
这是我的第361篇原创文章。
一、引言
Rasa是一个开源的对话式 AI 框架,用于构建自定义的对话式 AI 助手。它可以处理自然语言理解(NLU)和对话管理(DM),使得开发者能够轻松地创建功能丰富的对话式 AI 应用。Rasa是一个开源机器学习框架(小模型),主要功能:支持闲聊,问答型机器人和多轮会话。
二、系统架构

上图概述了Rasa开源体系结构:
- RASA包含自然语言理解(NLU)和对话管理两个主要组件。NLU提供了意图分类,实体提取和响应检索功能,它是以管道的方式处理用户对话,在上图中显示为NLU Pipeline。对话管理组件可以根据上下文决定对话中的下一个动作,在上图中显示为Dialogue Policies。
- Agent组件,从Robot User来看,Agent就是整个RASA系统的代理,它接收用户输入消息,返回Rasa系统的回答。在Rasa系统内,Agent就是一个总控单元,它引导系统启动,它连接NLU和DM,得到Action,然后调用Action得到回答,它保存对话数据到数据存储。
- Tracker Store是对话的存储单元,对话跟踪单元将用户和机器人的对话保存在Tracker Store中。Rasa提供了针对不同存储类型的开箱即用的实现,包括postgresql,SQLite,Oracle,Redis,MongoDB,DynamoDB。TrackerStore也支持自定义存储。
- Event Broker事件代理,机器人可以通过Event Broker连接到其他服务。机器人可以发布一个消息给其他服务来处理这些消息,也可以依靠Event Broker转发Rasa Server的消息到其他服务。目前RASA支持的Event Broker有RabbitMQ,Kafka,SQL。
- Lock Store,该组件是一个ID产生器,当RASA是一个集群部署的时候,并且客户端在发送RASA服务端的消息每次不一定会寻址到同一个服务器,因此需要一个全局的Session ID。Rasa使用Token Lock机制来确保全局唯一SessionID,并在消息处于活动状态时锁定会话,以此保证消息的顺序处理。
- FileSystem提供无差别的文件存储服务,比如训练好的模型可以存储在不同的位置。支持磁盘加载,服务器加载,S3这样的云存储加载。
- ActionServer提供了Action与Policy解耦的一种方式。用户可以定义任何一种Action连接到Action Server上,通过训练学习,RASA可以将policy路由到这个Action上。这使得给机器人热插拔一个能力成为可能。
三、核心模块介绍
Rasa有两个主要模块:Rasa NLU 和Rasa Core,旧版本:rasa-nlu和rasa-core是分开安装的,最新版本:rasa 将二者做了合并。
Rasa NLU 是核心模块之一,NLU是英文Natural Language Understanding的简称,也就是自然语言理解,这个模块用于对用户消息内容进行语义理解,并将结果转换成结构化的数据。在Rasa这里,需要提供一份训练数据,Rasa NLU会基于这份数据进行模型训练,然后通过模型对用户消息进行语义理解,主要是意图识别和实体提取。
- 意图分类器主要是对用户的每一次对话进行意图识别,确定用户的每次意图,确定客户每次问的意图是哪种,需要做什么。一般任务型对话中,意图识别都是确定的集合,需要人为先确定任务意图类型,然后在实际场景中进行意图分类。RASA的意图分类器主要是完成这一任务。
- 实体提取器主要是对用户的每一次对话中进行命名实体识别,实体做为slot(槽)信息进行填充。举例来说,用户意图为订火车票,那机器人必须知道是从哪里出发目的地是哪里,这个信息就需要从用户对话中提取地名这个命名实体。RASA的实体提取器支持这一个功能。
NLU组件也是一个可细分pipeline结构,过程是Tokenize->Featurize->NER Extract->Intent Classify。
例如,下面句子:
"I am looking for a Mexican restaurant in the center of town"
返回结构化数据:
{ "intent": "search_restaurant","entities": { "cuisine" : "Mexican", "location" : "center" }}
Rasa_NLU_Chi 作为 Rasa_NLU 的一个 fork 版本,加入了jieba 作为中文的 tokenizer,实现了中文支持。
Rasa Core是一个对话管理平台,用于举行对话和决定下一步做什么。Rasa core是Rasa框架提供的对话管理模块,它类似于聊天机器人的大脑,主要的任务是维护更新对话状态和动作选择,然后对用户的输入作出响应。所谓对话状态是一种机器能够处理的对聊天数据的表征,对话状态中包含所有可能会影响下一步决策的信息,如自然语言理解模块的输出、用户的特征等;所谓动作选择,是指基于当前的对话状态,选择接下来合适的动作,例如向用户追问需补充的信息、执行用户要求的动作等。
RASA在处理对话时,整体流程是pipeline结构,自然语言理解(NLU)、对话状态追踪(DST)以及对话策略学习(DPL)一系列流程处理下来,再判断执行下一个动作。使用Rasa构建的助手响应消息的基本步骤:
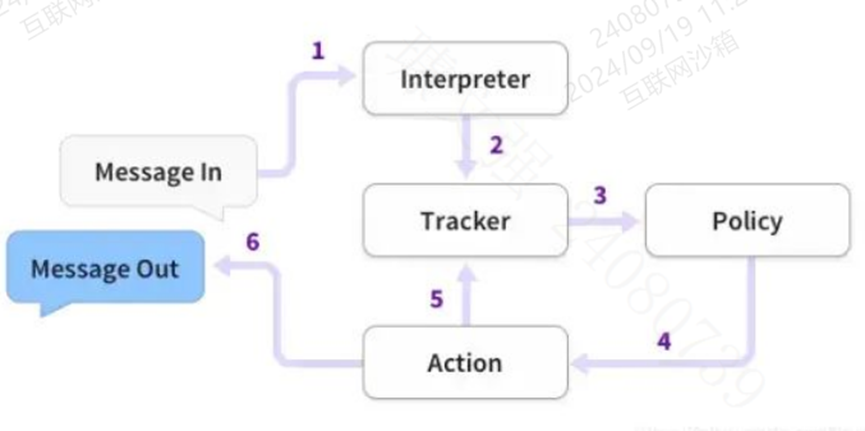
- 首先,将用户输入的Message传递到Interpreter(NLU模块),该模块负责识别Message中的"意图(intent)“和提取所有"实体”(entity)数据;
- 其次,Rasa Core会将Interpreter提取到的意图和实体传给Tracker对象,该对象的主要作用是跟踪会话状态(conversation state);
- 第三,利用policy记录Tracker对象的当前状态,并选择执行相应的action,其中,这个action是被记录在Track对象中的;
- 最后,将执行action返回的结果输出即完成一次人机交互。
几个术语
- 意图:用户打算问什么?
- 实体:用户查询中重要的信息是什么?
- 故事:即对话脚本,对话进行的可能方式是什么?
- 行动:机器人应根据特定请求采取什么行为措施?
四、使用
1、安装rasa
使用pip install rasa[full]安装Rasa,则会为每种配置安装Rasa的所有依赖项(比如spaCy、MITIE)
2、创建一个新的rasa****项目
rasa init

项目结构:一个典型的 Rasa 项目包含以下文件和文件夹:
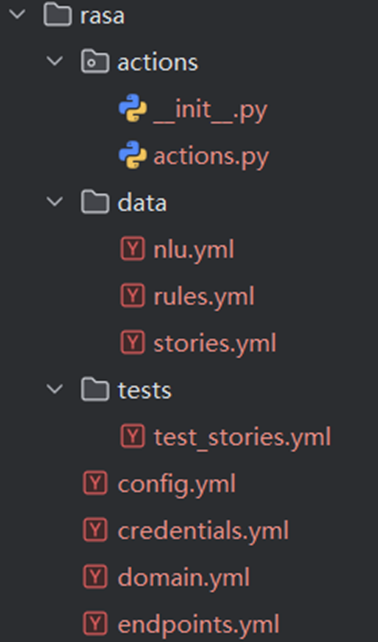

- credentials.yml: 存储与外部服务(如 Facebook Messenger、Slack 等)的 API 凭据。
- config.yml: 存储 Rasa 的配置信息,如 NLU 管道、策略等。
- data/: 存储训练数据,包括 NLU数据(训练意图识别模型)和对话数据(训练对话策略选择模型)。
- domain.yml: 定义对话的领域,包括实体、槽、意图、动作、模板等。
- credentials.yml: 存储与外部服务的 API 凭据。
- endpoints.yml: 定义 Rasa 服务器的端点,如模型存储、自定义操作等。
3、根据业务配置文件
nlu.yaml

nlu文件是告诉模型用户可能会说什么。给的例子是模拟了平时人在相关情形下常说的话。可以理解为,有监督的机器学习,我们给模型提供的学习数据。为了创建自定义聊天机器人,我们将在其中编写一些意图,同时确保意图名称没有重复,并且每个意图确保至少给出两个示例。
domain.yml

这个文件列出了nlu里的所有类型,而responses则是我们告诉机器人,当用户做出了nlu里的相关行为之后,应该怎样回应(其实就是类似一个判断分支的代码逻辑),比如当我识别出用户想让我讲个笑话的时候,我们就回复今日的风儿甚是喧嚣啊。当然,我这里只定义了一条,当定义多条回复信息时,机器人就会随机回复其中的一条。
sotries.yaml:

这里其实是模拟了可能发生的对话情况,每一条训练数据是一个story,即是一次完整的场景对话(多个intent-action),比如第一个沮丧情况,机器人问候之后,用户表示不开心,机器人会做一个cheer_up行为,然后询问刚才的鼓励行为是否有效,如果用户回复确认,机器人会进行说请保持,也就是23行的happy行为。
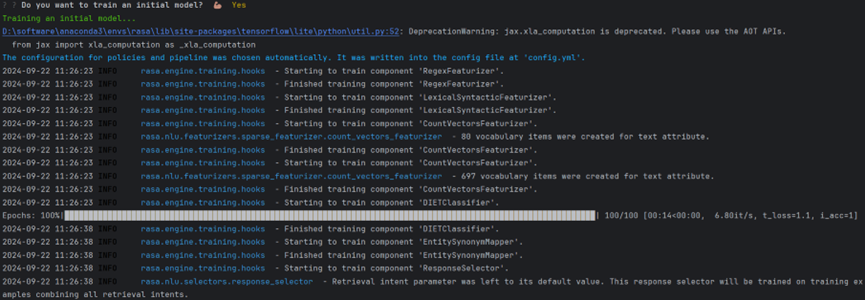
4****、训练模型
准备好domain.yml和sotries.yaml数据之后,就可以进行模型的训练了。Rasa会根据这些数据来训练机器人的回答策略,模型的输入数据是历史对话记录,lable是下一个决策action。模型本质上是num_actions个类别的多分类。
这里它直接问我要不要训练这个初始化的模型,我直接输入Y就可以。等价于命令
rasa train
训练过程:

训练完成:

训练完成之后这将在models/文件夹下生成一个训练好的模型。
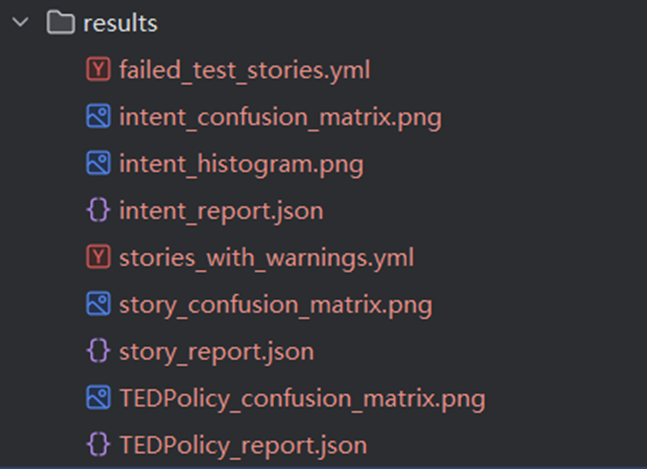
**5. **测试模型
使用以下命令测试模型:
rasa test
这将在results/文件夹下生成测试结果。
6****、运行
现在,可以将此聊天机器人集成到自己的网站或者连接到任何其他平台,但是必须创建自己的自定义连接器。有两种运行Rasa的方法:在Shell和localhost上。
这里它直接问我要不要对话这个训练好的模型,我直接输入Y就可以。等价于命令
rasa shell

另一种方法是在本地服务器上运行Rasa。为此,只需在Rasa文件夹中打开的终端上运行以下命令:
rasa run
这将在本地系统上运行Rasa,并在本地主机的5005端口公开REST端点。为了与Rasa服务器公开的REST端点进行通信,可以使用cURL命令(对于Linux爱好者)或Postman。这里推荐Postman,因为它易于使用。

7****、部署对话式 AI 助手
要将你的对话式 AI 助手部署到生产环境,你可以使用 Rasa 的 REST API。首先,在endpoints.yml文件中配置端点:
action_endpoint:
url: "http://localhost:5055/webhook"
model:
url: "http://localhost:5005/model"
token: "your-token"
tracker_store:
type: "sql"
dialect: "sqlite"
db: "rasa.db"
然后,使用以下命令启动 Rasa 服务器:
rasa run
现在你的对话式 AI 助手已经部署到生产环境,可以通过 REST API 与外部服务进行交互。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
版权归原作者 数据杂坛 所有, 如有侵权,请联系我们删除。