
机器学习卷积神经网络YOLOv5佩戴安全帽检测和识别含佩戴安全帽
目录
设计项目案例演示地址: 链接
毕业设计代做一对一指导项目方向涵盖:
基于Python,MATLAB设计,OpenCV,,CNN,机器学习,R-CNN,GCN,LSTM,SVM,BP目标检测、语义分割、Re-ID、医学图像分割、目标跟踪、人脸识别、数据增广、
人脸检测、显著性目标检测、自动驾驶、人群密度估计、3D目标检测、CNN、AutoML、图像分割、SLAM、实例分割、人体姿态估计、视频目标分割,PyTorch、人脸检测、车道线检测、去雾 、全景分割、
行人检测、文本检测、OCR、姿态估计、边缘检测、场景文本检测、视频实例分割、3D点云、模型压缩、人脸对齐、超分辨、去噪、强化学习、行为识别、OpenCV、场景文本识别、去雨、机器学习、风格迁移、
视频目标检测、去模糊、活体检测、人脸关键点检测、3D目标跟踪、视频修复、人脸表情识别、时序动作检测、图像检索、异常检测等毕设指导,毕设选题,毕业设计开题报告,
1. 前言
安全帽是作业场所作业时头部防护所用的头部防护用品,它对使用者的头部在受坠落物或小型飞溅物体等其他因素引起的伤害起到防护作用。近年来,因不佩戴安全帽、不规范佩戴安全帽等原因导致的安全生产事故屡禁不止,事故发生背后的影响是巨大的,不仅为家人带来巨大的伤痛,也为企业的利益带来巨大的损失。而如何使员工规范佩戴安全帽、保障员工和企业双方利益,成为了一直以来各方坚持不懈想要实现的目标。因此,研究佩戴安全帽的监测算法,具有重大的意义和广泛的应用价值。
本篇博客,将手把手教你搭建一个基于YOLOv5的佩戴安全帽目标检测识别方法。目前,基于YOLOv5s的目标检测的佩戴安全帽识别方法的平均精度平均值mAP_0.5=0.93,mAP_0.5:0.95=0.63,基本满足业务的性能需求。
另外,为了能部署在手机Android平台上,本人对YOLOv5s进行了模型轻量化,开发了一个轻量级的版本yolov5s05_416和yolov5s05_320,在普通Android手机上可以达到实时的检测和识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
先展示一下Python版本佩戴安全帽检测和识别Demo效果(head表示(头部)未佩戴安全帽,helmet表示佩戴了安全帽):


2. 佩戴安全帽检测和识别的方法
(1)基于目标检测的佩戴安全帽识别方法
基于目标检测的佩戴安全帽识别方法,一步到位,把佩戴安全帽类别直接当成多个目标检测的类别进行训练。
- 该方案采用one-stage的方法,直接端到端训练,任务简单,速度较快;+ 新增类别或者数据,需要人工拉框标注佩戴安全帽的框,成本较大+ 部署简单
(2)基于头部检测+佩戴安全帽分类识别方法
该方法,先训练一个通用的头部检测模型(不区分是否佩戴安全帽),然后外扩检测框并裁剪头部区域,再训练一个佩戴安全帽分类器,完成对佩戴安全帽的分类识别。当然一个更加简单的方法是,可以将人脸检测器当做头部检测器,即将人脸检测框外扩2倍左右,作为头部检测框的区域。只是这样做,若人背向,人脸检测器一般效果比较差,无法识别是否佩戴了安全帽。
- 该方案采用two-stage方法,可针对性分别提高检测模型和分类模型的性能+ 头部检测模型不区分是否佩戴安全帽,只检测头部检测框,检测精度较高,+ 佩戴安全帽分类模型可以做到很轻量+ 由于采用two-stage方法进行检测-识别,因此速度相对较慢
考虑到佩戴安全帽检测和识别的任务比较简单,因此本博客将采用“基于目标检测的佩戴安全帽识别方法”。目标检测的的方法较多,比如Faster-RCNN,YOLO系列,SSD等均可以采用,本博客将采用YOLOv5进行佩戴安全帽目标检测模型训练。
3. 佩戴安全帽数据集说明
(1)佩戴安全帽数据集
目前收集了2W+的佩戴安全帽数据集:
- Helmet-Asian亚洲人佩戴安全帽数据集:总共有19000+图片,VOC的XML数据格式,可直接用于目标检测模型训练。+ Helmet-Europe欧洲人佩戴安全帽数据集:总共有3000+图片,VOC的XML数据格式,可直接用于目标检测模型训练。
(2)自定义数据集
如果需要增/删类别数据进行训练,或者需要自定数据集进行训练,可参考如下步骤:
- 采集图片,建议不少于200张图片+ 使用Labelme等标注工具,对目标进行拉框标注:labelme工具:GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).+ 将标注格式转换为VOC数据格式,参考工具:labelme/labelme2voc.py at main · wkentaro/labelme · GitHub+ 生成训练集train.txt和验证集val.txt文件列表+ 修改engine/configs/voc_local.yaml的train和val的数据路径+ 重新开始训练
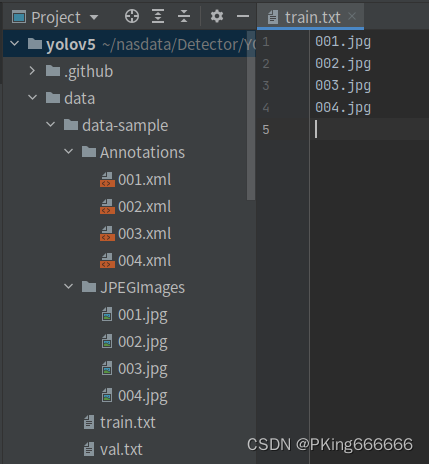
4. 基于YOLOv5的佩戴安全帽模型训练
(1)YOLOv5安装
训练Pipeline采用YOLOv5: https://github.com/ultralytics/yolov5 , 原始代码训练需要转换为YOLO的格式,不支持VOC的数据格式。为了适配VOC数据,本人新增了LoadVOCImagesAndLabels用于解析VOC数据集进行训练。另外,为了方便测试,还增加demo.py文件,可支持对图片,视频和摄像头的测试。
Python依赖环境,使用pip安装即可:
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
thop # FLOPs computation
pybaseutils
项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境):
- 项目开发使用教程和常见问题和解决方法+ 视频教程:1 手把手教你安装CUDA和cuDNN(1)+ 视频教程:2 手把手教你安装CUDA和cuDNN(2)+ 视频教程:3 如何用Anaconda创建pycharm环境+ 视频教程:4 如何在pycharm中使用Anaconda创建的python环境
(2)准备Train和Test数据
下载Helmet-Asian和Helmet-Europe佩戴安全帽数据集,总共约2W+的图片
Helmet-Asian****Helmet-Europe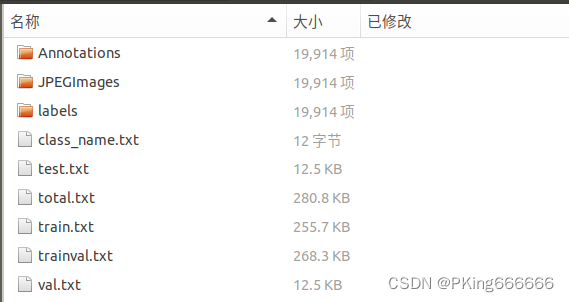
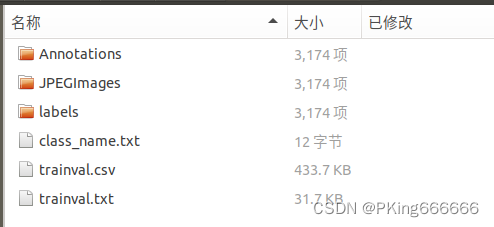
(3)配置数据文件
- 修改训练和测试数据的路径:engine/configs/voc_local.yaml+ 注意数据路径分隔符使用【/】,不是【\】+ 项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]# 数据路径
path: ""# dataset root dir
train:
- "D:/path/to/helmet/Helmet-Asian/trainval.txt"
- "D:/path/to/helmet/Helmet-Europe/trainval.txt"
val:
- "D:/path/to/helmet/Helmet-Asian/test.txt"
test: # test images (optional)
data_type: voc
# Classes
nc: 2# number of classes
names: {'head':0, "helmet":1}
(4)配置模型文件
官方YOLOv5给出了YOLOv5l,YOLOv5m,YOLOv5s等模型。考虑到手机端CPU/GPU性能比较弱鸡,直接部署yolov5s运行速度十分慢。所以本人在yolov5s基础上进行模型轻量化处理,即将yolov5s的模型的channels通道数全部都减少一半,并且模型输入由原来的640×640降低到416×416或者320×320,该轻量化的模型我称之为yolov5s05。从性能来看,yolov5s05比yolov5s快5多倍,而mAP下降了9%(0.93→0.84),对于手机端,这精度勉强可以接受。
下面是yolov5s05和yolov5s的参数量和计算量对比:
*模型input-sizeparams(M)GFLOPsmAP0.5*yolov5s640×6407.216.5
0.93067 yolov5s05416×4161.71.8
0.87051 yolov5s05320×3201.71.1
0.84477
(5)重新聚类Anchor(可选)
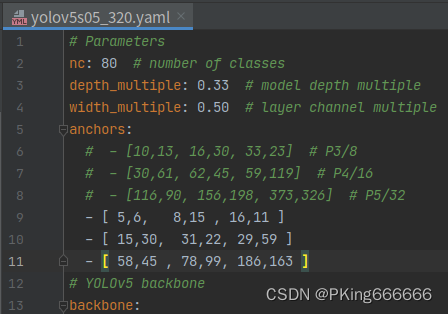
官方yolov5s的Anchor是基于COCO数据集进行聚类获得(详见models/yolov5s.yaml文件)
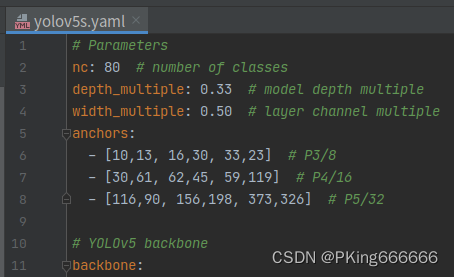
对于yolov5s05的Anchor,由于输入大小640缩小到320,其对应的Anchor也应该缩小一倍:
一点建议:
- 官方yolov5s的Anchor是基于COCO数据集进行聚类获得,不同数据集需要做适当的调整,其最优Anchor建议重新进行聚类 。+ 当然你要是觉得麻烦就跳过,不需要重新聚类Anchor,这个影响不是特别大。如果你需要重新聚类,请参考engine/kmeans_anchor/demo.py文件
(6)开始训练
整套训练代码非常简单操作,填写好对应的数据路径,即可开始训练了。
- 修改训练超参文件: data/hyps/hyp.scratch-v1.yaml (可以修改训练学习率,数据增强等方式,使用默认即可)+ Linux系统终端运行,训练yolov5s或轻量化版本yolov5s05_416或者yolov5s05_320 (选择其中一个训练即可)
#!/usr/bin/env bash#--------------训练yolov5s--------------# 输出项目名称路径project="runs/yolov5s_640"# 训练和测试数据的路径data="engine/configs/voc_local.yaml"# YOLOv5模型配置文件cfg="yolov5s.yaml"# 训练超参数文件hyp="data/hyps/hyp.scratch-v1.yaml"# 预训练文件weights="engine/pretrained/yolov5s.pt"
python train.py --data$data--cfg$cfg--hyp$hyp--weights$weights --batch-size 64--imgsz640--workers12--project$project#--------------训练轻量化版本yolov5s05_416--------------# 输出项目名称路径project="runs/yolov5s05_416"# 训练和测试数据的路径data="engine/configs/voc_local.yaml"# YOLOv5模型配置文件cfg="yolov5s05_416.yaml"# 训练超参数文件hyp="data/hyps/hyp.scratch-v1.yaml"# 预训练文件weights="engine/pretrained/yolov5s.pt"
python train.py --data$data--cfg$cfg--hyp$hyp--weights$weights --batch-size 64--imgsz416--workers12--project$project#--------------训练轻量化版本yolov5s05_320--------------# 输出项目名称路径project="runs/yolov5s05_320"# 训练和测试数据的路径data="engine/configs/voc_local.yaml"# YOLOv5模型配置文件cfg="yolov5s05_320.yaml"# 训练超参数文件hyp="data/hyps/hyp.scratch-v1.yaml"# 预训练文件weights="engine/pretrained/yolov5s.pt"
python train.py --data$data--cfg$cfg--hyp$hyp--weights$weights --batch-size 64--imgsz320--workers12--project$project
- Windows系统终端运行,训练yolov5s或轻量化版本yolov5s05_416或者yolov5s05_320 (选择其中一个训练即可)
#!/usr/bin/env bash#--------------训练yolov5s--------------
python train.py --data engine/configs/voc_local.yaml --cfg yolov5s.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 64--imgsz640--workers12--project runs/yolov5s_640
#--------------训练轻量化版本yolov5s05_416--------------
python train.py --data engine/configs/voc_local.yaml --cfg yolov5s05_416.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 64--imgsz416--workers12--project runs/yolov5s05_416
#--------------训练轻量化版本yolov5s05_320--------------
python train.py --data engine/configs/voc_local.yaml --cfg yolov5s05_320.yaml --hyp data/hyps/hyp.scratch-v1.yaml --weights engine/pretrained/yolov5s.pt --batch-size 64--imgsz320--workers12--project runs/yolov5s05_320
- 开始训练:
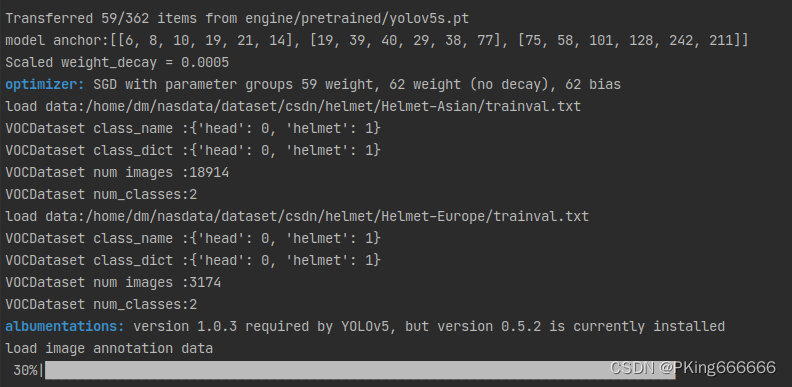
训练完成,可以得到yolov5s佩戴安全帽识别的mAP指标大约mAP_0.5=0.93;而
yolov5s05_416 mAP_0.5=0.87左右;yolov5s05_320 mAP_0.5=0.84左右
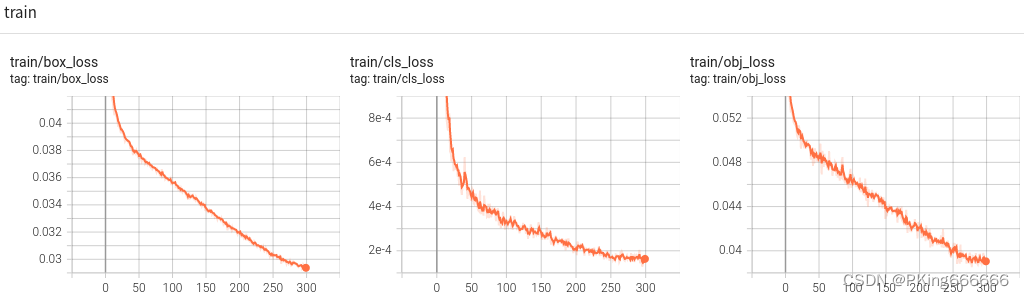
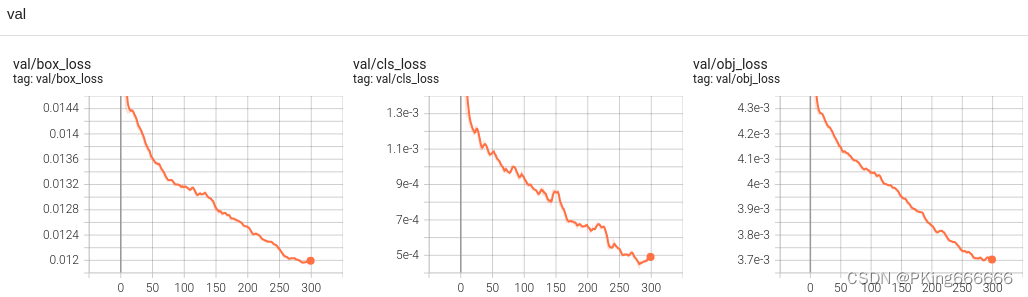
(7)可视化训练过程
训练过程可视化工具是使用Tensorboard,使用方法,在终端输入:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir ./runs/yolov5s_640
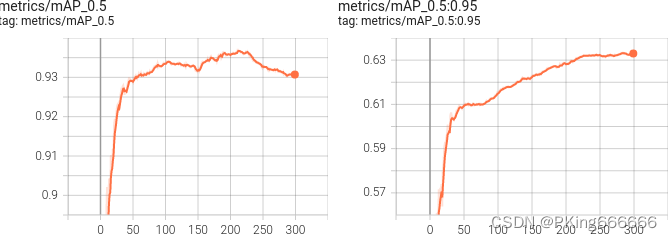

- 这是每个类别的F1-Score分数
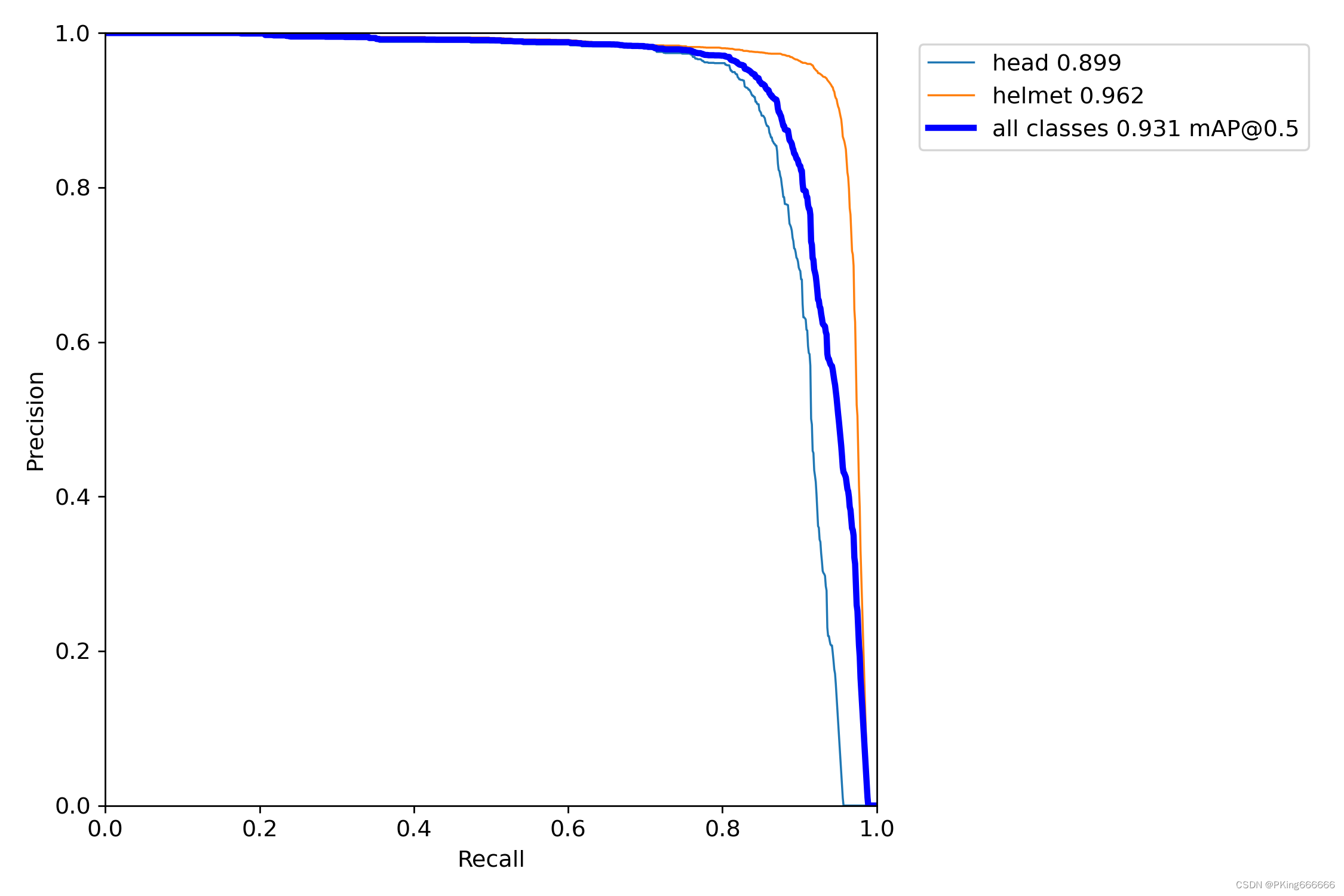
- 这是模型的PR曲线
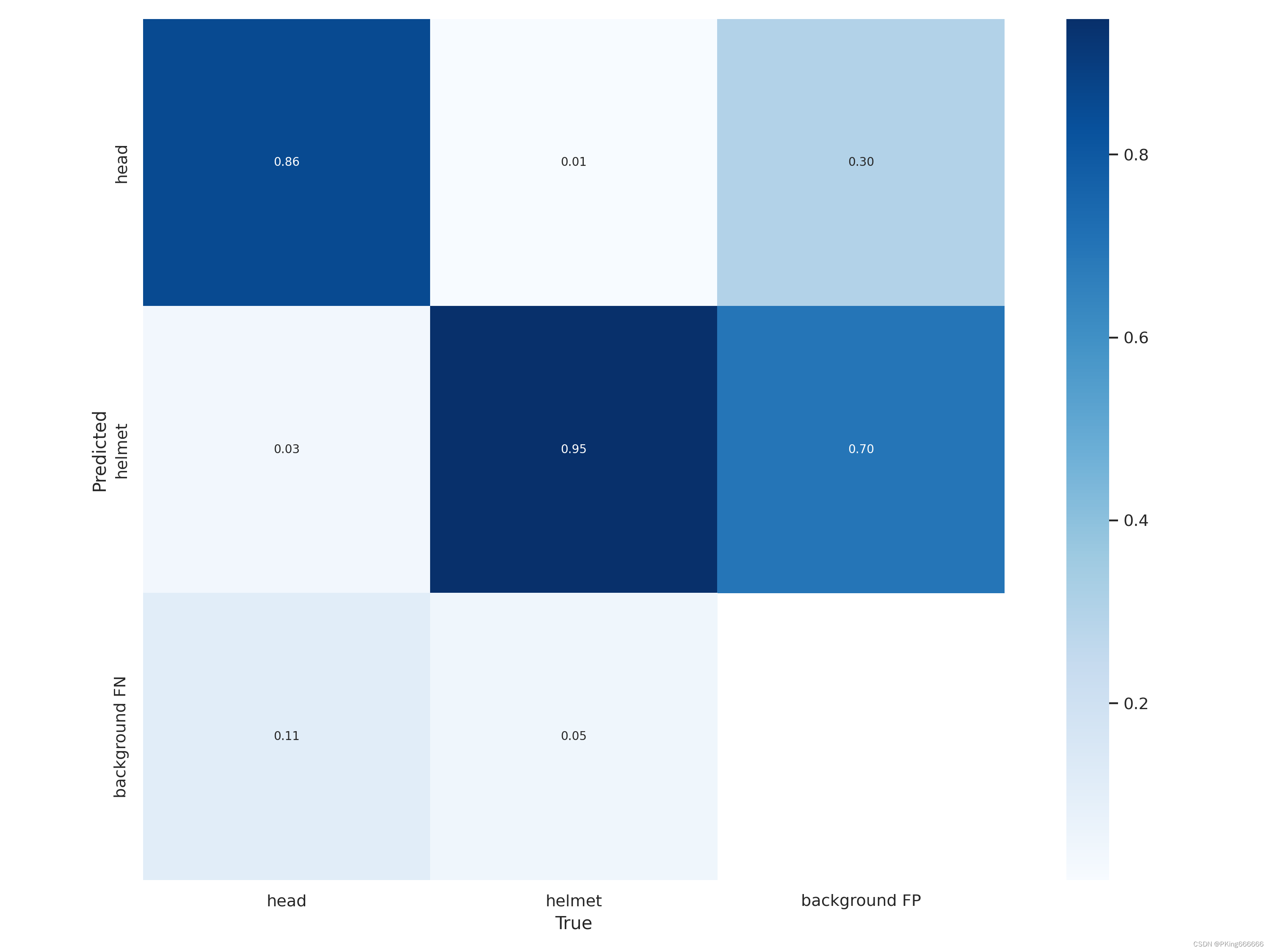
- 这是混淆矩阵:
(8)常见的错误
- YOLOv5 BUG修复记录+ 项目安装教程请参考:项目开发使用教程和常见问题和解决方法+ 项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!!!!!!!!
5. Python版本佩戴安全帽检测效果
demo.py文件用于推理和测试模型的效果,填写好配置文件,模型文件以及测试图片即可运行测试了
- 测试图片
# 测试图片(Linux系统)image_dir='data/helmet-test'# 测试图片的目录weights="runs/model/yolov5s_640/weights/best.pt"# 模型文件out_dir="runs/helmet-result"# 保存检测结果
python demo.py --image_dir$image_dir--weights$weights--out_dir$out_dir```
Windows系统,请将$image_dir, $weights ,$out_dir等变量代替为对应的变量值即可,如
```bash
# 测试图片(Windows系统)
python demo.py --image_dir data/helmet-test --weights runs/model/yolov5s_640/weights/best.pt --out_dir runs/helmet-result
- 测试视频文件
# 测试视频文件(Linux系统)video_file="data/helmet-test.mp4"# path/to/video.mp4 测试视频文件,如*.mp4,*.avi等weights="runs/model/yolov5s_640/weights/best.pt"# 模型文件out_dir="runs/helmet-result"# 保存检测结果
python demo.py --video_file$video_file--weights$weights--out_dir$out_dir``````bash
# 测试视频文件(Windows系统)
python demo.py --video_file data/helmet-test.mp4 --weights runs/model/yolov5s_640/weights/best.pt --out_dir runs/helmet-result
- 测试摄像头
# 测试摄像头(Linux系统)video_file=0# 测试摄像头IDweights="runs/model/yolov5s_640/weights/best.pt"# 模型文件out_dir="runs/helmet-result"# 保存检测结果
python demo.py --video_file$video_file--weights$weights--out_dir$out_dir
# 测试摄像头(Windows系统)
python demo.py --video_file0--weights runs/model/yolov5s_640/weights/best.pt --out_dir runs/helmet-result
先展示一下Python版本佩戴安全帽检测和识别Demo效果(head表示(头部)未佩戴安全帽,helmet表示佩戴了安全帽):




如果想进一步提高模型的性能,可以尝试:
- 增加训练的样本数据: 目前只有2W+的数据量,建议根据自己的业务场景,采集相关数据,提高模型泛化能力+ 使用参数量更大的模型: 本教程使用的YOLOv5s,其参数量才7.2M,而YOLOv5x的参数量有86.7M,理论上其精度更高,但推理速度也较慢。+ 尝试不同数据增强的组合进行训练
7.项目源码下载
整套项目源码内容包含佩戴安全帽数据集 +** YOLOv5训练代码和测试代码**
项目源码下载:YOLOv5实现佩戴安全帽检测和识别(含佩戴安全帽数据集+训练代码)
(1)佩戴安全帽数据集,总共2W+图片
- Helmet-Asian亚洲人佩戴安全帽数据集:总共有19000+图片,VOC的XML数据格式,可直接用于目标检测模型训练。+ Helmet-Europe欧洲人佩戴安全帽数据集:总共有3000+图片,VOC的XML数据格式,可直接用于目标检测模型训练。
(2)YOLOv5训练代码和测试代码(Pytorch)
- 整套YOLOv5项目工程,含训练代码train.py和测试代码demo.py+ 支持高精度版本yolov5s训练和测试+ 支持轻量化版本yolov5s05_320和yolov5s05_416训练和测试+ 根据本篇博文说明,简单配置即可开始训练:train.py+ 源码包含了训练好的yolov5s,yolov5s05_416和yolov5s05_320模型,配置好环境,可直接运行demo.py+ 测试代码demo.py支持图片,视频和摄像头测试
(1)佩戴安全帽数据集,总共2W+图片
- Helmet-Asian亚洲人佩戴安全帽数据集:总共有19000+图片,VOC的XML数据格式,可直接用于目标检测模型训练。+ Helmet-Europe欧洲人佩戴安全帽数据集:总共有3000+图片,VOC的XML数据格式,可直接用于目标检测模型训练。
关于数据详细说明:佩戴安全帽数据集使用说明和下载
(2)YOLOv5训练代码和测试代码(Pytorch)
- 整套YOLOv5项目工程,含训练代码train.py和测试代码demo.py+ 支持高精度版本yolov5s训练和测试+ 支持轻量化版本yolov5s05_320和yolov5s05_416训练和测试+ 根据本篇博文说明,简单配置即可开始训练:train.py+ 源码包含了训练好的yolov5s,yolov5s05_416和yolov5s05_320模型,配置好环境,可直接运行demo.py+ 测试代码demo.py支持图片,视频和摄像头测试
设计项目案例演示地址: 链接
毕业设计代做一对一指导项目方向涵盖:
基于Python,MATLAB设计,OpenCV,,CNN,机器学习,R-CNN,GCN,LSTM,SVM,BP目标检测、语义分割、Re-ID、医学图像分割、目标跟踪、人脸识别、数据增广、
人脸检测、显著性目标检测、自动驾驶、人群密度估计、3D目标检测、CNN、AutoML、图像分割、SLAM、实例分割、人体姿态估计、视频目标分割,PyTorch、人脸检测、车道线检测、去雾 、全景分割、
行人检测、文本检测、OCR、姿态估计、边缘检测、场景文本检测、视频实例分割、3D点云、模型压缩、人脸对齐、超分辨、去噪、强化学习、行为识别、OpenCV、场景文本识别、去雨、机器学习、风格迁移、
视频目标检测、去模糊、活体检测、人脸关键点检测、3D目标跟踪、视频修复、人脸表情识别、时序动作检测、图像检索、异常检测等毕设指导,毕设选题,毕业设计开题报告,
版权归原作者 purple_love 所有, 如有侵权,请联系我们删除。