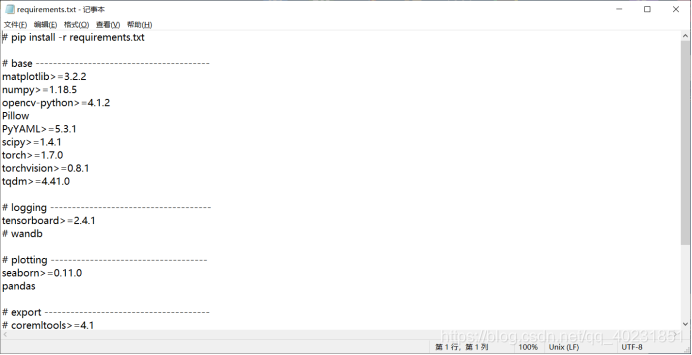
2.2Anaconda与Pycharm的安装与配置
Anaconda是一个管理用于Python开发的包含不同库的虚拟环境的平台,可以高效的管理和创建适用于不同项目的Project interpret。安装完成自带一个根环境,路径在Anaconda的安装目录下,进入后可以在环境管理页面创建新环境,新环境的路径在安装目录下的envs中存储。Pycharm是一种Python IDE,可以方便的帮助用户在使用Python语言开发时提高效率,本项目主要使用Pycharm对源码进行修改。
这两个软件都可以在官网上下载安装,因为本项目使用的Python版本为3.8,对应的Anaconda版本为Anaconda3,安装结束后进入Anaconda Prompt中建立虚拟环境。使用指令
conda create --name pytorch python=3.8
创建一个名称为pytorch,Python版本为3.8的虚拟环境,然后使用指令activate pytorch激活该虚拟环境,当指令行前面括号内由base变为pytorch时,表示该虚拟环境被激活。
2.3CUDA与CUDNN的安装与配置
CUDA是显卡厂商 NVDIA推出的运算平台,CUDA是一种由NVDIA推出的通用并行计算架构,使该架构GPU能够解决复杂的计算问题。CUDNN是用于深度神经网络的GPU加速器。
首先需要将电脑的显卡驱动升级至最新版本,在NVDIA控制面板中查看支持的最高版本的CUDA,打开NVDIA控制面板-帮助-系统信息-组件,可以查看到该版本下支持的最高版本CUDA为10.2.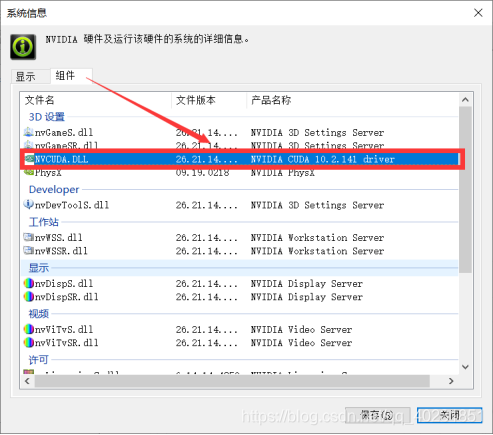
在官网下载对应版本的CUDA以及CUDNN,安装CUDA结束后更改路径,在电脑的高级系统设置-环境变量-Path中新建环境变量,将
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1
两个路径添加进Path中。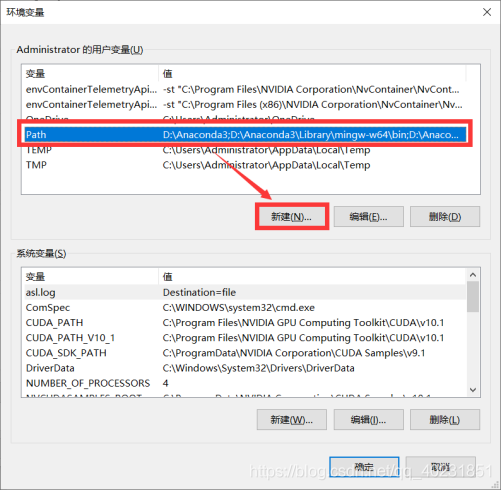
将CUDNN解压后,将其中的所有内容复制到以下路径中:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
打开cmd输入nvcc -V验证CUDA是否安装成功,出现下面界面即为成功。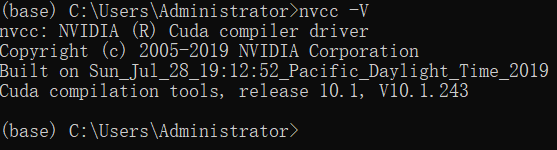
2.4Pytorch和torchvision的安装与配置
在官网上下载适合自己电脑的Pytorch和torchvision版本,这两个软件需要与CUDA和python版本对应。我的环境对应的版本如下图所示:
下载完成后需要进入Anaconda Prompt的虚拟环境中,找到文件对应的路径,安装这两个软件,这里我们使用镜像源来加速安装,采用离线安装的方式,在cmd中输入指令:
pip install 包名 -i http://pypi.douban.com/simple/--trusted-host pypi.douban.com
安装结束后打开python,输入下图所示的指令,没有报错且最后输出为Ture,则安装完成。
2.5其他配置文件的安装
将Pytorch和torchvision安装完成后,最后只需将YOLOv5文件中requirement.txt中剩余的库安装完成就结束了。将requirement.txt文件中的torch和torchvision注释掉,依次安装剩余的库。
安装完成后进入到YOLOV5的官网中下载权重文件,考虑到计算机的性能,本项目使用yolov5s.pt权重文件,下载完成后将权重文件放入./weights文件夹下。
2.6Yolov5运行测试
至此yolov5所需要的环境就全部搭建完成了,然后测试YOLOv5是否能正常运行。我们进入Anaconda Prompt的虚拟环境中,进入YOLOv5的文件路径下,输入指令:
python detect.py
若没有报错则安装成功。
3.测试数据和结果
3.1数据集的准备与源码修改
数据集可以使用labelimg进行手工标注,但考虑到手工标注的工作量巨大,这里我们使用网上的公共数据集。我们进入https://public.roboflow.com/object-detection官网寻找合适的公开数据集,这里我们选用车辆数据集,将其下载下来。每个数据集中包含test、train和valid三个文件夹,分别对应测试、训练和验证数据集,每个数据集包含images和labels两个文件夹,分别对应图片集和标签集。其中测试集有63张图片,训练集有878张图片,验证集有125张图片,数据集共标注5中车辆类型,分别对应Ambulance、Bus、Car、Motorcycle和Truck。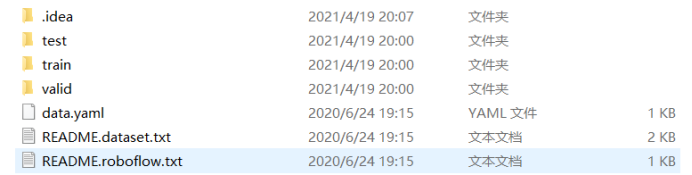
我们在yolov5\yolov5-master\data下面新建一个coco文件夹,用于存放图片集和标签集,在coco文件夹下面新建images和labels文件夹,然后在这两个文件夹下面再新建两个文件夹train2017和val2017分别用于存放训练集和验证集的图片和标签。
数据集设置完成后,我们对yolov5的源码进行修改,主要修改的是yolov5\yolov5-master\data\coco128.yaml文件和yolov5\yolov5-master\models\yolov5s.yaml文件。其中coco128.yaml文件修改类别数量nc后面的数值和类别名称name后面对应的标签名称;yolov5s.yaml文件修改类别数量nc后面的数值。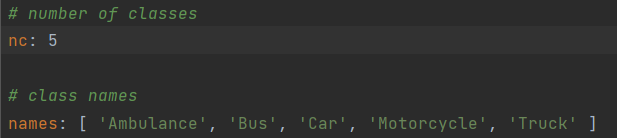
将源码修改结束后就可以开始对数据集进行训练了,在yolov5路径下输入指令
python train.py --img 640--data data/coco128.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 2--epochs 100
进行训练,其中由于电脑性能限制,我们设置batch-size为2,num-worker为0,epoch次数设置为100,以便获得更高的识别准确度。
训练结束后会自动生成last.pt和best.pt两个权重文件,之后我们会使用这两个权重文件进行图像推断测试和视频推断测试。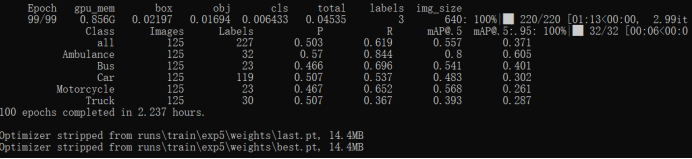
3.2推断测试
我们使用65张图片和1个手机拍摄的视频进行推断测试,这些数据都没有在训练集和验证集中出现过,以此来测试识别的准确性。使用best.pt权重文件进行推断测试,部分测试结果如下图所示:


4.测试分析
4.1YOLOv5车辆检测的优势
总体来说识别车辆准确,适应性强。具体表现如下:
1.对于多车不会漏检,面向镜头的车辆无论是车头、车位还是车身都能被检测到;
2.只出现一部分的车身也能被检测到,但是也要看是否能体现车辆特征;
3.光线强弱对检测影响不大,只要车辆特征明显都可以被检测到。
4.2YOLOv5车辆检测存在的问题
测试中发现了很多问题,主要分为以下几类:
1.存在漏检,某些明显车辆未能检测到;
2.对于距离较远的车辆可能会出现检测不到或者检测准确度较低;
3.车辆错误识别为其他种类;
4.数据集太小,最终识别的准确度不是很高。
5.结论
这个项目表明:对于道路车辆的识别,如果速度和准确度达到实用程度,那么计算机视觉可以用于车辆监测、自动驾驶等。该模型在数据集不大的情况下仍能取得不错的性能,即使对于复杂路况条件下的车辆识别,也能获得良好的检测结果。然而现有模型的局限性可以通过增大调整数据集和使用性能更好的计算机得到解决。
版权归原作者 初级炼丹师666 所有, 如有侵权,请联系我们删除。