
上海交大发布的LLM手机推理框架PowerInfer-2
前言

昨天苹果WWDC大会刚刚举办完毕,“如何在手机端部署人工智能”就成为了一大热点。与PC端不同,手机端的AI部署条件更加苛刻。但就在WWDC的后一天,上海交大 IPADS 实验室推出了面向手机的大模型推理引擎PowerInfer-2.0。
PowerInfer-2

按照大模型的Scaling Law法则,模型参数越大,能力对应的也就越强,这就意味着能力更强的模型对内存的要求越高。即使勉强把通过量化等手段把模型塞进手机了,推理速度也慢,适合的应用场景也就非常有限了。这也是手机部署AI的难点所在。
但这次上海交大 IPADS 实验室给出了他们自己解决的方案:
动态神经元缓存:为了解决手机运行内存(DRAM)不足的问题,PowerInfer-2.0 利用了稀疏模型推理时的一个特性,即每次只需激活一小部分神经元,也就是所谓的“稀疏激活”。未被激活的神经元即便不参与 AI 模型的推理计算,也不会影响模型的输出质量。稀疏激活为降低模型推理的内存使用提供了新契机。为充分利用这一特性,PowerInfer-2.0 将整个神经网络中的神经元分为冷、热两种,并在内存中基于 LRU 策略维护了一个神经元缓存池。频繁激活的“热神经元”被放置在运行内存中,而“冷神经元”只有在被预测激活时才会被拉入内存,这样就大幅降低了内存使用量。
以神经元簇为粒度的异构计算:针对手机硬件平台存在 CPU、GPU、NPU 三种异构计算单元,情况十分复杂的问题,PowerInfer-2.0 将粗粒度的大矩阵计算分解为细粒度的“神经元簇”。每个神经元簇可包含若干参与计算的神经元。对于不同的处理器,会根据其特性动态决定划分出的神经元簇的大小。例如,NPU 擅长进行大矩阵计算,可将所有神经元合并为一个大的神经元簇,交给 NPU 计算,这样就能充分利用它的计算能力。而在使用 CPU 时,拆出多个细粒度的神经元簇分发给多个 CPU 核心进行计算。
分段缓存和神经元簇级的流水线技术:PowerInfer-2.0 提出了分段神经元缓存和神经元簇级的流水线技术,当一个神经元簇等待 I/O 时,可及时将另一个已准备好的神经元簇调度到处理器上进行计算,从而充分隐藏了 I/O 延迟。同时这种基于神经元簇的流水线打破了传统推理引擎中逐矩阵计算的方式,允许来自不同参数矩阵的神经元簇交错执行来达到最高的并行效率。
分段缓存和专门的模型存储格式:I/O 加载神经元的速度对模型推理至关重要。分段缓存会针对不同的权重类型(如注意力权重、预测器权重、前馈网络权重)采取不同的缓存策略,以提高缓存命中率,减少不必要的磁盘 I/O。缓存还会使用 LRU 替换算法动态更新每个神经元的实际冷热情况来保证缓存中存放的都是最热的神经元。此外,PowerInfer-2.0 还针对手机 UFS 4.0 存储的性能特点,设计了专门的模型存储格式,以提高读取性能。
最终成果
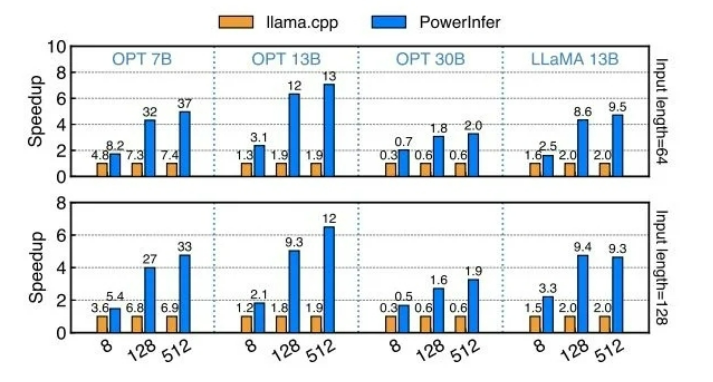
最后在内存受限的情况下,PowerInfer-2.0的预填充速度都显著高于llama.cpp与LLM in a Flash,包括解码阶段PowerInfer-2.0也占据了很大的优势。特别是对于Mixtral 47B这样的大模型,也能在手机上跑出11.68 tokens/s的速度。而对于Mistral 7B这种可以放进手机运行内存的模型,PowerInfer-2.0可以节约40%内存的情况下,达到与llama.cpp和MLC-LLM同水平甚至更快的解码速度。
总结
从目前的情况来看,PowerInfer-2.0 将会在手机人工智能领域发挥很大的作用,为推动手机智能应用的广泛普及和创新提供强大的动力。
厚德云官方最近推出GPU狂欢月活动!高配4090折扣劲爆价!如果你对算力感兴趣或有需求,可以来厚德云官方看看!
厚德云是专业的AI算力云平台,为用户提供稳定、可靠、易用、省钱的GPU算力解决方案。海量GPU算力资源租用,就在厚德云。
版权归原作者 厚德云 所有, 如有侵权,请联系我们删除。