
在线工具推荐:
Three.js AI纹理开发包
- *
YOLO合成数据生成器
- *
GLTF/GLB在线编辑
- *
3D模型格式在线转换
- *
3D数字孪生场景编辑器
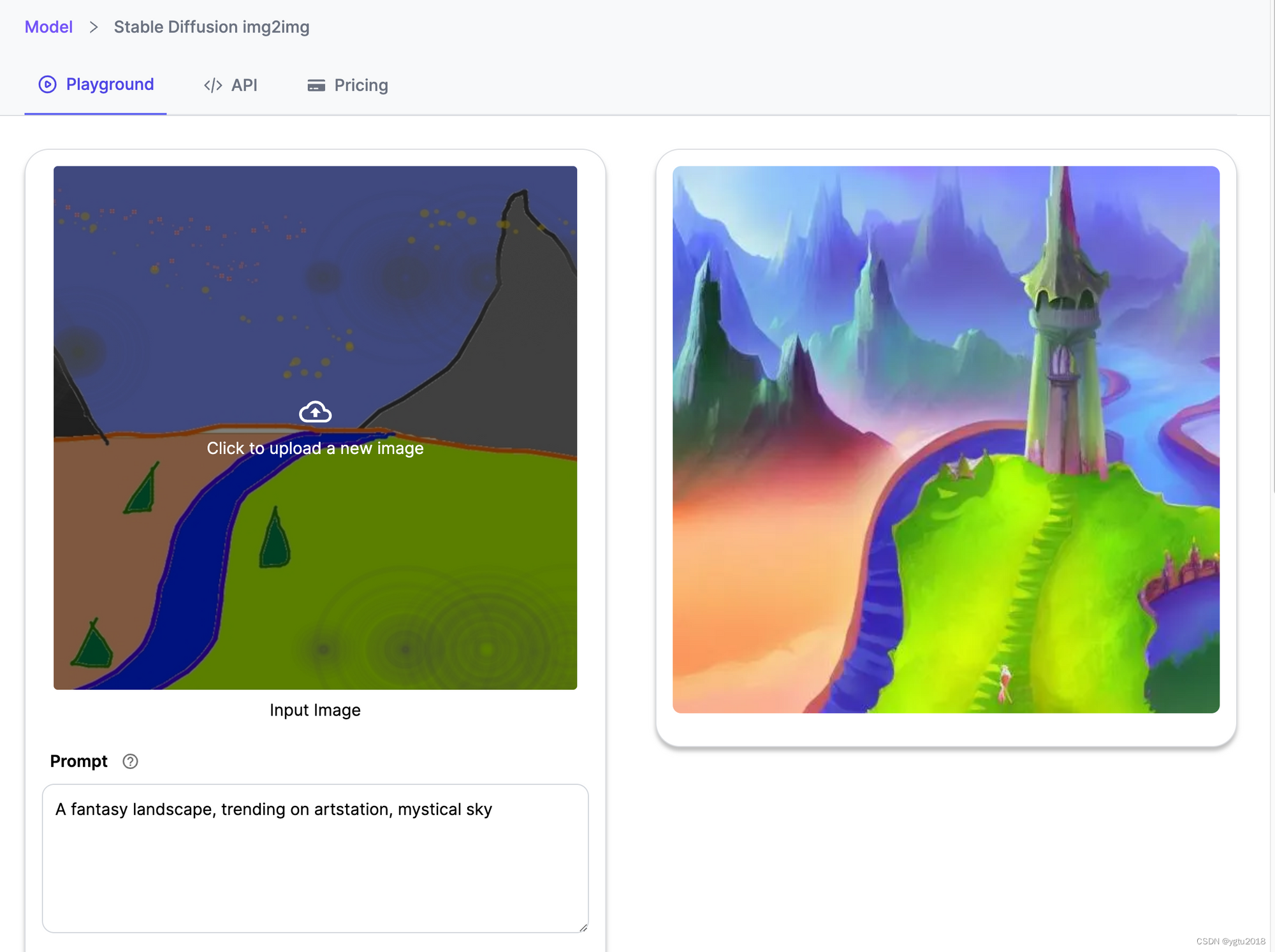
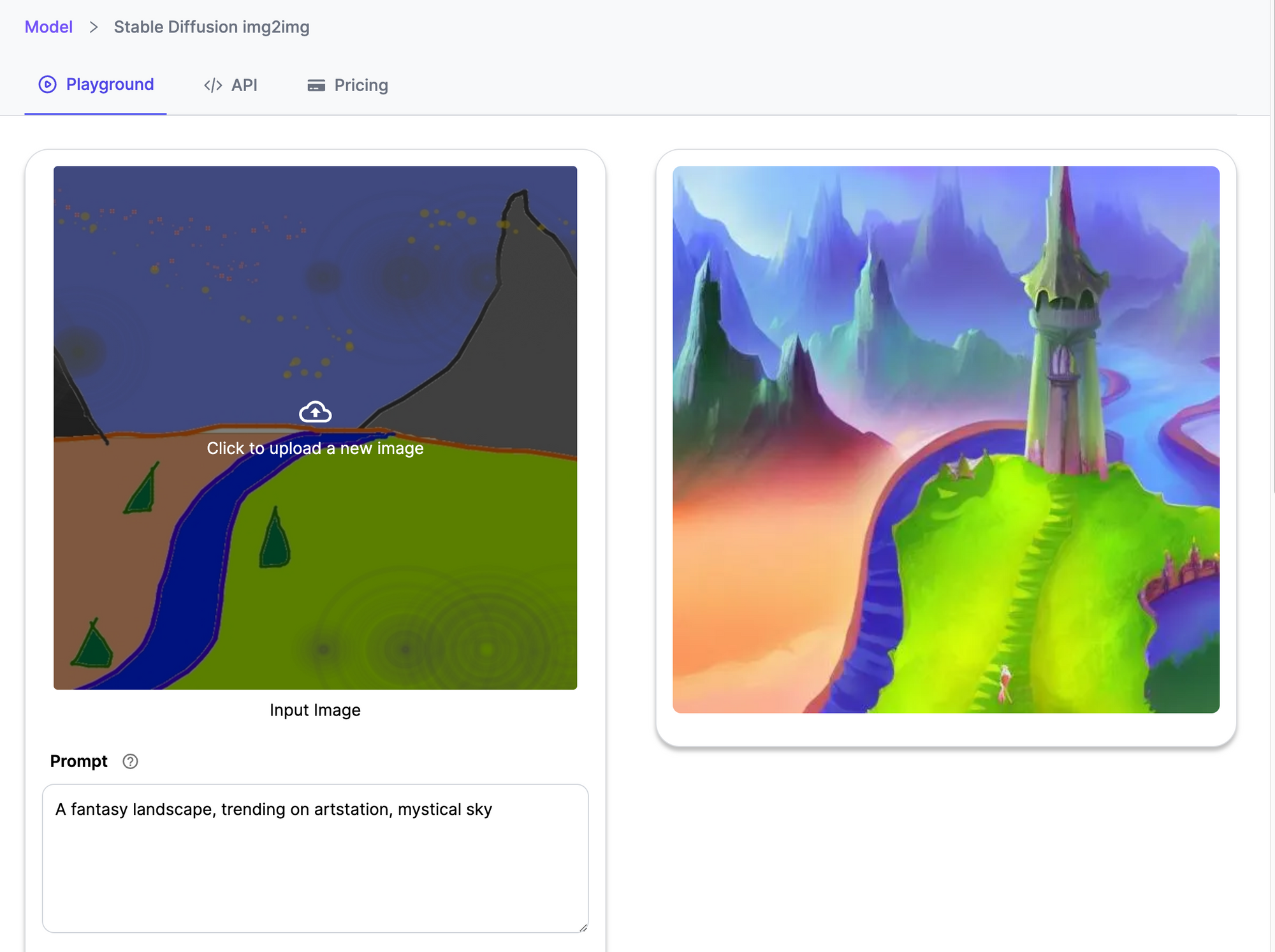
Stable Diffusion 2022.1 Img5Img 于 2 年发布,是一款革命性的深度学习模型,正在重新定义和推动照片级真实感图像生成领域的创新。该模型提供了广泛的功能,其主要功能是从文本描述、修复和修复任务以及由文本提示引导的图像到图像翻译中生成详细的图像。
稳定扩散 1.5 Img2Img 引擎
该模型的功能不仅扩展到简单的图像生成,还扩展到图像放大、增强分辨率、压缩和生成更精细的细节。该过程建立在一个复杂的架构之上,该架构将自动编码器与在自动编码器的潜在空间中训练的扩散模型融合在一起,一旦编码器开始将输入图像转换为潜在表示,该过程就开始了,相对下采样因子为 8。
ViT-L/14 文本编码器负责对文本提示进行编码,并通过交叉注意力将文本编码器的非池化输出发送到潜在扩散模型的 UNet 主干中。该模型的损失函数是添加到潜在空间的噪声与UNet预测之间的重建目标。
强度值参数在这里也起着至关重要的作用,因为它决定了添加到生成的图像中的噪声量。值越大,变化越大,但在某些情况下,可能会影响文本提示的语义一致性。
要了解有关该模型工作原理的更多信息,请查看官方 Stable Diffusion 博客。
Stable Diffusion 1.5 Img2Img的应用和优势
Stable Diffusion 1.5 Img2Img 提供了强大的选项,可增强分辨率并为图像添加更精细的细节或噪点。其独特的方法将文本提示和图像与强度值相结合,使用户能够创建独特、丰富且具有视觉吸引力的图像,这些图像在上下文中将文本提示与原始图像的真正本质融合在一起。此外,其图像放大和压缩的潜力拓宽了图像处理的范围。
从增强视觉内容到促进研究和数据分析,Stable Diffusion 1.5 Img2Img 可满足不同的行业需求:
- 图像到图像翻译:该模型能够根据文本提示和现有图像生成新图像,为创意项目和艺术活动开辟了无限的可能性。
- 数据匿名化:通过向原始图像添加噪点来保护敏感信息。该模型在不影响数据分析和建模的情况下改变和匿名化图像数据的视觉特征。
- 数据增强:机器学习任务通常涉及使用大型图像数据库。Stable Diffusion 1.5 Img2Img 通过改变和增强图像数据来促进数据增强,从而为训练和研究目的提供丰富多样的数据集。
- 图像放大:在不牺牲质量的情况下提高图像的分辨率。Stable Diffusion Img2Img 提供高端图像放大功能,为低分辨率图像注入新的活力和更精细的细节。
- 图像压缩:数据存储和传输在很大程度上依赖于高效的图像压缩。虽然优化仍在进行中,以更好地保留小文本和人脸,但该模型作为图像压缩工具的表现令人印象深刻。
Stable Diffusion 1.5 Img2Img 入门
在本地运行具有必要依赖项的 Stable Diffusion 1.5 Img2Img 模型可能在计算上非常详尽且耗时。这就是为什么我们创建了免费使用的 AI 模型,例如 ControlNet Canny 和其他 30 个模型。要免费开始,请按照以下步骤操作。
- 在 Segmind.com 上创建您的免费帐户
- 登录后,单击“模型”选项卡,然后选择“稳定扩散 1.5 Img2Img'
- 上传您要处理的图像
- 输入详细说明所需输出的文本提示
- 点击“生成”
- 见证 Stable Diffusion 1.5 Img2Img 的魔力!
Stable Diffusion 1.5 Img2Img 许可证
Stable Diffusion 1.5 Img2Img 模型根据 Creative ML OpenRAIL-M 许可证(负责任 AI 许可证 (RAIL) 的一种形式)获得许可。根据该许可证,虽然用户保留对其生成的输出图像的权利并可以自由地将其用于商业用途,但该许可证禁止某些用例,包括犯罪、诽谤、骚扰、人肉搜索、剥削未成年人、提供医疗建议、自动产生法律义务、提供法律证据以及基于社会行为、个人特征歧视或伤害个人或群体、 或受法律保护的类别。
转载:使用 Stable Diffusion Img2Img 生成、放大、模糊和增强 (mvrlink.com)
版权归原作者 ygtu2018 所有, 如有侵权,请联系我们删除。