
走近科学之——缓存
什么是缓存
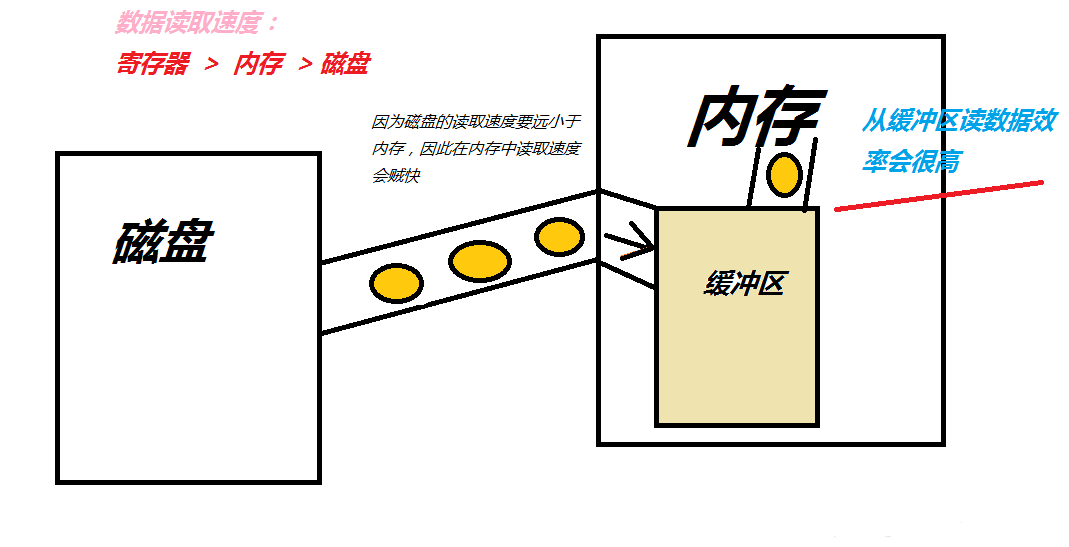
缓存是CPU的一部分,它存在于CPU中。CPU存取数据的速度非常的快,一秒钟能够存取、处理十亿条指令和数据,而内存就慢很多,快的内存能够达到几十兆就不错了,可见两者的速度差异是多么的大。
缓存是为了解决CPU速度和内存速度的速度差异问题 。内存中被CPU访问最频繁的数据和指令被复制入CPU中的缓存,这样CPU就可以不经常到象“蜗牛”一样慢的内存中去取数据了,CPU只要到缓存中去取就行了,而缓存的速度要比内存快很多。
Java的缓冲流
创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
字节输入流(InputStream)——子类BufferedInputStream
- 底层会创建一个长度是8192的byte数组(缓冲区)
- 每次读取数据存入该缓冲区中
- 减少了读取的次数,提高读取效率
字节输出流(OutputStream)——子类BufferedOutputStream
- 底层会创建一个长度是8192的byte数组(缓冲区)
- 每次写出数据先写到该缓冲区中
- 减少了写出的次数,提高写出效率
MyBatis缓存
缓存(cache),数据交换的缓冲区,当应用程序需要读取数据时,先从数据库中将数据取出,放置在缓冲区中,应用程序从缓冲区读取数据。
类比于上文提到过的缓冲流,**MyBatis的缓存属于输出型缓存**。
特点&缺点
数据库去除的数据保存在内存中,具备快速读取和使用的特点。
读取数据时无需再从数据库中获取,因此**得到的数据可能不是最新的**。
术语&功能
命中:当在缓存中找到需要的数据,则直接取出使用。
未命中:当在缓存中未找到需要的数据,则先从数据库中取出并先放入缓冲区,亦方便下次使用。
减少Java项目与数据库的交互次数,从而提升程序的运行效率。
一般通过**配置或定制**的方式来使用缓存。
使用场景
适合使用缓存
经常查询并且不经常改变,或者数据的正确与否对最终结果影响不大的。
比如:公司的介绍或者新闻。
新闻一般为已经发生且无法改变的事,查询的人会很多,使用缓存可以大大提高效率。
不适合使用缓存
经常改变的数据,或者数据的正确与否对最终结果影响很大的。
比如:商品的库存,股市等等。
由于缓存的缺点,得到的数据可能不是最新的,当商品的库存无法实时更新,不仅会对商家造成损失,也会加大与消费者的纠纷;股市数据一旦不是最新的,股民公司都会得到损失,轻则亏本,重则倾家荡产。
缓存的分类
一级缓存会话Session级别的缓存,针对一次会话操作内二级缓存映射器级别的缓存,针对不同Namespace的映射器自定义缓存根据各类不同的缓存机制,自定义缓存的实现方式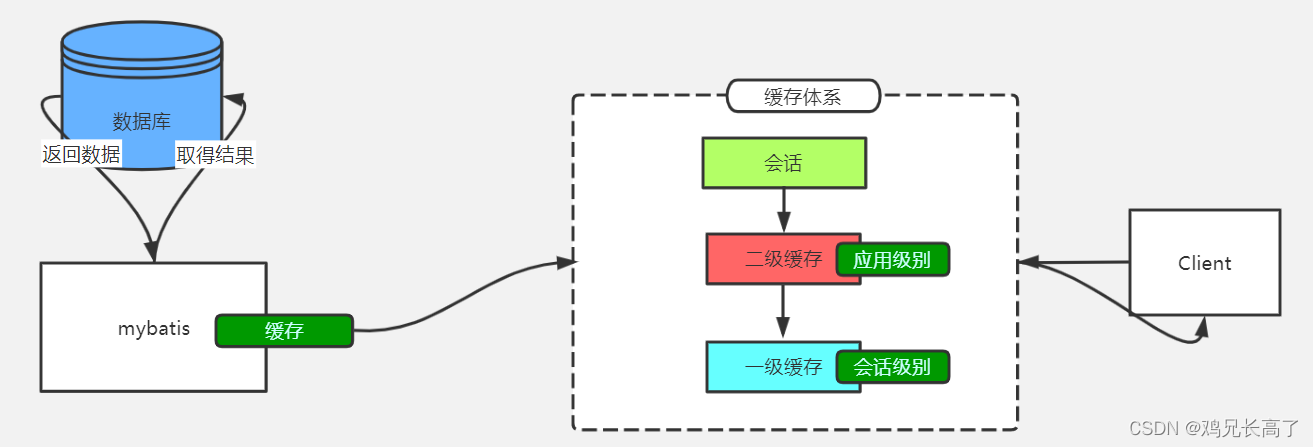
一级缓存
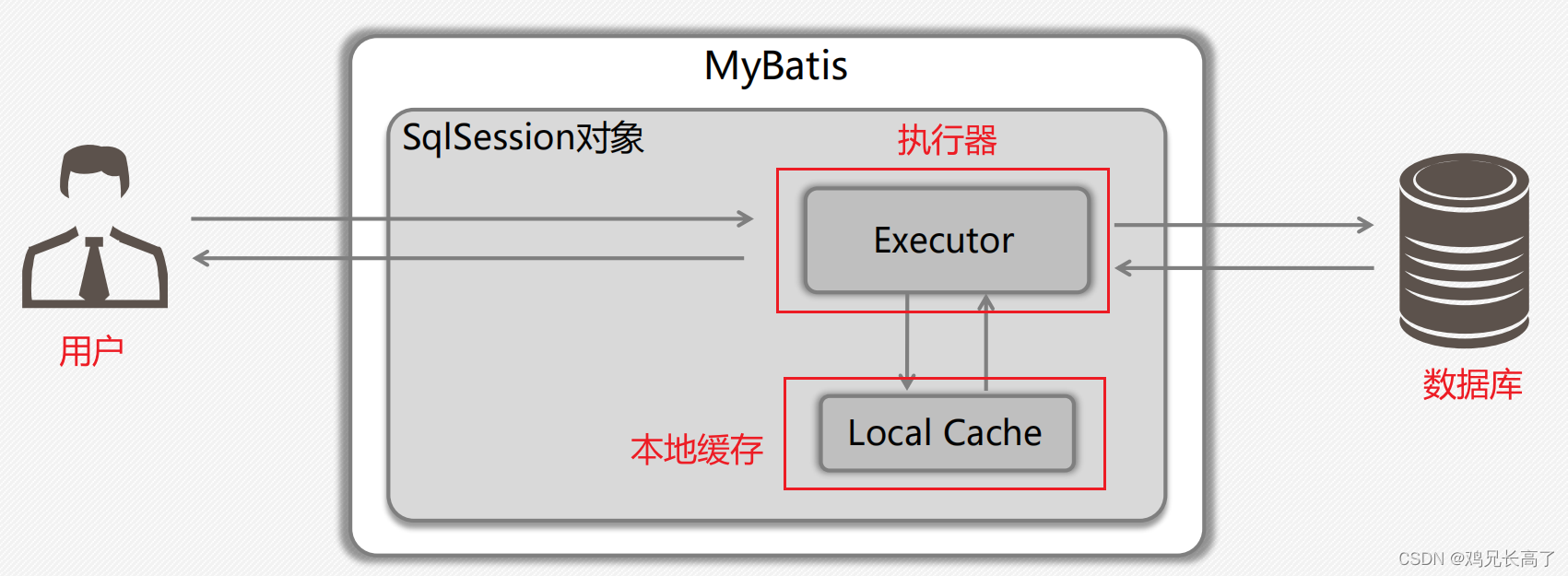
一级缓存针对的是**SqlSession**,是**默认开启**的,在**主配置文件**中进行配置。每个Session都有自己的缓存。
配置

我们需要在<configuration>的子标签<settings>中完成对一级缓存的配置,由于一级缓存是默认开启的,因此一般我们不会去手动书写。
value属性有两个值。
SESSIONsession级别的缓存STATEMENTstatement级别的缓存
因此,当我们需要改变一级缓存级别时再进行修改。
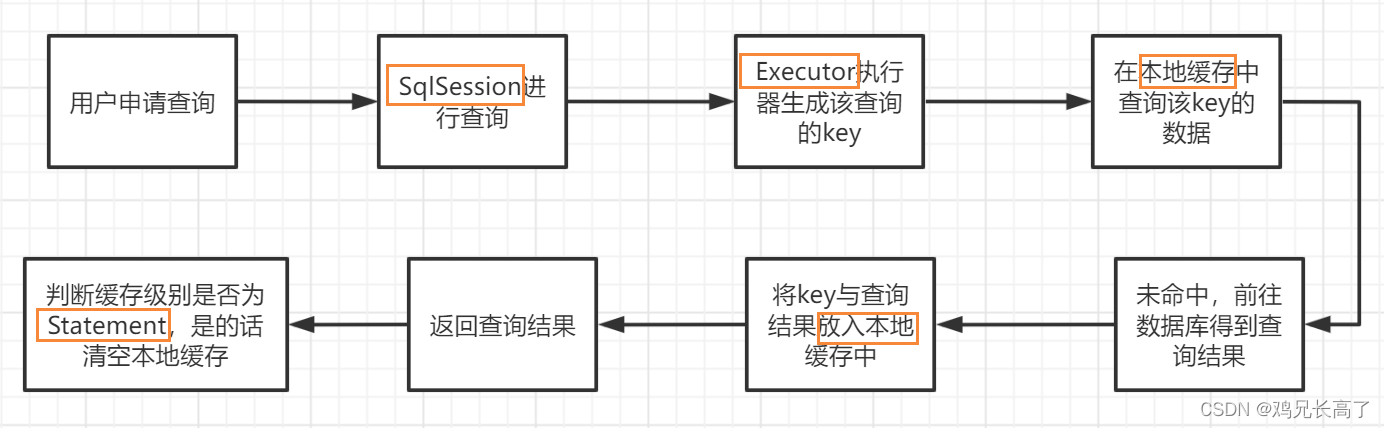
工作流程
命中

未命中
案例
查询学号为33的学生。
- DaoUtil.java——封装SqlSession的基本操作。
public class DaoUtil {
private static SqlSessionFactory build;
static {
try {
//读取配置文件
//要返回一个流
InputStream readConfig = Resources.getResourceAsStream("mybatis-config.xml");
//获取工厂对象
build = new SqlSessionFactoryBuilder().build(readConfig);
} catch (IOException e) {
e.printStackTrace();
}
}
public static SqlSession getSqlSession() {
return build.openSession();
}
public static void closeResource(SqlSession ss) {
ss.close();
}
}
- StudentMapper.java——定义查询方法
@Select("select * from student where sid = #{v}")
public Student findStuBySid(int sid);
- StudentTest.java——测试
public class StudentTest {
public static void main(String[] args) {
SqlSession ss = DaoUtil.getSqlSession();
StudentMapper mapper = ss.getMapper(StudentMapper.class);
//第一次查询
Student stu1 = mapper.findStuBySid(33);
System.out.println(stu1);
//第二次查询
Student stu2 = mapper.findStuBySid(33);
System.out.println(stu2);
System.out.println(stu1 == stu2);
DaoUtil.closeResource(ss);
}
}

因此我们也可以知道——打开一个SqlSession会完成两件事:
- 获得SqlSession
- 获得缓冲空间
一级缓存失效的情况
#1. 不同SqlSession对应不同的一级缓存
#2. 同一个SqlSession但查询条件不同
#3. 同一个SqlSession两次查询期间执行了任何一次增删改操作
当同一个SqlSession多次发出相同的SQL语句查询时,MyBatis会直接从缓存中取数据。如果前后两次中间出现过commit操作(修改、添加、删除),则认为数据发生了变化,MyBatis会把SqlSession中的一级缓存区域全部清空,则下一次的SQL语句查询时,需从数据库中查询数据并将查询的结果写入缓存。
#4. 同一个SqlSession两次查询期间手动清空了缓存
** **SqlSession对象.clearCache()方法。
二级缓存
在使用一级缓存的时候,我们发现:**不同SqlSession对应不同的一级缓存**,意味着即使我们想查询的为同一的数据,但是使用了不同的SqlSession,仍需不断的访问数据库。
因此,升级版的缓存出现了——二级缓存。
二级缓存是跨SqlSession的缓存,Mapper级别的缓存,**面向的是工厂,同一工厂使用一个缓存空间**。在Mapper级别的缓存内,不同的SQLSession缓存可以共享。
配置
通过映射器
#1. 在主配置文件中进行配置

<configuration>子标签<settings>。
#2. 在映射文件中进行配置

<mapper>子标签<cache>。
#3. 在使用的操作中配置(在select标签中配置)

通过注解
#1. 在主配置文件中进行配置
<configuration>子标签<settings>。
#2. 用@CacheNamespace注解修饰定义的接口,并将参数blocking设置为true

案例
使用两个SqlSession查询同一学号的学生。
public class CacheTest {
public static void main(String[] args) {
//第一次查询
SqlSession ss1 = DaoUtil.getSqlSession();
StudentMapper mapper1 = ss1.getMapper(StudentMapper.class);
Student stu1 = mapper1.findStuBySid(33);
System.out.println(stu1);
//第二次查询
SqlSession ss2 = DaoUtil.getSqlSession();
StudentMapper mapper2 = ss2.getMapper(StudentMapper.class);
Student stu2 = mapper2.findStuBySid(33);
System.out.println(stu2);
System.out.println(stu1 == stu2);
DaoUtil.closeResource(ss2);
DaoUtil.closeResource(ss1);
}
}
我们发现代码报错了,原因是我们没有对实体类:Student进行序列化。

运行结果
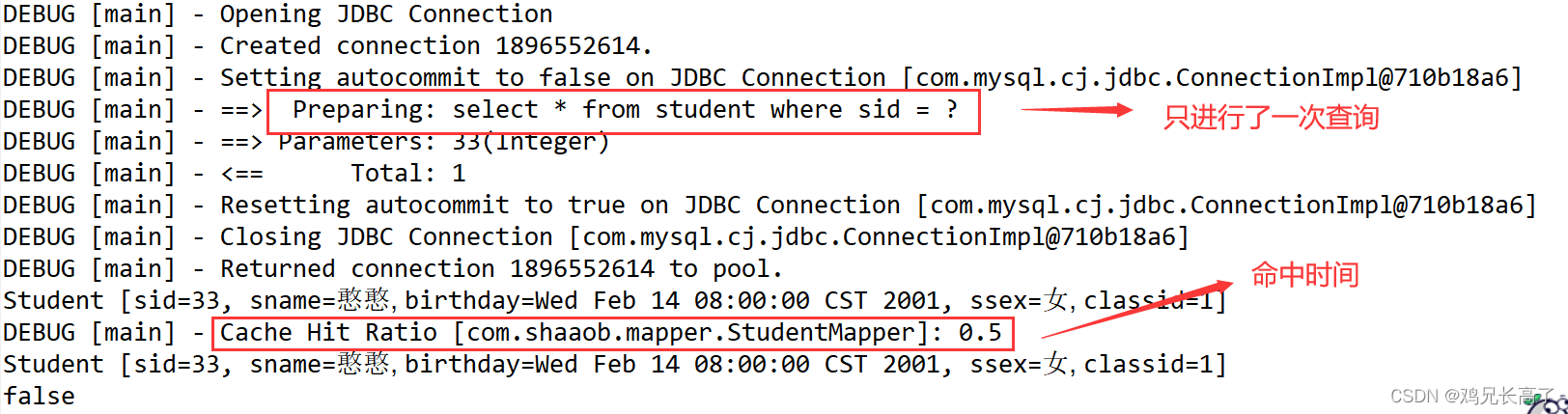
第二次查询不需要获取链接。
POJO类(实现类)序列化问题
1、序列化就是一种用来处理对象流的机制,所谓对象流就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可以在网络之间传输,需要实现Serializable接口,该接口没有需要实现的方法,只是为了表示对象是可以序列化的。序列化是将对象转换为容易传输的格式的过程。
2、是对象永久化的一种机制,在程序终止后,这些对象仍然存在,可以在程序再次启动之后读取这些对象的值,也可以在其他程序利用这些保存下来的值。
3、只有序列化的对象才可以存储在存储设备上。
二级缓存的位置
二级缓存不将数据放入内存,而是序列化到磁盘上。
二级缓存面向的是工厂,使用工厂的好处:节约链接,使得独缺无法造成很多锁竞争,实现真正的节约资源。
一级缓存和二级缓存的对比
缓存面向位置开启方式消亡一级缓存SqlSession内存自动开启四种失效情况二级缓存SqlSessionFactory磁盘手动开启随工厂消亡
二级缓存的特点与缺陷
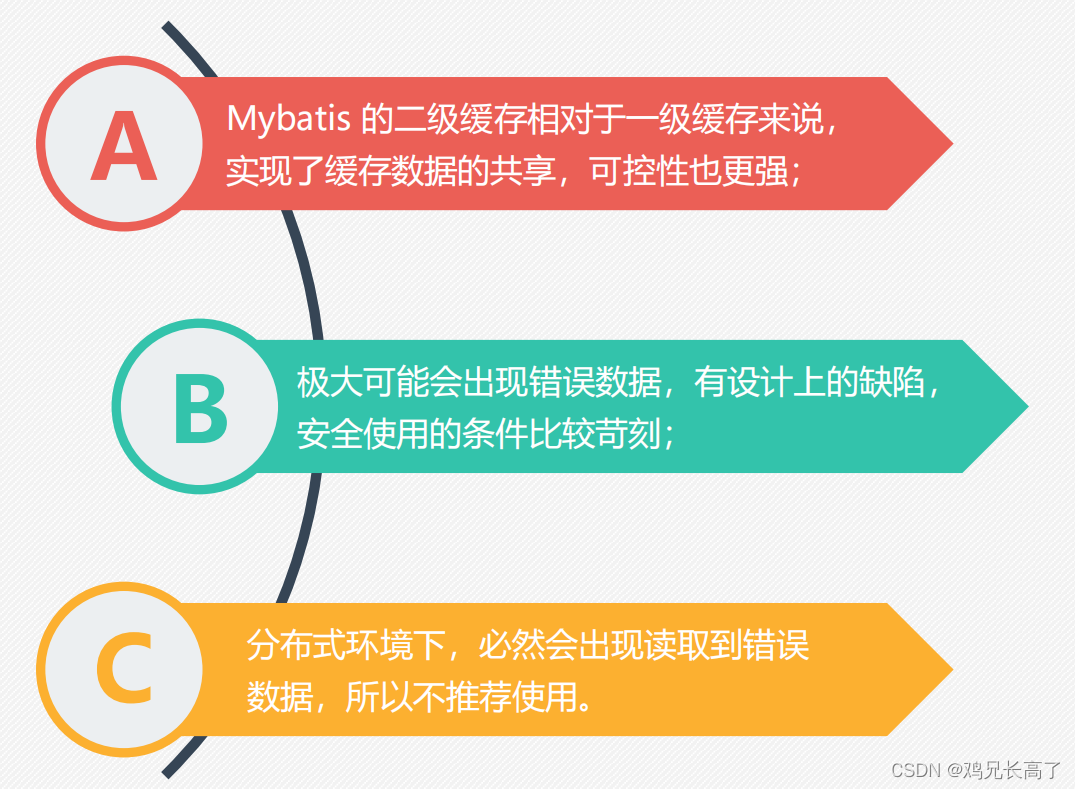
当我们使用数据库时,创建表需要遵循三大范式(确保表中每列的原子性、确保表中每列都和主键相关且未直接相关),因此我们通常需要创建多张表。而在实际情况中,一个数据库处理不过来数据时,我们甚至需要一起使用多个数据库——数据库的集群。
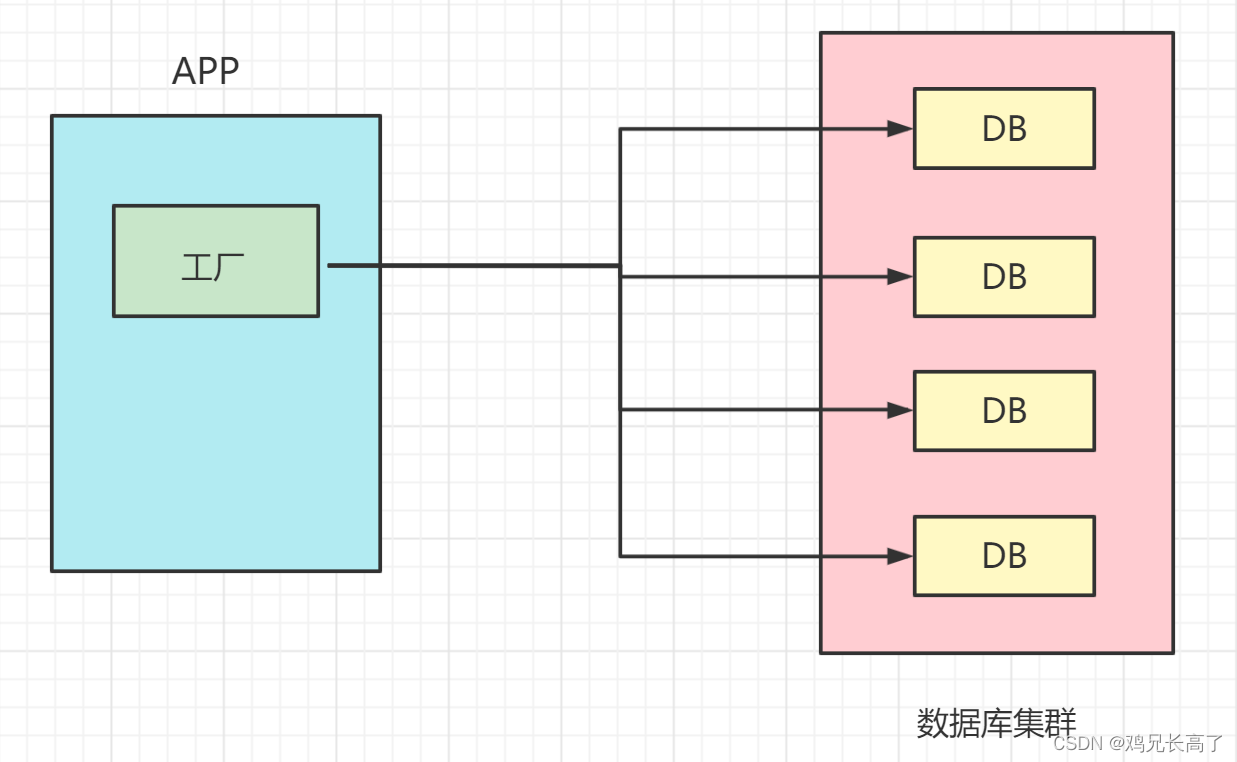
相应的,应用/服务器也会集群,比如不同地区的人会访问不同的服务器(英雄联盟分国服、韩服等等……)。
但是,在实际的项目中是绝对不会使用二级缓存的。
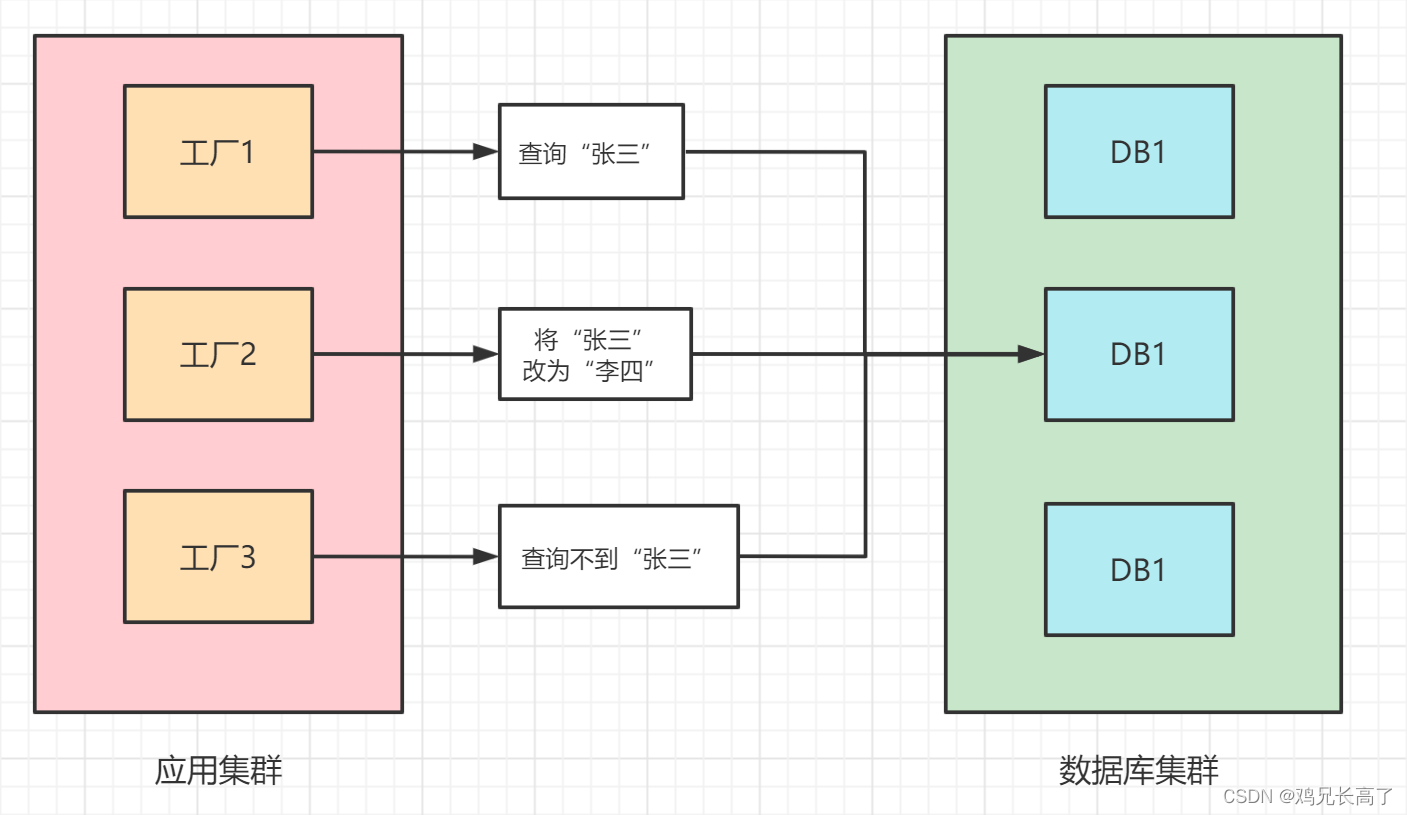
**每个服务器作为一个工厂——不同工厂无法同步。**
自定义缓存

版权归原作者 鸡兄长高了 所有, 如有侵权,请联系我们删除。