
一、文档识别难题
我们通过视觉、听觉、触觉、嗅觉来认知周围环境客观物体。眼睛是我们探测周围物体光线的接收器,它探测了物体的明暗、颜色、形状和空间关系,人类对世界的感知 80% 是通过眼睛获取,相比听觉和触觉来说,视觉更有冲击力。
利用眼睛理解外部事物的过程通常就是视觉感知,视觉感知是人工智能当中特别重要的问题之一,在视觉感知中,文档文字识别是非常重要的计算机视觉技术,因为文字是我们感知这个世界最重要的手段,文字可以说是人类文明的标志,是信息交流的途径,学习知识的重要渠道,是记录历史、思想、文化的载体。
我们把 OCR 比做 AI 技术的一双慧眼,帮助人工智能看清所有需要处理的文字内容、符号信息,然而目前低质文档图像的识别问题似乎已经成为 AI 技术落地中的瓶颈,文档图像作为一种非结构化数据,其分析识别面临一些技术难点:
- 低质文档图像难以识别:图文混合、区域形状不规则、变形文档质量退化严重,如下图产生了极大的摩尔纹,为图像识别带来极大困难;
- 场景文本的文字检测及版面分析困难:自然场景图像的背景复杂、光照和拍照视角变化、文本行方向和形状变化、字体风格和颜色变化等,,如下图手机拍照时角度倾斜,视角奇葩,文本准确定位提取非常困难;

- 无法检测过滤 PS 技术篡改:身份证、护照、行驶证、驾驶证、港澳通信证等证照类别,及增值税发票、普通发票、小票、合同等文档篡改后无法检测出是否真实,PS 智能检测在反欺诈、合规风控等领域意义重大。如下图证件修改过字和有效期数字,这为识别带来了新的困难;

二、技术分析
2.1、切边切片增强
2.1.1、技术介绍
目前自带的数码相机已经成为了手机等移动设备的标准配置,这些数字成像设备经常被用来拍摄各种文本图像,由于拍摄习惯,取景需求等的不同,用户拍摄到的文本图像,一般是包含有背景的,而用户需要的图像,通常是去掉了背景区域的图像。在票据识别、PPT 拍摄、名片识别、文稿备份时就需要用到切边切片技术。如下图所示:切边后图像可以更好的展示并提升下游任务(OCR 识别,信息抽取等)的准确率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZHs0PqJR-1666579769860)(static/boxcnA3OSUBEVESY60kF0on2L3f.png)]](https://img-blog.csdnimg.cn/800afa4352834ae69f58f03b5854a2d1.png#pic_center)
2.1.2、原理分析
对普通图像的切边切片的步骤如下:1.加载图像;2.对图像进行灰度化;3.边缘检测;4.轮廓发现;5.找出符合目标的最大外接矩形,并使用矩形的四个坐标点绘制线;6 切除 ROI(感兴趣区域);7.显示 ROI 区域。
对旋转图像的切边切片的步骤如下:1.加载原图;2.对图像进行灰度化;3.边缘检测;4.轮廓发现;5.找出图像旋转角度(a.找出旋转矩形的最大宽和最大高 b.找出这个目标矩形的旋转角度及旋转矩形。c.把此矩形绘制出来);6.根据图片中心点及旋转角度,制作目标旋转矩阵;7.利用仿射变换 + 第 6 步的旋转矩阵实现最终的旋转(仿射变换在图像还原、图像局部变化处理方面有重要意义);8.显示最终图像。
仿射变换是指在向量空间中进行一次线性变换和一次平移变换到另一个向量空间的过程,仿射变换可以通过一系列的原子变换的复合来实现,包括:平移、旋转和翻折;缩放、错切。没有平移或者平移量为 0 的所有仿射变换都可以叫线性变换,线性变换可以用如下变换矩阵描述:
[
x
′
y
′
]
=
[
a
b
c
d
]
[
x
y
]
\left[\begin{array}{l} x^{\prime} \\ y^{\prime} \end{array}\right]=\left[\begin{array}{ll} a & b \\ c & d \end{array}\right]\left[\begin{array}{l} x \\ y \end{array}\right]
[x′y′]=[acbd][xy]
不同变换对应的 a,b,c,d 约束不同,可以看上式,比如尺度变换的约束 a 就是 α,约束 d 就是 β,b 和 c 为 0,这样 x‘=αx,y’=βy 就是将图像沿着 x 轴放缩 α 倍,沿 y 轴放缩 β 倍。
而为了涵盖平移变换,需要给矩阵加一个维度,如下:
[
x
′
y
′
1
]
=
[
a
b
c
d
e
f
0
0
1
]
[
x
y
1
]
\left[\begin{array}{l} x^{\prime} \\ y^{\prime} \\ 1 \end{array}\right]=\left[\begin{array}{lll} a & b & c \\ d & e & f \\ 0 & 0 & 1 \end{array}\right]\left[\begin{array}{l} x \\ y \\ 1 \end{array}\right]
⎣⎡x′y′1⎦⎤=⎣⎡ad0be0cf1⎦⎤⎣⎡xy1⎦⎤
对应的约束有:a,b,c,d,e,f,即具有 6 个自由度,不同基础变换的 a,b,c,d,e,f 约束不同。平移变换时,b=0,d=0,a=1,b=1,c=λ,f=θ,那么 x‘=x+λ,y‘=y+θ,就是将图像沿 x 轴平移 λ 位,将图像沿 y 轴平移 θ 位。
为了使图像能够旋转,我们加入了三角函数,最终的矩阵变换我们定义为:
[
s
cos
(
θ
)
−
s
sin
(
θ
)
t
x
s
sin
(
θ
)
s
cos
(
θ
)
t
y
0
0
1
]
[
x
y
1
]
=
[
x
′
y
′
1
]
\left[\begin{array}{ccc} s \cos (\theta) & -s \sin (\theta) & t_{x} \\ s \sin (\theta) & s \cos (\theta) & t_{y} \\ 0 & 0 & 1 \end{array}\right]\left[\begin{array}{l} x \\ y \\ 1 \end{array}\right]=\left[\begin{array}{l} x^{\prime} \\ y^{\prime} \\ 1 \end{array}\right]
⎣⎡scos(θ)ssin(θ)0−ssin(θ)scos(θ)0txty1⎦⎤⎣⎡xy1⎦⎤=⎣⎡x′y′1⎦⎤
最终的仿射变换就是线性变换和平移变换如此叠加而来的,仿射变换能够给予图片放缩、旋转、平移、偏移等几何变换功能。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pN5hmHFu-1666579769862)(static/boxcnFPVnx1OGsIP83K92pzCTbc.png)]](https://img-blog.csdnimg.cn/5ffbd14d351a4acbb626de43d8378ced.png#pic_center)
2.2、弯曲矫正拉平
2.2.1、技术介绍
不同于平面扫描仪获得的文档图像,由手持镜头拍照得到的文档图像往往含有几何形变以及环境背景的干扰。这会使得现有文档信息抽取和内容分析系统的性能下降。如纸张的内容歪斜扭曲,部分纸张本身就不平整,存在过折叠、皱纹的畸变问题且本身厚度造成拍照过程中存在的图像的弯曲畸变。如下图所示形变矫正后图像能够更好的展示,并能显著提升下游任务(OCR 识别,版面分析/还原等)的准确率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h7QKRYF2-1666579769865)(static/boxcniYfz1JL0yY0n2Cdd7leqff.png)]](https://img-blog.csdnimg.cn/4827d7d615e1455fa1ea5edc19d36ca7.png#pic_center)
2.2.2、原理分析
DocUNet:具有中间监督的堆叠图像解扭曲网络
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xQMw8vTK-1666579769867)(static/boxcnYb4RbTr9AmlIz0mFMqsYih.png)]](https://img-blog.csdnimg.cn/615fb8f1f8814b5c973e2fd7aa8f6489.png#pic_center)
DocUNet 依赖于卷积神经网络(CNN)进行端到端图像恢复。模型由两个 U-Net 组成。其中,U-Net 是一个完全卷积网络,它包含一系列下采样层和一系列上采样层。特征图在下采样层和上采样层之间连接。然而,单个 U-Net 的输出无法完成工作,受连续预测和渐进精化工作的启发,文章将另一个 U-Net 作为精化器叠加在第一个 U-Net 的输出端。第一个 U-Net 在最后一个反褶积层之后分裂,而第一个 U-Net 和中间预测 y1 的反卷积特征被连接在一起作为第二个 U-Net 的输入。第二个 U-Net 最终给出精确的预测。
DewarpNet:使用堆叠的 3D 和 2D 回归网络对单图像文档进行解扭曲
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lP4aVNpH-1666579769869)(static/boxcnhxROMrd9PB7bUZ6cZFhmGd.png)]](https://img-blog.csdnimg.cn/68bce3d8582b4bffa650b1c1c8ba925b.png#pic_center)
DewarpNet 由两个子网络组成:形状网络和纹理映射网络。此外,文章还提出了一个用于光照效果调整的后处理增强细化网络,该模块可以在视觉上改善未旋转的图像。
形状网络:将此回归任务表述为图像到图像的转换问题。形状网络将 I 的每个像素转换为 3D 坐标图,C∈ Rh×w×3,其中每个像素值(X,Y,Z)对应于文档形状的 3D 坐标。在设计形状网络时,文章使用跳连接的 U-Net 型编码器-解码器架构。
纹理映射网络:以三维坐标映射 C 为输入,输出后向映射 B。在纹理映射网络中,采用了一种多 DenseNet 块的编解码结构。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QL4gX1RK-1666579769870)(static/boxcnyGwrLOYedUrYX3gUiu0WWh.png)]](https://img-blog.csdnimg.cn/566c38a91ac24ae8a5a1cf7a8f0904e0.png#pic_center)
细化网络:作为后处理组件以调整校正图像中的照明效果。该网络不仅提高了结果的感知质量,而且提高了 OCR 性能。文章利用 Doc3D 数据集中的额外地面真实信息(即表面法线和反照率地图)来训练细化网络。细化网络有两个 U-Net 型编码器解码器:一个用于预测曲面法线 N∈ ×3 给定输入图像 I;另一个以 I 和对应的 N 作为输入并估计阴影图 S∈ Rh×w×3.S 描述阴影强度和颜色。
2.3、摩尔纹去除
2.3.1、技术介绍
当感光元件像素的空间频率与影像中条纹的空间频率接近时,可能产生一种新的波浪形的干扰图案,即所谓的摩尔纹,最形象来说,我们用手机拍摄电脑、电视上的画面,或者拍摄条纹和格子的衣服时,拍出来的照片上总是有奇奇怪怪的彩色条纹,这些纹理由摩尔效应引起的。摩尔效应是一种特殊的光学现象,它是两条线或两个物体之间以固定的角度和频率发生干涉后产生的视觉效果。如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aWTOjN8v-1666579769872)(static/boxcnUHnBgpsDN5oTi1hVTJ1zpC.png)]](https://img-blog.csdnimg.cn/25a58aa2c1ea4ce2b3a39cc0e3d49a3d.png#pic_center)
而摩尔纹去除,可以帮助消除屏幕纹对画质的干扰,提高图像、文字清晰度,如下图运用摩尔纹去除网络后,图像质量明显提升:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a3r3R8wG-1666579769873)(static/boxcnpQnRfSMGvO4RSjAsdzymAg.png)]](https://img-blog.csdnimg.cn/e51284d206734f09b18c237f1ce35d68.png#pic_center)
2.3.2、原理分析
基于多分辨率卷积神经网络的摩尔纹图像恢复![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7iOws52k-1666579769874)(static/boxcnECWMAW8Sperux1OiUSt6qf.png)]](https://img-blog.csdnimg.cn/7d0eb37f8eb44ca9a893c6eb61c50ab8.png#pic_center)
网络架构如上图所示,其中包括不同分辨率的多个并行分支,图像输入为 2562563,使用非线性激活函数 + 卷积核。可以看到:
(1)网络中不采用池化层,通过步长为 2 的卷积核来代替池化操作。
(2)下采样过程中大量使用 3*3 卷积核,步长为 1。
(3)在反卷积过程中,增大了图像分辨率,生成 3 通道像素图,最后通过叠加完成输出。
顶部的分支以输入图像的原始分辨率处理特征映射,而其他分支处理越来越粗糙的特征映射。每个分支中的前两个卷积层形成一个组,在所有分支的前两个卷积层之后生成的特征图可以堆叠在一起以形成倒置金字塔。金字塔使用非线性“滤波器”(即卷积核 + 非线性激活函数)计算。然后通过将输入图像转换为不同分辨率的多个特征图,在输入图像中显示不同级别的细节。更重要的是,在网络中,每个分辨率都与一个网络分支相关联,其中六个堆叠卷积层保持相同的分辨率。 这样的网络分支能够执行复杂的非线性变换(例如去除特定频带内的摩尔纹),并且比 U-Net 中的跳过连接(Skip Connection)更强大。
在每个分支内,前两层的输出特征图被馈送到级联卷积层序列中。这些卷积层保持相同的输入和输出分辨率,并且不执行任何下采样或池操作。他们负责消除与该分支的特定频带相关的莫尔效应的核心任务,另外在这个序列中放置了多个卷积层(通常为 5 个),每个卷积层具有 3×3 个核和 64 个通道。
为了将所有并行分支的变换结果组合到一个完整的输出图像中,需要将级联卷积层生成的特征图的分辨率提高到除第一个分支外的每个分支内输入图像的原始分辨率。在从顶部开始的第 i 个分支中,模型使用一组 i−1 个反卷积层来实现这一目标。每个反卷积层使输入分辨率加倍。在每个分支内的反褶积层之后有一个额外的卷积层。这个额外的层生成一个只有 3 个通道的特征图。该特征图基本上消除了与该分支的频带相关联的摩尔图案(在输入图像中)的分量。最后,来自所有分支的最终 3 通道特征图被简单地相加在一起,以产生去除莫尔纹图案的最终输出图像。
三、黑科技体验
日前举行的 2022 中国图像图形大会《ocr 前沿技术与产业应用》论坛上,合合信息公司自然语言算法研发总监丁凯博士介绍的该公司智能文字识别及图像处理技术,被参加论坛的中科院、北京大学、联想研究院等顶尖科研机构的专家,一致认为是破解难题的“钥匙”。
经过体验,合合信息公司智能文字识别及图像处理技术,通过引入ai(人工智能)技术,能够帮助各应用领域简化下游文档处理任务,提升文字识别效率与准确性。
笔者在研究图像处理时也深入体验了一次他们的黑科技。
3.1、功能介绍
官网提供了高精准度的智能文字识别引擎及场景化产品,支持多种部署方式,可以帮助提升文档处理流程的效率。包括证件识别、图像切边切片、PS 检测、自动擦除手写文章、去除摩尔纹、图像矫正、水印去除、文档转换等等。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3jVmw8aW-1666579769875)(static/boxcnr9Ow67ZrddaEuocQUdQ8Hg.png)]](https://img-blog.csdnimg.cn/25866ff4479c4c5a8b5938fefac1dceb.png#pic_center)
下面我们挑选最感兴趣的文档图像切边矫正和 PS 检测进行体验。
3.2、文档图像切边矫正
文档图像切边矫正功能可以智能定位图像中文档主体的边缘,并进行背景切除 (文档提取),对形变文档进行矫正。
官网提供了 API 调用的接口和文档:
请求 URL:
https://api.textin.com/ai/service/v1/dewarp
HTTP 请求方法:HTTP POST
请求头说明(Request Header)
URL 参数
请求体说明(Request Body)
Content-Type: application/octet-stream
要上传的图片,目前支持 jpg, png, bmp, pdf, tiff, 单帧 gif 等大部分格式.
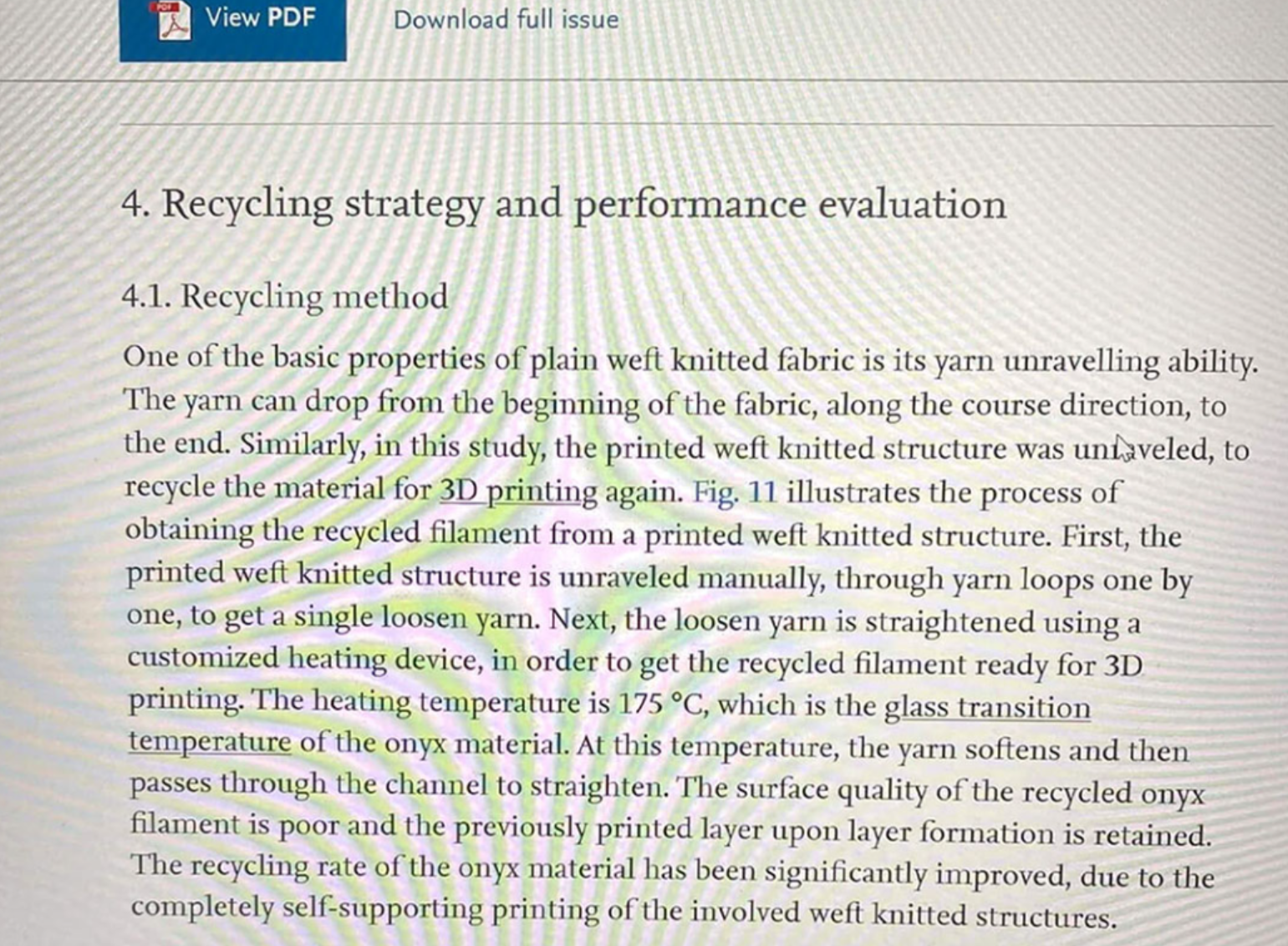
响应体说明(Response Data)
Content-Type: application/json。JSON 结构说明如下: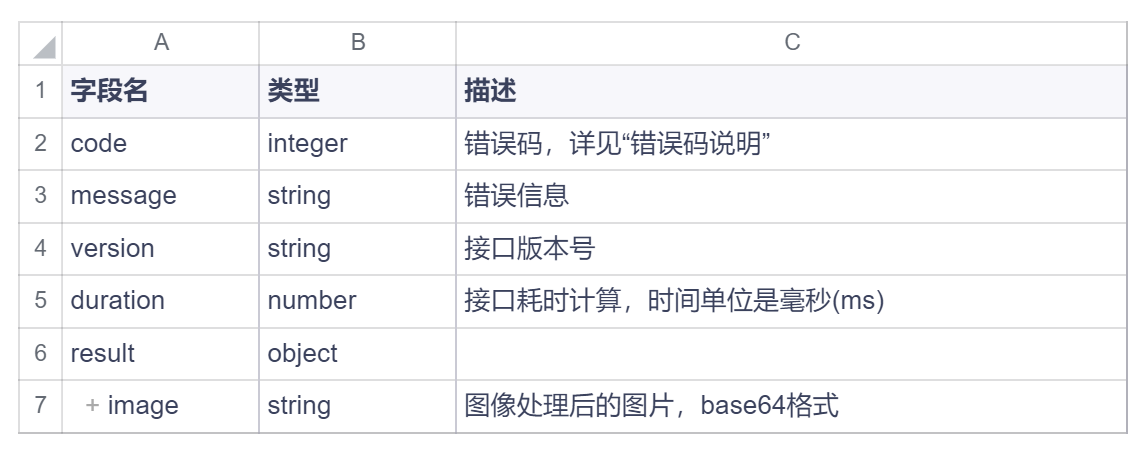
JSON结构示例
{
"code": 200,
"message": "success",
"version": "0.2.0",
"duration": 100,
"result": {
"image": "iVBORw0KGgoAAAANSUhEUgAAEIAAABYA"
}
}
于是,我们可以使用 html 代码调用接口:
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>服务集成演示</title>
</head>
<body>
<h2>上传文件</h2>
<div>
<input type="file" id="file">
</div>
<script>
document.querySelector('#file').addEventListener('change', function(e) {
var file = e.target.files[0] // 上传文件的 File 对象
var reader = new FileReader()
reader.readAsArrayBuffer(file) // 读取成二进制
reader.onload = function (e) {
var fileData = this.result
var xhr = new XMLHttpRequest()
// --------------------------------------------------------------------
var appId = 'c81f*************************e9ff'
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-secret-code
// 示例代码中 x-ti-secret-code 非真实数据
var secretCode = '5508***********************1c17'
// 文档图像切边矫正 服务URL
var url = 'https://api.textin.com/ai/service/v1/dewarp'
xhr.open('POST', url)
xhr.setRequestHeader('x-ti-app-id', appId)
xhr.setRequestHeader('x-ti-secret-code', secretCode)
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
xhr.onreadystatechange = null
var response = xhr.response
var obj = {}
try {
obj = JSON.parse(response) // 转化为对象
} catch (e) {
}
if (!obj.result) return
var list = obj.result.item_list
if (!list || !list.length) return
console.log(list)
}
}
xhr.send(fileData)
}
})
</script>
</body>
</html>
我们使用一副倾斜角度的图像进行测试:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-98QfHwE9-1666579769878)(static/boxcnVz6efHfT5trBctj00tMa3c.jpg)]](https://img-blog.csdnimg.cn/249b62e23b7348699e67b148b0c5460b.png#pic_center)
上传图片后,显示成功调用 API,JSON 对象返回如下,message:success 表示成功,result image 表示的是修正后的图像的 base64 表示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gKdN9Uag-1666579769879)(static/boxcn11xQuV2erGpo7Yyfe4sGHd.png)]](https://img-blog.csdnimg.cn/8ed3119c30c6415c8635eb865f6e3d52.png#pic_center)
我们使用
img src="data:image/jpeg:base64,+‘返回的base64字符串’ "
解码 base64 格式的字符串,得到图像,发现调用成功,图像被成功矫正了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uw0bIX3e-1666579769880)(static/boxcnfUPk8BXGCSe8edPYNH0Zyd.png)]](https://img-blog.csdnimg.cn/16a4fd7c07b24ae2b05ad42f4261867c.png#pic_center)
3.2、PS 检测
另外一个很牛的就是 PS 检测系统,基于行业领先的自研篡改检测系统,可判断图片是否被篡改,支持身份证、护照、行驶证、驾驶证、港澳通信证等证照类别,及增值税发票、普通发票、小票、合同等文档类别。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qtu9jsx4-1666579769882)(static/boxcnpoZ3DvascSaePyReRGGoBh.png)]](https://img-blog.csdnimg.cn/a22edc02cb054c46929288577e163bf9.png#pic_center)
网站提供了丰富的 API 调用接口和文档
请求 URL:
https://api.textin.com/ai/service/v1/manipulation_detection
HTTP 请求方法:HTTP POST
请求头说明(Request Header)
URL 参数
请求体说明(Request Body)
Content-Type: application/octet-stream
要上传的图片,目前支持 jpg, png, bmp, pdf, tiff, webp, 单帧 gif 等大部分格式
响应体说明(Response Data)
JSON 结构说明如下: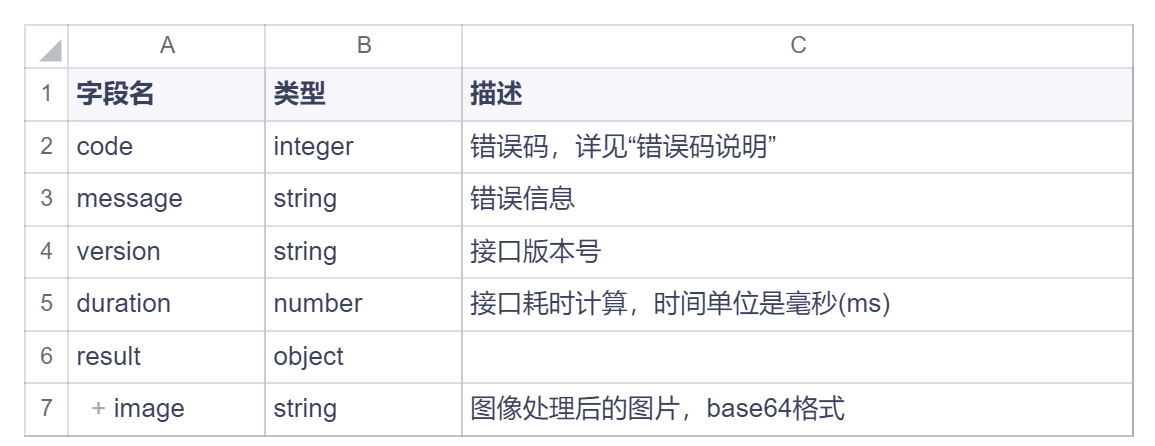
JSON结构示例
{
"code": 200,
"message": "success",
"version": "1.0.1",
"duration": 100,
"result": {
"image_width": 1024,
"image_height": 1024,
"image_property": {
"ps": {
"image": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBD",
"is_tampered": 1,
"positions": [
[
38,
88,
42,
8,
42,
12,
38,
12
],
[
48,
88,
52,
8,
52,
12,
48,
12
]
]
}
}
}
}
这次我们使用 java 代码调用接口:
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws Exception {
// PS检测
String url = "https://api.textin.com/ai/service/v1/manipulation_detection";
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-app-id
// 示例代码中 x-ti-app-id 非真实数据
String appId = "c81f*************************e9ff";
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-secret-code
// 示例代码中 x-ti-secret-code 非真实数据
String secretCode = "5508***********************1c17";
BufferedReader in = null;
DataOutputStream out = null;
String result = "";
try {
byte[] imgData = readfile("example.jpg"); // image
URL realUrl = new URL(url);
HttpURLConnection conn = (HttpURLConnection)realUrl.openConnection();
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("Content-Type", "application/octet-stream");
conn.setRequestProperty("x-ti-app-id", appId);
conn.setRequestProperty("x-ti-secret-code", secretCode);
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestMethod("POST"); // 设置请求方式
out = new DataOutputStream(conn.getOutputStream());
out.write(imgData);
out.flush();
out.close();
in = new BufferedReader(
new InputStreamReader(conn.getInputStream(), "UTF-8"));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送 POST 请求出现异常!" + e);
e.printStackTrace();
}
finally {
try {
if (out != null) {
out.close();
}
if (in != null) {
in.close();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
System.out.println(result);
}
public static byte[] readfile(String path)
{
String imgFile = path;
InputStream in = null;
byte[] data = null;
try
{
in = new FileInputStream(imgFile);
data = new byte[in.available()];
in.read(data);
in.close();
}
catch (IOException e) {
e.printStackTrace();
}
return data;
}
}
同样,我们使用一张被 PS 篡改过后的图像进行测试,调用接口运行后,返回 json 为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8zMDCGzE-1666579769883)(static/boxcnvR6El50WICr2t0HbxtVEAb.png)]](https://img-blog.csdnimg.cn/2d0e684e5ee645008b178ce5792e8d68.png#pic_center)
我们打开 imageproperty,查找 ps 中的 is_tampered,代码显示为 1,即表明检测到这幅图像被 PS 修改过,返回 image 图像为检测到修改的地方的图像。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ijGq2Rnn-1666579769884)(static/boxcnAIg8lWAj2qQzs9RXkA1Qlf.png)]](https://img-blog.csdnimg.cn/d50cd88e74f34315b9b440926dee1074.png#pic_center)
四、总结
经过技术分析,目前低质文档图像的识别问题似乎已经成为 AI 技术落地中的瓶颈,文档图像作为一种非结构化数据,其分析识别确实存在不少技术难点。
合合信息专注于智能文字识别、图像处理、自然语言处理(NLP)、知识图谱、大数据挖掘等技术。基于自主研发的领先的智能文字识别及商业大数据核心技术,为全球 C 端用户和多元行业 B 端客户提供数字化、智能化的产品及服务。
合合信息 C 端产品方面的落地非常成熟,扫描全能王(智能扫描及文字识别 APP)、名片全能王(智能名片及人脉管理 APP)、启信宝(企业商业信息查询 APP)这些耳熟能详的产品覆盖了全球百余个国家和地区的亿级用户;
而 B 端业务如合合旗下智能文字识别服务平台 TextIn,为面向企业客户提供以智能文字识别、商业大数据为核心的服务,形成了包括基础技术服务、标准化服务和场景化解决方案的业务矩阵,满足客户降本增效、风险管理、智能营销等多元需求。
在体验过程中,TextIn 智能文字识别引擎可以从图像和 PDF 文档中提取印刷、手写、印章、公式、表格、图片等富文本信息,支持 50+ 多语言识别,众多文档类型,包括商业文件、发票、账单、收据、名片和海报。在财务共享系统中可以从混贴的发票中切分、分类、提取字段信息,支持发票中错行、倾斜、重叠、遮挡、形变、光照不均等复杂场景;在证件识别系统中支持 13 类国家证件识别,覆盖个人和企业所需的 200+ 种证件识别;在人机结合系统中实现精准 100% 识别,远超越人类的辨识度;此外引擎提供了丰富的方便的 API 调用方法和文档,且在通用场景中平均 1s 处理完一张文本图像,用起来非常便捷迅速。
版权归原作者 中杯可乐多加冰 所有, 如有侵权,请联系我们删除。