
另一篇文章必须看,提供了示例代码: 深度学习中nan和inf的解决
1、 Nan 和 INF
NaN 是 not a number,
INF是infinity的简写,意义是无穷大。比如求损失函数会用到log(x),如果 x 接近0,那么结果就是 inf。
梯度消失:是指导数值特别小,导致其连乘项接近无穷小,可能是由输人数据的值域太小(导致权重 W 的导数特别小)或者是神经网络层输出数据落在在激活函数的饱和区(导致激活函数的导数特别小)
梯度爆炸:是指导数值特别大,导致其连乘项特别大,致使 W 在更新后超出了值域的表示范围。可能是输人数据没有进行归一化(数据量纲太大致使 W 的梯度值变大),只要连乘项的导数一直大于1,就会使得靠近输入层的 W 更新幅度特别大。连乘项是指链式求导法则中毎一层的导数,很明显梯度消失与梯度爆炸都受连乘项的影响(也就是网络梯度的影响)。
总结:梯度消失不会导致模型出现 nan 和 inf ,只会导致模型 loss 不会下降,精度无法在训练过程中提升。而梯度爆炸则有可能导致模型在训练过程中出现 inf 。
1.1、从理论的角度看,训练过程中出现 Nan的本质原因是是出现了**
下溢出
** 和 **
上溢出
** 的现象
上溢出:首先怀疑模型中的指数运算, 因为模型中的数值过大,做exp(x)操作的时候出现了上溢出现象,这里的解决方法是推荐做
Nrom
操作,对参数进行正则化,这样在做exp操作的时候就会很好的避免出现上溢出的现象,可以做
LayerNorm
BatchNorm
等,这里我对模型加fine-tune的时候使用
LayerNorm
解决了loss为
NAN
的问题。【比如不做其他处理的softmax中分子分母需要计算exp(x),值过大,最后可能为INF/INF,得到NaN,此时你要确认你使用的softmax中在计算exp(x)做了相关处理(比如减去最大值等等)】
上溢出同样可能是因为, x/0 的原因,这样就不是参数的值过大的原因,而是具体操作的原因,例如,在自己定义的softmax类似的操作中出现问题,下面是softmax解决上溢出和下溢出的解决方法:
下溢出:一般是log(0) 或者exp(x)操作出现的问题。可能的情况可能是学习率设定过大,需要降低学习率,可以降低到学习率直至不出现nan为止,例如将学习率1e-4设定为1e-5即可。
除了降低学习率的方法,也可在在优化器上面加上一个eps来防止分母上出现0的现象,例如在batchnorm中就设定eps的数值为1e-5,在优化器同样推荐加入参数
eps
,
torch.optim.adam
中默认的
eps
是
1e-8
。但是这个值属实有点小了,可以调大这个默认的
eps
值,例如设定为
1e-3
。
optimizer1 = optim.Adam(model.parameters(), lr=1e-3, eps=1e-4)
optimizer1 = optim.Adam(model.parameters(), lr=0.001, eps=1e-3)
optimizer2 = optim.RMSprop(model.parameters(), lr=0.001, eps=1e-2)
1.2、从数据的角度上看,训练中产生的 nan 、 inf ,本质上可以分为输人数据和值域的问题。
- 对于输入数据有缺陷,模型前向传播过程中值域超出界限,需要用均值进行 nan 值填充,对于图像数据通常不会出现。
- 绝大部分情况是值域的问题,值过大或过小。这出现在模型的前向传播中,模型中的系列运行使得数据超出值域范围,如交又熵中的 log 函数, log (1e-10) 值过小, mse loss 中的 math.pow ( x .2)取平方值过大;激活函数中的 relu 函数,没有上界限制;模型的权重过大。
2、出现 Nan 和 INF 常见原因汇总
一般来说,出现NaN有以下几种情况:
相信很多人都遇到过训练一个deep model的过程中,loss突然变成了NaN。在这里对这个问题做一个总结:
- 脏数据:训练数据(包括label)中有无异常值(nan, inf等);
- 除0问题。这里实际上有两种可能,一种是被除数的值是无穷大,即 Nan,另一种就是0作为了除数(分母可以加一个eps=1e-8)。之前产生的 Nan 或者0,有可能会被传递下去,造成后面都是 Nan。请先检查一下神经网络中有可能会有除法的地方,例 softmax 层,再认真的检查一下数据。可以尝试加一些日志,把神经网络的中间结果输出出来,看看哪一步开始出现 Nan 。
- 可能0或者负数作为自然对数,或者 网络中有无开根号(torch.sqrt), 保证根号下>=0
- 初始参数值过大:也有可能出现 Nan 问题。输入和输出的值,最好也做一下归一化。
- 学习率设置过大:初始学习率过大,也有可能造成这个问题。如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为你的学习率过高,需要降低学习率。可以不断降低学习率直至不出现NaN为止,一般来说低于现有学习率1-10倍即可。如果为了排除是不是学习率的原因,可以直接把学习率设置为0,然后观察loss是否出现Nan,如果还是出现就不是学习率的原因。需要注意的是,即使使用 adam 之类的自适应学习率算法进行训练,也有可能遇到学习率过大问题,而这类算法,一般也有一个学习率的超参,可以把这个参数改的小一些。
- 梯度过大,造成更新后的值为 Nan 。如果当前的网络是类似于RNN的循环神经网络的话,在序列比较长的时候,很容易出现梯度爆炸的问题,进而导致出现NaN,一个有效的方式是增加“gradient clipping”(梯度截断来解决):对梯度做梯度裁剪,限制最大梯度,
- 需要计算loss的数组越界(尤其是自定义了一个新的网络,可能出现这种情况)
- 在某些涉及指数计算,可能最后算得值为 INF(无穷)(比如不做其他处理的softmax中分子分母需要计算exp(x),值过大,最后可能为INF/INF,得到NaN,此时你要确认你使用的softmax中在计算exp(x)做了相关处理(比如减去最大值等等)
3、原因分析与解决方法
3.1、输入数据有误(脏数据)
原因: 输入数据中就含有NaN 、使用的label为空或者 training sample中出现了脏数据!脏数据的出现导致logits计算出了0 出现INF,0作为了除数即nan。
通常我们都会保证输入的数据是否正确。一般输入不正确的话可以立马观察出来。有两种情况可能并不是那么容易检测到:
- 数据比较多,99%的数据是对的,但有1%的数据不正常,或者损坏,在训练过程中这些数据往往会造成
nan或者inf,这时候需要仔细挑选自己的数据,关于如何挑选数据(关于训练神经网路的诸多技巧Tricks(完全总结版) - Oldpan的个人博客)。 - 训练过程中跳出了错误的数据,这是需要在IDE或者通过其他途径对运行中的程序进行分析。
**现象:**每当学习的过程中碰到这个错误的输入,就会变成NaN。观察loss的时候也许不能察觉任何异常,loss逐步的降低,但突然间就变成NaN了
解决方法:
1、我们要注意在训练过程中的输入和输出是否正确,是否有Nan:
利用debug寻找错误的输入
2、label缺失问题也会导致loss一直是nan,需要检查label。
3、逐步去定位错误数据,然后删掉这部分数据:
通过设置batch_size = 1,shuffle = False,一步一步地将sample定位到了所有可能的脏数据,删掉重整数据集,确保训练集和验证集里面没有损坏的图片。可以使用一个简单的网络去读取输入,如果有一个数据是错误的,这个网络的loss值也会出现Nan。
4、在神经网络中,很有可能在前几层的输入是正确的,但是到了某一层的时候输出就会变成
nan
或者
inf
(其中
-inf
代表负无穷,而
nan
代表不存在的数),这个时候就需要通过debug去一一检查。
当然我们可以在自己代码中添加检测函数。例如在Pytorch框架中我们可以使用
torch.autograd.tect_anomaly
类来监测训练或者预测过程中遇到的隐晦的问题:
>>> import torch
>>> from torch import autograd
>>> class MyFunc(autograd.Function):
... @staticmethod
... def forward(ctx, inp):
... return inp.clone()
... @staticmethod
... def backward(ctx, gO):
... # Error during the backward pass
... raise RuntimeError("Some error in backward")
... return gO.clone()
>>> def run_fn(a):
... out = MyFunc.apply(a)
... return out.sum()
>>> inp = torch.rand(10, 10, requires_grad=True)
>>> out = run_fn(inp)
>>> out.backward()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/your/pytorch/install/torch/tensor.py", line 93, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/your/pytorch/install/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
File "/your/pytorch/install/torch/autograd/function.py", line 76, in apply
return self._forward_cls.backward(self, *args)
File "<stdin>", line 8, in backward
RuntimeError: Some error in backward
>>> with autograd.detect_anomaly():
... inp = torch.rand(10, 10, requires_grad=True)
... out = run_fn(inp)
... out.backward()
Traceback of forward call that caused the error:
File "tmp.py", line 53, in <module>
out = run_fn(inp)
File "tmp.py", line 44, in run_fn
out = MyFunc.apply(a)
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
File "/your/pytorch/install/torch/tensor.py", line 93, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/your/pytorch/install/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
File "/your/pytorch/install/torch/autograd/function.py", line 76, in apply
return self._forward_cls.backward(self, *args)
File "<stdin>", line 8, in backward
RuntimeError: Some error in backward
3.2、学习率过高 --> 梯度爆炸进 --> Nan
原因:学习的过程中,梯度变得非常大,使得学习的过程偏离了正常的轨迹,使得学习过程难以继续。
原因很简单,学习率较高的情况下,直接影响到每次更梯度新值的程度比较大,走的步伐因此也会大起来。如下图,过大的学习率会导致无法顺利地到达最低点,稍有不慎就会跳出可控制区域,此时我们将要面对的就是损失成倍增大(跨量级)。
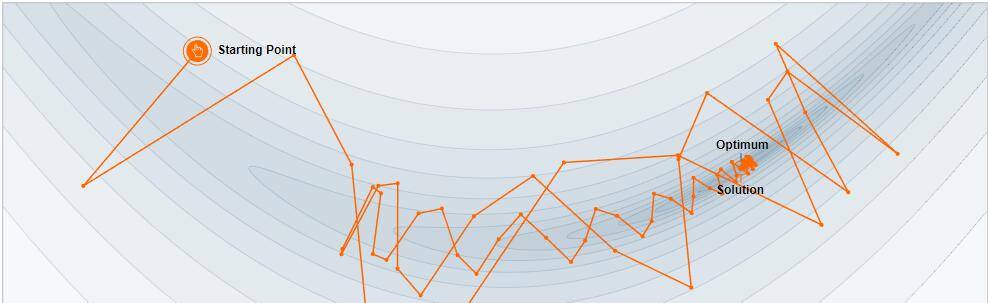
另外,这种情况很容易在网络层数比较深的时候出现,借用gluon的一段话:

现象:观察每次迭代的loss值,会发现loss随着每轮迭代明显增长,并且越来越大,最后loss值太大最终超过了浮点型表示的范围,所以变成了Nan。
解决方法:
1、降低初始学习率,并且设置合适的学习速率和学习率衰减,至少降低一个数量级
2、梯度裁剪,设置gradient clipping,用于限制过大的 diff
3、数据量纲不一致,也会导致梯度爆炸,数据归一化方法(减均值,除方差,或者加入normalization,例如BN、L2 norm等)
5、注意每个batch前梯度要清零,optimizer.zero_grad()
4、如果模型中有多个loss层,就需要找到梯度爆炸的层,然后降低该层的loss weight
3.3、损失函数有误
原因:损失函数的计算可能导致NaN的出现,尤其是在我们自己设计损失函数的时候,如交叉熵损失函数的计算可能出现log(0),可能是初始化的问题,也可能是数据的问题(输入没有归一化的值),所以就会出现loss为Nan的情况
当网络训练到达一定程度的时候,模型对分类的判断可能会产生0这样的数值,log(0)本身是没有问题的,-inf可以安全的参与绝大部分运算,除了(-inf * 0),会产生NaN。NaN的话,一旦参与reduce运算会让结果完蛋的
**现象: **观测训练产生的loss时一开始并不能看到异常,loss也在逐步的下降,但是突然出现Nan
解决方法:
1、损失函数应该考虑到是否可以正常地
backward
。
2、其次对输入的
Tensor
是否进行了类型转化,保证计算中保持同一类型。
3、最后考虑在除数中加入微小的常数保证计算稳定性。
4、尝试重现该错误,在loss layer中加入一些输出以进行调试。找到可能出现的错误的地方,增加一个bias
# 源代码
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
# 修改后
eps = 1e-5
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh + eps) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
y_truth * log(y_predict)
# when y_truth[i] is 0, it is likely that y_predict[i] would be 0
# 这样的表达式,要考虑对log中的变量进行clip. 比如
safe_log = tf.clip_by_value(some_tensor, 1e-10, 1e100)
bin_tensor * tf.log(safe_log)
3.4、Pooling层的步长(stride)大于核(kernel)的尺寸
在卷积层的卷积步伐大于卷积核大小的时候,有可能产生
nan
:
如下例所示,当池化层中stride > kernel的时候会在y中产生NaN
layer {
name: "faulty_pooling"
type: "Pooling"
bottom: "x"
top: "y"
pooling_param {
pool: AVE
stride: 5
kernel: 3
}
}
3.5、batchNorm可能捣鬼
如果你的网络中
batchNorm
层很多,而且充当比较重要的角色,那么可以适当地检查一下
Tensor
在输入Batchnorm层后有没有可能变为
nan
,如果恰好发生这种情况,batchNorm层中的移动均值(running_mean)和移动方差(running_var)也很有可能都是
nan
,而且这种情况很有可能发生在预测阶段。
这种情况通过发生在训练集和验证集是两个截然不同的分布的时候,这是在训练集中学习到的均值和方法在验证集中是没有作用反而会捣乱。或者在一个神经网络中存在两种结构不同的阵营:典型的是Unet,当在自定义Unet的时候,编码网络和解码网络如果是两个结构存在较大差异的网络,那么在编码阶段学习到的分布在解码阶段就会出现问题。
举个真实的例子:Unet + resnet34 表现正常,但是使用Unet + resnext50 则造成损失爆炸(将解码阶段的batchnorm层失效后表现正常)。
当然上述现象出现的原因大部分在当我们**使用
model.eval()
(Pytorch)之后**发生。如果你在预测阶段也将模型
model
设置为
model.train(True)
,那么问题可能就不会出现:

解决方式:
或者设置Batchnorm中的参数
track_running_stats=False
使移动均值和移动方差不起作用:
相关的问题:
Fix batchnorm layer numerics by replacing powx() by pfollmann · Pull Request #5136 · BVLC/caffe · GitHub
3.6、Shuffle设置有没有乱动
Suffle即洗牌的意思,如果我们在数据加载阶段将Shuffle参数设置在True,那么在神经网络的读取数据的时候,将会打乱顺序去读取,也就是不按照数据的排列顺序去读取。
一般我们是在训练阶段开启shuffle而在预测阶段关闭shuffle,训练阶段在进行每个epoch的时候开启shuffle可以使数据充分地被随机过一遍(类似于我们烤鱼,我们选择是频繁将鱼上下翻面(shuffle)或者只翻一次面,每次烤很长时间),这样训练的鲁棒性比不shuffle稍高一些。
但是假如我们使用了batch_norm层,并且数据的分布极不规律(使用shuflle和不使用shuffle读取的数据顺序的信息分布完全不同),那么在训练阶段训练好的模型(使用shuffle),在预测阶段使用的时候(不使用shuffle),由于数据分布的不同,也是有可能导致batch_norm层出现nan,从而导致不正常的损失函数出现。
3.7、设置远距离的Label会得到NAN
我的理解是,模型采用了交叉熵损失函数,当标签过于分散的时候,比方说标签为8000的数据,其概率分布值就会变成了比较小的数值,也就是会出现类似于log(0)这种情况,从而模型的loss为Nan.
4、本质解决方案:本质就是调整输入数据在模型运算过程中的值域
4.1、模型权重加入正则化,约束参数的大小
** **模型权重初始化方法Xavier初始化,Kaiming初始化
4.2、模型中加入 BatchNormalization ,归一化数据
如将输入的图片数据除以255将其转化成0-1之间的数据; 还有减均值,除方差,或者加入normalization,例如BN、L2 norm等
4.3、使用带上限的激活函数,例如relu6函数
pytorch 下使用 torch . nn .ReLU6,函数原型为 min ( max (0, x ),6),也就是把 relu 函数的最大值限制为6。 也就是对输出做了限制
4.4、在 losse 函数运算前进行值域修正
tf可以使用 clip_by_value 函数,在 loss 函数的 log , exp 前调整 y_pred 的值域,避第 -logl(0)产生的无穷大
pytorch 可以使用 torch.clip ( input , min=None , max = None ) 或 torch.clamp ( input , min=None, max = None )进行值域限制
import torch.nn as nn
outputs = model(data)
loss= loss_fn(outputs, target)
optimizer.zero_grad()
loss.backward()
#nn.utils.clip_grad_value(model.parameters(),clip_value=2)
nn.utils.clip_grad_norm_(model.parameters(), max_norm=20, norm_type=2)
optimizer.step()
4.5、进行梯度減枝
对超出值域范围的梯度进行约束,避免梯度持续大于1,造成梯度爆炸。(没办法规避梯度消失)
pytorch 使用 nn.utils.clip_grad_value(parameters, clip_value).将所有的参数剪裁到[-clip_value , clip_value]。如 clip_value =1,[100,0.1]=>[1,0.1],该操作会改变梯度的方向
使用 nn.utils.clip_grad_norm_ 按照范数大小进行归一化,当参数的范数( norm_type=2 范数)大于最大值时,则会将其归约到最大值。该方法可以保证梯度的方向是完全一致的,可能会导致梯度值被缩放到特别小(如[100,0.1]=>[1,0.0001])。
4.6、使用 ResNet 或 DenseNet 结构
将深层的样度值通过跳跃连接传递到浅层中。在训练早期,模型参数可能不是很合适,会出现梯度消失和爆炸的情况,特别是有lstm,rnn这类网络的情况。nan 是not a number ,inf是无穷大。比如求损失函数会用到log,如果输入接近0,那么结果就是inf。
5、pytorch半精度amp训练nan问题
5.1、Why?
如果要解决问题,首先就要明确原因:为什么全精度训练时不会nan,但是半精度就开始nan?这其实分了三种情况:
- 计算loss 时,出现了除以0的情况
- loss过大,被半精度判断为inf
- 网络参数中有nan,那么运算结果也会输出nan
大部分报nan都是第三种情况。这里来先看看3。什么情况下会出现情况3?这个讨论给出了不错的解释:Nan Loss with torch.cuda.amp and CrossEntropyLoss - #17 by bruceyo - mixed-precision - PyTorch Forums
翻译就是:在使用ce loss 或者 bceloss的时候,会有log的操作,在半精度情况下,一些非常小的数值会被直接舍入到0,log(0)等于啥?——等于nan啊!于是逻辑就理通了:回传的梯度因为log而变为nan->网络参数nan-> 每轮输出都变成nan。
5.2、How?
当我们使用具有 log() 的损失函数,如 Focal Loss 或 Cross Entropy 时,输入张量的某些维度可能是一个非常小的数字,正常情况是float32是一个极其小的数但也不是0,但是amp使用半精度可能就直接摄入到了0,因此就出现NAN的问题了。问题定位清楚,那解决方案就非常简单了。因此,我们可以在涉及到
log
操作的时候,将float16转化为float32
x = x.float()
x = torch.sigmoid(x)
5.3、原因(1)和(2)的分析解决
(1)&(2),其实是可以通过
scaler.step(optimizer)
解决的,分别由optimizer和scaler帮我们捕捉到了nan的异常。但(3)不行,(3)意味着部分甚至全部的网络参数已经变成nan了。这可能是在更之前的梯度回传过程中除以0导致的——首先【回传的梯度不是nan】,所以scaler不会捕捉异常;其次,由于使用了半精度,optimizer接收到了【已经因为精度损失而变为nan的loss】,nan不管加上多大的eps,都还是nan,所以optimizer也无法处理异常,最终导致网络参数nan。
所以3,只能通过本文一开始提出的方案来解决。其实,大部分分类问题在使用半精度时出现nan的情况都是第3种情况,也只能通过把精度转回为float32,或者在计算log时加上微小量来避免(但这样会损失精度)。
6、神经网络学不出东西怎么办?
可能我们并没有遇到,或者解决了 Nan 等问题,网络一直在正常的训练,但是 cost 降不下来,预测的时候,结果不正常。
- 请打印出训练集的 cost 值和测试集上 cost 值的变化趋势,正常情况应该是训练集的 cost 值不断下降,最后趋于平缓,或者小范围震荡,测试集的 cost 值先下降,然后开始震荡或者慢慢上升。如果训练集 cost 值不下降,有可能是代码有 bug ,有可能是数据有问题(本身有问题,数据处理有问题等等),有可能是超参(网络大小,层数,学习率等)设置的不合理。请人工构造10条数据,用神经网络反复训练,看看 cost 是否下降,如果还不下降,那么可能网。络的代码有 bug ,需要认真检查了。如果 cost 值下降,在这10条数据上做预测,看看结果是不是符合预期。那么很大可能网络本身是正常的。那么可以试着检查一下超参和数据是不是有问
- 如果神经网络代码,全部是自己实现的,那么强烈建议做梯度检查。确保梯度计算没有错误。
- 先从最简单的网络开始实验,不要仅仅看 cost 值,还要看一看神经网络的预测输出是什么样子,确保能跑出预期结果。例如做语言模型实验的时候,先用一层 RNN ,如果一层 RNN 正常,再尝试 LSTM ,再进一步尝试多层 LSTM 。
- 如果可能的话,可以输入一条指定数据,然后自己计算出每一步正确的输出结果,再检查一下神经网络每一步的结果,是不是一样的。
参考文章:
警惕!损失Loss为Nan或者超级大的原因 - Oldpan的个人博客
深度学习中nan和inf的解决_dddeee的专栏-CSDN博客_nan和inf
解决pytorch半精度amp训练nan问题 - 知乎
模型训练 loss变成NAN的原因解决方法 - 知乎
版权归原作者 ytusdc 所有, 如有侵权,请联系我们删除。