
📋 博主简介
- 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP)、TiDB数据库认证SQL开发专家(PCSD)认证。 通过了微软Azure开发人员、Azure数据工程师、Azure解决方案架构师专家认证。 对大数据技术栈Hadoop、Hive、Spark、Kafka等有深入研究,对Databricks的使用有丰富的经验。
- 📝 个人主页:wux_labs,如果您对我还算满意,请关注一下吧~🔥
- 📝 个人社区:数据科学社区,如果您是数据科学爱好者,一起来交流吧~🔥
- 🎉 请支持我:欢迎大家 点赞👍+收藏⭐️+吐槽📝,您的支持是我持续创作的动力~🔥
《PySpark大数据分析实战》-02.了解Hadoop
《PySpark大数据分析实战》-02.了解Hadoop
前言
大家好!今天为大家分享的是《PySpark大数据分析实战》第1章第2节的内容:了解Hadoop。

图书在:当当、京东、机械工业出版社以及各大书店有售!
了解Hadoop
2002年,Hadoop之父Doug Cutting和Mike Cafarella等人决定开创一个优化搜索引擎算法的平台,重新打造一个网络搜索引擎,于是一个可以运行的网页爬取工具和搜索引擎系统Nutch就面世了。Nutch项目是基于Doug Cutting的文本搜索系统Apache Lucene的,Nutch本身也是Lucene的一部分。后来,开发者认为Nutch的灵活性不够,不足以解决数十亿网页的搜索问题,刚好谷歌于2003年发表的关于GFS的论文以及GFS的架构可以解决他们对于网页爬取和索引过程中产生的超大文件的需求。2004年他们开始实现开源版本的Nutch分布式文件系统(NDFS)。2005年,Nutch的开发人员基于谷歌关于MapReduce的论文在Nutch上实现了一个MapReduce系统,并且将Nutch的主要算法全部移植,使用NDFS和MapReduce来运行。2006年,开发人员将NDFS和MapReduce移出Nutch形成一个Lucene的子项目,并用Doug Cutting的小孩的毛绒象玩具的名字Hadoop进行命名,至此,Hadoop便诞生了,其核心便是Hadoop分布式文件系统HDFS和分布式计算框架MapReduce,集群资源调度管理框架是YARN。
分布式文件系统HDFS
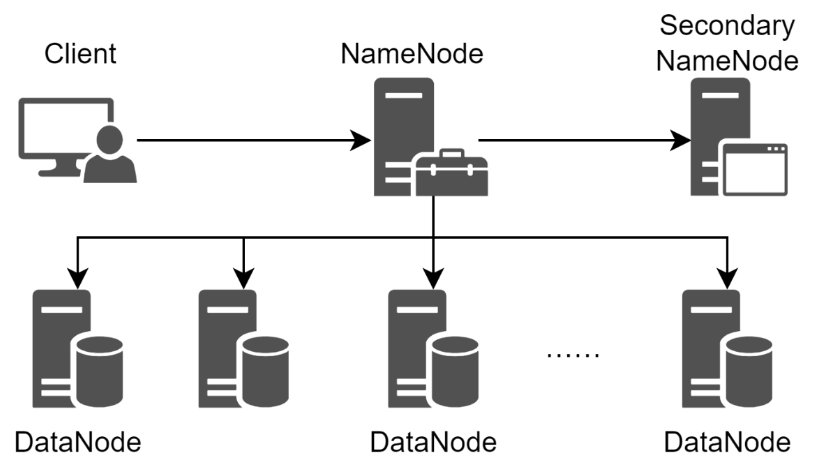
HDFS提供了在廉价服务器集群中进行大规模文件存储的能力,并且具有很好的容错能力,还能兼容廉价的硬件设备。HDFS采用了主从模型,一个HDFS集群包括一个NameNode和若干个DataNode,NameNode负责管理文件系统的命名空间和客户端对文件的访问,DataNode负责处理文件系统客户端的读写请求,在NameNode的统一调度下进行数据块(Block)的创建、删除、复制等操作。HDFS的容错能力体现在可以对数据块保存至少3份以上的副本数据,并且同时分布在相同机架和不同机架的节点上,即便一个数据块损坏,也可以从其他副本中恢复数据。HDFS的体系结构如图所示。
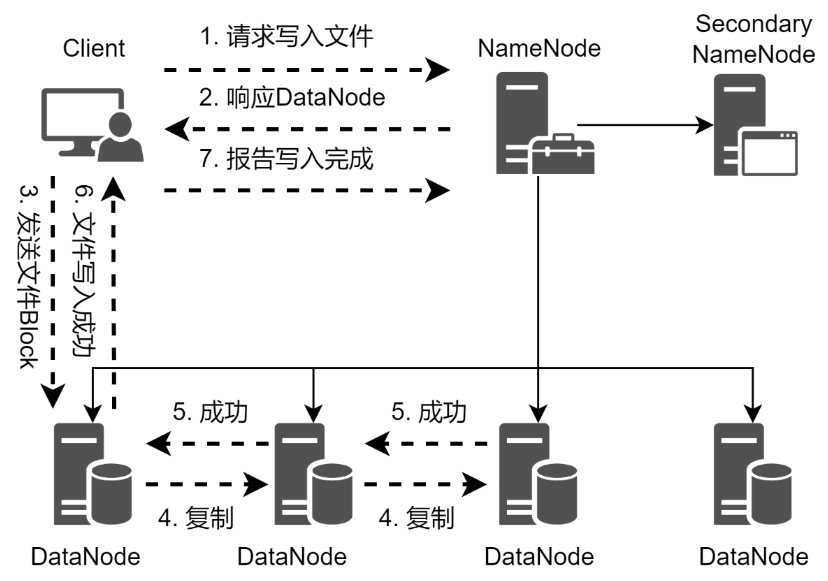
当客户端需要向HDFS写入文件的时候,首先需要跟NameNode进行通信,以确认可以写文件并获得接收文件的DataNode,然后客户端按顺序将文件按数据块逐个传递给DataNode,由接收到数据块的DataNode向其他DataNode复制指定副本数的数据块。HDFS文件的写入流程如图所示。
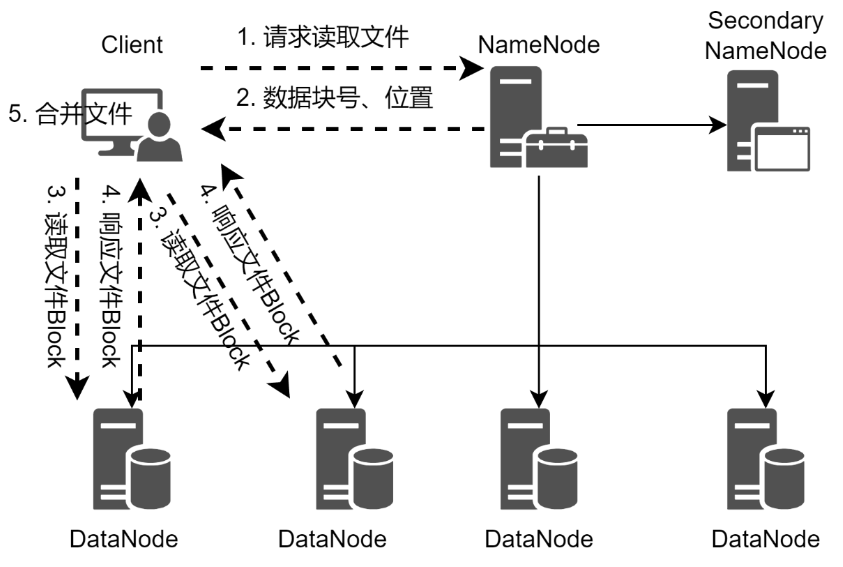
当客户端需要从HDFS读取文件的时候,客户端需要将文件的路径发送给NameNode,由NameNode返回文件的元数据信息给客户端,客户端根据元数据信息中的数据块号、数据块位置等找到相应的DataNode逐个获取文件的数据块并完成合并从而获得整个文件。从HDFS读取文件的流程如图所示。
分布式计算框架MapReduce
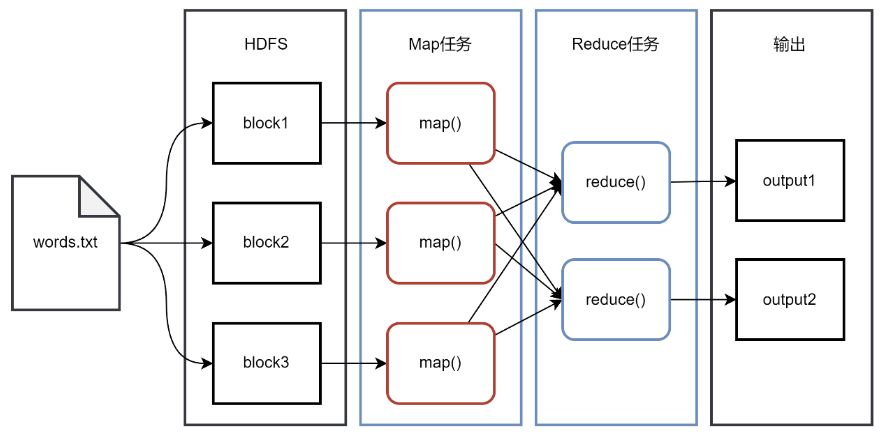
一个存储在HDFS的大规模数据集,会被切分成许多独立的小数据块,并分布在HDFS的不同的DataNode上,这些小数据块可以被MapReduce中的多个Map任务并行处理。MapReduce框架会为每个Map任务输入一个数据子集,通常是一个数据块,并且在数据块所在的DataNode节点上启动Map任务,Map任务生成的结果会继续作为Reduce任务的输入,最终由Reduce任务输出最后的结果到HDFS。MapReduce的设计理念是移动计算而不是移动数据,也就是说,数据在哪个节点就将在哪个节点上执行计算任务,而不是将一个节点的数据复制到另一个计算节点上,因为移动数据需要大量的网络传输开销,在大规模数据的环境下,这种开销太大,移动计算比移动数据要经济实惠。
使用MapReduce框架编程,简单实现一些接口就可以完成一个分布式程序,这个分布式程序就可以分布到大量廉价的PC机器运行。以经典的WordCount程序为例,统计一个文件中每个单词出现的次数,准备一个文本文件words.txt。文件内容如下:
Hello Python
Hello Spark You
Hello Python Spark
You know PySpark
Map任务对读取的文件进行单词拆分,StringTokenizer按照空格、制表符、换行符等将文本拆分成一个一个的单词,循环迭代对拆分的每个单词赋予初始计数为1,并将结果以键值对的形式组织用于Map任务的输出。Map任务的代码如下:
publicclassWordMapperextendsMapper<Object,Text,Text,IntWritable>{privatefinalstaticIntWritable one =newIntWritable(1);privateText word =newText();publicvoidmap(Object key,Text value,Context context
)throwsIOException,InterruptedException{StringTokenizer itr =newStringTokenizer(value.toString());while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);}}}
经过对Map输出的键值对按照键分组,相同键的数据在同一个分组。Reduce任务对分组后的数据进行迭代,取出Map任务中赋予的初始值1进行累加,最终得到单词出现的次数。Reduce任务代码如下:
publicclassWordReducerextendsReducer<Text,IntWritable,Text,IntWritable>{privateIntWritable result =newIntWritable();publicvoidreduce(Text key,Iterable<IntWritable> values,Context context
)throwsIOException,InterruptedException{int sum =0;for(IntWritable val : values){
sum += val.get();}
result.set(sum);
context.write(key, result);}}
在主任务中,需要将Map任务和Reduce任务串联起来,并指定Map任务的输入文件和Reduce任务的输出,主任务代码如下:
publicclassWordCount{publicstaticvoidmain(String[] args)throwsException{Configuration conf =newConfiguration();Job job =Job.getInstance(conf,"WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job,newPath("words.txt"));FileOutputFormat.setOutputPath(job,newPath("count"));System.exit(job.waitForCompletion(true)?0:1);}}
将程序打包、提交运行,运行结束后在count目录下生成最终的结果,结果如下:
Hello 3
Python 2
Spark 2
You 2
know 1
PySpark 1
MapReduce的工作流程如图所示。
资源调度管理框架YARN
Hadoop的两个组件HDFS和MapReduce是由批量处理驱动的,JobTracker必须处理任务调度和资源管理,这容易导致资源利用率低或者作业失败等问题。由于数据处理是分批完成的,因此获得结果的等待时间通常会比较长。为了满足更快速、更准确的处理数据的需求,YARN诞生了。YARN代表的是Yet Another Resource Negotiator,最初被命名为MapReduce2,是Hadoop的主要组件之一,用于分配和管理资源。YARN整体上属于Master/Slave模型,采用3个主要组件来实现功能,第1个是ResourceManager,是整个集群资源的管理者,负责对整个集群资源进行管理;第2个是NodeManager,集群中的每个节点都运行着1个NodeManager,负责管理当前节点的资源,并向ResourceManager报告节点的资源信息、运行状态、健康信息等;第3个是ApplicationMaster,是用户应用生命周期的管理者,负责向ResourceManager申请资源并和NodeManager交互来执行和监控具体的Task。YARN不仅做资源管理,还提供作业调度,用户的应用在YARN中的执行过程如图所示。

 :在YARN集群中,NodeManager定期向ResourceManager汇报节点的资源信息、任务运行状态、健康信息等。
:在YARN集群中,NodeManager定期向ResourceManager汇报节点的资源信息、任务运行状态、健康信息等。
1:客户端程序向ResourceManager提交应用并请求一个ApplicationMaster实例。
2:ResourceManager根据集群的资源情况,找到一个可用的节点,在节点上启动一个Container,在Container中启动ApplicationMaster。
3:ApplicationMaster启动之后,反向向ResourceManager进行注册,注册之后客户端通过ResourceManager就可以获得ApplicationMaster的信息。
4:ResourceManager根据客户端提交的应用的情况,为ApplicationMaster分配Container。
5:Container分配成功并启动后,可以与ApplicationMaster交互,ApplicationMaster可以检查它们的状态,并分配Task,Container运行Task并把运行进度、状态等信息汇报给ApplicationMaster。
6:在应用程序运行期间,客户端可以和ApplicationMaster交流获得应用的运行状态、进度信息等。
7:一旦应用程序执行完成,ApplicationMaster向ResourceManager取消注册然后关闭,ResourceManager会通知NodeManager进行Container资源的回收、日志清理等。
结束语
好了,感谢大家的关注,今天就分享到这里了,更多详细内容,请阅读原书或持续关注专栏。
版权归原作者 wux_labs 所有, 如有侵权,请联系我们删除。