
有时候我们并不想使用
Transformers
来训练别人的预训练模型,而是想用来训练自己的模型,并且不想写训练过程代码。这时,我们可以按照一定的要求定义数据集和模型,就可以使用
Trainer
类来直接训练和评估模型,不需要写那些训练步骤了。
使用
Trainer
类训练自己模型步骤如下,以网络退化现象和残差网络效果中的残差模型为例:
导入必要库
import torch
from torch import nn
from datasets import Dataset
from transformers import Trainer, TrainingArguments
# 驱动选择
device ="cuda"if torch.cuda.is_available()else"cpu"
准备数据
X = torch.zeros((26,26), dtype=torch.float32).to(device=device)
labels =[]for i inrange(26):
labels.append((i+1)%26)
X[i][i]=1.
labels = torch.tensor(labels)
dataset = Dataset.from_dict({'x':X,'labels':labels})
- 注意
Trainer训练时,会将dataset中的数据按照对应的键值传入,因此需要在自己模型的forward方法中接收键值变量。如上例,需要将方法写为:forward(self, x, labels)
构建网络
# 残差网络classRN(nn.Module):def__init__(self):super(RN, self).__init__()
self.linear_stack = nn.Sequential(
nn.Linear(26,64),
nn.Hardsigmoid(),
nn.Linear(64,26),
nn.Hardsigmoid(),)
self.linear_stack_2 = nn.Sequential(
nn.Linear(26,64),
nn.Hardsigmoid(),
nn.Linear(64,64),
nn.Hardsigmoid(),)
self.output_layer = nn.Linear(64,26)
self.loss_f = nn.CrossEntropyLoss()defforward(self, x, labels, mode='train'):
y = self.linear_stack(x)# 残差
y = y+x
y = self.linear_stack_2(y)
y = self.output_layer(y)if mode is'train':return{'loss':self.loss_f(y, labels),'predictions':y
}return y
网络与之前完全一致,只是改了下前向传播方法,这里的
mode=’train’
是为了后续自己使用模型加的,也可以不要。
创建Trainer类
# 生成模型实例
model = RN().to(device=device)defcompute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
acc =(labels == preds).sum()/len(labels)return{'accuracy': acc,}
training_args = TrainingArguments(
output_dir='./results',# output directory 结果输出地址
num_train_epochs=1000,# total # of training epochs 训练总批次
per_device_train_batch_size=1,# batch size per device during training 训练批大小
per_device_eval_batch_size=1,# batch size for evaluation 评估批大小
logging_dir='./logs/rn_log',# directory for storing logs 日志存储位置
learning_rate=1e-3,# 学习率
save_steps=False,# 不保存检查点)
trainer = Trainer(
model=model,# the instantiated 🤗 Transformers model to be trained 需要训练的模型
args=training_args,# training arguments, defined above 训练参数
train_dataset=dataset,# training dataset 训练集
eval_dataset=dataset,# evaluation dataset 测试集
compute_metrics=compute_metrics # 计算指标方法)
trainer.train()
trainer.evaluate()
训练过程:
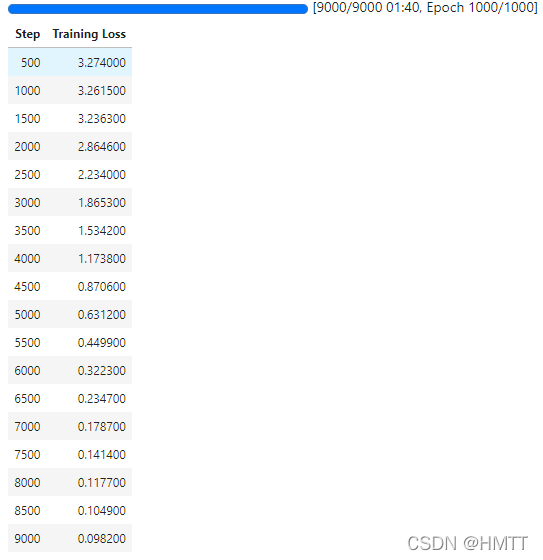
评估结果:
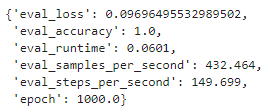
保存模型
trainer.save_model()
加载并使用模型
checkpoint = torch.load('./results/pytorch_model.bin')
model = RN().to(device)
model.load_state_dict(checkpoint)
model(X.to(device), torch.tensor(labels).to(device))['predictions'].argmax(1)

本文转载自: https://blog.csdn.net/qq_42464569/article/details/123990005
版权归原作者 HMTT 所有, 如有侵权,请联系我们删除。
版权归原作者 HMTT 所有, 如有侵权,请联系我们删除。