
Apache Hive 系列文章
1、apache-hive-3.1.2简介及部署(三种部署方式-内嵌模式、本地模式和远程模式)及验证详解
2、hive相关概念详解–架构、读写文件机制、数据存储
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
4、hive的使用示例详解-事务表、视图、物化视图、DDL(数据库、表以及分区)管理详细操作
5、hive的load、insert、事务表使用详解及示例
6、hive的select(GROUP BY、ORDER BY、CLUSTER BY、SORT BY、LIMIT、union、CTE)、join使用详解及示例
7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
8、hive的关系运算、逻辑预算、数学运算、数值运算、日期函数、条件函数和字符串函数的语法与使用示例详解
9、hive的explode、Lateral View侧视图、聚合函数、窗口函数、抽样函数使用详解
10、hive综合示例:数据多分隔符(正则RegexSerDe)、url解析、行列转换常用函数(case when、union、concat和explode)详细使用示例
11、hive综合应用示例:json解析、窗口函数应用(连续登录、级联累加、topN)、拉链表应用
12、Hive优化-文件存储格式和压缩格式优化与job执行优化(执行计划、MR属性、join、优化器、谓词下推和数据倾斜优化)详细介绍及示例
13、java api访问hive操作示例
文章目录
本文主要介绍了hive的功能、部署方式、三种部署方式的实现及验证和hive的简单示例。
本文依赖是hadoop环境好用,相关内容参看hadoop专栏。
本文分为四个部分,即hive介绍、hive的几种部署方式及区别、三种部署方式及验证和hive的简单示例。
一、hive介绍
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。Hive由Facebook实现并开源。
1、Hive作用或好处
使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写MapReduce,减少开发人员的学习成本
- 支持自定义函数,功能扩展很方便
- 基于Hadoop,擅长存储分析海量数据集
2、Hive与Hadoop的关系
Apache Hive作为一款大数据时代的数据仓库软件,具备数据存储与分析能力,都是通过hadoop来实现的。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
Hive的用户专注于编写HQL,Hive转换成为MapReduce程序完成对数据的分析。
二、部署方式介绍
1、hive元数据介绍
1)、Metadata
Metadata即元数据,元数据包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
2)、Metastore
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
2、metastore三种配置方式
metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。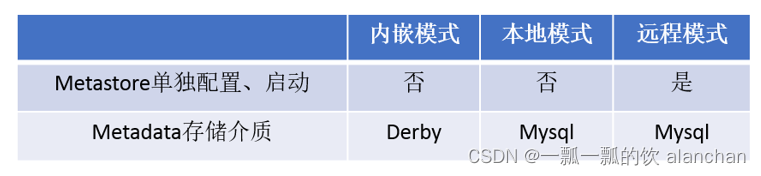
1)、内嵌模式
内嵌模式(Embedded Metastore)是metastore默认部署模式。此种模式下,元数据存储在内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动。
不需要额外起Metastore服务。
但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。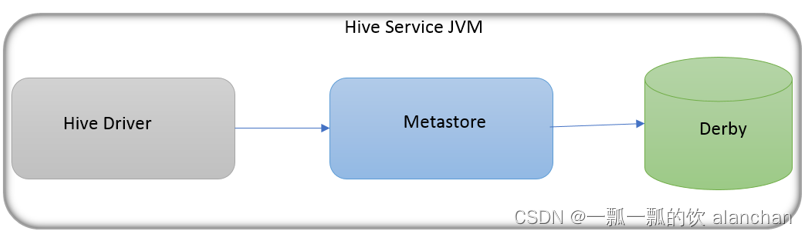
2)、本地模式
本地模式(Local Metastore)下,Hive Metastore服务与主HiveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信。
本地模式采用外部数据库来存储元数据,推荐使用MySQL。
hive根据hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
缺点是每启动一次hive服务,都内置启动了一个metastore。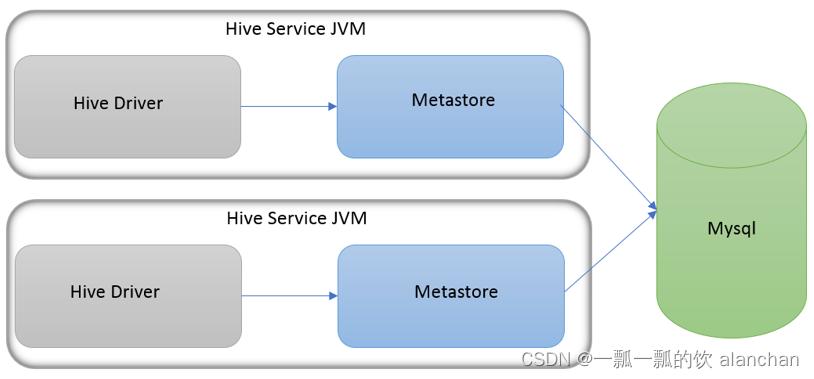
3)、远程模式
远程模式(Remote Metastore)下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。
在生产环境中,建议用远程模式来配置Hive Metastore。
在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。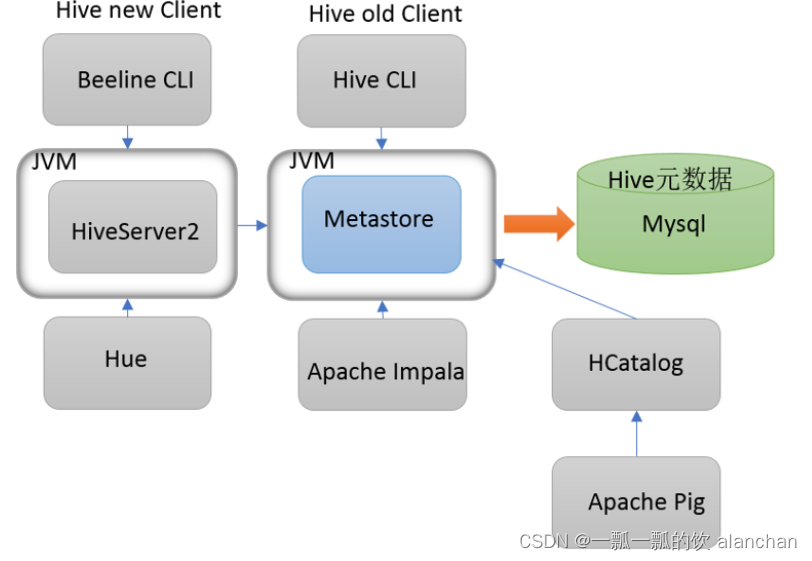
三、部署及验证
1、安装前准备
由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
1)、服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装等。
2)、Hadoop集群
启动Hive之前必须先启动Hadoop集群。特别要注意,需等待HDFS 安全模式关闭之后再启动运行Hive。
Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
2、内嵌模式部署及验证
# 1、上传解压安装包cd /usr/local/bigdata/
tar zxvf /usr/local/bigdata/apache-hive-3.1.2-bin.tar.gz -C /usr/local/bigdata
#2、解决hadoop、hive之间guava版本差异# 如果你使用的版本不存在该情况,则不需要处理,本示例使用的是hive3.1.2[alanchan@server4 apache-hive-3.1.2-bin]$ bin/schematool -dbType derby -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in[jar:file:/usr/local/bigdata/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:518)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:430)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.<init>(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)cd /usr/local/bigdata/apache-hive-3.1.2-bin
rm -rf lib/guava-19.0.jar
cp /usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/bigdata/apache-hive-3.1.2-bin/lib/
#3、修改hive环境变量文件 添加Hadoop_HOMEcd /usr/local/bigdata/apache-hive-3.1.2-bin/conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
exportHADOOP_HOME=/usr/local/bigdata/hadoop-3.1.4
exportHIVE_CONF_DIR=/usr/local/bigdata/apache-hive-3.1.2-bin/conf
exportHIVE_AUX_JARS_PATH=/usr/local/bigdata/apache-hive-3.1.2-bin/lib
#4、初始化metadatacd /usr/local/bigdata/apache-hive-3.1.2-bin
bin/schematool -dbType derby -initSchema
[alanchan@server4 apache-hive-3.1.2-bin]$ bin/schematool -dbType derby -initSchema
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.derby.sql
Initialization script completed
schemaTool completed
#5、启动hive服务
bin/hive
[alanchan@server4 apache-hive-3.1.2-bin]$ bin/hive
Hive Session ID = 4a5010a3-8e5a-4183-8f71-3cfd8e28f091
hive> show databases;
OK
2022-10-17 10:38:20,705 INFO [29002c9d-fcc2-4f03-824e-0795fcb33b80 main] lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2022-10-17 10:38:20,722 INFO [29002c9d-fcc2-4f03-824e-0795fcb33b80 main] lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 5dbdddb8cfb544e58b4e0b9664b9d1b66657faf5]
default
Time taken: 0.622 seconds, Fetched: 1 row(s)# 如果第一次没有初始化成功,可能需要将全部的文件删除,重新解压、部署,否则会出现异常,而不能正常使用
org.datanucleus.store.rdbms.exceptions.MissingTableException: Required table missing : “VERSION” in Catalog “” Schema “”. DataNucleus requires this table to perform its persistence operations.
# 注意:Hive3版本需要用户手动进行元数据初始化动作。内嵌模式下,判断是否初始化成功的依据是执行命令之后输出信息和执行命令的当前路径下是否有文件产生。
3、本地模式部署及验证
本地模式和内嵌模式最大的区别就是:本地模式使用mysql来存储元数据。
如果环境具备mysql,该步骤则可忽略。
1)、Mysql安装
#卸载Centos7自带mariadbrpm -qa|grep mariadb
mariadb-libs-5.5.64-1.el7.x86_64
rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
#创建mysql安装包存放点mkdir /usr/local/bigdata/mysql
#上传mysql-5.7.29安装包到上述文件夹下、解压tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
#执行安装
yum -y install libaio
rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm
#初始化mysql
mysqld --initialize
#更改所属组chown mysql:mysql /var/lib/mysql -R
#启动mysql
systemctl start mysqld.service
#查看生成的临时root密码cat /var/log/mysqld.log
#这行日志的最后就是随机生成的临时密码[Note] A temporary password is generated for root@localhost: o+TU+KDOm004
#修改mysql root密码、授权远程访问
mysql -u root -p
Enter password: #这里输入在日志中生成的临时密码#更新root密码 设置为hadoop
mysql> alter user user() identified by "hadoop";
Query OK, 0 rows affected (0.00 sec)#授权
mysql> use mysql;
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;#mysql的启动和关闭 状态查看
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
#建议设置为开机自启动服务
systemctl enable mysqld
#查看是否已经设置自启动成功
systemctl list-unit-files |grep mysqld
2)、Hive部署及验证
# 1、上传解压安装包cd /usr/local/bigdata/
tar zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/bigdata/mysql
# 2、解决hadoop、hive之间guava版本差异cd /usr/local/bigdata/apache-hive-3.1.2-bin
rm -rf lib/guava-19.0.jar
cp /usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
# 3、添加mysql jdbc驱动到hive安装包lib/文件下
mysql-connector-java-5.1.32.jar
# 4、修改hive环境变量文件 添加Hadoop_HOMEcd /usr/local/bigdata/apache-hive-3.1.2-bin/conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
exportHADOOP_HOME=/usr/local/bigdata/hadoop-3.1.4
exportHIVE_CONF_DIR=/usr/local/bigdata/apache-hive-3.1.2-bin/conf
exportHIVE_AUX_JARS_PATH=/usr/local/bigdata/apache-hive-3.1.2-bin/lib
# 5、新增hive-site.xml 配置mysql等相关信息vim hive-site.xml
# 参考下个目录关于hive-site.xml的内容# 6、初始化metadatacd /usr/local/bigdata/apache-hive-3.1.2-bin
bin/schematool -initSchema -dbType mysql -verbos
#初始化是否成功验证标准:初始化成功会在mysql中创建74张表# 7、启动hive服务
bin/hive
[alanchan@server4 apache-hive-3.1.2-bin]$ bin/hive
Hive Session ID = 7627b84b-43f3-447d-8cbd-1d6b601a4934
Logging initialized using configuration in jar:file:/usr/local/bigdata/apache-hive-3.1.2-bin/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true2022-10-17 10:52:07,673 INFO [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored
2022-10-17 10:52:08,423 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:08,424 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:08,425 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:08,425 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:08,425 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:08,425 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:09,741 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:09,741 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:09,742 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:09,742 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:09,742 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
2022-10-17 10:52:09,742 WARN [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignored
Hive Session ID = 7c110419-6517-42f5-ae1f-f21f0d755278
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show databases;
OK
2022-10-17 10:52:18,927 INFO [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2022-10-17 10:52:18,929 INFO [7627b84b-43f3-447d-8cbd-1d6b601a4934 main] lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 5dbdddb8cfb544e58b4e0b9664b9d1b66657faf5]
default
Time taken: 0.889 seconds, Fetched: 1 row(s)
3)、Hive-site.xml
<configuration><!-- 存储元数据mysql相关配置 --><property><name>javax.jdo.option.ConnectionURL</name><value> jdbc:mysql://192.168.10.44:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- 关闭元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><!-- 关闭元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property></configuration>
4、远程模式部署及验证
本示例中选择server4作为hive安装的机器。大家可以根据自己实际情况调整机器位置,注意主机名和IP和等信息的变更。
1)、Mysql安装
#卸载Centos7自带mariadbrpm -qa|grep mariadb
mariadb-libs-5.5.64-1.el7.x86_64
rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
#创建mysql安装包存放点mkdir /usr/local/bigdata/mysql
#上传mysql-5.7.29安装包到上述文件夹下、解压tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
#执行安装
yum -y install libaio
rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm
#初始化mysql
mysqld --initialize
#更改所属组chown mysql:mysql /var/lib/mysql -R
#启动mysql
systemctl start mysqld.service
#查看生成的临时root密码cat /var/log/mysqld.log
#这行日志的最后就是随机生成的临时密码[Note] A temporary password is generated for root@localhost: o+TU+KDOm004
#修改mysql root密码、授权远程访问
mysql -u root -p
Enter password: #这里输入在日志中生成的临时密码#更新root密码 设置为hadoop
mysql> alter user user() identified by "hadoop";
Query OK, 0 rows affected (0.00 sec)#授权
mysql> use mysql;
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;#mysql的启动和关闭 状态查看
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
#建议设置为开机自启动服务
systemctl enable mysqld
#查看是否已经设置自启动成功
systemctl list-unit-files |grep mysqld
2)、Hive部署及验证
# 1、上传解压安装包cd /usr/local/bigdata/
tar zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/bigdata
# 2、解决hadoop、hive之间guava版本差异cd /usr/local/bigdata/apache-hive-3.1.2-bin
rm -rf lib/guava-19.0.jar
cp /usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
# 3、添加mysql jdbc驱动到hive安装包lib/文件下
mysql-connector-java-5.1.32.jar
# 4、修改hive环境变量文件 添加Hadoop_HOMEcd /usr/local/bigdata/apache-hive-3.1.2-bin/conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
exportHADOOP_HOME=/usr/local/bigdata/hadoop-3.1.4
exportHIVE_CONF_DIR=/usr/local/bigdata/apache-hive-3.1.2-bin/conf
exportHIVE_AUX_JARS_PATH=/usr/local/bigdata/apache-hive-3.1.2-bin/lib
# 5、新增hive-site.xml 配置mysql等相关信息vim hive-site.xml
(见下文)
# 6、初始化metadatacd /usr/local/bigdata/apache-hive-3.1.2-bin
bin/schematool -initSchema -dbType mysql -verbos
#初始化是否成功验证标准:初始化成功会在mysql中创建74张表
3)、Hive-site.xml
<configuration><!-- 存储元数据mysql相关配置 --><property><name>javax.jdo.option.ConnectionURL</name><value> jdbc:mysql://192.168.10.44:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- H2S运行绑定host --><property><name>hive.server2.thrift.bind.host</name><value>server4</value></property><!-- 远程模式部署metastore 服务地址 --><property><name>hive.metastore.uris</name><value>thrift://server4:9083</value></property><!-- 关闭元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><!-- 关闭元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property></configuration>
4)、启动及验证
如果在远程模式下,直接运行hive服务,在执行操作的时候会报错,错误信息如下:
在远程模式下,必须首先启动Hive metastore服务才可以使用hive。因为metastore服务和hive server是两个单独的进程了。
#前台启动
/usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service metastore
# 关闭该服务则使用命令ctrl+c即可#后台启动(进程挂起)#输入命令回车执行 再次回车 进程将挂起后台# 关闭该服务则使用命令jps找到该服务,然后killnohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service metastore > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/hive.log 2>&1&[alanchan@server4 ~]$ nohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service metastore > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/hive.log 2>&1&[1]14961[alanchan@server4 ~]$ jps
14961 RunJar
24020 DataNode
29189 HRegionServer
3990 RunJar
24166 JournalNode
15144 Jps
21979 NodeManager
#前台启动开启debug日志
/usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
hive> show databases;
OK
2022-10-17 11:14:09,393 INFO [04d4371b-c470-4894-9f04-21cb25d9401a main] lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2022-10-17 11:14:09,396 INFO [04d4371b-c470-4894-9f04-21cb25d9401a main] lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 5dbdddb8cfb544e58b4e0b9664b9d1b66657faf5]
default
Time taken: 0.37 seconds, Fetched: 1 row(s)
后台启动的输出日志信息,在/usr/local/bigdata/apache-hive-3.1.2-bin/logs/hive.log。
四、hive简单示例
1、Hive Client、Hive Beeline Client
- 第一代客户端(deprecated不推荐使用):$HIVE_HOME/bin/hive, 是一个 shellUtil。 主要功能: 一是可用于以交互或批处理模式运行Hive查询; 二是用于Hive相关服务的启动,比如metastore服务。
- 第二代客户端(recommended 推荐使用):$HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。 Beeline Shell在嵌入式模式和远程模式下均可工作。在嵌入式模式下,它运行嵌入式 Hive(类似于Hive Client),而远程模式下beeline通过 Thrift 连接到单独的 HiveServer2 服务上,这也是官方推荐在生产环境中使用的模式。
2、HiveServer、HiveServer2服务
HiveServer、HiveServer2都是Hive自带的两种服务,允许客户端在不启动CLI的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果。但是,HiveServer不能处理多于一个客户端的并发请求。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer已经被废弃。
HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。
3、Hive服务和客户端关系
HiveServer2通过Metastore服务读写元数据。所以在远程模式下,启动HiveServer2之前必须先首先启动metastore服务。
远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive。而Hive Client是通过Metastore服务访问的。
具体关系如下: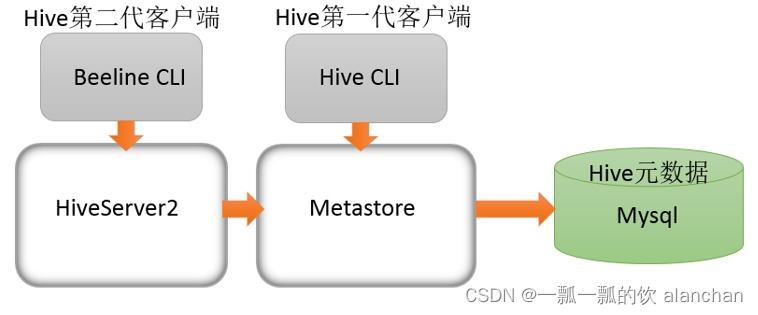
4、Hive Client使用
在hive安装包的bin目录下,有hive提供的第一代客户端 bin/hive。该客户端可以访问hive的metastore服务,从而达到操作hive的目的。
如果您是远程模式部署,手动启动运行metastore服务。如果是内嵌模式和本地模式,直接运行bin/hive,metastore服务会内嵌一起启动。
可以直接在启动Hive metastore服务的机器上使用bin/hive客户端操作,此时不需要进行任何配置。
如果需要在其他机器上通过bin/hive访问hive metastore服务,只需要在该机器的hive-site.xml配置中添加metastore服务地址即可。
具体配置如下:
/usr/local/bigdata/apache-hive-3.1.2-bin
#上传hive安装包到另一个机器上,比如server3:cd /usr/local/bigdata/
tar zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/bigdata
#解决hadoop、hive之间guava版本差异cd /usr/local/bigdata/apache-hive-3.1.2-bin/
rm -rf /usr/local/bigdata/apache-hive-3.1.2-bin/lib/guava-19.0.jar
cp /usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/bigdata/apache-hive-3.1.2-bin/lib/
#修改hive环境变量文件 添加Hadoop_HOMEcd /usr/local/bigdata/hive/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
exportHADOOP_HOME=/usr/local/bigdata/hadoop-3.1.4
#添加metastore服务地址cd /usr/local/bigdata/apache-hive-3.1.2-bin/conf/
vim hive-site.xml
<configuration><property><name>hive.metastore.uris</name><value>thrift://server4:9083</value></property></configuration>
5、Hive Beeline Client使用
在hive运行的服务器(server4)上,首先启动metastore服务,然后启动hiveserver2服务。
#先启动metastore服务 然后启动hiveserver2服务。默认的日志级别nohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service metastore > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/metastore.log 2>&1&nohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/hiveserver2.log 2>&1&#如果设置日志级别,则执行下面的命令nohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service metastore > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/metastore.log --hiveconf hive.root.logger=WARN,console 2>&1&nohup /usr/local/bigdata/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 > /usr/local/bigdata/apache-hive-3.1.2-bin/logs/hiveserver2.log --hiveconf hive.root.logger=WARN,console 2>&1&
Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://server4:10000
! connect jdbc:hive2://server4:10000
#本机访问与其他的服务器访问方式一样,只是运行环境配置不同#server4访问[alanchan@server4 bin]$ beeline
Beeline version 3.1.2 by Apache Hive
beeline>! connect jdbc:hive2://server4:10000
Connecting to jdbc:hive2://server4:10000
Enter username for jdbc:hive2://server4:10000: alanchan(hsfs环境配置的用户名和密码)
Enter password for jdbc:hive2://server4:10000: ********(rootroot)
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://server4:10000> show databases;
INFO : Compiling command(queryId=alanchan_20221017134041_54f59c4d-883b-4a15-9e74-3f0ecd120009): show databases
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017134041_54f59c4d-883b-4a15-9e74-3f0ecd120009); Time taken: 0.902 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017134041_54f59c4d-883b-4a15-9e74-3f0ecd120009): show databases
INFO : Starting task [Stage-0:DDL]in serial mode
INFO : Completed executing command(queryId=alanchan_20221017134041_54f59c4d-883b-4a15-9e74-3f0ecd120009); Time taken: 0.025 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (1.244 seconds)#server3机器上访问[alanchan@server3 bin]$ beeline
Beeline version 3.1.2 by Apache Hive
beeline>! connect jdbc:hive2://server4:10000
Connecting to jdbc:hive2://server4:10000
Enter username for jdbc:hive2://server4:10000: alanchan
Enter password for jdbc:hive2://server4:10000: ********(rootroot)
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://server4:10000> show databases;
INFO : Compiling command(queryId=alanchan_20221017134402_d2beee57-2d5e-474f-878a-a6ee5fbc4892): show databases
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017134402_d2beee57-2d5e-474f-878a-a6ee5fbc4892); Time taken: 0.015 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017134402_d2beee57-2d5e-474f-878a-a6ee5fbc4892): show databases
INFO : Starting task [Stage-0:DDL]in serial mode
INFO : Completed executing command(queryId=alanchan_20221017134402_d2beee57-2d5e-474f-878a-a6ee5fbc4892); Time taken: 0.005 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (0.109 seconds)
6、创建数据库、表和插入一条数据
create database test;--创建数据库
show databases;--列出所有数据库
use test;--切换数据库
-建表
create table t_student(id int,name varchar(255));
--插入一条数据
insert into table t_student values(1,"alan");
--查询表数据
select * from t_student;0: jdbc:hive2://server4:10000> insert into table t_student values(1,"alan");
INFO : Compiling command(queryId=alanchan_20221017143532_15c65250-5027-49a7-ada7-513cfa9cecdf): insert into table t_student values(1,"alan")
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:int, comment:null), FieldSchema(name:_col1, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017143532_15c65250-5027-49a7-ada7-513cfa9cecdf); Time taken: 0.373 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017143532_15c65250-5027-49a7-ada7-513cfa9cecdf): insert into table t_student values(1,"alan")
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = alanchan_20221017143532_15c65250-5027-49a7-ada7-513cfa9cecdf
INFO : Total jobs=3
INFO : Launching Job 1 out of 3
INFO : Starting task [Stage-1:MAPRED]in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO :set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO :set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO :set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1665988516927_0001
INFO : Executing with tokens: []
INFO : The url to track the job: http://server1:8088/proxy/application_1665988516927_0001/
INFO : Starting Job = job_1665988516927_0001, Tracking URL = http://server1:8088/proxy/application_1665988516927_0001/
INFO : Kill Command = /usr/local/bigdata/hadoop-3.1.4/bin/mapred job -kill job_1665988516927_0001
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO :2022-10-17 14:36:30,823 Stage-1 map =0%, reduce =0%
INFO :2022-10-17 14:36:32,909 Stage-1 map =100%, reduce =100%, Cumulative CPU 3.47 sec
INFO : MapReduce Total cumulative CPU time: 3 seconds 470 msec
INFO : Ended Job = job_1665988516927_0001
INFO : Starting task [Stage-7:CONDITIONAL]in serial mode
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Starting task [Stage-4:MOVE]in serial mode
INFO : Moving data to directory hdfs://HadoopHAcluster/user/hive/warehouse/test.db/t_student/.hive-staging_hive_2022-10-17_14-35-32_439_6346816882425817085-7/-ext-10000 from hdfs://HadoopHAcluster/user/hive/warehouse/test.db/t_student/.hive-staging_hive_2022-10-17_14-35-32_439_6346816882425817085-7/-ext-10002
INFO : Starting task [Stage-0:MOVE]in serial mode
INFO : Loading data to table test.t_student from hdfs://HadoopHAcluster/user/hive/warehouse/test.db/t_student/.hive-staging_hive_2022-10-17_14-35-32_439_6346816882425817085-7/-ext-10000
INFO : Starting task [Stage-2:STATS]in serial mode
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.47 sec HDFS Read: 23756 HDFS Write: 915260 SUCCESS
INFO : Total MapReduce CPU Time Spent: 3 seconds 470 msec
INFO : Completed executing command(queryId=alanchan_20221017143532_15c65250-5027-49a7-ada7-513cfa9cecdf); Time taken: 62.003 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (62.384 seconds)0: jdbc:hive2://server4:10000>select * from t_student;
INFO : Compiling command(queryId=alanchan_20221017143649_781a864c-fa0f-4578-a9f2-1e6011a2109d): select * from t_student
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_student.id, type:int, comment:null), FieldSchema(name:t_student.name, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017143649_781a864c-fa0f-4578-a9f2-1e6011a2109d); Time taken: 0.147 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017143649_781a864c-fa0f-4578-a9f2-1e6011a2109d): select * from t_student
INFO : Completed executing command(queryId=alanchan_20221017143649_781a864c-fa0f-4578-a9f2-1e6011a2109d); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------------+-----------------+
| t_student.id | t_student.name |
+---------------+-----------------+
|1| alan |
+---------------+-----------------+
1 row selected (0.21 seconds)

7、将结构化数据映射成为表
--建表语句 增加分隔符指定语句
create table t_user(id int,name varchar(255),age int,city varchar(255))
row format delimited
fields terminated by ',';#把user.txt文件从本地文件系统上传到hdfs,hive文件解析与上传的文件名无关,即创建的表名称与上传的文件名称无关,与位置有关。#先创建表或先上传文件没有关系,但先上传文件的位置名称需要与创建的表名称相一致。1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijing
hadoop fs -put user.txt /user/hive/warehouse/test.db/t_user/
--执行查询操作
select * from t_user;0: jdbc:hive2://server4:10000> create table t_user(id int,name varchar(255),age int,city varchar(255)).............. .> row format delimited
.............. .> fields terminated by ',';
INFO : Compiling command(queryId=alanchan_20221017144708_278ef43a-dc84-46e8-b0e3-54ae6d0faa51): create table t_user(id int,name varchar(255),age int,city varchar(255))
row format delimited
fields terminated by ','
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017144708_278ef43a-dc84-46e8-b0e3-54ae6d0faa51); Time taken: 0.017 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017144708_278ef43a-dc84-46e8-b0e3-54ae6d0faa51): create table t_user(id int,name varchar(255),age int,city varchar(255))
row format delimited
fields terminated by ','
INFO : Starting task [Stage-0:DDL]in serial mode
INFO : Completed executing command(queryId=alanchan_20221017144708_278ef43a-dc84-46e8-b0e3-54ae6d0faa51); Time taken: 0.071 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.097 seconds)0: jdbc:hive2://server4:10000>select * from t_user;
INFO : Compiling command(queryId=alanchan_20221017144717_7e45fbca-5a47-4b1b-b471-81cb46070b36): select * from t_user
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_user.id, type:int, comment:null), FieldSchema(name:t_user.name, type:varchar(255), comment:null), FieldSchema(name:t_user.age, type:int, comment:null), FieldSchema(name:t_user.city, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017144717_7e45fbca-5a47-4b1b-b471-81cb46070b36); Time taken: 0.177 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017144717_7e45fbca-5a47-4b1b-b471-81cb46070b36): select * from t_user
INFO : Completed executing command(queryId=alanchan_20221017144717_7e45fbca-5a47-4b1b-b471-81cb46070b36); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+--------------+-------------+--------------+
| t_user.id | t_user.name | t_user.age | t_user.city |
+------------+--------------+-------------+--------------+
|1| zhangsan |18| beijing ||2| lisi |25| shanghai ||3| allen |30| shanghai ||4| woon |15| nanjing ||5| james |45| hangzhou ||6| tony |26| beijing |
+------------+--------------+-------------+--------------+
6 rows selected (0.238 seconds)
在hive中创建表跟结构化文件映射成功,注意事项:
- 创建表时,字段顺序、字段类型要和文件中保持一致
- 如果类型不一致,hive会尝试转换,但是不保证转换成功。不成功显示null
- 文件好像要放置在Hive表对应的HDFS目录下,其他路径则需要指定load的路径
- 建表的时候好像要根据文件内容指定分隔符,不指定则使用系统默认的分隔符
8、使用hive进行小数据统计
select count(*) from t_user where age >25;0: jdbc:hive2://server4:10000>select count(*) from t_user where age >25;
INFO : Compiling command(queryId=alanchan_20221017145604_3b0cd5a3-5b30-451d-9947-ed4a103ca98c): select count(*) from t_user where age >25
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017145604_3b0cd5a3-5b30-451d-9947-ed4a103ca98c); Time taken: 0.263 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017145604_3b0cd5a3-5b30-451d-9947-ed4a103ca98c): select count(*) from t_user where age >25
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = alanchan_20221017145604_3b0cd5a3-5b30-451d-9947-ed4a103ca98c
INFO : Total jobs=1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED]in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO :set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO :set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO :set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1665988516927_0002
INFO : Executing with tokens: []
INFO : The url to track the job: http://server1:8088/proxy/application_1665988516927_0002/
INFO : Starting Job = job_1665988516927_0002, Tracking URL = http://server1:8088/proxy/application_1665988516927_0002/
INFO : Kill Command = /usr/local/bigdata/hadoop-3.1.4/bin/mapred job -kill job_1665988516927_0002
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO :2022-10-17 14:57:22,714 Stage-1 map =0%, reduce =0%
INFO :2022-10-17 14:57:24,825 Stage-1 map =100%, reduce =100%, Cumulative CPU 4.1 sec
INFO : MapReduce Total cumulative CPU time: 4 seconds 100 msec
INFO : Ended Job = job_1665988516927_0002
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.1 sec HDFS Read: 21806 HDFS Write: 906989 SUCCESS
INFO : Total MapReduce CPU Time Spent: 4 seconds 100 msec
INFO : Completed executing command(queryId=alanchan_20221017145604_3b0cd5a3-5b30-451d-9947-ed4a103ca98c); Time taken: 82.191 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------+
| _c0 |
+------+
|3|
+------+
1 row selected (82.514 seconds)
以上,简单的介绍了hive的基本功能、部署方式以及部署方式的实现、hive的简单示例。
版权归原作者 一瓢一瓢的饮 alanchan 所有, 如有侵权,请联系我们删除。