
可解释人工智能作业
一. 选择题(每道题5分,单选与多选混杂)
1.关于可解释AI的英文术语,相较于术语Explanation,下面哪一条描述不符合术语Interpretation特性? D
A. 理解模型的运行机理
B. 对模型决策过程的建模
C. 具有高度人类可理解度
D. 研究模型决策的因果效应
- 基于归因算法的可解释,下面哪个选项不是常用的评价指标?B
A. Faithfulness
B. Accuracy
C. Sensitivity
D. Understandability
- 以下哪个选项不是基于概念的可解释方法? B D
A. TCAV
B. HINT
C. Concept Bottleneck Model
D. Grad-CAM
- 本课程介绍的方法中,以下哪个选项不是Post-Hoc可解释?A
A. Bayesian Deep Learning
B. HSIC-Attribution
C. HINT
D. Less is More
- 请先阅读因果图模型,然后回答以下哪一组变量在给定观察时,变量X与Y相互独立? A
A. {U, Z, T}
B. {W}
C. {W, U, Z}
D. {T,U}
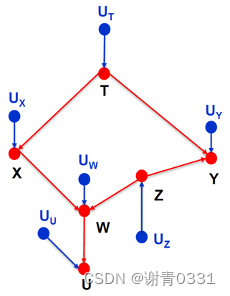
- 你认为下图的方法是?B
A. Ante-Hoc方法
B. Post-Hoc方法
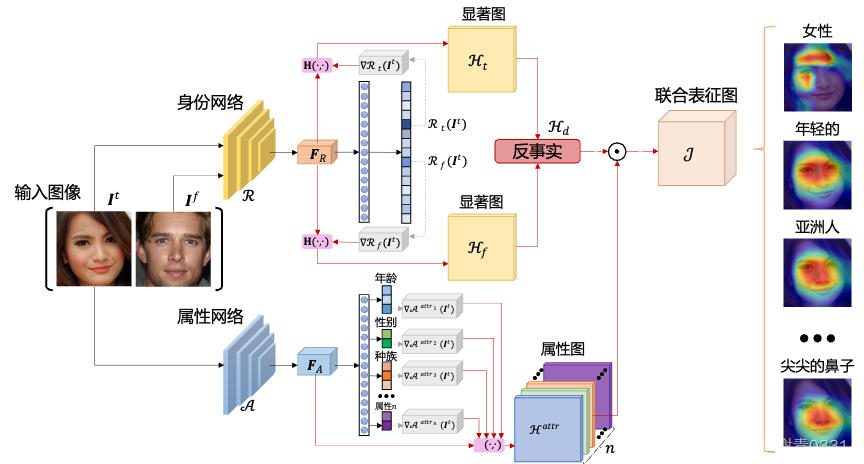
7.下面哪一条不属于传统可解释方法在多模态编码式基础模型应用的缺陷:
A. 没有考虑到人类可理解的语言模态
B. 没有考虑到历史对话信息
C. 处理多模态方法上存在缺陷
D. 没有利用LLM的context learning的特性
选择题:
- D
- B
- B D
- A
- A
- B
- D
二. 简述题
- 简述1)什么是Ante-Hoc的可解释方法,2)有什么特性。(15分,第1个9分,第2个6分)
答:
1)
Ante-Hoc的可解释方法指的是在模型训练的过程中内置可解释性,即在设计模型的阶段就考虑到如何使模型的决策过程透明和可解释。这与Post-Hoc的可解释方法相对,后者是在模型训练完成后,再采取措施来解释模型的行为。
例如,决策树就是一种典型的Ante-Hoc模型,因为它通过树结构来直观地展示决策过程。其他如线性模型、贝叶斯模型也属于这一类,因为它们的数学结构简单、直观。
2)
透明性:Ante-Hoc方法通常更透明,因为可解释性是模型设计的一部分。模型的每个部分和每个决策都可以直接解释和理解。
简洁性:这些方法往往侧重于更简洁的模型结构,以便于理解和解释。例如,线性模型就是通过权重和特征的线性组合来做出预测,每个权重的作用都非常清晰。
泛化性:由于模型结构通常比较简单,这类方法在泛化到未见数据时往往更稳定。
约束性:为了保持可解释性,这些模型可能牺牲一些性能,尤其是在处理复杂数据或任务时。例如,它们可能无法捕捉数据中的所有复杂模式和关系。
- 评价图像归因方法的Faithfulness,评价指标包括Insertion AUC,Deletion AUC和MuFidelity,请分别简述这些方法计算过程。(15分,每个指标5分)
答:
Insertion AUC是通过逐步插入对模型决策影响最大的区域来计算的。首先,将图像的所有像素或区域根据它们对模型输出影响的重要性进行排序。然后,从一个基线(通常是一个黑色或平均值图像)开始,逐步插入最重要的像素或区域,每次插入后都重新评估模型的输出。这个过程生成了一个性能曲线,衡量的是随着更多相关区域的加入,模型输出的正确性如何变化。Insertion AUC是这条曲线下的面积,较大的AUC表示归因方法能够有效识别对模型决策影响大的区域。
Deletion AUC与Insertion AUC相反,是通过逐步删除对模型决策影响最大的区域来计算的。同样先对所有像素或区域进行排序,然后从完整的图像开始,逐步删除最重要的像素或区域,每次删除后都重新评估模型的输出。这个过程生成的性能曲线反映了随着重要区域的移除,模型性能如何下降。Deletion AUC是这条曲线下的面积,较小的AUC表示归因方法有效地识别了对模型决策最关键的区域,因为移除这些区域导致性能显著下降。
MuFidelity是衡量归因方法的保真度的指标。它通过比较模型在原始输入和修改后输入上的输出差异来计算。首先,根据归因方法确定的重要性对像素或区域进行排序,然后修改这些重要区域(如遮盖或插值),生成一系列修改后的图像。对于每个修改后的图像,计算模型输出的变化(如概率或置信度的变化)。MuFidelity是这些变化的平均值,反映了归因给出的重要区域对模型输出的实际影响。较高的MuFidelity表示归因方法能准确识别影响模型决策的区域。
- 请简述因果推断中,什么是反事实?它在图像归因任务中可以解释什么?(15分)
答:
反事实(Counterfactual)是指在某种情况下未发生但在另一种情况下可能发生的事件或结果。它基于这样的假设:“如果不是X发生,而是Y发生,结果会怎样?” 这里的X是实际发生的事实,Y是想象中的替代事件。反事实用于探讨和理解事件的因果关系,通过比较实际发生的事实和假想的替代情况来评估特定因素对结果的影响。
反事实可以帮助解释:
对模型决策的影响:通过构建图像的反事实版本,例如改变图像中某个对象的颜色或形状,可以观察这些变化如何影响模型的判断。这样可以理解特定特征或区域对模型决策的贡献程度。
模型的敏感度和健壮性:通过应用微小的扰动(如遮挡或添加噪声)来创建反事实图像,可以测试模型对于这些变化的敏感性。这有助于评估模型的健壮性和可靠性,即模型是否容易因为无关紧要的变化而改变其判断。
潜在的偏见和不公平:反事实分析可以用来揭示模型可能存在的偏见。例如,通过系统地修改图像中人物的种族或性别属性,并观察模型行为的变化,可以检测和理解模型在这些维度上的潜在偏见。
因果关系的解释:反事实分析使研究者能够超越相关性,探索潜在的因果关系。例如,通过观察去除或添加特定图像区域(如物体或背景)对分类决策的影响,可以更深入地理解哪些元素是导致特定决策的真正原因。
- 你觉得可解释性人工智能有什么重要性?未来有哪些insighting的研究方向?并阐述相关理由。(20分)
答:
重要性:
任和接受度:用户和决策者更可能信任并接受他们能理解和验证的系统。当人们理解AI如何作出决策时,他们更容易信任这些决策,尤其是在医疗、金融和法律等关键领域。
安全和可靠性:可解释的模型使开发者能够识别和纠正错误或偏见,从而构建更安全、可靠的系统。这对于防止错误决策和不公平非常关键,尤其是当这些决策可能对人们的生活产生重大影响时。
遵守法规和标准:随着越来越多关于数据和算法使用的法规(如欧盟的通用数据保护条例GDPR)的实施,可解释性成为遵守法律要求的一个关键方面。这些法规通常要求算法的决策是可以解释和验证的。
促进创新和改进:通过理解模型的工作原理和决策过程,研究人员和开发者可以更有效地诊断问题、提出改进措施,并创新新的模型和技术。
研究方向:
因果推断和反事实解释:超越相关性,深入理解因果关系。研究如何通过模拟干预和生成反事实来揭示数据和模型决策之间的真正因果关系。
可解释性与性能的平衡:开发新的算法和技术,在保持高性能的同时提高模型的可解释性。探索如何设计既能捕捉复杂数据模式也易于理解和解释的模型。
个性化解释:提供针对不同用户(如专家与非专家)的定制化解释,使所有用户都能根据自己的背景和需求理解AI决策。这包括开发交互式和用户友好的解释工具。
评估和改进解释的质量:研究如何量化和评估解释的有效性、准确性和用户满意度。同时,探索如何利用用户反馈来改进解释的质量和相关性。
解释性在特定领域的应用:深入探索可解释性在医疗、金融、法律等特定领域的应用,解决这些领域独特的挑战和需求。
版权归原作者 谢青0331 所有, 如有侵权,请联系我们删除。