

本文总计 2000 字,预计阅读需要 5-8 分钟
Spark SQL 是 Apache spark 中最重要的组件,在处理 SQL和DataFrame API的时候都会用到它,Spark SQL的核心是Catalyst优化器。
与Oraclel类似,Catalyst 优化器支持基于规则(RBO)和基于成本(CBO)的两种方式优化。RBO的最大的问题在于它是靠硬编码在Spark代码中的一系列规定的规则来决定目标SQL的执行计划的并没有考虑目标SQL中所涉及的对象的数据量和实际数据分布情况,这样一旦规定规则并不适用于执行SQL中所涉及的实际对象时,RBO根据规定规则产生的执行计划就很可能不是当前情况下的最优执行计划了。
而CBO则恰恰相反,它会根据目标SQL的相关的对象的实际数据量,实际数据分布情况的统计信息来决定其执行计划,CBO是随着目标SQL中所涉及的对象的统计信息的变化而变化的。理论上来说统计信息相对准确,则用CBO来解析目标SQL会比同等条件下的RBO来解析得到正确执行计划的要高。
Catalyst优化器
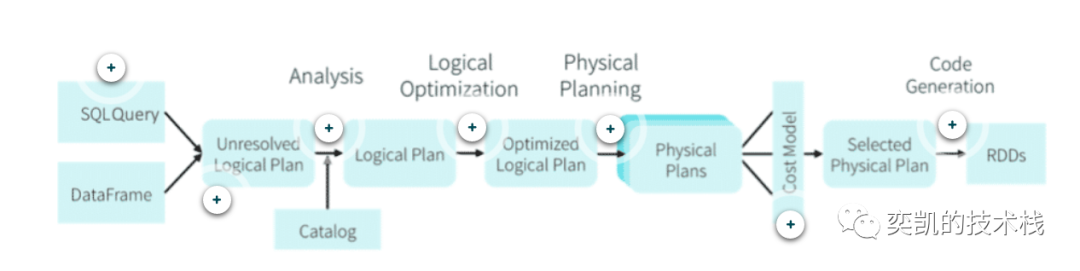
未解析的逻辑计划 Unresolved Logical Plan
Spark SQL在执行一条SQL语句时,首先会将SQL语句解析成Unresolved Logical Plan。之所以被称为未解析,是因为此阶段不会解析所有实体(例如列名)。
在Unresolved logical plan树的绑定、解析、优化过程中,主要方法都是基于规则的,通过scala语言模式匹配机制进行树的转换或节点改写。Rule是一个抽象类,子类需要重写apply方法来定制特定的处理逻辑。
abstractclass Rule[TreeType <: TreeNode[_]] extends Logging
有了各种具体的规则以后,Catalyst中由RuleExecutor来调用这些规则。RuleExecutor内部提供了一个Seq[Batch],里面定义的是该RuleExecutor处理的规则,每个Rule都是顺序执行。
例如下面语句
scala> var df = spark.read.option("header",true).csv("/user/test/olympic-summary/Summer-Olympic-medals-1976-to-2008.csv").orderBy("Year").filter(col("Country")==="East Germany").count()
Unresolved Logical Plan如下所示
Aggregate [count(1) AS count#1197L]+- AnalysisBarrier +- Filter (Country#1169 = East Germany) +- Sort [Year#1162 ASC NULLS FIRST], true +- Relation[City#1161,Year#1162,Sport#1163,Discipline#1164,Event#1165,Athlete#1166,Gender#1167,Country_Code#1168,Country#1169,Event_gender#1170,Medal#1171] csv
我们可以看到它类似于我们自己的查询,读取csv文件,按年份排序并过滤详细信息。
逻辑计划 Logical Plan
在执行的逻辑计划时主要就是获取操作表的元数据信息,校对所引用的表名或者列名。unresolved logical plan 通过了验证,这时就被称之为 已解析的逻辑计划(resolved logical plan) 。
count: bigintAggregate [count(1) AS count#1197L]+- Filter (Country#1169 = East Germany) +- Sort [Year#1162 ASC NULLS FIRST], true +- Relation[City#1161,Year#1162,Sport#1163,Discipline#1164,Event#1165,Athlete#1166,Gender#1167,Country_Code#1168,Country#1169,Event_gender#1170,Medal#1171] csv
最优逻辑计划 Optimized Logical plan
在这个阶段,已解析的逻辑计划(resolved logical plan) 它会传递到 Catalyst Optimizer 优化器,然后被经过一些列优化生成最优逻辑计划(Optimized logical plan),在这里实际查询计划将被重新排序。
Aggregate [count(1) AS count#1197L]+- Project +- Sort [Year#1162 ASC NULLS FIRST], true +- Project [Year#1162] +- Filter (isnotnull(Country#1169) && (Country#1169 = East Germany)) +- Relation[City#1161,Year#1162,Sport#1163,Discipline#1164,Event#1165,Athlete#1166,Gender#1167,Country_Code#1168,Country#1169,Event_gender#1170,Medal#1171] csv
我们可以看到计划进行了重新排序,在Filter执行后才执行Sort。
Physical plan 物理计划
这是优化的最后一步。根据查询生成一个或多个物理计划。每个物理计划都根据成本模型进行评估,从中选择最佳模型。实际上,物理执行计划可以看做是一系列的RDD转换操作。这就是为什么我们可以经常听到有人将Spark被比作编译器 —— Spark可以替我们将DataFrame、Dataset和SQL中的查询编译成一些列的RDD转换过程。
DAG 分析
spark基于执行计划创建了一个有向无环图(DAG),现在让我们看看分析一个简单的DAG(计数)示例和一个join 示例中的步骤和阶段。
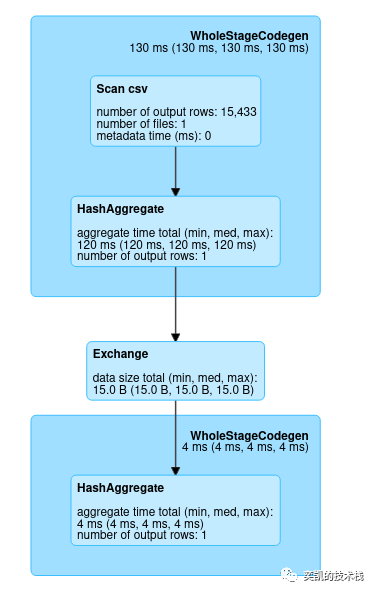
Wholestagecodegen是生成实际代码以供执行的过程。
var df = spark.read.option("header",true).csv("/user/test/olympic-summary/Summer-Olympic-medals-1976-to-2008.csv")df.queryExecution.debug.codegen
上述查询可用于查看生成的读取 csv 文件的代码。
HashAggregate:Scala 有一个 Aggutils 对象,其中定义了所有聚合方法。在调用所有聚合方法(如 min、max、count 等)时调用这些方法。
planAggregateWithOneDistinct( groupingExpressions: Seq[NamedExpression], functionsWithDistinct: Seq[AggregateExpression], functionsWithoutDistinct: Seq[AggregateExpression], resultExpressions: Seq[NamedExpression], child: SparkPlan): Seq[SparkPlan]
planAggregateWithOneDistinct 方法在调用排序时使用。
数据交换
spark中的交换是数据在不同节点之间传输的过程。spark中的交换大致可以分为两种
- Broadcast :在不同节点之间广播较小数据集的过程。
- Shuffle:不同节点间的数据传输
现在让我们详细看看这俩问题
Broadcast exchange
val t1=spark.range(10)val t2=spark.range(10)val t3=t1.join(broadcast(t2)).where(t1("id")===t2("id"))
t2 被广播到不同的executers,Broadcast 将比 shuffle 更有效率。在 spark 中,只能广播小于 8 GB 的数据集。
scala> t3.explain()== Physical Plan ==*(2) BroadcastHashJoin [id#1363L], [id#1365L], Inner, BuildRight:- *(2) Range (0, 10, step=1, splits=8)+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false])) +- *(1) Range (0, 10, step=1, splits=8)
Shuffle Exchanges
将数据划分为不同spark分区的repartition 方法就是shuffle的一个例子。
val q1=spark.range(5).repartition(5)scala> q1.explain()== Physical Plan ==Exchange RoundRobinPartitioning(5)+- *(1) Range (0, 5, step=1, splits=8)
shuffle的本质并不是跨节点/跨进程,本质其实是任务协调的一种实现,所以我们看到了一个完全不同的物理执行计划。
代码生成
查询优化的最后阶段涉及生成Java字节码用于在每台机器上运行。代码生成引擎的构建通常很复杂,特别是编译器。Catalyst依靠Scala语言的特殊功能quasiquotes来简化代码生成,具体可以查看这篇论文
http://people.csail.mit.edu/matei/papers/2015/sigmod_spark_sql.pdf