
深度搜索Agent核心问题其实就有两个:怎么把复杂问题拆得合理,以及怎么判断搜索结果够不够用。近两年深度搜索Agent发展很快各家的实现思路也越来越成熟,围绕这两个问题业界逐渐沉淀出几种主流架构:从最基础的Planner-Only,到加入评估反馈的双模块设计,再到Sentient Labs提出的递归式方案。这篇文章将整理这些架构并顺便附上一些实用的prompt模板。
迭代式搜索Agent
在讨论更复杂的架构之前,先回顾一下最基础的迭代式搜索Agent。这类Agent通常基于ReAct(Reasoning and Acting)范式,工作流程很简单:接收问题→思考→调用工具搜索→观察结果→继续思考→再搜索...如此循环直到找到满意的答案。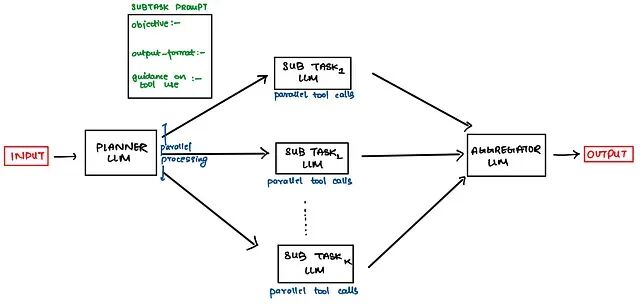
但是这种简单的迭代模式有个问题:当面对复杂查询时单线程一步步搜效率太低。于是就有了并行工作流的思路,把一个大问题拆成多个子查询,让多个搜索任务同时跑。
Planner-Only架构
但并行工作流又有个明显的短板:子查询数量是写死的。实际情况是简单问题拆2-3个子查询就够了,而复杂问题可能要拆5-6个甚至更多。也就是说子查询的拆分应该是动态的而不是预先固定。
Planner LLM就是为解决这个问题产生的。它的作用很简单,就是分析用户问题的复杂度,决定应该拆成多少个子任务,每个子任务负责什么,以及应该调用哪些工具。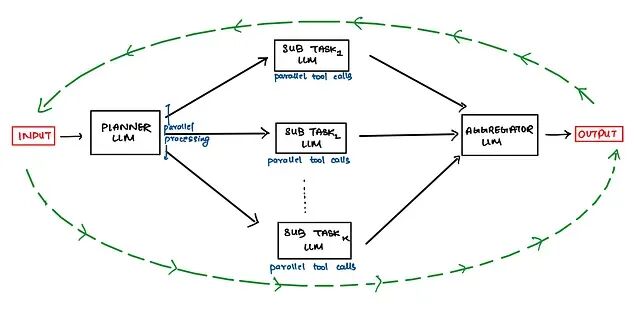
一个典型的Planner提示词结构如下:
# MAKE A STRATEGY/PLAN, YOU HAVE ACCESS TO FOLLOWING TOOLS
↳ describe tools & their input parameters here
# GUIDELINES FOR QUERY COMPLEXITY, TOOL CALLS & [#SUBAGENTS](#SUBAGENTS)
↳ simple fact finding queries requires just 1 subtask with 3-10 tool calls.
↳ direct comparison queries might need 2-5 subtasks with 10-15 tools call each.
↳ complex research might use more than 10 subtasks with clearly divided responsibilities
# CLEARLY DEFINE EACH SUBAGENT'S ROLE IN FOLLOWING FORMAT
{
objective :-
output_format :-
tool_guidance :-
rationale :-
}
# HEURISTICS FOR TOOL GUIDANCE (basically here we are doing Tool RAG)
examine all available tools first, match tool usage to subagent objective,
search the web only for broad external information or prefer specialized tools
over generic ones.
这个提示词模板的设计思路值需要注意的是:首先告诉Planner有哪些工具可用,然后给出不同复杂度问题的拆分参考标准,最后要求它为每个子Agent明确定义目标、输出格式和工具使用指导。这样Planner输出的计划才足够具体,下游的执行Agent才能照着执行。
Planner承担的任务复杂度高是整个架构的核心节点。所以强烈建议用推理能力强的模型来做Planner,比如GPT-4o、Claude 3.5 Sonnet或者专门的推理模型如o1、DeepSeek-R1等。
停止条件的处理
有了Planner问题拆分的问题解决了,但还有另一个老问题:ReAct循环什么时候该停?
传统做法是手动设一个固定阈值靠经验调参比如最多跑5轮,但这显然不够灵活,因为复杂查询需要更多轮迭代,简单查询几轮就够了。固定阈值要么会让简单问题跑太多轮浪费资源,要么会让复杂问题提前结束拿不到完整答案。
所以解决办法是引入一个评估器LLM,每轮迭代后让评估器判断当前答案是否已经足够好,如果够好就停不够就继续跑。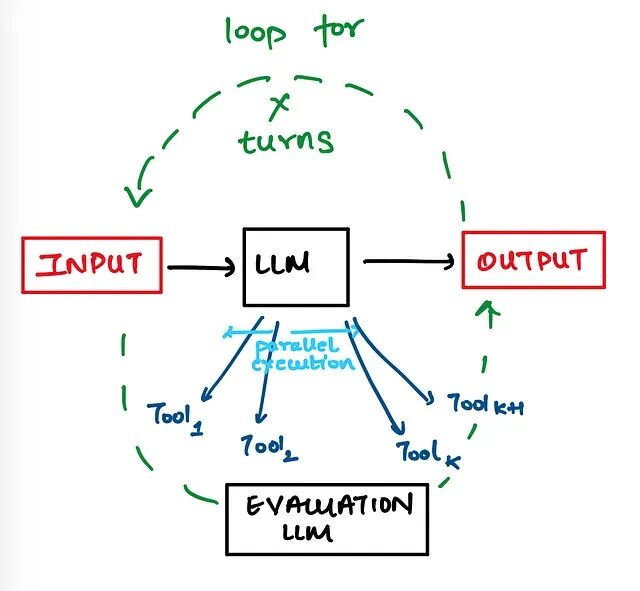
评估器的提示词可以这样写:
# TASK
Your task is to analyse and determine if following information is sufficient
or there are knowledge gaps?? Provide reasoning for your answer
# Question
add here the user question
# Generated Answer
add here the answer generated by this iteration of ReAct
# OUTPUT FORMAT
{
"is_sufficient": true/false
"reasoning":
"knowledge_gap":
}
评估器需要做两件事:判断当前答案是否充分,以及如果不充分的话缺的是什么。
knowledge_gap
字段很关键,它可以指导下一轮迭代应该往哪个方向搜。
澄清问题机制
OpenAI在评估器的基础上又加了一层设计。他们观察到有些特别刁钻的问题LLM怎么搜都找不到满意的答案,评估器一直返回
is_sufficient = false
循环就没完没了。
这种情况往往不是搜索能力的问题而是问题本身定义不清,比如用户问"最好的笔记本电脑是哪个",这里的"最好"指什么?性价比最高?性能最强?便携性最好?不同的理解会导向完全不同的搜索方向。
所以OpenAI的方案是:当评估器发现反复搜索都无法得到充分答案时,不如让Agent主动问用户几个澄清问题,把人拉进来帮忙明确需求。这就是所谓的human-in-the-loop设计。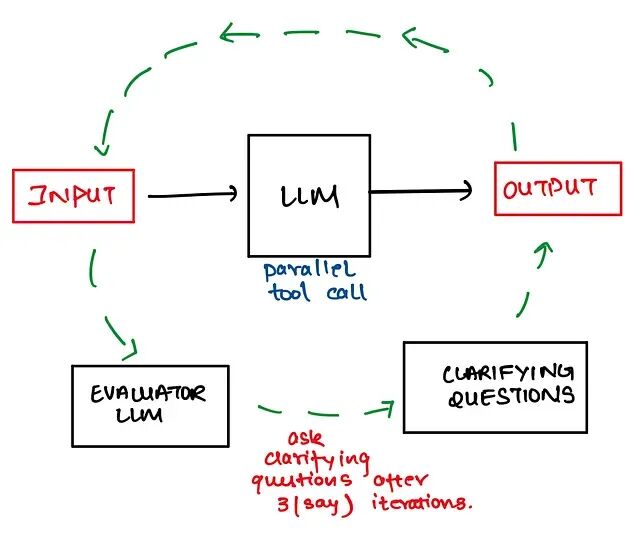
检查清单评分
而SamayaAI提出了另一种评估思路:检查清单评分,这个方案对长篇幅答案特别有效。
传统评估器面对长答案容易"晕",单个LLM很难在一大段文本里保持完整的推理链,上下文一长就开始丢信息,评估结果也就不太靠谱了。SamayaAI的想法是,与其让评估器去理解和评判整个答案的内容质量不如换个角度来评估答案是否符合预设的结构规范,这个结构规范就是所谓的检查清单。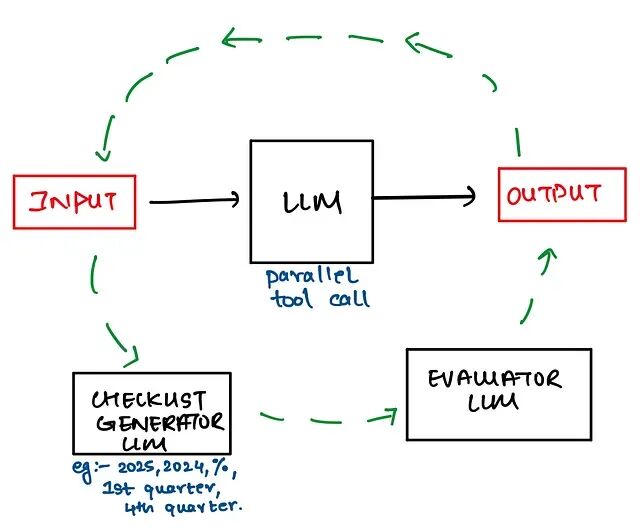
比如说,如果用户问的是"对比A和B两个产品"检查清单可能包括:是否分别介绍了A和B的特点?是否有价格对比?是否有优缺点总结?是否给出了推荐建议?评估器只需要逐项打勾比从头读完整个答案再打分要简单得多。
# TASK
Your task is to analyse and determine if the answer follows following checklist
or not. If not the identify knowledge gaps. Provide reasoning for your answer.
# Question
add here the user question
# Generated Answer
add here the answer generated by this iteration of ReAct
# Checklist
add your checklist here
# OUTPUT FORMAT
{
"is_sufficient": true/false
"reasoning":
"knowledge_gap":
}
Planner + Plan Evaluator双模块架构
前面说的评估器主要是评估搜索结果,但其实Planner生成的计划本身也可能有问题。于是就有了Planner + Plan Evaluator的双模块设计:先让Planner生成计划,再让评估器审核这个计划靠不靠谱,通过了再执行。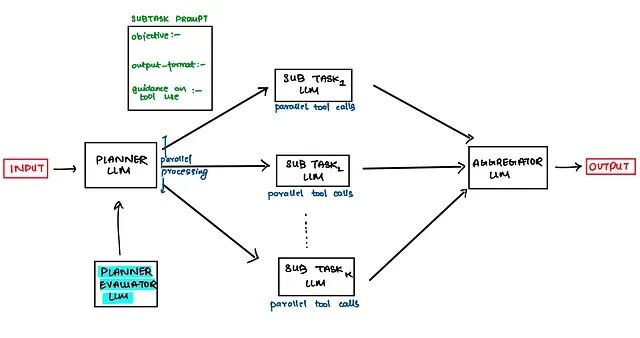
Plan Evaluator有几种典型的设计思路。
思路一:多计划竞争。让Planner并行生成多个执行计划,评估器从中挑最优的那个。这样能提高计划质量,但代价是成本和延迟都会上升——多生成几个计划就多几倍的token消耗。
思路二:单计划审核。先生成一个计划,评估器判断好坏,好就执行不好就打回去重新生成。这个思路成本更可控,但可能需要多轮打回-重生成才能得到合格的计划。
计划出问题一般都会是以下几种情况:
目标失败:Agent没完成任务或者完成了但违反了约束条件。比如让模型规划一趟从旧金山到印度的两周旅行,预算5000美元,结果它给你规划到越南去了;或者确实规划了印度行程但预算直接超了。
工具失败:这又分好几种情况。可能是生成了根本不存在的工具名(比如调用
bing_search
但工具库里压根没这个);可能是工具对了但参数个数不对(
lbs_to_kg
只需要一个参数,它传了俩);也可能是参数个数对了但值填错了(该传120传成了100)。
Plan Evaluator需要针对这些常见问题设计检查逻辑,在计划执行前就把明显的错误拦住,避免浪费执行资源。
递归搜索Agent
前面介绍的架构本质上都是迭代式的,但从算法角度看迭代能做的事递归也能做,而且递归天然适合处理可分解的层次化问题。
Sentient Labs就按照这个思路搞出了ROMA(Recursive Open Meta Agent)。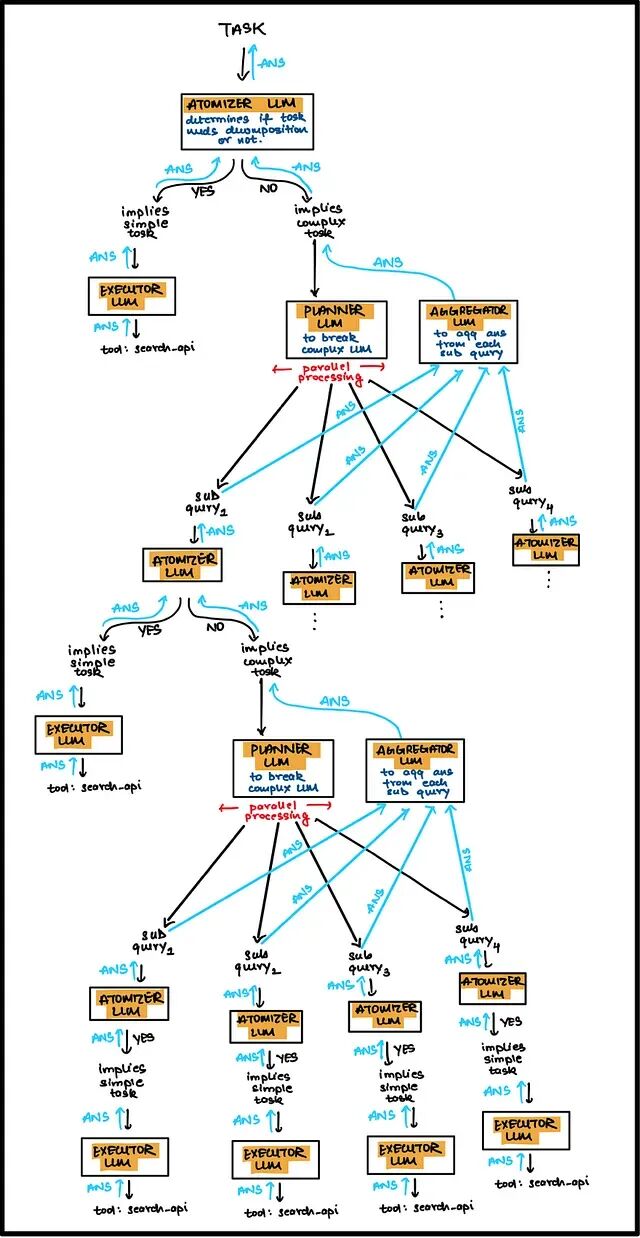
ROMA的核心思想是:把复杂问题递归地分解成子问题,每个子问题再独立处理。和普通的并行拆分不同,ROMA的子问题之间可以有依赖关系——某个子问题的答案可能是另一个子问题的输入。这种设计更符合复杂研究任务的实际结构。
上图是ROMA的简化版本,完整架构还有一层基于依赖图的信息抽取机制。依赖图用来管理子问题之间的前后关系,确保有依赖的任务按正确顺序执行。
递归架构的优势在于理论上可以处理任意深度的复杂查询,只要问题能被合理分解。但工程实现上也更有挑战,需要处理好递归深度控制、子问题结果合并、错误传播等问题。
总结
这几种架构并不是非此即彼的关系。Planner-Only适合入门,实现简单调试方便;加上评估器后系统变得更智能,但复杂度和成本也跟着上来;检查清单评分这类方案对长文档输出效果不错,值得在特定场景下尝试;而ROMA的递归思路理论上能处理更深层次的复杂查询,不过工程实现的门槛也更高。
实际落地时,可以先从简单架构跑通,再根据具体问题逐步叠加模块。毕竟Agent系统的调试本身就不容易,一上来就搞太复杂容易把自己绕进去。