
1 前言
🚩 基于大数据的高考数据分析
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
🧿 选题指导, 项目分享:
1 课题背景
本期我们通过分析2017-2019年山东省高考考生考试成绩分布数据以及双一流大学(985/211)录取山东省考生数据,通过数据可视化分析山东省考生高考成绩主要集中在哪些区间、本科上线率有多少、双一流大学录取最低分各是多少、考生报考比较多的专业有哪些。
2 具体实现
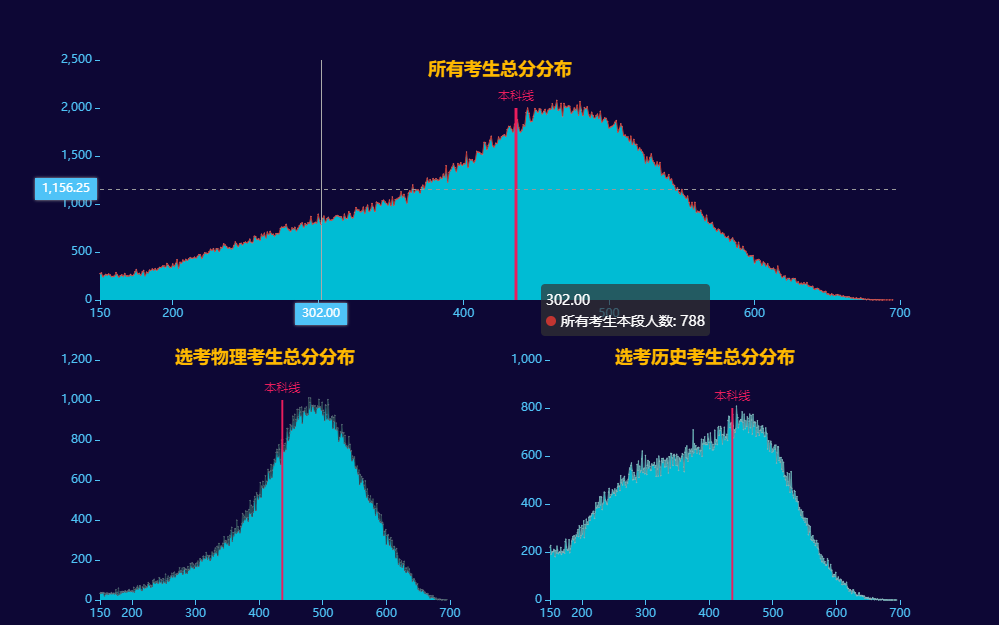
所有考生及各学科总分分布图
#部分代码
colors =["#00BCD4","#ea1d5d","#ffb900","#4FC3F7"]
L1 =(
Line().add_xaxis(df['分数段']).add_yaxis("所有考生本段人数",df['所有考生本段人数'],symbol_size=0.5,).set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=1, color=colors[0]),
label_opts=opts.LabelOpts(is_show=False),
markarea_opts=opts.MarkAreaOpts(
data=[
opts.MarkAreaItem(
name="本科线", x=(435,437),y=(0,2000),
label_opts=opts.LabelOpts(color=colors[1]),
itemstyle_opts=opts.ItemStyleOpts(color=colors[1]))]))
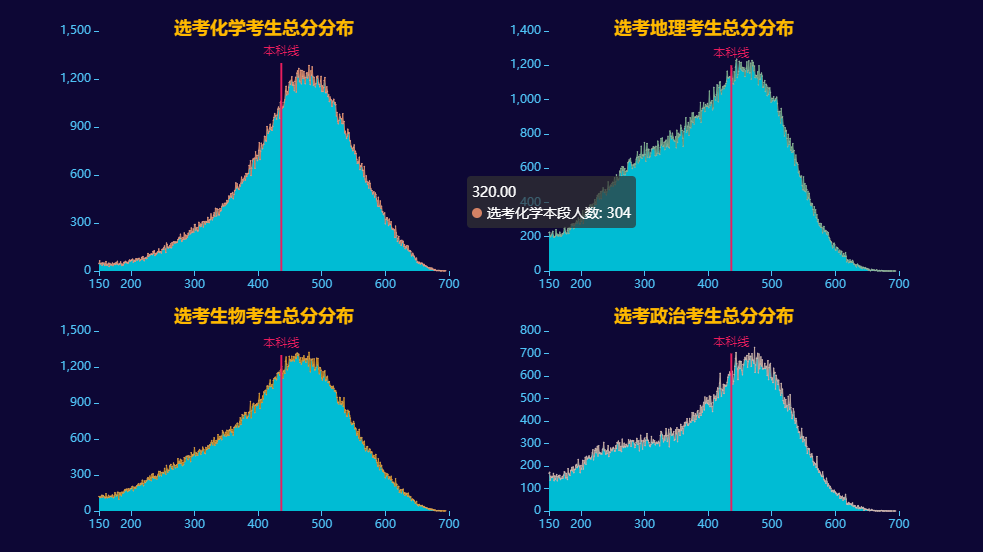
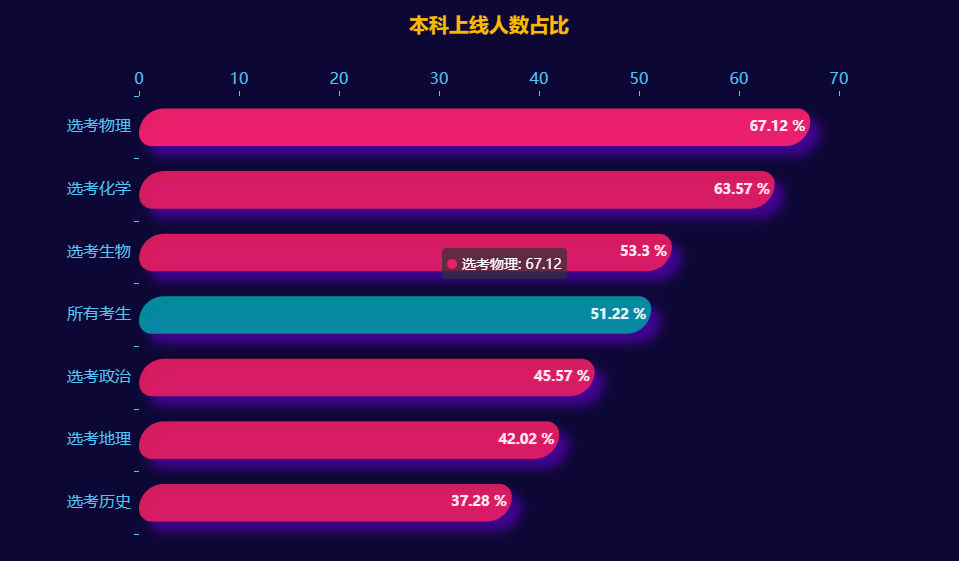
本科上线人数占比
# 指定柱子颜色的js代码
color_function ="""
function (params) {
if (params.value == 51.22)
return '#0097A7';
else return '#E91E63';
}
"""
cols =['所有考生','选考物理','选考化学','选考生物','选考历史','选考地理','选考政治']
rate_data =[]for i in cols:
rate_data.append(round(df.loc[df['分数段']>435][i+'累计人数'].tolist()[-1]/df[i+'累计人数'].tolist()[-1]*100,2))
df_rate_data = pd.DataFrame([rate_data],columns=cols)
df_rate_data = df_rate_data.T.sort_values(0,ascending=False)
b1 =(
Bar().add_xaxis(df_rate_data.index.tolist()[::-1]).add_yaxis('', df_rate_data[0].values.tolist()[::-1], category_gap='40%').set_series_opts(
label_opts=opts.LabelOpts(
position='insideRight',
vertical_align='middle',
font_size=14,
font_weight='bold',
formatter='{c} %'),
itemstyle_opts={'opacity':0.9,'shadowBlur':10,'shadowOffsetX':10,'shadowOffsetY':10,'shadowColor':'rgba(125,0, 255, 0.5)','barBorderRadius':[30,15,30,15],'color':JsCode(color_function)}).set_global_opts(
xaxis_opts=opts.AxisOpts(
position='top',
axislabel_opts=opts.LabelOpts(font_size=16, color=colors[3]),
axisline_opts=opts.AxisLineOpts(
is_show=False,linestyle_opts=opts.LineStyleOpts(width=2, color=colors[3]))),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(font_size=16, color=colors[3]),
axisline_opts=opts.AxisLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(width=2, color=colors[3])),),
title_opts=opts.TitleOpts(title="本科上线人数占比", pos_top="3%", pos_right="center",
title_textstyle_opts=opts.TextStyleOpts(color=colors[2], font_size=20),),).reversal_axis())
grid1 = Grid(init_opts=opts.InitOpts(width='1000px', height='600px',bg_color='#0d0735'))
grid1.add(b1, is_control_axis_index=False, grid_opts=opts.GridOpts(pos_left='15%', pos_right='15%', pos_top='17%'))
grid1.render_notebook()
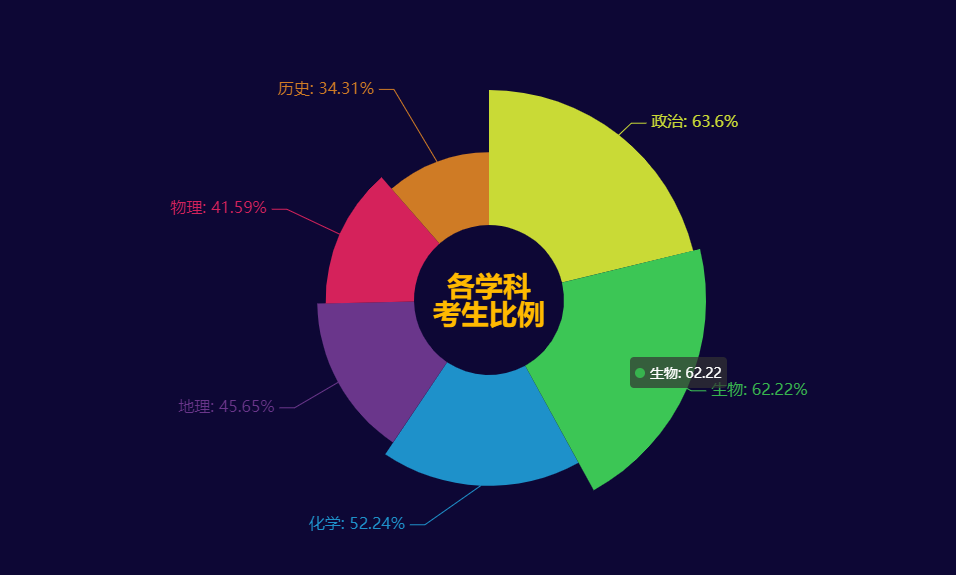
各学生考生比例
color_series =['#C9DA36','#37B44E','#1E91CA','#6A368B','#D5225B','#CF7B25']
df1=df.iloc[-1,[i%2==0and i!=0for i inrange(len(df.columns))]]
subj_data =[round(i/df1.values.tolist()[-1]*100,2)for i in df1.values.tolist()][:-1]
subj_name =['物理','化学','生物','历史','地理','政治']
df_subj = pd.DataFrame(subj_data,index=subj_name,columns=['比例'])
df_subj.sort_values('比例',ascending=False,inplace=True)
P =(
Pie(init_opts=opts.InitOpts(width='1000px', height='600px',bg_color='#0d0735')).add("",[list(z)for z inzip(df_subj.index, df_subj['比例'])],
radius=["25%","70%"],
center=["50%","50%"],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=False),).set_colors(color_series).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}%",font_size=16)).set_global_opts(
title_opts=opts.TitleOpts(title="各学科\n考生比例", pos_top="45%", pos_right="center",
title_textstyle_opts=opts.TextStyleOpts(color=colors[2], font_size=28),),
legend_opts=opts.LegendOpts(is_show=False),))
P.render_notebook()
985/211大学(理工类)录取最低分数
#双一流高校的名单
double_first_list =['北京大学','中国人民大学','清华大学','北京航空航天大学','北京理工大学','中国农业大学','北京师范大学','中央民族大学','南开大学','天津大学','大连理工大学','吉林大学','哈尔滨工业大学','复旦大学','同济大学','上海交通大学','华东师范大学','南京大学','东南大学','浙江大学','中国科学技术大学','厦门大学','山东大学','中国海洋大学','武汉大学','华中科技大学','中南大学','中山大学','华南理工大学','四川大学','重庆大学','电子科技大学','西安交通大学','西北工业大学','兰州大学','国防科技大学','东北大学','郑州大学','湖南大学','云南大学','西北农林科技大学','新疆大学']
data_dir ='/home/mw/input/2206085359/'
all_files =[]for dirpath, dirnames, files in os.walk(data_dir):
all_files += files
all_files =[fileforfilein all_files if'2020'notinfile]#历年的数据
df_merge_year = pd.DataFrame()forfilein all_files:
df_tmp = pd.read_excel(os.path.join(data_dir,file),header=2)
df_tmp = df_tmp[df_tmp['院校名称'].isin(double_first_list)]
df_year = df_tmp.groupby(['院校名称'])['录取最低分'].min().reset_index()
df_year = pd.merge(df_year, df_tmp, on =['院校名称','录取最低分'], how ='inner')
df_year = df_year[['院校名称','录取最低分','专业名称','最低位次','平均分']]
df_year['年份']= re.findall('\d+',file)[0]
df_year['类别']= re.findall('((.*))',file)[0]
df_year['标签']= df_year['年份']+ df_year['类别']
df_merge_year = pd.concat([df_year, df_merge_year])
df_merge_year = df_merge_year.replace('前20名内',20)
sci_2019 = df_merge_year.loc[df_merge_year['标签']=='2019理工类',['院校名称','录取最低分','年份','最低位次']]
sci_2018 = df_merge_year.loc[df_merge_year['标签']=='2018理工类',['院校名称','录取最低分','年份','最低位次']]
sci_2017 = df_merge_year.loc[df_merge_year['标签']=='2017理工类',['院校名称','录取最低分','年份','最低位次']]
sci_2019 = sci_2019.sort_values('录取最低分')
df_score_pos = pd.merge(sci_2019,sci_2018,on ='院校名称')
df_score_pos = pd.merge(df_score_pos,sci_2017,on ='院校名称')
df_score_pos.columns =['院校名称','2019年录取最低分','2019年','2019年最低位次','2018年录取最低分','2018年','2018年最低位次','2017年录取最低分','2017年','2017年最低位次']
df_score_pos = df_score_pos.astype({'2019年最低位次':'int','2018年最低位次':'int','2017年最低位次':'int'})
index_list = df_score_pos[['院校名称','2017年录取最低分']].drop_duplicates()['院校名称'].tolist()
data1_2017 = df_score_pos[['院校名称','2017年录取最低分']].drop_duplicates()['2017年录取最低分']
data1_2018 = df_score_pos[['院校名称','2018年录取最低分']].drop_duplicates()['2018年录取最低分']
data1_2019 = df_score_pos[['院校名称','2019年录取最低分']].drop_duplicates()['2019年录取最低分']
df_score = pd.DataFrame([index_list, data1_2017.values.tolist(), data1_2018.values.tolist(), data1_2019.values.tolist()]).T
df_score.columns=['院校名称','2017年最低分','2018年最低分','2019年最低分']
df_score['最低平均分']=(df_score['2017年最低分']+df_score['2018年最低分']+df_score['2019年最低分'])/3
df_score['最低平均分']= df_score['最低平均分'].astype('float').round(2)
x_data = df_score['院校名称'].values.tolist()
y_score_2017 = df_score['2017年最低分'].values.tolist()
y_score_2018 = df_score['2018年最低分'].values.tolist()
y_score_2019 = df_score['2019年最低分'].values.tolist()
y_score_mean = df_score['最低平均分'].values.tolist()

985/211大学(理工类)录取最低位次
line2 =(
Line().add_xaxis(y_pos_mean).add_yaxis(
series_name ='平均最低位次',
y_axis = x_data,
symbol ="diamond",
symbol_size=14,
z=10,
linestyle_opts=opts.LineStyleOpts(color="#FFEB3B", width=3),
itemstyle_opts=opts.ItemStyleOpts(border_width=2, border_color="#C62828", color="#FFEB3B"),
label_opts=opts.LabelOpts(color='#FFEB3B',position='right'),))
bar2 =(
Bar().add_xaxis(x_data).add_yaxis("2017年", y_pos_2017, color='#EC407A').add_yaxis("2018年", y_pos_2018, color='#26A69A').add_yaxis("2019年", y_pos_2019, color='#3F51B5').set_series_opts(
label_opts=opts.LabelOpts(
position='inside',
vertical_align='middle',),
itemstyle_opts={'opacity':0.9,'shadowBlur':5,'shadowOffsetX':5,'shadowOffsetY':5,'shadowColor':'rgba(125,0, 125, 0.5)','barBorderRadius':[0,15,15,0],}).set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True, trigger='axis', axis_pointer_type='cross'),
datazoom_opts=opts.DataZoomOpts(orient="vertical",range_start=80,range_end=100),
title_opts=opts.TitleOpts(
title='985/211大学(理工类)录取最低位次',
subtitle='<制图@公众号:Python当打之年>',
pos_left='center',
pos_top='1%',
title_textstyle_opts=opts.TextStyleOpts(color='#ffb900', font_size=18),
subtitle_textstyle_opts=opts.TextStyleOpts(color='#009bbb', font_size=12),),
legend_opts=opts.LegendOpts(pos_left="center", pos_top='7%'),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(font_size=14, color='#c2ff00'),
axisline_opts=opts.AxisLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(width=2, color='#DB7093'))),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(font_size=14, color='#c2ff00'),
axisline_opts=opts.AxisLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(width=2, color='#DB7093')),)).reversal_axis())
bar2.overlap(line2)
grid = Grid(init_opts=opts.InitOpts(width='1000px', height='1200px',bg_color='#0d0735'))
grid.add(bar2, opts.GridOpts(pos_top="10%",pos_left="15%", pos_right="15%"), is_control_axis_index=True)
grid.render_notebook()

985/211大学(文史类)录取最低分数
line1 =(
Line().add_xaxis(y_score_mean).add_yaxis(
series_name ='最低平均分',
y_axis = x_data,
symbol ="diamond",
symbol_size=14,
z=10,
linestyle_opts=opts.LineStyleOpts(color="#FFEB3B", width=3),
itemstyle_opts=opts.ItemStyleOpts(border_width=2, border_color="#C62828", color="#FFEB3B"),
label_opts=opts.LabelOpts(color='#FFEB3B',position='right'),))
bar1 =(
Bar().add_xaxis(x_data).add_yaxis("2017年", y_score_2017, color='#EC407A').add_yaxis("2018年", y_score_2018, color='#26A69A').add_yaxis("2019年", y_score_2019, color='#3F51B5').set_series_opts(
label_opts=opts.LabelOpts(
position='inside',
vertical_align='middle',),
itemstyle_opts={'opacity':0.9,'shadowBlur':5,'shadowOffsetX':5,'shadowOffsetY':5,'shadowColor':'rgba(125,0, 125, 0.5)','barBorderRadius':[0,15,15,0],}).set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True, trigger='axis', axis_pointer_type='cross'),
datazoom_opts=opts.DataZoomOpts(orient="vertical",range_start=70,range_end=100),
title_opts=opts.TitleOpts(
title='985/211大学(文史类)录取最低分数',
subtitle='<制图@公众号:Python当打之年>',
pos_left='center',
pos_top='1%',
title_textstyle_opts=opts.TextStyleOpts(color='#ffb900', font_size=18),),
legend_opts=opts.LegendOpts(pos_left="center", pos_top='7%'),
xaxis_opts=opts.AxisOpts(
min_=400,
axislabel_opts=opts.LabelOpts(font_size=14, color='#c2ff00'),
axisline_opts=opts.AxisLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(width=2, color='#DB7093'))),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(font_size=14, color='#c2ff00'),
axisline_opts=opts.AxisLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(width=2, color='#DB7093')),)).reversal_axis())
bar1.overlap(line1)
grid = Grid(init_opts=opts.InitOpts(width='1000px', height='1200px',bg_color='#0d0735'))
grid.add(bar1, opts.GridOpts(pos_top="10%",pos_left="15%", pos_right="15%"), is_control_axis_index=True)
grid.render_notebook()
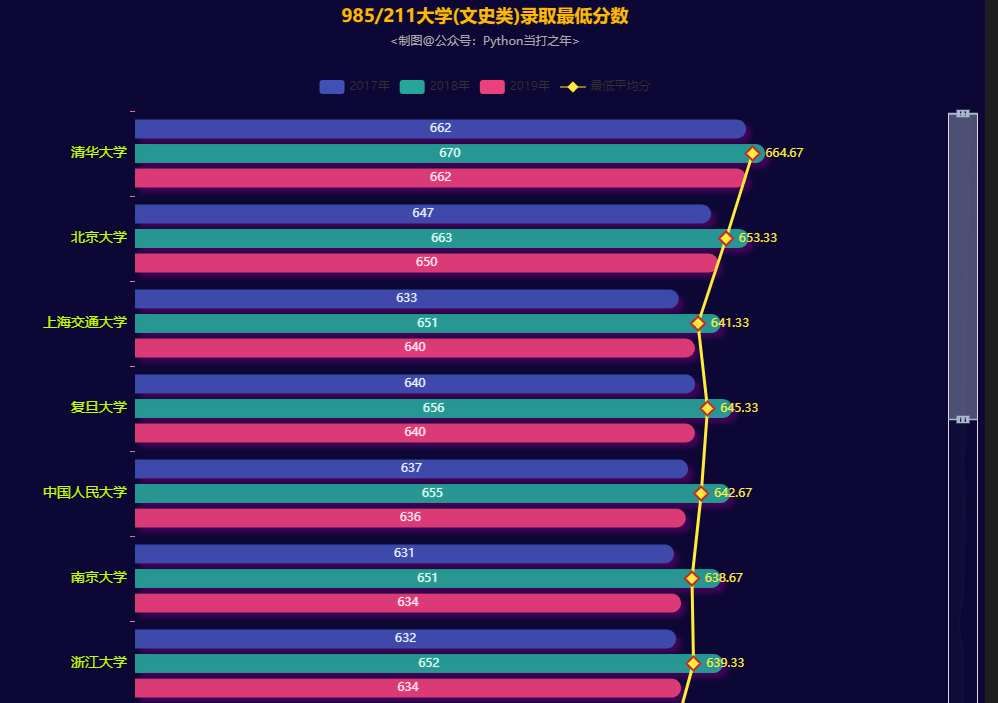
985/211大学(文史类)录取最低位次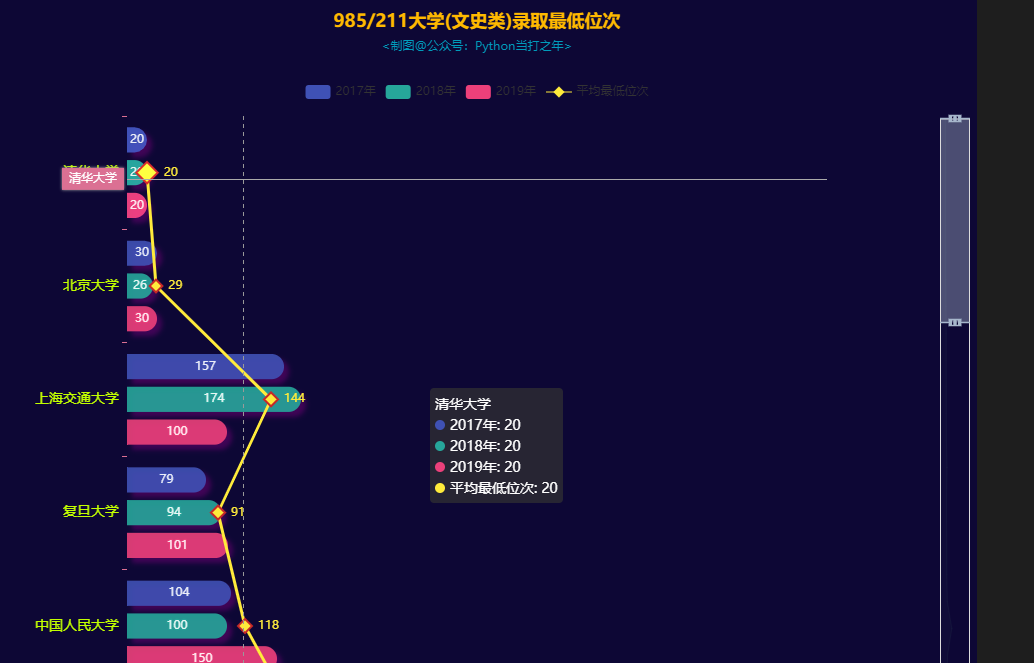
- 985/211大学(文史类)录取平均最低位次最高的前三甲学校:清华大学(20),北京大学(29),复旦大学(91)
- 中华人民大学(118),上海交通大学(144),浙江大学(172)紧随其后评论
985/211大学录取数量前15的理工类专业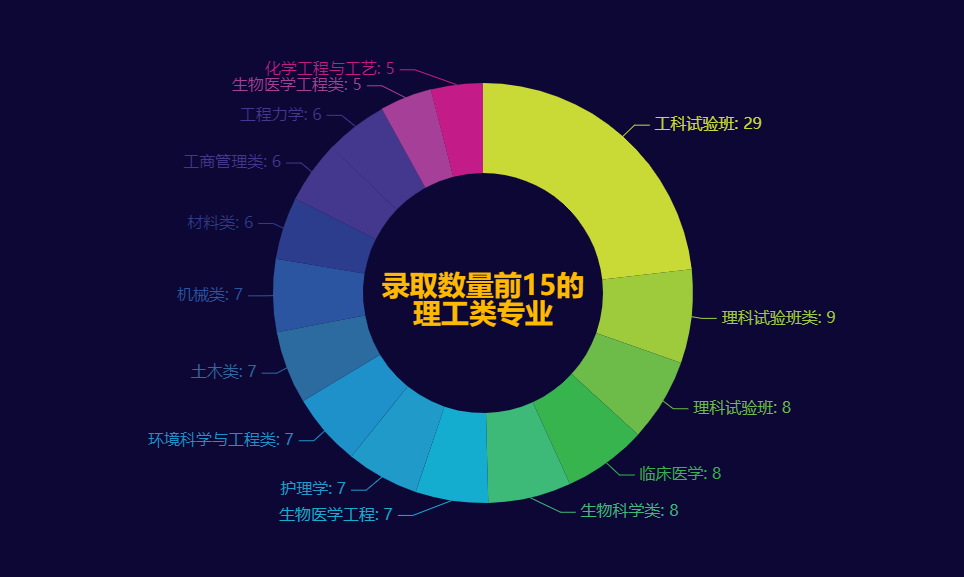
985/211大学录取数量前15的文史类专业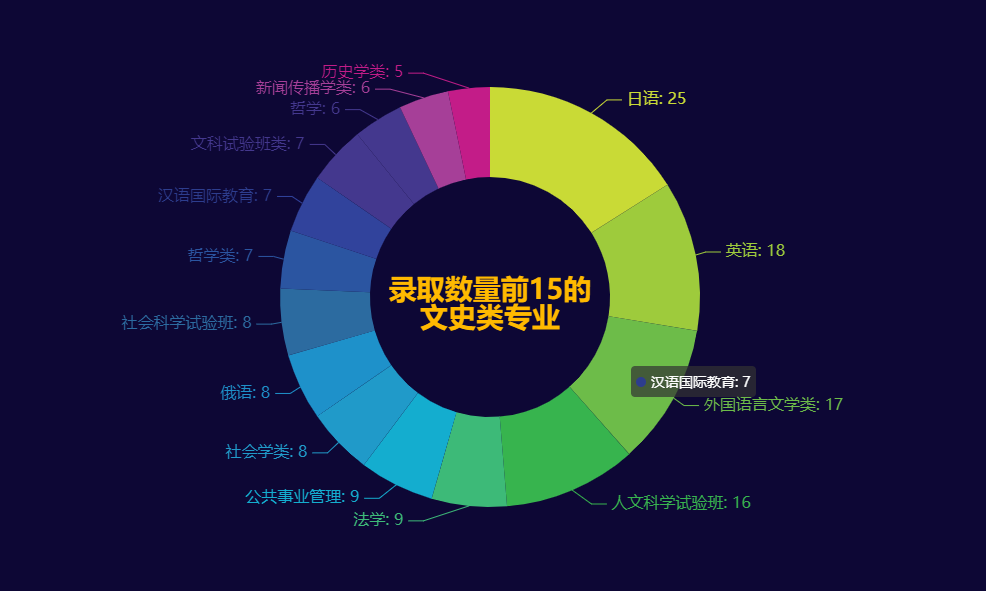
实现原理
涉及到的库
Pandas — 数据处理
行数据填充,重置列索引,去除前2行
import re
import os
import pandas as pd
df.loc[0]= df.loc[0].fillna(method ='ffill')
df.iloc[:,0]= df.iloc[:,0].fillna('')
df.columns = df.loc[0]+ df.loc[1]
df = df[2:]
df.head(20)
Pyecharts — 数据可视化
简介
Echarts是由百度研发,可以生成直观、生动、可交互、可高度个性化定制的Web数据可视化图表的可视化库。具有着开源、丰富的可视化类型、深度交互式探索、动态数据、绚丽特效等优点。2018年全球著名开源社区Apache基金会宣布Echarts项目全票通过进入Apache孵化器。
特性
- 简洁的 API 设计,使用如丝滑般流畅,支持链式调用
- 囊括了 30+ 种常见图表,应有尽有
- 支持主流 Notebook 环境,Jupyter Notebook 和 JupyterLab
- 可轻松集成至 Flask,Django 等主流 Web 框架
- 高度灵活的配置项,可轻松搭配出精美的图表
- 详细的文档和示例,帮助开发者更快的上手项目
- 多达 400+ 地图文件以及原生的百度地图,为地理数据可视化提供强有力的支持
最后
本文转载自: https://blog.csdn.net/HUXINY/article/details/126712232
版权归原作者 DanCheng-studio 所有, 如有侵权,请联系我们删除。
版权归原作者 DanCheng-studio 所有, 如有侵权,请联系我们删除。