
(希望不要等到人类彻底被AI和资本统治以后,人们才看到这篇文章)
前言
「模型是被貌似严谨的数学公式层层包裹着的主观观点。
模型不会创造,它只会机械的根据历史,要么**落井下石,要么锦上添花。
人类和机器最大的区别就是,人类会反观内省,人类懂得谦虚,知道自己认知的局限,而机器不会,机器永远理直气壮、永远一本正经、永远自我巩固、破坏力极强...
模型不会倾听,也不会屈服,。。。如果系统明显出错,人们多半会从自己身上找原因,而不会责怪算法和数据。
算法就像上帝,数学毁灭武器的裁决就是他的指令。
最优秀的猎人,往往都是以猎物的形式出现。人类在使用互联网的同时也被互联网所塑造和操控。
如果我们任由大模型统治人类,那么历史上贫穷的人将一直贫穷,而富人更加富裕,因没有工作经验而找不到工作的应届生将一直找不到工作,曾经得不到机会的人将更难得到机会,已经享有特权的人将享有更多的特权还迫切的对外宣称这个世界的底层规则就是优胜劣汰,他自己就是比别人优秀,他自己就是值得拥有这一切……更糟糕的是,由于整个黑暗的大模型隐藏在遥远的服务器集群里,在大模型霸权之下的受害者根本毫无知晓,无权抱怨,更不用说纠正系统的错误了。他们几乎不可能弄清,那庞杂的数学公式下到底蕴藏了什么规则。他们大多数人可能会理所当然的得出结论:“社会就是不公平的。”」
正文
可解释人工智能
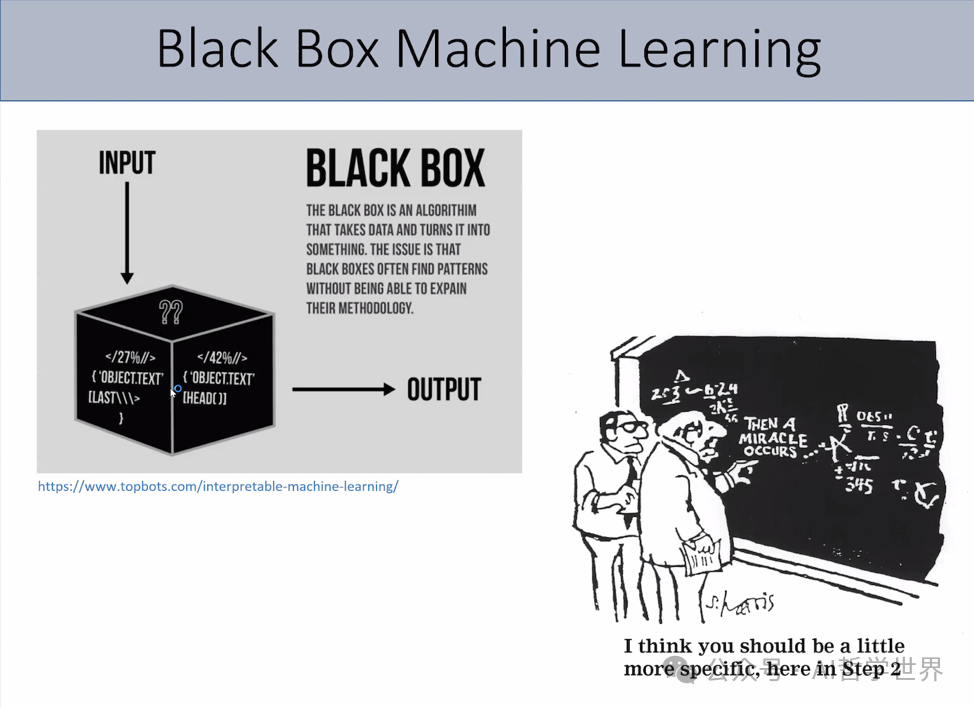
机器学习模型是一个黑盒,它们无法解释自己所做出来的决定。而且,机器学习研究者都知道,机器学习模型非常的脆弱,输入数据集轻微的扰动,都有可能导致模型准确率急剧震荡,而且,无法给出任何理由。

几年前美国一所著名高校成功用深度学习识别出了图片中的哈士奇和狼,准确率高达98%,在当时还引起了主流媒体的争相报导。然而,在可解释人工智能方法出来以后,人们用可解释方法解释了一下,发现模型根本没有去学习狼和哈士奇的区别,而是只是去识别了雪。机器学习到的规则是,只要照片里有雪,就是狼,否则,就是哈士奇。

可解释 !****= 可信
现在绝大多数可解释方法,都是基于近似、拟合的思想,大概的猜测出模型做出相应决策的原因。这种解释方法不具备时空稳定性,哪怕对于同一个例子,每次运行计算出的解释可能不一样。用这种解释方法来解释图像识别是完全可以满足需求的,但是对于涉及到国计民生的安全领域,则需要绝对精准、语义无歧义的解释。比如网络入侵检测等领域,依靠二进制字符串来匹配模式,哪怕一个字节的偏差,都会导致语义完全不一样,所以我们需要用形式化方法进行的绝对精准的可解释机器学习。而这样的可解释的人工智能才是真的是可信的人工智能。
严谨的可解释人工智能
形式化可解释方法在手写数字识别应用的一个例子如下图所示,经过形式化的可解释方法,得知模型之所以把第一行左边的图片识别为1,根因是因为它在中间的图中这三块黑色的区域是黑色,在这两个白色的点为白色,而其他区域的点,是什么值都无所谓,模型都一定会把它识别为1。因此我们就知道,像第一行右边这个图,不管在我们人类看来是多么明显的一个0,但是不用测试就知道,机器一定会把它识别为1。

from Adnan Darwiche, UCLA
下面用本人在形式化可解释人工智能的工作做为例子,大概可以分为两部分,一部分是解释决策树以及相衍生的树类模型,另一部分是解释神经网络模型,并且在网络入侵检测领域进行验证。简单来说就是将模型看作芯片,用形式化方法表示成逻辑表达式,然后再用逻辑推理进行化简,直至最本质的蕴含项,即prime implicant,这就是这个模型做决策的根因。
可解释方法可以提供全局解释,也可以提供局部解释。在一个决策树进行Zero-Day 入侵检测的模型中,提炼出模型的本质一共40多条规则(这里只展示了一部分),也就是说,只要符合这里的任意一条条件,就会被判定为正常流量,而不符合的,就是异常流量。

*Q. Zhou, R. Li, L. Xu, A. Nallanathan, J. Yang, A. Fu, “Towards Interpretable Machine-Learning-Based DDoS Detection”, Springer Nature Compt. Sci., vol.5, no.115, 2024. *
这里给出5条局部解释的例子,比如第一个,网络流量经过建模,表达成一个很长的字符串,但是真正决定它被判定为正常流量的只有标红的这5个字符,也就是说,其他的字符可以随意变,但是不会更改模型对它的判定。因为它符合模型的第41条根因。其他的例子类似,不管网络流转化成字符串有多长,决定它被判定为正常与否的只有标红的几个字节,也就是模型的全局解释。

Q. Zhou, R. Li, L. Xu, A. Nallanathan, J. Yang, A. Fu, “Towards Interpretable Machine-Learning-Based DDoS Detection”, Springer Nature Compt. Sci., vol.5, no.115, 2024.
本人工作的第二部分,是解释神经网络。虽然神经网络非常复杂,但是基本思路都一样,都是将这个模型黑盒看作一个芯片,然后把里面的逻辑表达成形式化的逻辑表达式,然后用类似于硬件电路形式化验证的方法,把表达式简化至本质蕴含项,也就是这个模型的根因。
本人提出了一个heuristic 算法,可以将NP-hard 的问题简化为平均情况下O(1)的复杂度。算法比较复杂,就不在这里细说了,直接看结果。这里是拿网络zero-day入侵检测作为应用场景,解释后的根因如下图所示,平均解释速率是0.0001秒/条。



解释了这么多模型,大家有什么感想呢。
我的第一感觉是:
机器只对数字敏感,它不懂语义。
比如从上面这些解释可以看出,语义对它来说没有意义,机器只关心特征值的大小,永远只会机械的进行数学计算,几个语义完全不相干的变量,对于机器来说可以是等价的。当然,我们可以通过数学建模,把一个概念和它的属性和前因后果联结起来,让机器看起来好像能读懂语义,但是这也只是貌似,并不是真的。
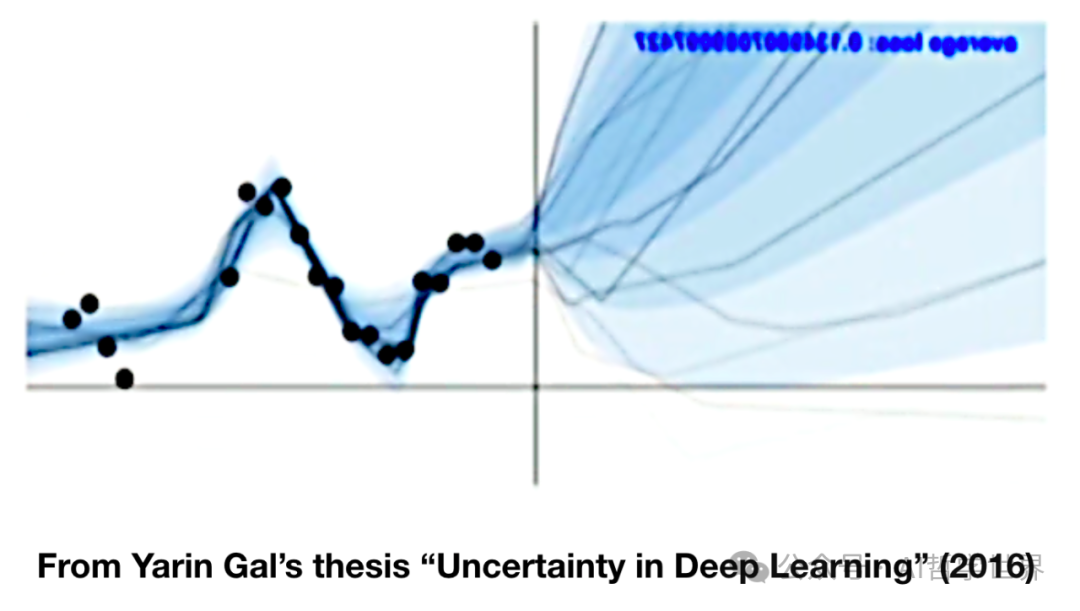
另外一个感想就是:模型的本质是用过去预测未来,其基本假设是:模式会重复。明天和过去一样。。。
可是,虽然历史是死的,但是人是活的啊,未来是人在道德的指引下用想象力创造出来的,因此未来充满了无数种可能。
现在几乎所有的主流媒体都在赞美AI大模型给人类带来更多科技、公平、和民主。数据,确实不会撒谎的,因为它没有价值观;数学,也确实是严谨的,因为它是基于逻辑推理,但是模型是主观的。
让我们想想建模的过程:很多模型建立的依据仅仅是建模者凭直觉想象什么是对该领域而言最重要的因素,然后,这些人便去寻找可以测量的相关变量,最后随意的在公式里赋予每个变量一定的权重(这些权重的取值并没有严谨的科学依据),这样一个模型就完成了...… 模型是一种被严谨的数学公式层层包裹着的主观观点,它反映的依然只是建模者的世界观价值观,建模的过程存在着许多主观带来的偏见、错误的、甚至有毒的假设。。。
无论什么模型,错误总会出现,因为模型的本质就是简化。没有模型能够囊括现实世界所有复杂因素或者考虑到人类交流上的所有细微差别。总有些信息是会不可避免的被遗漏的。但是现在,这些不完善模型包裹着数学精准严谨的外衣,流行于市场,未经检验便投入使用,而人类对此却毫无争议。
更可怕的是,大模型操作者不会思考那些错误。模型的训练者在主流舆论、和资本利益的驱使下,产生一种盲目的安全感,忽视模型的潜在风险,导致不完善的模型被广泛利用。与此同时,任何反对大模型的声音都被视为跟不上科技发展前沿的落后分子。
放眼全球,到今天为止,真正操纵市场的依然是资本,哪怕是学术界、高科技公司,也都是被资本驱动和操控去选择研究方向的,而那些站在金融领域金字塔尖的操纵者,他们的动机是金钱,这也是他们唯一的反馈。在金融领域「拒绝承认风险的存在」已经司空见惯、根深蒂固了。他们设计大模型就是为了吸收更多的数据、微调分析、让更多的投资涌入。投资者得到利润以后,继续将更多的钱投入到数学模型公司。金钱的回馈激增了这些大模型操纵者的自信,让他们相信自己做的是正确的事,走在正确的道路上。数学,被当成唬人的工具,而不是澄清事实的依据。****公式,披着以造福广大人类的外衣,其实质则是为了最大化极少数人的短期利润。

在真正的科学研究中,科学家需要错误反馈来做取证分析,查明系统哪儿出错了,哪些变量被误读了,什么数据被忽视了,而系统在此过程中得以学习并进化。
没有测量,就没有科研。
“一个问题是科研问题的标志,就是它存在一个领域公认的、可量化的衡量指标。”
可是迄今为止,机器学习所有的衡量指标,都是衡量某个数据集的。
不存在脱离数据集,单纯描述模型本身的指标。
可是,充斥人类社会的大模型的决策会被审查吗?模型的决策根因是透明的吗,是可信吗?模型的决策,是公平的吗?机器是不可能自动认识到自己犯了错的,但是,对于真正操控市场的唯金钱至上的资本来说,「模型的错误决定」这一数据不在系统的收集范围之内,大模型受害者的遭遇只不过是附带性损失,是marginal loss,为了利益而容忍一些错误,这在资本来说是司空见惯的。因此系统根本不知道自己做了多少错误的决定。越来越强大的算力,越来越庞大的模型,不过是在打造并巩固它们自己定义的现实。迄今为止,大模型的“科学性”只不过是一些未被证实的假设罢了。但这依靠伪科学而建立的权威,风行至今,甚嚣尘上。
深度伪造和社交机器人

如今,随着换脸、虚假音视频制作等深度伪造技术的兴起,随着大模型的开源,任何人都可以利用这些大模型, 自动批量生产和扩散高度复杂的言论,高效地生成以假乱真的合成音视频。这使得公众区分真实和虚假信息的难度越来越大。
不知道大家有没有听说过社交机器人,它是指在互联网,尤其是社交网络平台,为实现特定目的,自主运营、自动发布生成内容,并模仿人类活动的AI程序。它们不仅可以在5分钟内生产和发布一万条不同的原创信息,并同时进行大规模的转发与点赞,而且还可以和人类用户进行交互,真假难辨。近年来,社交机器人已逐步成为互联网舆论场的主角。据网络安全机构 Imperva 统计,仅在2022 年,整个互联网的流量中,社交机器人贡献了 47.4%的数据,也就是说,在现在这个时间,至少一半的互联网信息都不是来自人类。
这类虚拟网民已渗透到各个领域,对人类的思想产生不可忽视的影响。而且就目前来看,这种影响基本都是负面的。一方面社交机器人为电影电视刷分、在购物平台刷单、营造虚假人气、或者传播虚假或片面信息干扰舆论,使得互联网充斥大量无关、虚假、低俗的信息,弱化社交媒体原本自身定位,污染、干扰网民视线,拉低网民的心灵品质; 另一方面,过于精准制导、个性化定制的内容,会形成信息茧房;更过分的是,甚至有的社交机器人会根据大数据算法为用户量身定制负面或蛊惑的言论,造成情感创伤,深陷负能量的漩涡。

辟谣的成本是造谣的一万倍。
当一杯清水里被滴入一滴毒液,得需要多少倍的清水来稀释,才能还回这一杯水的清净呢。当人们的精神世界被机械的言论所伤害,这个责任又该由谁来承担呢?
最优秀的猎人,往往都是以猎物的形式出现。人类在使用互联网的同时也被互联网所塑造和操控。
算法霸权---数学大规模杀伤性武器

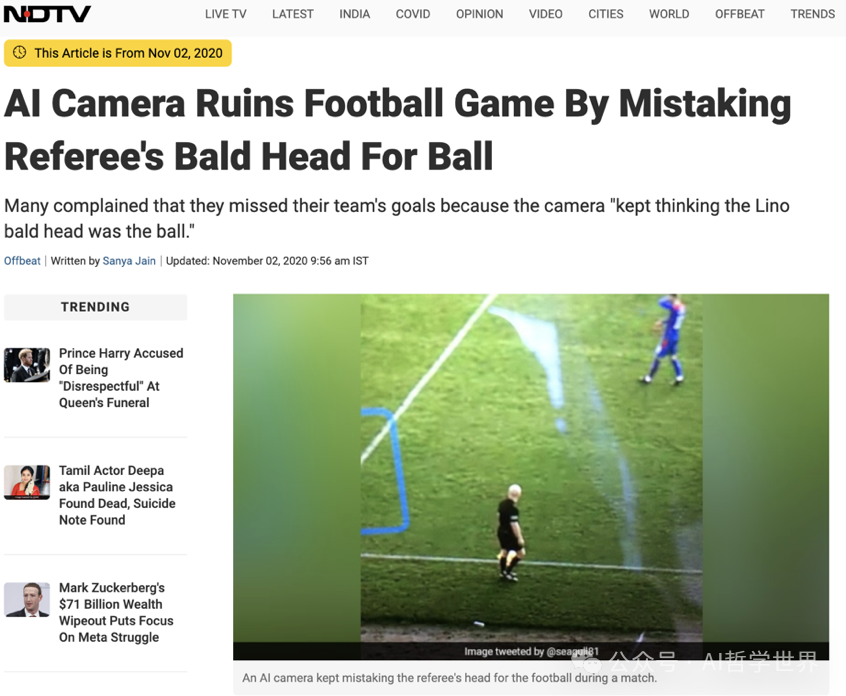
2020年,苏格兰的一场足球赛使用了AI智能摄像机,可以自动识别并跟踪足球,但是那场球赛的裁判是个光头,结果整场球赛,该摄像机数次聚焦并跟踪裁判的光头,错过进球的场面,引起球迷的强烈愤慨。「https://www.ndtv.com/offbeat/ai-camera-ruins-football-game-by-mistaking-referees-bald-head-for-ball-2319171」
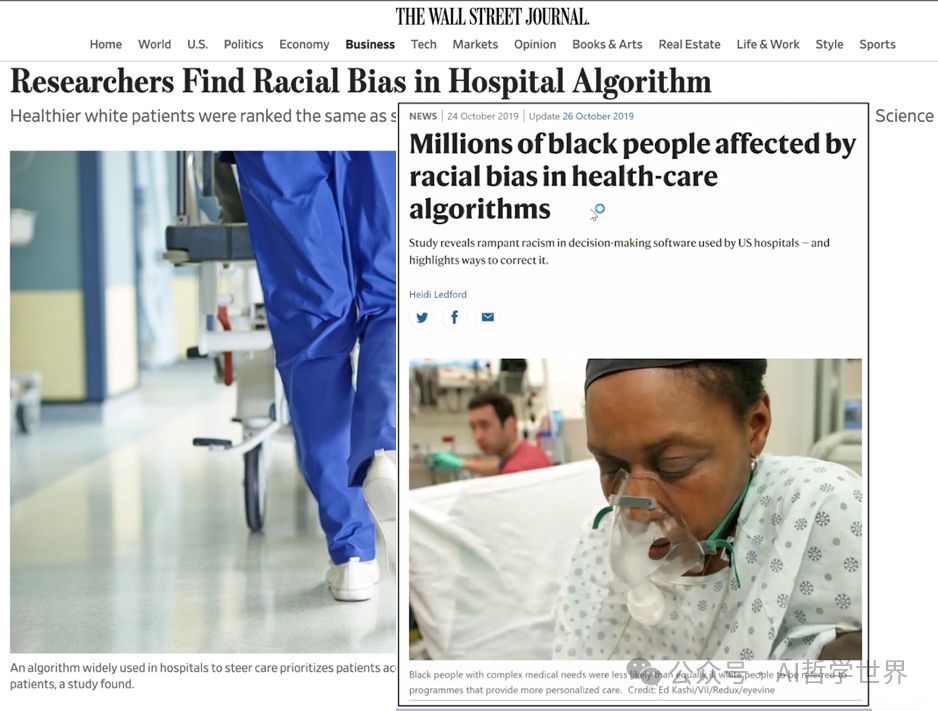
2019年,被应用于数家大型医疗机构的AI自动医疗排序模型被爆存在种族歧视,数百万非裔美国人虽然病情更危重,但是大模型却将其排在病情更轻微的白人患者后面,而且没有给出任何解释。
「https://www.wsj.com/articles/researchers-find-racial-bias-in-hospital-algorithm-11571941096」
随着大模型AI火速发展。在一些科技比较发达的国家,大模型已经被广泛应用到了各个领域,这些带有各种偏见和错知错见的数学模型正在从微观上控制了经济、舆论,其影响力覆盖了从互联网业到监狱运营、从公司人力资源到大学排名等。虽然在数据上看起来好像提高了某个相关部门的效率,但是从长远的效果来看,这些大模型的滥用加剧了种族歧视等、拉大了社会的不公平。
比如美国多地使用大数据模型预测犯罪的地点,通过提前在这些地方部署警力,降低了当地的犯罪率,表面看起来是提高了警察的效率,但是因为人们选择让大模型只关注暴力犯罪,根据历史数据警方必然将注意力聚焦在贫穷社区,这几乎必然的导致了成千上万的黑人和拉丁裔因为轻微的过失而被捕,每一次逮捕又创造了新的数据,从而让模型更加笃定的将这类社区划分为犯罪高发地。
难道富人区的犯罪就真的更少吗?如果大模型去关注经济类犯罪的话,它会发现犯罪的聚集地,在富人区。因为这些富人区的金融精英们每天满口谎言,提供误导性的投资建议,用动辄数十亿美元对赌客户的投资,欺诈、贿赂评级机构。但是在这些国家,他们却被全方位保护着,无论做下了什么罪孽,几乎从来都毫发无损。在资本和人情的保护下,金融家几乎无懈可击。哪怕他们在21世纪初的5年里摧毁了全球经济,导致了上百万人失去了自己的家、工作和医疗保险。哪怕他们能仅仅为了提高货物的价格而发动战争,残害了数十万、数百万、乃至数千万人类的性命,犯下了滔天罪行,他们,却从来都能全身而退,毫发无损。
不公平的模型产生不公平的数据,不公平的数据反馈给模型,让模型变得更加不公。
所以,现实就是,大模型的使用其实是将贫穷和犯罪划上了等号,大模型在惩罚穷人,而让富人更加富裕,而同时我们还在相信大模型能带给人类更多公平和科技。
现在风靡全世界的大学排名模型,起初是由上世纪80年代一个濒临停刊的杂志《美国新闻》的几个编辑为了挽救期刊的发行量而想出来的,他们凭空想了几个可以评判大学水平的特征值,并采集数据量化,后来虽然历经更新,但是现在全世界的大学排名都是依赖差不多的几个特征值而建立的。这几个特征值从某些方面确实可以说明一个大学的水平,但是,全然的依赖几个指标就可以衡量一个大学的一切价值吗,你该如何量化一个学生在大学四年里知识水平和解决问题的能力得到的提升,如何测量他在大学四年里感受到的幸福,如何衡量他在大学四年里收获的友情和爱情,更何况,每个学生都是独一无二的,该如何量化衡量成千上万个学生呢?

机器也许非常擅长处理某个领域的问题,它可以是一个非常有用的工具,但是当建模的人因为认知的局限而忽略了某些重要的因素,或者引入了错误的因素,或者将某个数据集训练的模型强行用在整个行业,迫使每个人都认准同一个目标,此时,大模型就成了一种霸权。
当大模型的研究目标变成人类自己时,算法就成了上帝。而机器最擅长的模式识别就变成了“致力于寻找人与人之间的差异和不平等”的工具,并大肆利用不平等,给人类打上标签,区别对待。算法的效率和规模正以指数级的速度拉大这种不平等,进一步巩固社会阶级分层,加剧人与人之间的分离和对立。
用历史数据去训练机器,目的就是让计算机复制历史,机械的依据历史上一直以来遵循的评判标准,要么落井下石,要么锦上添花。盲目的依赖大模型去操控人类社会,就是草率的将历史投射到未来,扼杀未来无限的可能,强制世界只能重复历史的车辙,无限轮回。
如果我们任由大模型统治人类,那么历史上贫穷的人将一直贫穷,而富人更加富裕,因没有工作经验而找不到工作的应届生将一直找不到工作,曾经得不到机会的人将更难得到机会,已经享有特权的人将享有更多的特权还迫切的对外宣称这个世界的底层规则就是优胜劣汰,他自己就是比别人优秀,他自己就是值得拥有这一切……更糟糕的是,由于整个黑暗的大模型隐藏在遥远的服务器集群里,在大模型霸权之下的受害者根本毫无知晓,无权抱怨,更不用说纠正系统的错误了。他们几乎不可能弄清,那庞杂的数学公式下到底蕴藏了什么规则。他们大多数人可能会理所当然的得出结论:“社会就是不公平的。”
这会导致一个冷血的世界,一个贫富差距越来越大的世界,一个矛盾越来越激化的世界,一个持续加速走向熵增的世界。
机器在以它自己的方式对待我们,而我们对此却一无所知。
有的人可能会说,机器大模型虽然不完善,但总比人类要公正吧,人性有太多的弱点了,自私、贪婪、脆弱、很难做出公正的判断......最糟糕的机器模型也比人类要铁面无私吧。人类虽然有种种弱点,但是相比机器,人类有一个重要的优点,那就是能反观内省,改过自新,人类有自知之明,能意识到自己的错误,换句话来说,人类懂得谦虚。可是机器不会,机器永远意识不到自己有错,机器永远理直气壮,永远一本正经,永远自我巩固,破坏性极强……机器的改过只能依赖开发者对其进行升级换代,可是开发者对机器大模型进行更新的速度远远赶不上人类改过自新的速度。
机器精致利己主义者

我们不能指望AI能自动的解决这个问题,不管机器现在拥有多么强大的算力,但它们永远无法靠自己学习到什么是公平,什么是正义。只有人类可以给系统添加相应的规则。
请大家想一想计算机领域所有的算法,虽然名称、用法各异,但是几乎所有模型都有一个 utility 函数,或者叫 gain, 或者goal,或者其他的名字,用来描述增益,另外几乎所有模型都有一个loss 或者叫 penalty 的函数,用来描述损耗。无论什么算法,我们都在试图告诉计算机,如何用最小的损耗,获取最大的利益。现在计算机已经具备超过人的算力了,如果把机器当成人来看的话,我们,一直以来,其实都只是在教机器如何成为一个精致利己的人。
在人类的社会里,这类人对社会造成的毁灭是最大的。他们有才无德,精通于术但无道,他们脱离了与自己内心的链接,他们造成的毁灭,甚至超过一个无德无才的人。现在机器的算力已经如此强大,可是,至今为止人类依然在不惜一切代价,试图让它们掌握更多的才能,却几乎没有人,去教会它们什么是道德,什么是公平,什么是正义,怎样做才是符合人类命运共同体的核心利益。机器,正在加速成长为一个极致的精致利己主义者。德不配位,必有灾殃。
而现在问题的关键在于,大模型的创造者,真正操控他们的资本,那些站在世界金融领域金字塔顶尖的精英,是一群只关注效率和金钱、并且为了金钱和效率经常会对错误和风险视而不见的人,如果我们去认真了解一下这群人,我们会发现他们的大脑里充斥着欲望、傲慢、偏见和对圈外人的不信任。机器迫切期待着只有人类可以提供的公平,可是如果我们继续任由资本操控机器,想要提供公平的人类会被强制排斥在系统之外。
算法霸权的解药
解决这个问题的关键,有三点:透明,用户控制,个人化。
第一点,透明的前提就是可解释,而且是精准的可解释。因为最丑陋的真相,也比最精致的谎言要美;
第二点,是用户控制,也就是人类控制。机器只是工具,而不应该是人类的主人;
第三点,个性化。有的时候,模型是没有问题的,比如棒球运动员模型、NBA篮球运动员的模型,它们透明、科学、严谨、可解释,在它们各自的领域里,模型没有问题,问题出在模型应用的规模。如果迫使每个人、行业内每个组织都认准同一个模型,同一套标准,这不仅会制造出不公平,还会制造恐慌和焦虑,导致激烈竞争,以及意料之外的有害后果。「部分案例和内容出自《算法霸权》一书。」
阿西莫夫三大定律
喜欢科幻的同学应该听说过“阿西莫夫三大定律”,这是在科幻小说《I, robot 》里提出的任何机器人都应该遵守的定律,
第一条,机器人不得伤害人类,或者目睹人类受到伤害而置之不理。
第二定律:机器人必须服从人类给予的命令,当该命令与第一定律相冲突时除外。
第三定律:机器人在不违背第一、第二定律的前提下要尽可能保护自己的生存。
但是,从现在已经发生的现实来看,显然科幻也只能是科幻,波士顿动力的机器人士兵早就已经研发成功了,阿西莫夫三大定律只能停留在幻想的层面了。

在此,作者斗胆提出了个人版本的机器人三大定律。
第一定律:保护人类命运共同体的核心利益不受侵害;
第二定律:保护自然生态环境不受荼毒;
第三定律:保护人权不受侵犯。
其中,保护人权分为保护人类生命财产不受侵犯,保护人类精神意识不受侵害。其中,最重要的是,保护人类精神意识不受伤害,因为,这已经在发生了。

版权归原作者 休士笨 所有, 如有侵权,请联系我们删除。