
一、前言
今天的文章来自VLDB
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
二、问题
在文章中提出了对于多变量异常检测的几个有挑战性的问题
- 缺乏异常的label
- 大数据量
- 在现实应用中需要尽可能少的推理时间(实时速度要求高)
在本文中,提出了基于transformer的模型TranAD,该模型使用基于注意力机制的序列编码器,利用数据中更广泛的时间趋势快速推断。TranAD使用基于score的自适应来实现鲁棒的多模态特征提取以及通过adversarial training以获得稳定性。此外,模型引入元学习(MAML)允许我们使用有限的数据来训练模型。
三、方法
3.1 问题定义
一个时间序列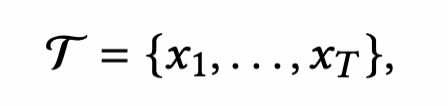 因为是多变量时间序列,每一个X是一个大小为m的向量,即该序列有m个特征。
因为是多变量时间序列,每一个X是一个大小为m的向量,即该序列有m个特征。
该工作定义了两种任务
- Anomaly Detection(检测):给予一个序列来预测目前时刻的异常情况(0或者1),1代表该数据点是异常的。
- Anomaly Diagnosis(诊断): 文中这块用denote which of the modes of the datapoint at the 𝑡-th timestamp are anomalous.来描述,其实就是判断是哪几个维度的特征(mode)导致的实体的异常,诊断到维度模式的程度。
3.2 数据预处理
对数据做normalize,数据的保存形式,是一个实体一个npy文件,维度是(n, featureNum)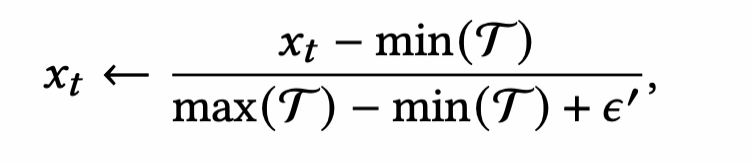
对数据进行滑窗,这里对于windowSize之前的数据并不舍去,而是用前面的数据直接复制,代码如下:
windows = []; w_size = model.n_window
for i, g in enumerate(data):
if i >= w_size: w = data[i-w_size:i]
else: w = torch.cat([data[0].repeat(w_size-i, 1), data[0:i]])
3.3 模型
先看一下transformer的模型图。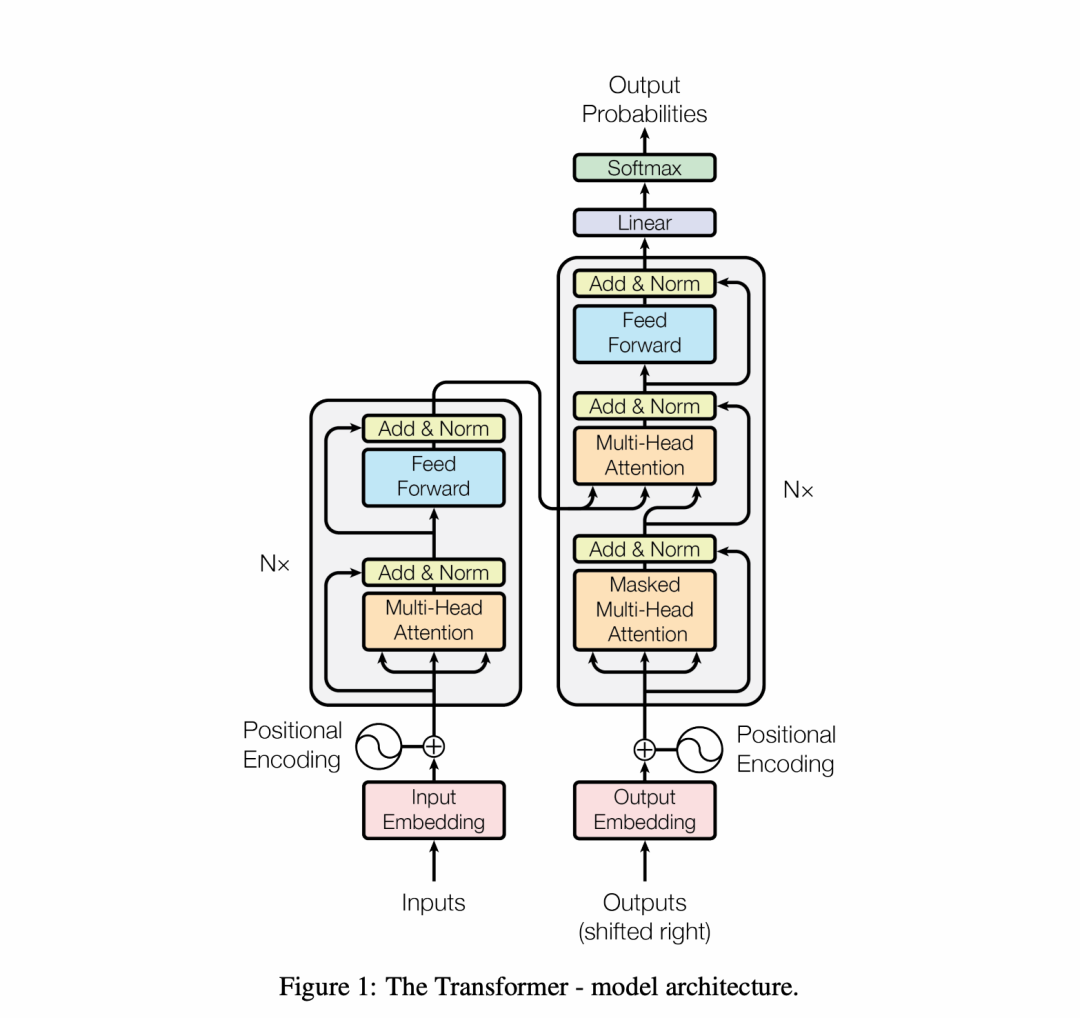
模型本身和TranAD除了有两个decoder其他基本上完全一样,这里结构不赘述了,具体看
- transformer的论文: https://arxiv.org/pdf/1706.03762.pdf
- 代码:https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html (推荐看官方的trasnformer代码,直接看源码实现)
TranAD也省去了decoder中feed forward后的add&Norm,softmax也更改为sigmoid,文中提到sigmoid是把输出的数据拟合到输入数据的归一化状态中,即【0, 1】范围内。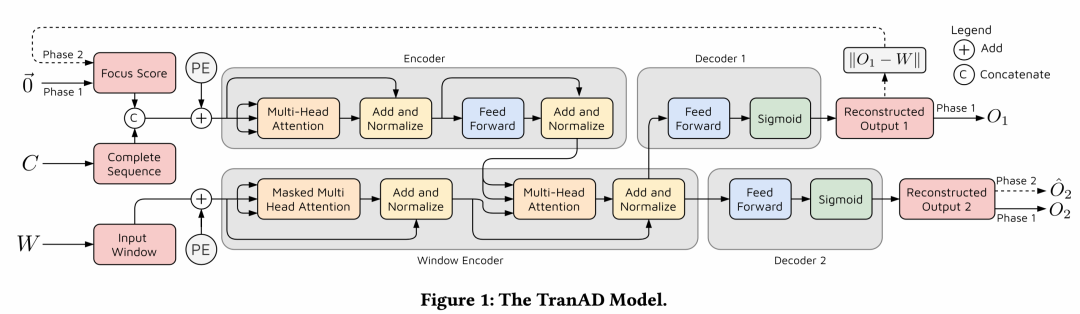
这个图其实十分清晰,这个方法最大的创新不在模型本身,甚至模型没什么改动,主要引入了对抗训练的思想 解释下其中的变量
- W为输入的窗口数据(前面数据预处理页提到了窗口数据的生成)
- Focus Score是和W一样维度的变量,在第一阶段为0矩阵,第二阶段是通过W和O1的计算得出
- C W的最后一个窗口数据
这个C变量,文中这样说。
其实看给的代码最好理解
elif 'TranAD' in model.name:
l = nn.MSELoss(reduction = 'none')
data_x = torch.DoubleTensor(data); dataset = TensorDataset(data_x, data_x)
bs = model.batch if training else len(data)
dataloader = DataLoader(dataset, batch_size = bs)
n = epoch + 1; w_size = model.n_window
l1s, l2s = [], []
if training:
for d, _ in dataloader:
local_bs = d.shape[0]
window = d.permute(1, 0, 2) // 这个就是W
elem = window[-1, :, :].view(1, local_bs, feats) // 这个就是C
z = model(window, elem)
l1 = l(z, elem) if not isinstance(z, tuple) else (1 / n) * l(z[0], elem) + (1 - 1/n) * l(z[1], elem)
if isinstance(z, tuple): z = z[1]
l1s.append(torch.mean(l1).item())
loss = torch.mean(l1)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
scheduler.step()
tqdm.write(f'Epoch {epoch},\tL1 = {np.mean(l1s)}')
return np.mean(l1s), optimizer.param_groups[0]['lr']
这里比较大的创新在于第一阶段和第二阶段的训练。
- 第一阶段:为了更好的重构序列数据,和大部分encoder-decoder模型的作用没有什么不同
- 第二阶段:引入对抗性训练的思想。
解读这个训练阶段之前,先把模型代码过一下。
class TranAD(nn.Module):
def __init__(self, feats):
super(TranAD, self).__init__()
self.name = 'TranAD'
self.lr = lr
self.batch = 128
self.n_feats = feats
self.n_window = 10
self.n = self.n_feats * self.n_window
self.pos_encoder = PositionalEncoding(2 * feats, 0.1, self.n_window)
encoder_layers = TransformerEncoderLayer(d_model=2 * feats, nhead=feats, dim_feedforward=16, dropout=0.1)
self.transformer_encoder = TransformerEncoder(encoder_layers, 1)
decoder_layers1 = TransformerDecoderLayer(d_model=2 * feats, nhead=feats, dim_feedforward=16, dropout=0.1)
self.transformer_decoder1 = TransformerDecoder(decoder_layers1, 1)
decoder_layers2 = TransformerDecoderLayer(d_model=2 * feats, nhead=feats, dim_feedforward=16, dropout=0.1)
self.transformer_decoder2 = TransformerDecoder(decoder_layers2, 1)
self.fcn = nn.Sequential(nn.Linear(2 * feats, feats), nn.Sigmoid())
def encode(self, src, c, tgt):
src = torch.cat((src, c), dim=2)
src = src * math.sqrt(self.n_feats)
src = self.pos_encoder(src)
memory = self.transformer_encoder(src)
tgt = tgt.repeat(1, 1, 2)
return tgt, memory
def forward(self, src, tgt):
# Phase 1 - Without anomaly scores
c = torch.zeros_like(src)
x1 = self.fcn(self.transformer_decoder1(*self.encode(src, c, tgt)))
# Phase 2 - With anomaly scores
c = (x1 - src) ** 2
x2 = self.fcn(self.transformer_decoder2(*self.encode(src, c, tgt)))
return x1, x2
从代码可以看出来,虽然图中画的Window Encoder对于Decoder1和2来说是shared,但其实是分开的。
分别用transformer_decoder1和transformer_decoder2实现的。
第一阶段 Input Reconstruction
很多传统的encoder-decoder模型经常不能够获取short-term的趋势,会错过一些偏差很小的异常,为了解决这个问题,采用两个阶段的方式来进行重构。
在第一阶段,模型的目标是生成和输入窗口数据近似的reconstruction。对于这个推断的偏差,称之为focus score,有助于Transformer Encoder内部的注意力网络提取时间趋势,关注偏差高的子序列。(理解其实就是用与真实值的残差去拟合偏差高的序列,在第二阶段)
第一阶段下的focus score是0矩阵,与输入windows数据一致,输出O,与W计算L2 loss作为第一阶段的loss函数。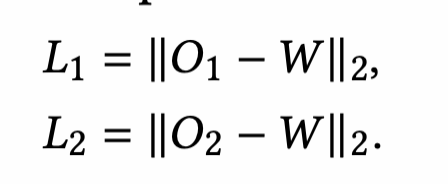
注意代码中的encode的部分,是将C和focus score直接concat再乘以sqrt(featureNum),之后再经过位置编码,其实文中只顺带说了一下而已,没有说为什么这么做,我个人倾向于为了将C和focus score信息放在一起,已concat常见的尝试揉在了一起。
第二阶段
将第一阶段O1与W的L2 loss作为focus score,在进行之前的步骤。这可以在第二阶段调整注意力权重,并为特定输入子序列提供更高的神经网络激活,以提取短期的时间趋势(这句话是文中说的,和我前面的那里理解基本上差不多)。
之后算是比较重点的地方了,引入对抗训练的思想,来设计第二阶段的loss这个地方十分的绕,建议大家读读原文的3.4 Offline Two-Phase Adversarial Training的Evolving Training Objective部分
- 第二个decoder尽力去区分输入和第一阶段decoder1的重建,所以是max O2这个L2 loss(这里就会有疑问,decoder1的重建不是O1吗?为啥要max ||O2-W||2? 这里我从作者的角度去理解,其实他是一种条件近似转移,因为O1和O2再第一阶段都是近似W,那区别于第一阶段的decoder1的重建O1,其实就是区别于O2)
- 第一个decoder尽力去通过创建一个接近W的O1来迷惑decoder2(其实就是想让这个focus score接近于0矩阵),其实就是min(W和O1),其实转移也就是min(W和O2),所以得到了下面这个公式
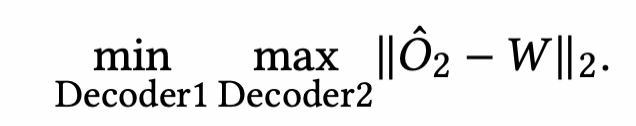
可以分解为: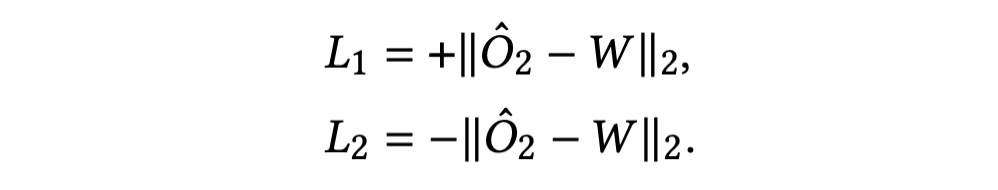
再加上第一阶段的loss,总loss就是: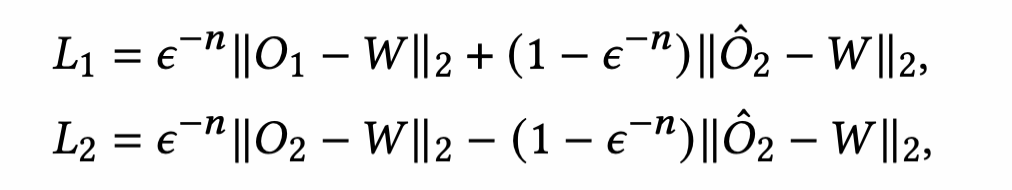
这里又对decoder1和decoder2做了明确的解释:
看代码理解
之后我们看下代码里的区别,代码里其实根本就没有算O2,只算了O1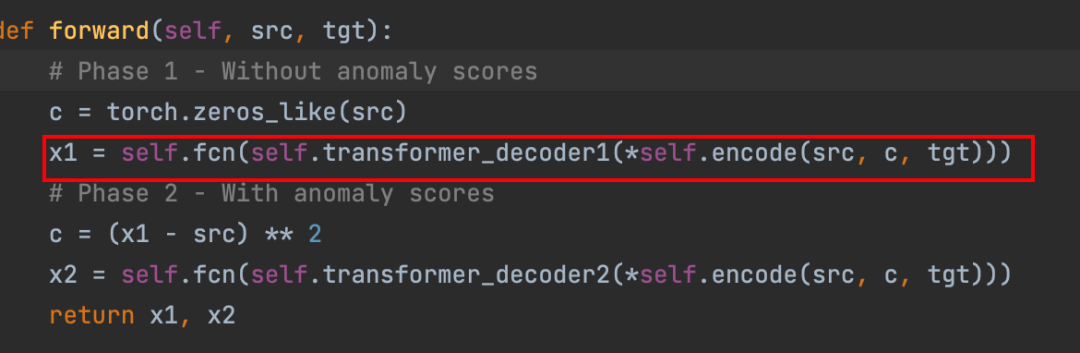
在做反向传播,优化参数的时候也只算了L1的总loss,没有算L2
 这里有个z的type判别,因为做了很多消融实验,不是最终的模型,最终就是后面那个L1loss,其中前面有个参数,是epoch+1,参数会随着训练轮数的增加,倒数慢慢变小,即前面的第一阶段的loss慢慢权重减小,而第二阶段的loss慢慢权重增大。
这里有个z的type判别,因为做了很多消融实验,不是最终的模型,最终就是后面那个L1loss,其中前面有个参数,是epoch+1,参数会随着训练轮数的增加,倒数慢慢变小,即前面的第一阶段的loss慢慢权重减小,而第二阶段的loss慢慢权重增大。
其实这也给出了一个我个人感觉非常合理的解释,因为第二阶段要附属于第一阶段的训练,应该先让O1和O2接近于W,之后才能去用对抗训练,这样才会让第二阶段训练有效,否则就混乱了。
现在再理解下这个,就完全明白了:
 测试阶段,引入了阈值自动选择(POT,但代码中没有看到这的设置),以及score的计算
测试阶段,引入了阈值自动选择(POT,但代码中没有看到这的设置),以及score的计算
四、结果
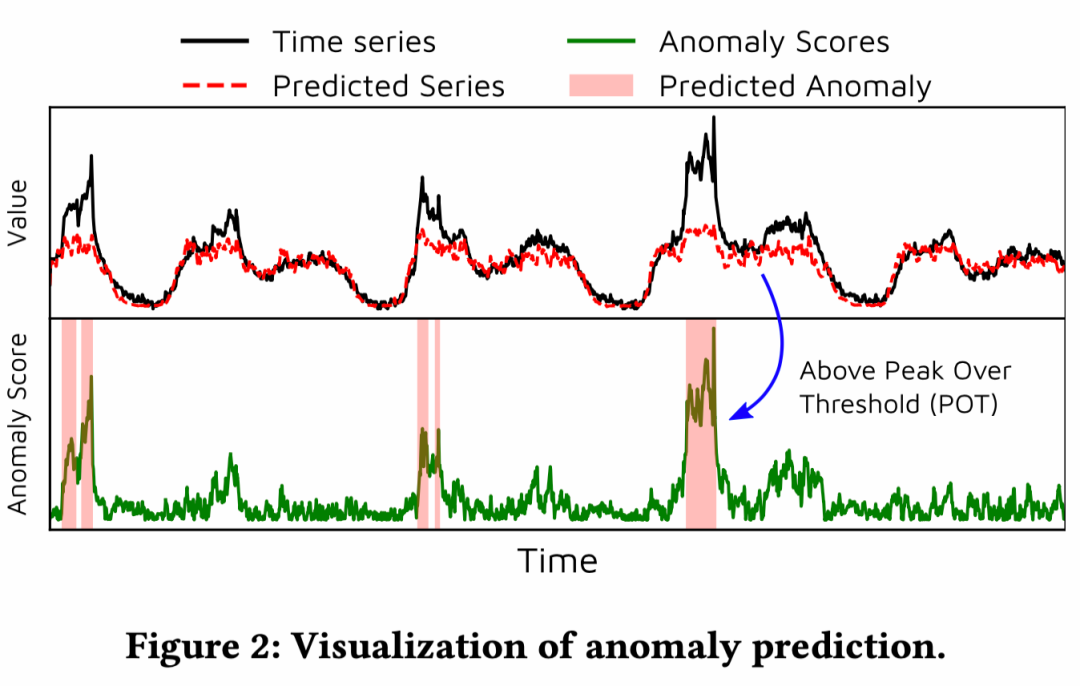
对于异常的定义,是score大于阈值就是异常。
 任意一个维度有异常就算作是异常,感觉这样描述本质上还是单序列的异常检测,没有从根本解决多变量的问题。
任意一个维度有异常就算作是异常,感觉这样描述本质上还是单序列的异常检测,没有从根本解决多变量的问题。
4.1 数据集
 大部分常用数据集
大部分常用数据集
4.2 结果
每一个维度都有reconstruction,并且每个维度都有对应的score,不得不说这个图示还是很清晰的,构建很清晰易懂。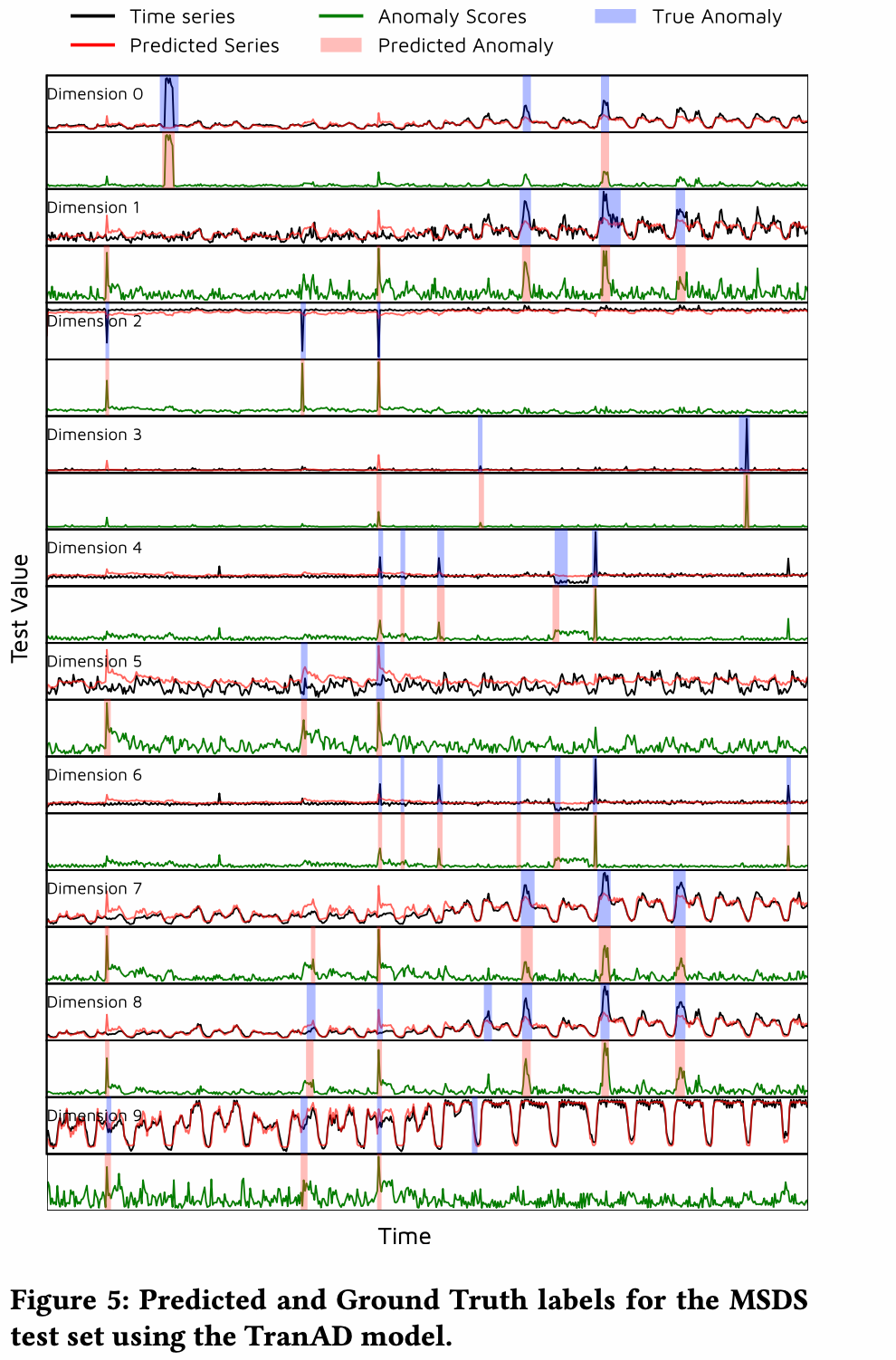
后面还有各种实验,参数灵敏度、数据集等实验,这篇paper实验部分还是很满的,整体来说,工作量还是拉满的。
本文也对两种任务都做了实验,异常检测部分不用说了,常规操作,诊断部分采用 HitRate and NDCG两种指标进行root cause的检验。
五、总结和思考
- 对于代码,给出了每个对比模型和数据集,可以为后续实验做参考,并给出了整体消融实验的代码,代码还是很全面的,虽然有一些杂乱,但对于一个要做这个方向的同学来说,还是相当于巨人的肩膀的。
- 把transformer和对抗性训练放在一起,确实是很新颖的想法
- 在代码处O2部分为何省略存疑,以及第二阶段的loss,其实有点套的生硬,为何不都引到O1上,假设引到O1上,那loss1就只剩下L2 loss了,可能在公式上就并非这种对称了。
- 存疑的点就是 代码中在训练过程中并未对L2进行训练,这样的话O2是否像理论说的那样输出工作?
- 诊断的定义和诊断任务的探索,其实是有一些生硬的,并且也没完全说清楚,当然这篇文章标题是anomaly detection,其实并未将diagnosis算重点,所以这个也可以接受。
- 文章的标题是多变量的异常检测,其实虽然可以应用在多变量上,但实际还是单变量的异常来判别是否是多变量的整体实体的异常,本质还是用单变量问题解决多变量(这里可以探究一下,因为最终的score是由loss决定,而loss本身的维度是和输入的window数据一样的维度,意思就是每一个特征维度有一个score,所以其实得到的score还是单变量的score而并非实体的score,所以这里作者也没有探究多变量pattern的情况,可能存在多个变量异常,但只是一个跳变的pattern,不足以让整体异常的情况。)
- 代码里也没给出POT的相关代码。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书
版权归原作者 AI蜗牛车 所有, 如有侵权,请联系我们删除。