
Join是数据库和数仓中最常用的一个感念了。在关系型数据库的数据模型中,为了避免数据冗余存储,不同的数据往往放在不同的表中,分为事实表和维度表,这样做可以极大的节省数据存储空间。但是在分析数据时,则需要通过join把多表关联起来分析。可以说,做数据分析,绕不开的一个话题就是join。而join有多种类型,在使用上有不同的使用方式,而在实现上也有不同的实现方式。不同的使用方式和实现方式,则会造成性能上的天差地别。本文尝试由表及里梳理join的使用和内部实现方式,通过了解内部实现,了解如何写出一个高性能的join SQL。
join类型
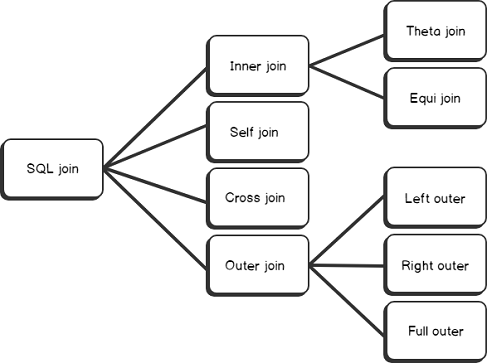
SQL Join从大的分类上,分为Inner Join,Outer Join,Self Join和Cross Join。

Inner join
内连接Inner Join是最常用的一种连接方式。左右表通过谓词连接。只有既在左表出现的行、又在右表出现的行才满足条件,也就是左右表的交集。语法是
select A.x, B.y from A join B on A.x = B.y
内连接不区分左右表的顺序,A inner join B 等同于 B join A。
Inner Join又分为 Equal join和Non Equal Join(Theta Join)。 区别在于,Equal join是在连接条件中,左表的某个字段等与右表的某个字段。而Theta Join的连接条件,不是一个相等条件,有可能是大于或者小于条件。
Outer join
Outer Join包括Left Join,Right Join, Full Join。各个join的不同点参考上图。
Left Join返回左表的全部行,不论这些行是否和右表匹配。这些数据中,又分为两类,分别是匹配右表的数据和不匹配右表的数据。对于左右表交集的部分,即匹配右表的数据,分别输出左右表的列。对于不在交集中的部分,即不匹配右表的数据,输出左表的列值,右表的列值为null。left join不可以左右互换。
right join和left join对称,返回右表的全部行,不论这些数据行是否和左表匹配。这些数据中,又分为两类,分别是匹配左表的数据和不匹配左表的数据。对于左右表有交集的部分,即匹配左表的数据,输出左右表的列。对于不在交集中的行,正常输出右表的列,而左表的列卫null。right join也是不可以左右互换的。但left join和right join是左右对称的。即一个left join可以转写成right join。
A left join B
等同于
A right join B
。
full join是left join和right join的综合,返回的是左右表的并集。在结果中包含三部分数据,分别是左右表的交集(同时匹配左表和右表的数据)、只匹配左表的数据、只匹配右表的数据。对于左右表的交集数据,输出左右表的列值。对于只匹配左表的数据,输出左表的列,右表的列为null。对于只匹配右表的数据,输出右表的列,左表的列为null。
Inner Join和Outer join的区别
Inner Join和Outer Join的区别在于,Inner Join的结果是左右表中同时存在的行,即两个表的交集,也就是结果都在左右表内部。而Outer Join的结果中,可能包含不属于本表的行,如下图中的left join、right join和full join,有些结果是属于本表外部的,所以称为outer join
Cross Join
Cross join是两个表的的笛卡尔积,即左表和右表的N*M种组合。这种一般很少用到,毕竟不是所有的组合都是有意义的。一般在组合后,再加上筛选条件,选择出部分有意义的结果。使用方式如:
A cross join
Self Join
Self Join顾名思义,就是自己join 自己,左右表都是自己,可能是inner join,也可能是outer join。
Semi join
Semi Join是半连接,从一个表中返回的行与另一个表中数据行进行不完全联接查询(查找到匹配的数据行就返回,不再继续查找)。典型的查询如in和exists查询。
Anti Semi join
Anti-semi-join 从一个表中返回的行与另一个表中数据行进行不完全联接查询,然后返回不匹配的数据。典型的查询时not exists和not in。
例如
select * from A where not exists (select B.y from B)
join实现方式
了解系统实现,有助于我们写出性能最佳的SQL。 如果不做任何优化,一个朴素的Hash算法是怎么做的?用两层循环,依次遍历左表和右表的每一行,然后判定连接条件,如果满足连接条件,则输出该行。这种做法称为Product Join(点积join)。
for rowX in left_table:
for rowY in right_table:
if rowX match rowY
output rowX and rowY
这种做法虽然能达到目的,但显然这种做法的时间复杂度是O(N*M),速度是非常慢的。于是有了下边几种更加快速实现方式。
Sort Merge
首先对左右表排序,然后把两个排好序的表按照多路归并算法,合并两个排序表。排序的时间复杂度是O(nlog(n)),归并时间复杂的是O(n)。整体时间复杂度是O(nlog(n))。

Hash Join
Hash Join的算法是对右表构建Hash表,然后遍历左表,根据join key的hash值到hash表中寻找。因此右表称为build side, 左表称为probe side。
构建Hash表的时间复杂度是O(n)。probe的时间复杂度也是O(n)。更重要的时,Hash Join可以用来做分布式join,当数据量太大时,可以把数据Hash到不同的机器上,相同的数据Hash到同一个机器上匹配。可以利用分布式机器解决大数据的join问题。
BroadCast Hash Join
HashJoin要求把左右表都计算Hash,然后按照Hash key分发到其他机器上执行join。如果数据很大的话,shuffle的代价就很大。这个时候就可以区分下情况,如果另一张表也很大,那只能乖乖的Hash做分布式处理了;但如果另外一张表很小,则可以直接把这个小表广播拷贝到大表所在的机器上,这样大表就避免了shuffle。
Shuffle Sort Merge Join
对于大表和大表的join。除了Shuffle hash Join,还可以用shuffle sort merge join,区别在于,Hash Join按照特定的hash key shuffle到固定机器上。而shuffle sort merge join可以按照一个更加宽泛的partition key shuffle到固定机器上。同一个partition的数据,shuffle到同一台机器上,再按照单机的sort merge算法join。
关系型数据库和数仓的不同做法
我们在上文讨论join的实现方式时,有一个隐含的前提是,数据是存在数仓中的。数据量比较大,是多partitoin存储的,左右表更是在不同机器上存储的。而单机的关系性数据库,左右表的全部数据存储在同一个机器上,因此两者的算法存在很大不同。对于数仓而言,天然的需要shuffle数据,把左右表移动到同一个机器上。不过,根据表的大小,有不同的优化方案。如果一个表很小,那么只需要广播这张小表就够了;如果两个表都很大,那么只能乖乖的shuffle两张表了。
Equal join和None Equal join
如果join连接条件中,全都是相等条件,那么在join时,就可以直接按照连接条件进行shuffle,同时按照hash key构建hash表,这样probe的时候,就能够利用hash表在O(1)级别查找数据。
但如果连接条件中包含了非相等条件,或者包含or,那么在连接时,只能逐行验证条件了。
最佳实践
上文介绍了SQL的使用方式和内部实现,通过了解内部实现,我们可以大致了解到如何写出一个高性能的join 语句了
1: 尽量大表join小表,不要大表join大表。
2: 在连接条件中使用相等条件和and条件,不要有or条件。
3: 尽量使用inner join或者outer join,不要使用cross join。
原文链接
本文为阿里云原创内容,未经允许不得转载。
版权归原作者 阿里云云栖号 所有, 如有侵权,请联系我们删除。