

好久都没更新了,所以今天翻译一篇文章凑个数吧:
本文代码 https://gitlab.com/rahasak-labs/dot
作者:λ.erang
在这篇文章中,我将讨论使用协同过滤机器学习方法构建图书推荐系统。Spark-ML中的协同过滤模型采用交替最小二乘(ALS)算法。这篇文章的源代码和数据集可以在gitlab上找到。
推荐系统
推荐系统使用机器学习算法向特定用户或客户推荐最相关的产品。它的工作原理是在消费者行为数据中寻找显示和隐式的模式。推荐系统最常见的示例是亚马逊上的产品推荐、Netflix 中电影和电视节目的推荐、YouTube 上的推荐视频、Spotify 上的音乐、Facebook 新闻和 Google Ads。在机器学习中,主要有两种用于提供推荐的主要技术,1)基于内容的过滤,2)协同过滤。
基于内容的过滤
基于内容的过滤会分析每个产品的属性,旨在找到数据的来识别用户偏好。基于内容推荐依靠产品自身的特征来进行推荐。比如用户生成的电影标签、产品颜色、文本描述、用户的评论、电影流派、导演、剧情介绍、演员等。这些推荐系统背后的一般思想是,如果一个人喜欢特定产品 ,他或她也会喜欢与之相似的产品。换句话说,这些算法尝试推荐与用户过去喜欢的项目相似的项目。这可以在 Netflix、Facebook Watch 等应用程序中看到,它们根据导演、演员等推荐下一部电影或视频。
协同过滤
协同过滤根据用户过去的经验和行为推荐项目。与基于内容的过滤不同,它不需要有关产品或用户本身的任何信息。协同过滤背后的关键思想是相似的用户有相似的兴趣,具有相似兴趣的人倾向于喜欢相似的产品。系统会匹配具有相似兴趣的人并基于该匹配进行推荐。这方面的主要示例是 Google Ads。协同过滤有两类,1)基于用户 2)基于产品。基于用户的协同过滤衡量目标用户与其他用户之间的相似度(计算用户之间的相似度)。基于产品的协同过滤衡量目标用户的产品与其他产品之间的相似度(计算产品之间的相似度)。协同过滤的一个问题是,它无法对没有评分的新产品(例如产品、电影、歌曲等)进行推荐(冷启动问题)。
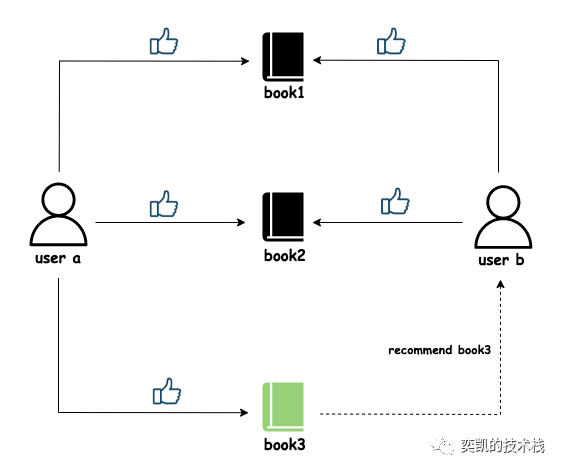
考虑以下书籍推荐场景。用户 A 和 B 对 Book1 和 Book2 给予了很高的评价。然后它可以假设它们必须具有相似的品味。因此,用户 B 喜欢一本他/她没有遇到但被用户 A 评价很高的书的可能性更高。在这种情况下,用户 A 对 Book3 进行了评价。但用户 B 没有遇到它,因此推荐系统向用户 B 推荐 Book 3。
数据集
本篇文章的书籍推荐系统中使用了两个CSV数据集。一个数据集包含书籍的信息,另一个数据集包含书籍的用户评分。 完整的数据集可以在 Kaggle 中找到。
https://www.kaggle.com/somnambwl/bookcrossing-dataset
准备数据
首先,我已将 CSV 数据集加载到 Spark DataFrames 中并对其进行了一些数据处理。基本上我已经加入了书籍数据集和评级数据集。
// context for spark
valspark=SparkSession.builder
.master("local[*]")
.appName("lambda")
.getOrCreate()
// SparkSession has implicits
importspark.implicits._
// book schema
valbookSchema=StructType(
StructField("ISBN", StringType, nullable=true) ::
StructField("Title", StringType, nullable=true) ::
StructField("Author", StringType, nullable=true) ::
StructField("Year", IntegerType, nullable=true) ::
StructField("Publisher", StringType, nullable=true) ::
Nil
)
// rating schema
valratingSchema=StructType(
StructField("USER-ID", IntegerType, nullable=true) ::
StructField("ISBN", IntegerType, nullable=true) ::
StructField("Rating", IntegerType, nullable=true) ::
Nil
)
// read books
valbookDf=spark.read.format("csv")
.option("header", value=true)
.option("delimiter", ";")
.option("mode", "DROPMALFORMED")
.schema(bookSchema)
.load(getClass.getResource("/rec_books.csv").getPath)
.cache()
.as("books")
bookDf.printSchema()
bookDf.show(10)
/*
output
root
|-- ISBN: string (nullable = true)
|-- Title: string (nullable = true)
|-- Author: string (nullable = true)
|-- Year: integer (nullable = true)
|-- Publisher: string (nullable = true)
+----------+--------------------+--------------------+----+--------------------+
| ISBN| Title| Author|Year| Publisher|
+----------+--------------------+--------------------+----+--------------------+
|0195153448| Classical Mythology| Mark P. O. Morford|2002|Oxford University...|
|0002005018| Clara Callan|Richard Bruce Wright|2001|HarperFlamingo Ca...|
|0060973129|Decision in Normandy| Carlo D'Este|1991| HarperPerennial|
|0374157065|Flu: The Story of...| Gina Bari Kolata|1999|Farrar Straus Giroux|
|0393045218|The Mummies of Ur...| E. J. W. Barber|1999|W. W. Norton & Co...|
|0399135782|The Kitchen God's...| Amy Tan|1991| Putnam Pub Group|
|0425176428|What If?: The Wor...| Robert Cowley|2000|Berkley Publishin...|
|0671870432| PLEADING GUILTY| Scott Turow|1993| Audioworks|
|0679425608|Under the Black F...| David Cordingly|1996| Random House|
|074322678X|Where You'll Find...| Ann Beattie|2002| Scribner|
+----------+--------------------+--------------------+----+--------------------+
*/
// read ratings
valratingDf=spark.read.format("csv")
.option("header", value=true)
.option("delimiter", ";")
.option("mode", "DROPMALFORMED")
.schema(ratingSchema)
.load(getClass.getResource("/rec_ratings.csv").getPath)
.cache()
.as("ratings")
ratingDf.printSchema()
ratingDf.show(10)
/*
output
root
|-- USER-ID: integer (nullable = true)
|-- ISBN: integer (nullable = true)
|-- Rating: integer (nullable = true)
+-------+----------+------+
|USER-ID| ISBN|Rating|
+-------+----------+------+
| 276726| 155061224| 5|
| 276727| 446520802| 0|
| 276729| 521795028| 6|
| 276733|2080674722| 0|
| 276737| 600570967| 6|
| 276745| 342310538| 10|
| 276746| 425115801| 0|
| 276746| 449006522| 0|
| 276746| 553561618| 0|
| 276746| 786013990| 0|
+-------+----------+------+
*/
// join dfs
valjdf=ratingDf.join(bookDf, $"ratings.ISBN"===$"books.ISBN")
.select(
$"ratings.USER-ID".as("userId"),
$"ratings.Rating".as("rating"),
$"ratings.ISBN".as("isbn"),
$"books.Title".as("title"),
$"books.Author".as("author"),
$"books.Year".as("year"),
$"books.Publisher".as("publisher")
)
jdf.printSchema()
jdf.show(10)
/*
output
root
|-- userId: integer (nullable = true)
|-- rating: integer (nullable = true)
|-- isbn: integer (nullable = true)
|-- title: string (nullable = true)
|-- author: string (nullable = true)
|-- year: integer (nullable = true)
|-- publisher: string (nullable = true)
+------+------+---------+--------------------+------------+----+--------------------+
|userId|rating| isbn| title| author|year| publisher|
+------+------+---------+--------------------+------------+----+--------------------+
|277378| 0|971880107| Wild Animus|Rich Shapero|2004| Too Far|
|277157| 0|971880107| Wild Animus|Rich Shapero|2004| Too Far|
|277042| 2|971880107| Wild Animus|Rich Shapero|2004| Too Far|
|276954| 0|971880107| Wild Animus|Rich Shapero|2004| Too Far|
|276939| 0|971880107| Wild Animus|Rich Shapero|2004| Too Far|
|276925| 0|971880107| Wild Animus|Rich Shapero|2004| Too Far|
|277195| 0|375406328| Lying Awake|Mark Salzman|2000| Alfred A. Knopf|
|276953| 10|446310786|To Kill a Mocking...| Harper Lee|1988|Little Brown & Co...|
|277168| 0|440225701| The Street Lawyer|JOHN GRISHAM|1999| Dell|
|276925| 0|804106304| The Joy Luck Club| Amy Tan|1994|Prentice Hall (K-12)|
+------+------+---------+--------------------+------------+----+--------------------+
*/
// do some filtering for test
jdf.filter(col("userId") ==="277378")
.limit(5)
.show()
/*
output
+------+------+---------+--------------------+--------------+----+------------+
|userId|rating| isbn| title| author|year| publisher|
+------+------+---------+--------------------+--------------+----+------------+
|277378| 0|971880107| Wild Animus| Rich Shapero|2004| Too Far|
|277378| 7|312195516|The Red Tent (Bes...| Anita Diamant|1998| Picador USA|
|277378| 7|670892963|Bridget Jones : T...|Helen Fielding|2000|Viking Books|
|277378| 0|671028375| Fatal Voyage| Kathy Reichs|2002| Pocket|
|277378| 0|670894494|The Passion of Ar...|Susan Vreeland|2002|Viking Books|
+------+------+---------+--------------------+--------------+----+------------+
*/
构建模型
我使用交替最小二乘(ALS)协同过滤算法来构建推荐模型。ALS 是一种非常流行的推荐算法。Apache Spark-ML 库提供的 ALS 算法实现。ALS 算法使用以下训练参数。
- userCol - 用户 ID 的列名。Id 必须是(或可以被强制转换为)整数。
- itemCol - 产品ID的列名。Id 必须是(或可以被强制转换为)整数
- ratingCol - 产品评分的列名。。
- maxIter - 最大迭代次数 (>= 0)。
- regParam - ALS 中的正则化参数,默认为 1.0 (>= 0)。
- iterations - 要运行的迭代次数。
- ColdStartStrategy - 当运行预测并且没有为特定用户/评分训练模型或未为用户找到项目时,如果给定“drop”作为参数值,它将删除这些用户。
// build recommendation model with als algorithm
valals=newALS()
.setMaxIter(5)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("isbn")
.setRatingCol("rating")
valalsModel=als.fit(trainingData)
// evaluate the als model
// compute root mean square error(rmse) with test data for evaluation
// set cold start strategy to 'drop' to ensure we don't get NaN evaluation metrics
alsModel.setColdStartStrategy("drop")
valpredictions=alsModel.transform(testData)
valevaluator=newRegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
valrmse=evaluator.evaluate(predictions)
println(s"root mean square error $rmse")
/*
output
root mean square error 5.44073307705168
*/
预测推荐
一旦构建了 ALS 模型并对其进行了训练,我们就可以使用它来进行用户和商品的推荐。以下是我为用户和书籍所做的各种建议。
// top 10 book recommendations for each user
valallUserRec=alsModel.recommendForAllUsers(10)
allUserRec.printSchema()
allUserRec.show(10)
/*
output
root
|-- userId: integer (nullable = false)
|-- recommendations: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- isbn: integer (nullable = true)
| | |-- rating: float (nullable = true)
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 496|[[373244630, 0.0]...|
| 1238|[[373244630, 0.0]...|
| 2366|[[689831390, 20.6...|
| 3918|[[373244630, 0.0]...|
| 4900|[[689841981, 37.4...|
| 6336|[[142003069, 26.6...|
| 6357|[[1714600, 0.0], ...|
| 6397|[[345368924, 17.4...|
| 6466|[[873529758, 19.0...|
| 7253|[[736413057, 12.9...|
+------+--------------------+
*/
// top 10 user recommendations for each book
valallBookRec=alsModel.recommendForAllItems(10)
allBookRec.printSchema()
allBookRec.show(10)
/*
output
root
|-- isbn: integer (nullable = false)
|-- recommendations: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- userId: integer (nullable = true)
| | |-- rating: float (nullable = true)
+--------+--------------------+
| isbn| recommendations|
+--------+--------------------+
| 2250810|[[263979, 44.0867...|
| 2740958|[[177870, 0.0], [...|
| 3701387|[[202919, 116.593...|
|20427115|[[263979, 135.824...|
|23417706|[[177870, 0.0], [...|
|27780260|[[10, 0.0], [20, ...|
|28604458|[[106208, 75.9024...|
|28616340|[[253797, 41.2638...|
|28639693|[[41111, 60.72071...|
|28644417|[[10, 0.0], [20, ...|
+--------+--------------------+
*/
// top 10 book recommendations for specific set of users(3 users)
valuserRec=alsModel.recommendForUserSubset(jdf.select("userId").distinct().limit(3), 10)
userRec.printSchema()
userRec.show(10)
/*
output
root
|-- userId: integer (nullable = false)
|-- recommendations: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- isbn: integer (nullable = true)
| | |-- rating: float (nullable = true)
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 496|[[1714600, 0.0], ...|
+------+--------------------+
*/
// top 10 user recommendations for specific set of books(3 books)
valbookRec=alsModel.recommendForItemSubset(jdf.select("isbn").distinct().limit(3), 10)
bookRec.printSchema()
bookRec.show(10)
/*
output
root
|-- isbn: integer (nullable = false)
|-- recommendations: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- userId: integer (nullable = true)
| | |-- rating: float (nullable = true)
+---------+--------------------+
| isbn| recommendations|
+---------+--------------------+
|440226430|[[263979, 28.0991...|
|385314744|[[114434, 81.7188...|
|872860175|[[226926, 116.011...|
+---------+--------------------+
*/
// top 10 book recommendations for user 277378
valudf=jdf.select("userId").filter(col("userId") ===277378).limit(1)
valuserRec277378=alsModel.recommendForUserSubset(udf, 10)
userRec277378.printSchema()
userRec277378.show(10)
/*
output
root
|-- userId: integer (nullable = false)
|-- recommendations: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- isbn: integer (nullable = true)
| | |-- rating: float (nullable = true)
+------+--------------------+
|userId| recommendations|
+------+--------------------+
|277378|[[1563526514, 47....|
+------+--------------------+
*/